
Transformer模型深度解读 精读 (transferwise)

10倍GPT

数字人 支持NVIDIA 终端AI助手 悟道 GTX单卡机运行百亿大模型 首次落地 全球最大智能模型 (数字人ecdh)

启明星计划 智驾科技MAXIEYE发布 面向全行业开放BEV感知标准件 (启明星 计划)

知识图谱的全方位总结 ACL 2019 (知识图谱的全称是什么)

出题 解题 评分样样都行 当AI学会高数 (题目打分)

基于序列对比学习的长视频逐帧动作表征 浙大蔡登团队 (序列对比算法)
少于两层的transformer GPT 且只有注意力块 (两层以上含两层不得设置防盗窗)

轻松应对高难度长文本序列 这六大方法 如何让 Transformer (轻松应对高难度的工作)

长程上下文综述 Transformers

开放代码又如何 资源集中 成本昂贵 大规模语言模型的民主化越来越难 (开放原代码许可)
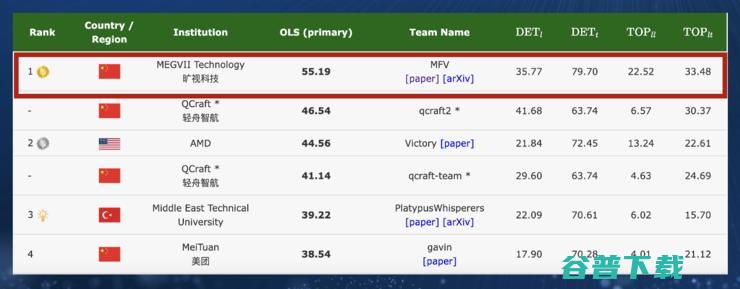
成熟了 旷视的自动驾驶果实 蛰伏两年 (成熟的潜台词是什么)

用Transformer做线代作业 真香! (用transportation造句简单)

cosFormer ICLR 重新思考注意力机制中的Softmax 2022 (cosforge)
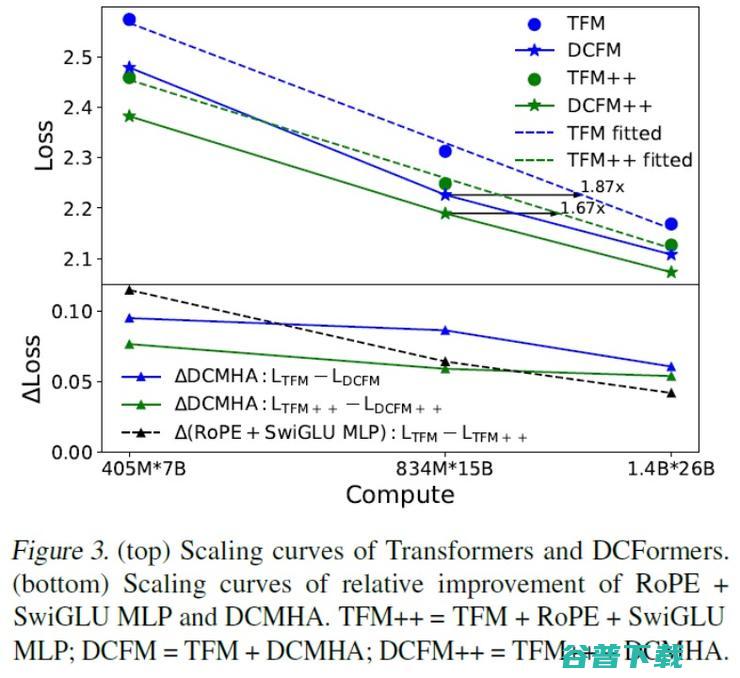
彩云科技DCFormer模型架构发布 效率是Transformer的两倍! (彩云科技大模型)

Yan1.3解密AGI新路径 当端侧革新遇见群体智能 (腌13斤肉要多少盐)
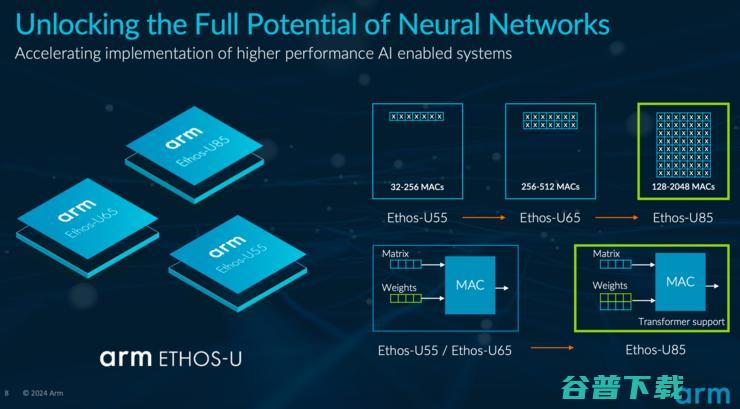
Arm全新NPU性能提升4倍 支持Transformer 边缘生成式AI时代指日可待 (arm全新架构)

用 限制 图机器学习无处不在 Transformer 可缓解 GNN (限制性作图的基本原理和方法)


欧思丹热能科技有限公司是集空气能热水器、地暖空调、特种高温机组研发、生产、销售、服务为一体的大型热泵厂家,服务热线0411-86421287,热泵热水器,优选欧思丹!。

习水特产商城,茅酒网,习水掌中科技有限公司

东锜特殊钢经销代理日本日立进口优质模具钢材yxr33,yxr33高速钢,YXR33模具钢,YXR33是什么材料,YXR33价格多少钱,YXR33出厂硬度状态:≤241HB,YXR33钢使用硬度:56-60HRC。日本YXR33压铸模具钢耐磨性好,耐裂纹性优良,不仅适用于温热精密锻造模,而且适用于耐高热负荷的热作工具用高韧性模型高速钢。

拥有全国各地上千万家企业信息,找企业信息就到黄页网。目前网站服务免费,并支持动态发布,实时更新,现在加入免费得到首页推荐,每天十万次的显示机会让给你。

一家家装为您提供优质的装修服务,拥有优质的装修建材,精湛的装修工艺,让您售前无虑,售后无忧。

广州益美硬盘销毁回收公司隶属于广州益美环境服务有限公司,长期提供硬盘消磁销毁,冻肉销毁,冻品销毁,保密数据销毁,洗发水销毁,涉密载体销毁,咖啡销毁,茶叶销毁,咖啡豆销毁,沐浴露销毁,洗衣液销毁,保密文件销毁,过期食品销毁,过期奶粉销毁,啤酒饮料销毁,冷冻食品销毁,牛肉销毁,报废化妆品销毁,过期保健品销毁,报废面膜销毁,过期护肤品销毁,u盘芯片银行卡销毁,垃圾清理,工业垃圾处理,工业垃圾处置等业务,服务范围涵盖深圳珠海东莞过期化妆品处理销毁,佛山惠州过期食品处理销毁等珠三角地区

通宝优品是专门做产品推广的电子商务平台,是产品和服务的电子商务平台提供商-通宝优品为产品宣传推广。

MT管理器官网

山东开山联合节能科技有限公司主要经营:空气压缩机,冷媒压缩机,膨胀发电机,工艺气体压缩机,环境工程,冷链产业,压缩空气系统

郑州冷链物流,郑州生鲜物流,郑州商超冷藏物流.郑州仓储物流,郑州冷藏运输,郑州物流配送,河南冷链物流,河南生鲜物流,河南商超冷藏物流.河南仓储物流,河南冷藏运输,河南物流配送

【昆山吉伦奇】提供Parmelee扳手,GEARENCH摩擦钳,PETOL摩擦钳,吉伦奇台式抱钳.陈13372123999

深圳市华美盛业投资发展有限公司成立于2013年,主营业务钢铁、长材、板材、钢构等建筑钢材与工程用材生产加工,先后注资控股和参股了钢铁、物流、互联网+、生物制药、跨境电商等行业领域,产业呈多元化发展。

