百度ERNIE2.0强势发布 (百度二年级语文上册)

17篇论文 详解图的机器学习趋势 (论文篇数是什么)

2022 十大领域!百度研究院发布 年十大科技趋势 涉及三大层面 (2022十大网络用语)

为桨 扬帆起航! 百度研究院发布2022年十大科技趋势!以AI为灯 (扬帆起航,为国争光什么意思)

光启慧语发布光语医疗大模型 联合上海中山医院探索智慧医疗新模式 (深圳光启智慧科技有限公司)

10倍GPT

巨量模型时代 打造全球最大中文语言模型 2457亿 浪潮不做旁观者 (巨量时代(深圳)科技有限公司)

2012年至今 细数深度学习领域这些年取得的经典成果 (2012年至2024年多少年)

数字人 支持NVIDIA 终端AI助手 悟道 GTX单卡机运行百亿大模型 首次落地 全球最大智能模型 (数字人ecdh)

TensorFlow最出色的30个机器学习数据集 (tensorflow)

思必驰俞凯 端到端与半监督语音识别的技术进展 (思必驰俞凯个人简介)

Vision平台 李飞飞发文发布谷歌云AutoML 订制化的企业级机器学习模型不再是难题 (vision pro 2)

这家企业走在了前面 预训练大模型产业落地的爆发前夜 (这家企业走在人生路上)

零一万物大模型Yi (零一万物大模型)

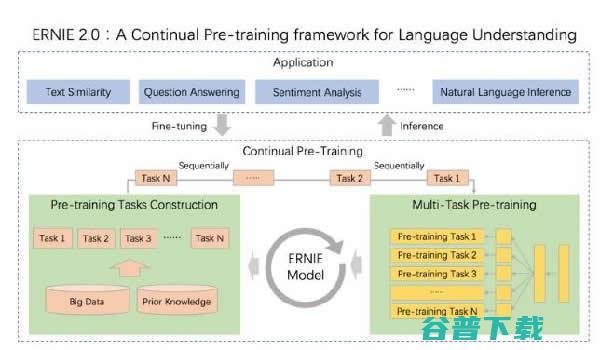
和 XLNet! ERNIE 百度开源自然语言理解模型 NLP 个 BERT 2.0 任务中碾压 16

12 NLP ChatGPT 还有 之后 个待解决命题 哈工大张民

现在和未来 语言模型的过去 Lab AI 总监李航 字节跳动 (现在和未来语录)

数据存储难 希捷HAMR技术4年让硬盘单盘容量翻倍! (数据 存储)


-房产-房地产网址

江苏绿星源垃圾房厂家专业生产垃圾房,垃圾分类房,智能垃圾箱,垃圾分类亭,智能垃圾回收站等产品,是宿迁较大智能垃圾回收设备生产厂家,资质齐全,厂价直销,支持定制欢迎咨询合作:17751081878

广东亚兰装备技术有限公司是一家专业电子设备研发,生产,销售,服务为一体的综合性配套厂商,提供高精度更稳定的铡刀分板机,冲压分板机,脉冲热压机,哈巴焊机等产品,为制造业生产提速,欢迎来电咨询:13528582360

北京弘森科元设备安装工程有限公司

绝地求生官方指定加速器,专业的网游加速器-迅游网游加速器,新用户免费试用!有效解决玩家在网络游戏中遇到的延时过高,登录困难,容易掉线等问题,迅游网游加速器为网游保驾护航!

金日达物流提供物流,货运,空运,搬家,海运等一站式门到门货物运输解决方案,打造标准化物流运输服务。

专业问答经验知识百科网站!

抖音培训就选二哥起号学,快速掌握最新起号技术。本人营销实战十年,23年首次开培训班,实操案例不计其数,良心授课,按方法严格执行,你也能像我一样,一月涨4万精准粉。

LLX模板网专注学生网页设计,提供HTML静态网页成品、dreamweaver网页制作、PHP动态网站设计、divcss布局静态网页作品、简单个人网页设计、HTML静态网页模板、phpmysql毕业设计网站源代码下载。

长沙润凯环境科技有限公司公司的主要产品有:UV光解净化器、低温等离子净化器、活性炭净化(及吸附脱附)设备、湿式洗涤塔、布袋除尘器、净化与治理。电话:18573102388

西鱼AI资源导航是一个汇聚集国内外优秀AI应用工具网址导航平台,包括AI绘画、AI内容设计、AI语音生成、AI短视频生成、AI自媒体写作、AI客服、AI办公、AI营销、数字人等人工智能工具。提供一站式AI工具导航服务,帮助用户提升工作效率和创作能力,定时更新分享优质AI工具应用书签。

海南福港远洋渔业有限公司

