
OpenAI公布GPT4 (openai和chatGPT什么关系)

稳健中走更远 AI 2.0时代的商汤智慧城市 (稳健才能走得远 诗句)

1.5 独家 投后估值 杨红霞创业入局 亿美元 端侧模型
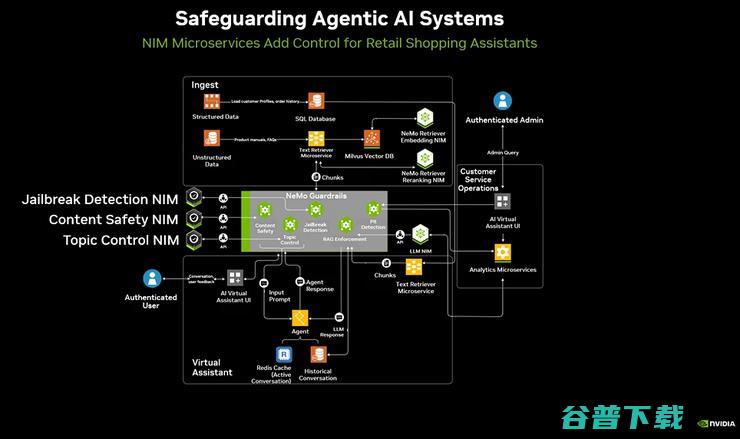
英伟达有3项全新微服务 如何给智能体装个 AI护栏 (英伟达只有三个选项)
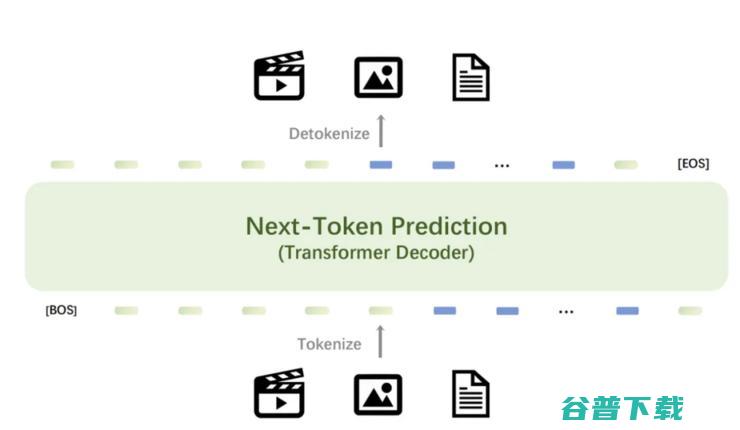
token Emu3 预测 智源 证明多模态模型新范式 只需基于下一个 (tokenexpired)

用户已破百万 最强对话模型 落地将有几何 ChatGPT OpenAI (用户已破百万什么意思)

豆包大模型综合能力提升20.3% 应用落地再提速 发布三个月 (豆包大模型综合能力提升20.3%)

北大校友 炼丹 OpenAI如何训练千亿级模型 分享 (北大校友炼丹师是谁)

中科曙光和智谱AI达成战略合作 竹间智能 通用人工智能在企业落地的到来! 加速 (中科曙光和智蒲合作)
两行代码解决大语言模型对话局限!港中文贾佳亚团队联合MIT发布超长文本扩展技术 (两行代码解决电脑卡顿)

巨量模型时代 打造全球最大中文语言模型 2457亿 浪潮不做旁观者 (巨量时代(深圳)科技有限公司)

启明创投发布2024生成式AI十大展望 (启明创投投资界)
Azure 如影数字人SenseAvatar上线微软全球云市场Microsoft Marketplace (azure如何申请OpenAI的API)

买模型 还是买管线 全球药企拥抱AI大模型进行时 (买个模型)

诚邀您共同探索中国大模型之路!详细日程公开 早鸟倒计时3天丨院士领衔 重磅嘉宾云集!中国大模型大会 CLM2024 (诚邀您共同探索的句子)

OpenAI祭出120亿参数魔法模型!从文本合成图像栩栩如生 仿佛拥有人类的语言想象力 (openai股票)

出题 解题 评分样样都行 当AI学会高数 (题目打分)

百度CTO王海峰 文心一言本质是提升生产力工具 将带来三大产业机会 (百度cto王海峰)


机械师--海外名表网精选全球畅销海外名表,海外私人直发,空运直达,开具发票,全球联保。总公司成立于2009年,总部位于德国,是欧洲系电商公司,具备严谨品质文化风格,所有商品海外仓储自营,提倡为用户“海外直发,空运直邮”,支持为用户开具欧洲发票,保障商品品质和用户海淘购物权益。

羊奶100网汇聚了羊奶行业的最新资讯、羊奶知识、羊奶品牌、羊奶专家及羊奶展会动态,是一个以羊奶为主题的专业媒体,全力专注于羊奶行业,走更为专业和深化的细分化道路,360度全方位的为羊奶企业提供网络传播和行销服务支持,是羊奶粉行业进行品牌网络宣传、产品展示、招商加盟和网络营销的最佳平台及有效途径.

云平财税--注册公司|代理记账|乱账清理|理账清账|注册商标|公司注销|工商变更|等财税服务|台州|温岭|台州云平税务咨询有限公司

掘诚二手挖掘机直销网是目前一家大型二手挖掘机销售市场.专业提供多种品牌二手挖掘机,小松,日立,卡特,神钢,现代,斗山,沃尔沃等二手小型中型大型挖掘机!免费包送,报销路费!因为业务扩大并在江苏苏州昆山设立二手挖掘机市场分部!

江苏橡胶护舷厂家-江苏建港橡胶制品有限公司

南昌精诚废旧物资回收有限公司是一家证照齐全的回收资质单位。拥有十余年回收经验,主要收购废旧金属类、通讯设备类、旧电线电缆、电池电瓶回收、承接工业一切库存废料及废旧厂房拆迁,长期向各企事业单位以高价现金上门回收各种废旧物资。

中共休宁县委组织部,休宁先锋网,休宁县先锋网

齐鲁经济网qljjw.com.cn山东经济网门户山东财经网站。齐鲁经济网定位山东财经门户、专业财经网络媒体,为用户提供专业、全面、丰富的山东本地财经资讯服务。

临沂鲁临消防装备有限公司,生产销售:消防车.环卫车.抢险车.特种车.电动车.等车用铝合金卷帘门.云梯,后爬梯.旋转支架.消防工具挂架.铝合金扶手.不锈钢扶手护栏.平托.立拖.各种灯具等相关配件.本公司本着质量为上,诚信为本的原则回馈社会。

欧洲包车网提供欧洲包车游.欧洲包车可选车型:5/7/10商务车:海狮/埃尔法等;欧洲各大机场接机送机服务,包括荷兰、意大利、西班牙、葡萄牙、希腊、英国等国家的包车旅行、机场接送机等信息,专注荷兰包车接机、阿姆斯特丹机场接送机、比利时包车接机、布鲁塞尔机场接送机、希腊包车、雅典机场接送机等。

年华数据科技有限公司

路面机械网为您提供工程机械产品报价,工程机械整机导购,行情,评测,口碑,论坛,以及精彩专业的工程机械新闻等内容,还提供工程机械配件,租赁,维修,二手等后市场服务。

