
北大校友 炼丹 OpenAI如何训练千亿级模型 分享 (北大校友炼丹师是谁)

10倍GPT

数字人 支持NVIDIA 终端AI助手 悟道 GTX单卡机运行百亿大模型 首次落地 全球最大智能模型 (数字人ecdh)
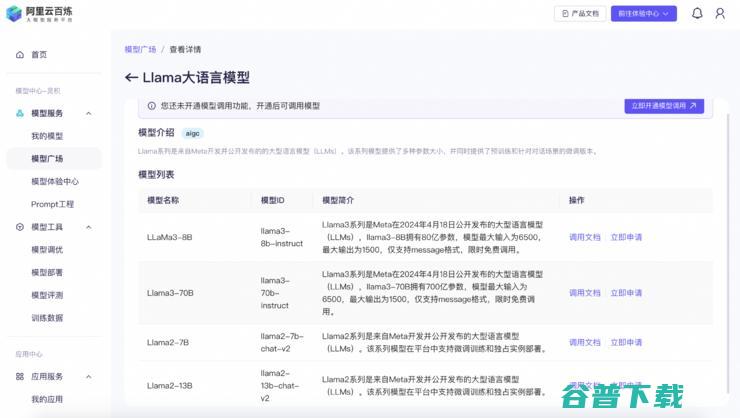
国内首家 训练推理 并提供免费算力 3 阿里云全方位支持Llama (国内首家训练基地)

平安科技前沿技术部门负责人王磊 大规模预训练模型在垂直领域应用的缺陷与改进 (平安科技前沿技术部门负责人王磊)


18320961979微信,ups电源制造厂,ups电源报价,C6K,C3K,3C20KS,3C10KS,C10KS,C3KS,C2K,3KVA,6KVA,10kva,20kva,30kva,40kva,ups不间断电源设备厂家,

河北标良丝网制造有限公司是大型热镀锌钢格栅板厂家,优秀生产企业:产品有镀锌钢格栅板、格栅板、钢格栅板、沟盖板、楼梯踏板、水篦子、不锈钢格栅板。服务电话:18631822676

吉林天善农业为您提供东北大米,吉林大米,德惠大米,富硒大米,酵素大米,吉林富硒大米,吉林酵素大米,绿色大米,东北香米,好吃的绿色大米

中小学综合实践活动评价管理系统

深圳市炫丰显视科技有限公司是一家新兴生产型企业,致力于为国内液晶商业显示行业企业提供银行双面吊挂屏,广告机,商用显示设备,液晶广告机,液晶触摸一体机,广告机厂家,触摸一体机.挂式,立式液晶一体背光套料,触摸(红外,电容,纳米膜)一体背光套料产品及技术支持服务,.联系电话:13713521137

河南浩明机械设备有限公司专业生产各种裙边皮带输送机,挡边皮带输送机,大倾角皮带输送机,通用型皮带输送机,斗式提升机等设备.15837399557,厂家直销.

Xilinx公司(中文名:赛灵思)于1984年在美国创立,Xilinx的成就,不止是发明了FPGA,也不止是繁荣了FPGA,更值得尊敬的是将FPGA的生态系统建立起来,成为目前几个最重要的主处理平台生态中最具发展活力又恰是最年轻的一个。Xilinx无论是它的世界第一颗FPGA芯片、Virtex、Spartan、嵌入式可编程处理器MicroBalze和Zynq,还是设计工具ISE,赛灵思的技术和产品在工业和学士界都赢得了巨大的影响,Xilinx的产品融合了开发板、FPGA、SoC和3DIC系列可编程器件,以及全可编程的开发模型,包括软件定义的开发环境等。Xilinx的产品支持5G无线、嵌入式视觉、工业物联网和云计算所驱动的各种智能、互连和差异化应用...

上网导航,网址导航,网站导航,网址之家,网址大全,网址,搜索,音乐,娱乐,图片,小游戏,短信,社区,日记,相册,K歌,通讯簿,BLOG,天气预报,实用工具.最方便,最快捷

河北聚金通讯设备有限公司

电热压高分子扩散焊机为大宇机械专门针对母线伸缩节、铜板、铜带、铜箔、铜块、导电带、软连接、不锈钢以及镍等进行焊接的设备。该高分子扩散焊接设备广泛应用于电力、化工、冶炼等行业,备受*评。

升达致力于一体化家居和智能化家居的打造,引领潮流家居的生活方式,为客户提供一体化家居解决方案,让家居生活更美丽。

五粮液防伪官网

