DeepSeek (deepseek是什么)

字节跳动起诉前实习生篡改代码 800万索赔与公开道歉的深思 (字节跳动公司事件)

助力AIoT 雅观科技发布空间智能化操作系统 (助力AI大模型训练,全球数据采集攻略)

360发布安全大模型3.0 开辟垂类大模型训练新战法 (360发布安全大模型)
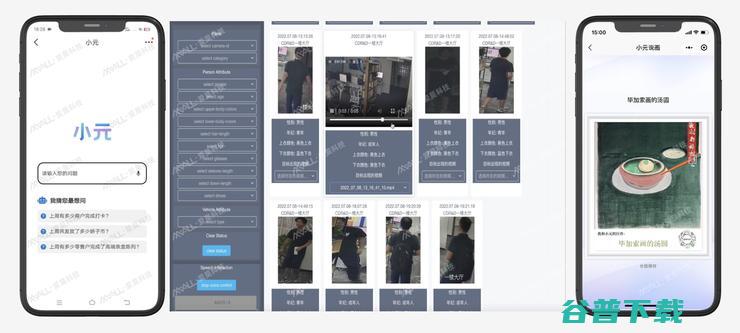
对话爱莫科技杨恒 15年数据仿真研发遇上大模型浪潮 (爱莫科技做什么的)

Lite只是故事的一部分 谷歌还一并介绍了新的模型压缩方法 TF (litegui)

2017精彩论文解读 显著降低模型训练成本的主动增量学习 CVPR (2017精彩音乐汇踏浪徐怀钰)

显著降低模型训练成本的主动增量学习 CVPR 2017精彩论文解读 (显著降低模型的方法)

腾讯云副总裁刘煜宏 构建企业数据连接器 助力企业更高效挖掘数据价值 (腾讯云副总裁排名)

提升GPU性能4 (提升gpu性能软件)

核武器 改变算法生产的 小样本 AutoML

要让深度学习模型训练时间缩短100倍 CAIIC 2016 英特尔宋继强 2020年
新瓜不断!2024NeurIPS最佳论文 花落字节起诉的实习生 (lh新瓜)
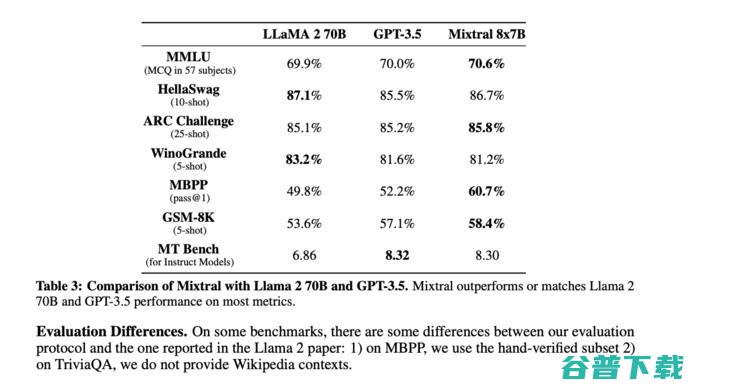
MoE A 高效训练的

的突破丨GAIR 2023 新加坡国立大学尤洋 高性能 AI (突破的突)

剑桥高级机器学习讲师Ferenc Huszár评马腾宇新作 它改变了我对上下文学习的思考方式 (剑桥gao)

已应用于豆包视频生成模型 火山引擎发布大模型训练视频预处理方案 (已应用于豆包的食品)

VLM 模型 生图超级外挂!贾佳亚团队提出 Mini (m-v模型)


站长之家Alexa排名查询工具提供zhihu.com网站alexa排名查询,特别是能够对网站预估收入以及网站价值进行评估的功能,帮助用户更好的提升alexa排名。

哈尔滨华恒展柜有限公司是一家集展示柜设计、制作、生产、销售于一体的综合性专业厂家!专业生产设计哈尔滨展览展示,哈尔滨展柜厂等各类展柜!一流品质欢迎定制。详询:15504628968

首页,广州惠广林科技有限公司

中投华创主张以互联网新技术加资本力量赋能创业成功!自成立以来独立或联合举办800+场次创业及资本对接活动,服务并陪跑了6000家以上企业。

面向医疗器械厂家提供数字化营销解决方案的智能科技公司。通过云产品与海量数据挖掘能力,提升厂商渠道拓展和更替效率;提供商机与商情大数据,赋能体系化营销;通过市场洞见工具与解决方案,赋能企业洞察与决策。

设计本是国内专业室内装修网站及设计招标服务平台,汇聚了全国百万室内设计师,每日更新大量室内设计效果图、知名室内设计师访谈、优质室内设计案例等,并提供专业的软装搭配、室内装修设计知识。

欧亚国际公司的客服【微信87208666】添加后咨询即可2.可到欧亚一楼前台电话【18988307616】与工作人员取得联系3.通过公司官方邮箱!

北京昌平区专业管道清洗公司,专业疏通设备,专业清洗车辆,专职高压清洗人员,经验丰富,优质服务,昌平24小时管道疏通电话,提供24小时清洗咨询,服务项目:管道疏通,管道清理,高压清洗管道,下水道疏通,化粪池清理清洗,化粪池抽粪吸粪,污水池清淤清污,昌平区管道堵塞时,请拨打昌平下水道疏通电话!

广东智慧物流一站式承接大小件散货、拼箱、整托、整柜、集运等货物从中国大陆运送到印度尼西亚、菲律宾、马来西亚、新加坡、巴西的电商物流,从头程到末端派送双清包税物流解决方案,同时配套式本地仓储印尼海外仓、菲律宾海外仓、巴西海外仓。

飞游网是专为游戏玩家们打造的一个安全、快速、绿色专业的下载前沿基地,这里汇集全网各种最前沿最新手机资源和安卓应用app,让你率先在这里尝鲜各种手机游戏、应用app、攻略、资讯、教程等相关内容,给你一站式的游戏网站服务体验。

彩虹网址导航,彩虹网址,网站导航,网址分类,彩虹导航,网址收藏,实用网址,在线工具,网站推荐,互联网资源

新华字典在线查字,支持部首拼音笔画多种查字法。新华字典,新华字典在线查字,康熙字典,字典在线查字,字典在线查询,在线字典,在线新华字典,康熙字典在线查字,现代汉语词典,新华字典部首查字,新华词典,新华字典在线查询,新华字典电子版,新华字典拼音查字,新华字典在线查笔画

