
有趣的数学思维游戏有什么 锻炼数学思维的游戏推荐2024 (有趣的数学思维游戏)

万字长文珍藏版 RL 如何将机器人可靠性逼进 99.9% Control (万字长车)

2019 谷歌新智能体Dreamer将亮相NeurIPS 数据效率比前身PlaNet快8个小时 (2019谷歌九八网)

卡牌游戏八合一 华人团队开源强化学习研究平台RLCard (卡牌游戏八合怎么玩)

强化学习的10个现实应用

2019 LeCun 年的预测 Yann 年的里程碑以及 AI2018 对话吴恩达 (2019雷凌)

ASSIA (assiassion什么意思)

这次用上了深度强化学习! 谷歌又出量子计算新成果

LeCun一小时演讲 附完整视频 Yann Facebook 研究的下一站是无监督学习 AI

人造太阳 DeepMind用深度强化学习研究 !据说这是秘密进行了3年的工作 (人造太阳的大科学装置是用于研究什么的)
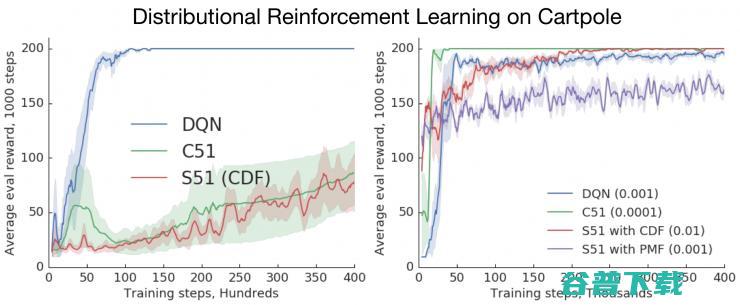
个月中 是怎样研究强化学习的 我在谷歌大脑工作的 18 (个月什么)

大赛联动高校破局AI研究 开悟 利用王者荣耀复杂环境第二届 (高校联赛hmg)
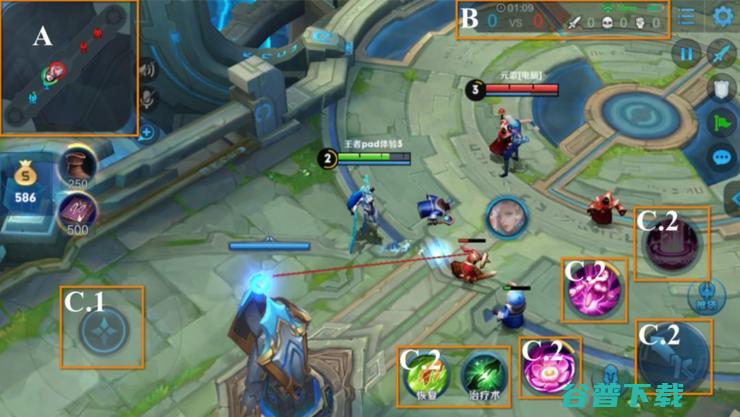
1v1胜率99.8% AI 腾讯绝悟 技术解读 2100场王者荣耀 (1v1胜率最高的英雄)

AI 但它本应成为我们的助力 Facebook事件背后 已经控制着我们 (ai显示非本机图稿怎么回事呢)

深度强化学习 (强化学习)
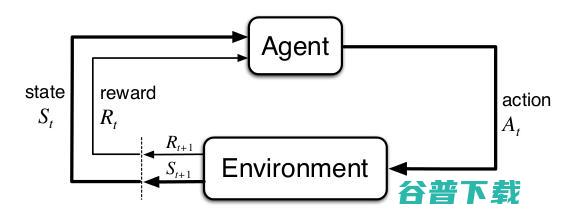
简单易懂 (简单易懂的现代魔法)
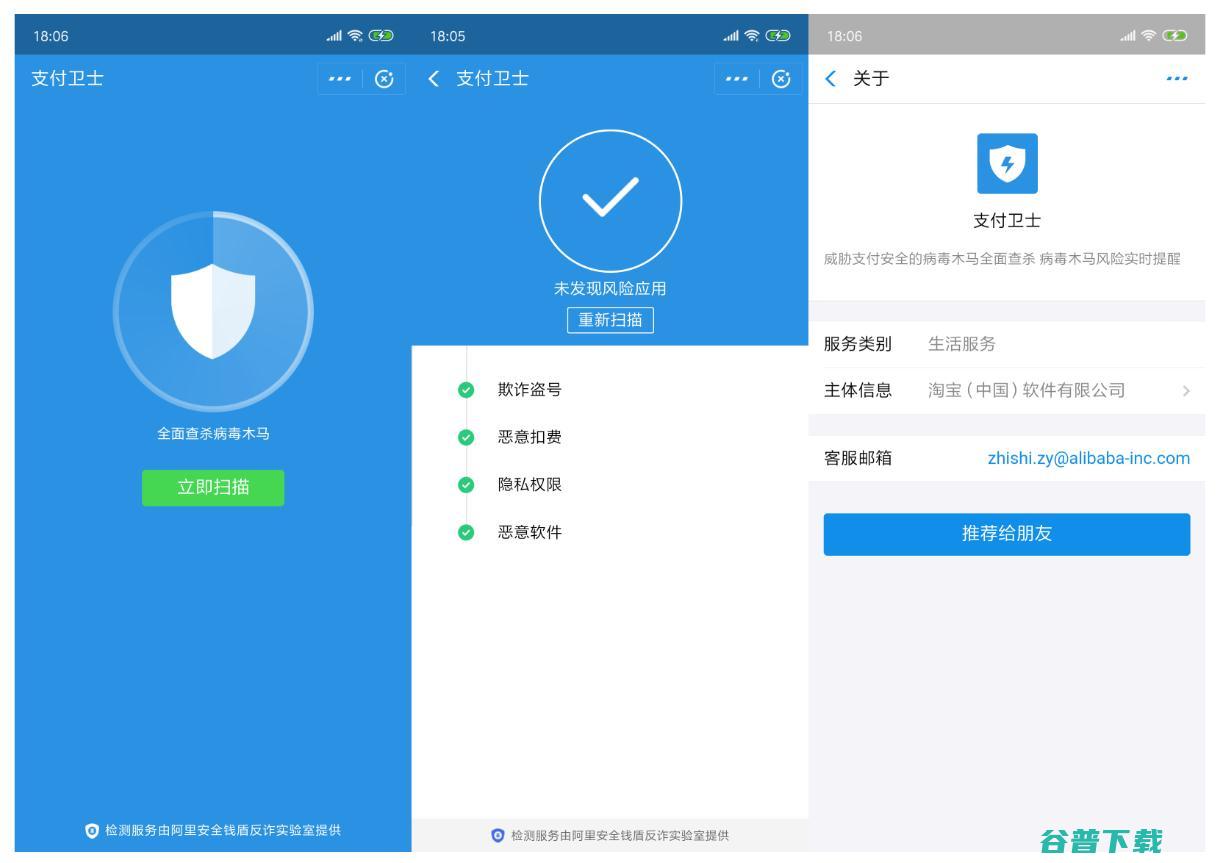
支付宝安全团队 京东等获奖 KDD 滴滴 比赛结果出炉 CUP (支付宝安全团队多少人)

普林斯顿大学王梦迪 从基础理论到通用算法 看见更大的AI世界观 (普林斯顿大学金融工程硕士)


欢迎登录支付宝,支付宝-全球领先的独立第三方支付平台,致力于为广大用户提供安全快速的电子支付/网上支付/安全支付/手机支付体验以及转账收款/水电煤缴费/信用卡还款等生活服务应用;为广大为从事电子商务的网站提供支付产品/支付服务的在线订购和技术支持等服务,帮助商家快速接入支付工具,高效、安全、快捷地开展电子商务。

安徽省庐江县恒风风机有限公司专主营各种用途的离心,轴流,斜流通风机,低噪音锅炉鼓,引风机等25个系列,300多种规格风机,厂家直销,欢迎来电:0551-87414666!
![北京理工大学出版社[官方网站]](http://www.gpxz.com/zdmsl_image/jietu/jt_13166.png "北京理工大学出版社[官方网站]")
北京理工大学出版社官方网站。北京理工大学出版社由北京理工大学主办,工业和信息化部主管,中央级出版社。1995年获得电子出版权,2005年获得音像制品出版权,2014年获得互联网出版权。北京理工大学出版社以“科技传播、文化传承”为历史使命,逐步形成了以数字出版为前瞻,以学术出版为主体,以教育出版和大众出版为两翼的出版格局。

厦门城市在线成立于2005年,位于厦门市岛内软件园二期,主要提供软件、网站、APP、微信公众号、微信小程序、信息管理系统的设计、开发和维护等业务。热线:0592-5735819,13328783439。

硕软官网首页-物联网卡[企业免费试用]_话费流量充值 硕软技术公司是领先的融合通讯云服务商,成立15年来已成为华为、阿里、腾讯、京东、唯品会、高德、拼多多等通信或互联网头部企业重要的战略合作伙伴。我们连接通信运营商与客户的智能化通讯需求,融合话费、流量、短信、物联网、号卡、语音及宽带资源转变为面向广大企业客户的数智服务。

发布信息,商机发布,首选中国商机服务平台,搜了网打造的发布信息,发布信息到3000多家网站,只需十分钟.它提供了强大的发布供求信息,发布信息反馈管理,商机搜索等功能,是企业推广,发布信息,供求信息发布的绝佳平台.自主建站,即时商机提供客户优质的商铺,更多的采购信息!

丹东通达科技有限公司丹东通达科技有限公司做为国内行业先锋企业,自成立以来就以专业的团队,专业的精神为客户提供先进的产品和优质的服务。为科研,商用等领域对于衍射分析,样品结构,定性定量等应用提供效率更高,性能更可靠的产品是我们一贯追求的目标。同时与各大院校以及国内顶尖科学家合作,不断升级产品,开发新产品以打破国际垄断,为社会造福,为用户创造价值。

上海索拓密封材料有限公司(www.chinesegasket.com)主营:奥地利TEADIT膨体四氟板,进口改性四氟板RPTFE,TEADIT四氟接口带,NA1002无石棉密封垫片,FDA认证盘根,TEALONTF1580改性四氟板,填充四氟板,TEADIT25BI带状垫片胶带,膨胀四氟胶带,24B四氟接口带,24SH膨体四氟板等产品,欢迎来电洽谈.

懂金融是金融知识科普网站,包括贷款、信用卡、理财、保险、股票、基金等金融领域的知识内容,更多金融知识尽在懂金融。

南京万厚中医医院开设重点科室有肝病科、中医科、肿瘤科,同时有中医治未病、体质检测、内病外治、冬病夏治、中医各种疑难杂症等,尤其在中医肿瘤的治疗上有着精深造诣,南京万厚中医医院是江苏省重点医院。

欢迎来到满分起名(www.manfenqiming.com)一个专注于姓名评分的网站,您可以轻松输入您想评分的姓名,并立即获得一个综合评分,无论您是为孩子起名、寻找一个适合的艺名,还是想要改名以改变自己的命运,满分起名都是您最可靠的姓名评分网站。

叽叽诗词网专注于经典唐诗宋词元曲古诗词三百首鉴赏,古诗三百首赏析,诗词名句,致力于让古诗词爱好者更方便地学习古诗词。

