与书对话 检索引擎 从字里行间邂逅心仪书籍 谷歌发布 (与书对话检索怎么做)
雷锋网 AI 科技评论按,今日,谷歌分享了 Semantic Experiences,在博客中展示了两大关于自然语言理解的互动工具。Talk to Books 是一个可以从书中的句子层面搜索书籍的全新检索模式;另一个互动内容则是 Semantris,一个由机器学习驱动的单词联想游戏。
地址:
雷锋网了解到,谷歌还发布了「通用语句编码器」(Universal Sentence Encoder),更加详细地呈现了上述示例所使用的模型;当然,谷歌还为开源社区提供了一个预训练的 TensorFlow 模型,开发者可以测试自己的句子及短语编码。
地址:
自然语言理解在近年已经有了极大进步,这得益于词向量(word vectors)的发展,这一技术使算法能根据实际语言使用的例子来学习单词之间的关系。这些向量模型根据概念和语言的等价性、相似性或关联性,将语义相似的词或短语投影到临近点。
谷歌拓展了在向量空间中表征语言(language)的构想,这一想法通过为像完整句子或段落为代表的较大语言块创建向量来实现。语言是由具有概念的层次结构组成的,因此团队采用模块的层次结构来构建向量,每一模块都要考虑与不同时间尺度序列所对应的特征。各种类型的关系,如关联、同/反义、部分/整体等都可以用向量空间语言表示。团队在论文《Efficient Natural Language Response for Smart Reply》有更多介绍。
论文地址:
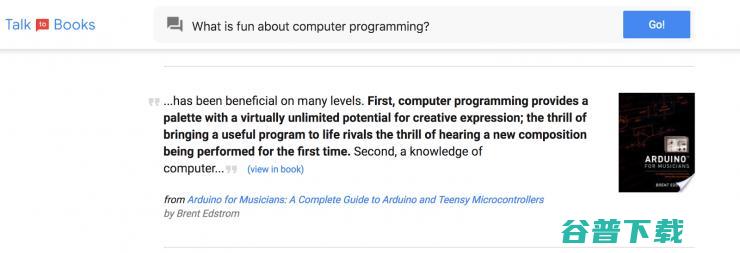
以往我们在检索书籍时,通常会从书名、作者、主题等表面标签入手。而谷歌发布的「Talk to Books」可以为用户提供一种检索书籍的全新方法。用户只需要做一段相关描述,或是提一个相关的问题,那么 Talk to Books 可以在不依赖关键词匹配的情况下,从超过 10 万本书籍中检索所有句子,并根据句子层面的语义,找到能匹配用户陈述或问题的句子。从某种意义上来说,Talk to Books 是一种用户与书「交谈」的新模式,系统给出的回答也能帮助用户确定自己是否对相关主题感兴趣。
模型在正式发布前经历了超十亿次的对话训练,以打磨更好的用户体验——对用户的提问或陈述给出更加合适的回答。这一方式相比起普通的谷歌检索,可能会帮助用户找到一些更有趣的书籍,特别是在关键字搜索中并不会显示的一些结果。
不过,这一模型还有更多的改进空间,比如搜索范围局限在句子层面上,而不是段落,因此可能会产生「断章取义」的情况。另外,因为只看某一句子的匹配程度,这也可能导致某些众所周知的、「符合口味」的书并不会出现在检索结果的前列。谷歌团队此举,更多的是希望帮助人们以一种新的探索方式,发现不曾料想过的作者和书名,竟然会有读者感兴趣的内容。
地址:
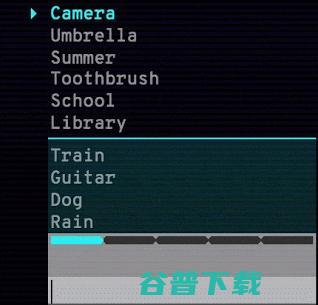
Semantris 是一个由相同技术驱动的单词联想游戏。屏幕上会呈现所有单词,用户可以输入某个单词,随即系统会根据屏幕上单词与用户输入单词的关联程度进行重新排序。不论是近义词、反义词还是相近概念,系统都能找到对应的排序模式。
如图所示,用户输入「Photo」时,最顶部的「Camara」因为与输入单词的关联最为紧密,因此会更替排序调整到第一位「消掉」。这确实是一个锻炼联想能力的好机会,此外还有限时模式和不限时模式供用户体验。
地址:
相信在这两个工具的驱动下,人工智能能够与用户更好地进行交互学习,并且帮助人类在现实生活中更好地理解科技,使用科技,并受惠于科技。更多资讯敬请关注雷锋网AI科技评论。
版权文章,未经授权禁止转载。详情见 转载须知 。



LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

众丛建筑,专注于农村别墅、私人自建房,为想建房的朋友们解决设计(建筑设计,室内设计,园林景观)、施工、室内修装等问题!服务专线:0731-8583353115874859961

玩具,卡通,F1

大纲古玩专门提供博物馆,古玩鉴定,文物鉴定,瓷器,古董,玛瑙,通宝最新资讯

深圳市成长建筑工程有限公司

骏通电力成立于2017年,在东莞的能源领域,专注建设、营运和维修保养,一直争当行业领先角色,雇员超过150人,产值额近亿元。骏通电力为发电供电、工商业企业和公共工程客户,提供涵盖建筑、电力、机电领域的全面服务,致力满足不同客户的特别需要。凭着对城市基础设施的深入掌握与落实能力,为客户从公共配电网到用电终端提供综合工程服务与解决方案,协助客户维持高可靠供电水平。

淄博钰铭磨料科技有限公司,我们致力于生产钢砂、钢丸已经26年,实现了生产设备及自动化流水线现代化。我们拥有专业的研发团队和优良的研发能力使我们能够生产高质量的:钢砂,钢丸,钢丝切丸等产品。

拓胜冷却设备有限公司专业从事水冷设备设计研发拥有核心技术,主要产品有封闭式冷却塔、玻璃钢冷却塔、横流塔、逆流塔、蒸发式冷凝器、空冷器、空压机冷却系统产品丰富。同时提供相关配件以及技术咨询。

新商纪,聚焦5G、AI人工智能、云计算、大数据等互联网科技驱动下的数字化商业创新及新潮生活,科技不仅是一种社会生产力,更是一种潮越平凡的生活态度。新科技、新商业、新趋势。

无需编程,快速开发A股、港股、ETF量化策略。提供策略集市、量化交易管理、资产配置等功能。通达信、大智慧等选股软件用户使用0门槛,快速升级为量化投资者。



好玩的涂色填色游戏免费下载有哪些,儿时,很多人都曾有过成为画手的梦想,可是因为一些原因,这个梦想没有实现,幸好,如今有许多涂色的游戏可以满足小时候的梦想,这类游戏简单有趣,只需要填充颜色即可,还能考验玩家对色彩的敏感度,1、,秘密花园,你将感受到一段动听的音乐,仿佛自己置身于一个绚丽多彩的花园,被自然界的美好和生机所包围,这个游戏提供...。

转眼19年就将翻篇,跨入2020,站长们私下也都在总结一年网站运营经验,预测明年搜索优化的方向,其中就有大佬对明年的搜索趋势做出了一个预判,站长们可以参考下,影响力过去的搜索,更多的是注重于具体的一个两个指标,而现在有一个趋势就是影响力营销,那些有影响力的人或者某个账号,背后可能有一个团队在运营,也可能是一个非常有创造力的有魅力的个人...。

大家好,我是电商沉楚,接下来我会从选品注意事项、选品思路、选品渠道两个方面为新手答疑解惑,1.选品注意事项把这点放在最前面,是因为许多小伙伴不清楚平台规则,盲目上架商品到底被平台惩罚,情节严重还会被封店,以下文章都是针对无货源商家提供的小建议,1,品牌类商品不要碰,品牌商品涉及到版权问题,容易被人举报,导致小店被封,2,主图上出现...。
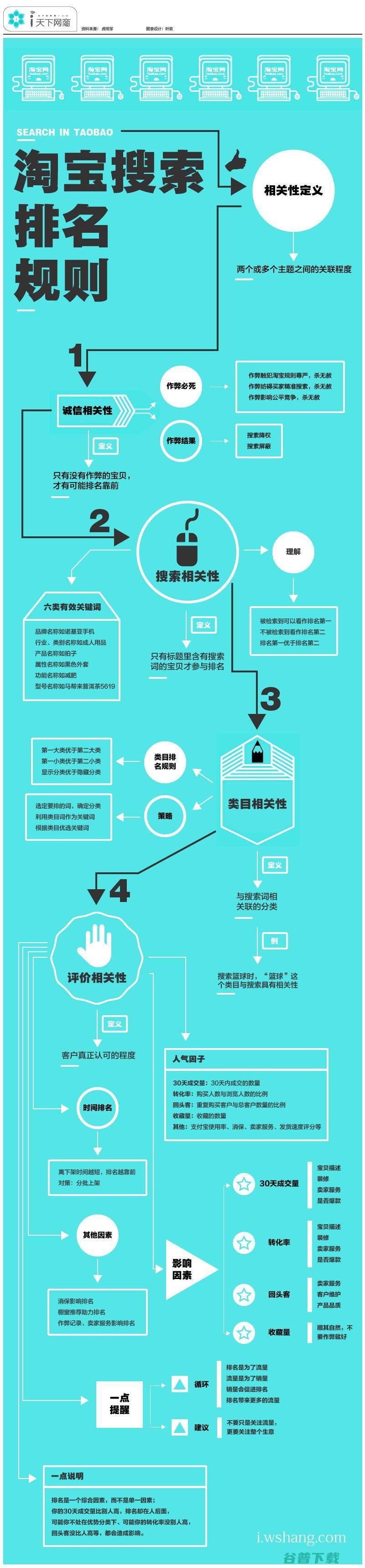
淘宝搜索规则的奥秘何在?有心人虎用军根据视频,淘宝搜索排名规则——相关性解读及其策略,整理出了详尽的思维导图,虽然不能完全代表淘宝搜索排名规则,但对于初级阶段的卖家来说,是不可多得的一份实战干货,天下网商视觉团队设计,图说淘宝搜索排名规则,注,此图仅供卖家学习交流,具体操作请以淘宝官方制定的淘宝搜索排名规则为准,点击看大图来源,卢...。
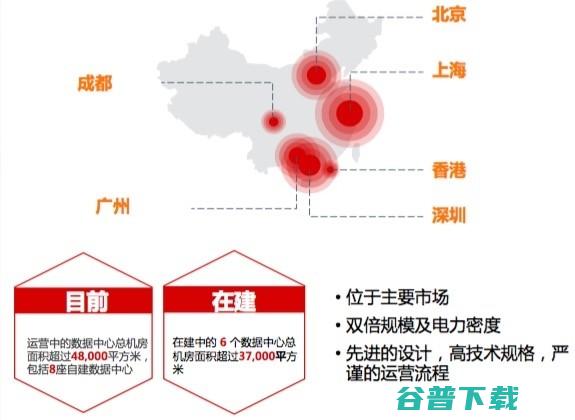
11月2日,创建15年的中国数据中心开发商和运营商万国数据宣布赴美上市,这是家什么样的数据公司,根据万国数据官方给出的数据,万国数据还指出,它家的数据中心是T3+级,主打高性能的数据中心,那么,什么是T3+级,科普一下,T3+数据中心比起普通的数据中心而言,在选址上要求更加严格,在地理位置均避开了地质灾害、自然灾害和社会风险的高危区域...。

7月19日,腾讯云在工业质检合作伙伴沙龙暨生态联盟发布会上,宣布升级发布工业质检训练平台TI,AOI2.3版本,并携手首批合作伙伴成立工业AI质检生态联盟,共同推动人工智能技术与实体产业深度融合,助力行业加快发展新质生产力,实现高质量发展,腾讯云副总裁、腾讯云智能产研负责人吴永坚表示,腾讯云在工业质检领域深耕多年,现已构建起包括工业质...。

各行各业都深谙数字技术的普惠价值,在这件事上,走在思想前列的我佛也不例外,最近少林寺方丈释永信现身Meta旧金山总部,线下分享,禅宗遇到AI,,让数字化的,朋友圈,,又颤抖了一把,在21世纪,古朴传统的佛门清净之地与炫酷现代的数字科技相结合,敢问还有什么奇观异景能比这更赛博朋克,寺庙数字化的话题被释永信带火后,各路网友实在按捺不住了,...。

大气低档的手机店名字解析若邻手机取自,天涯若比邻,,手机通信把身在各地的咱们咨询在一同,就象朝夕相伴的街坊一样,表现手机通信行业为人们带来的便利和其实质,名字有神韵和外延,更容易推行,先锋自动手机普通是年轻人和中高支出者的首选,他们是潮流的发明者和引领者,先锋这个十分有冲劲的名字,人造也和如今的年轻人十分合乎,可以惹起他们的共鸣,而且...。

电动汽车用动力蓄电池关键有铅酸电池、水电瓶、胶体免保养电池、三元锂电池、磷酸铁锂电池,以下是电动汽车用动力蓄电池的引见,1、种类,电动汽车经常使用的蓄电池关键有铅酸电池、水电瓶、胶体免保养电池、三元锂电池、磷酸铁锂电池,2、留意事项,因为低速电动四轮车的续航里程还是比拟有限不能齐全满足公众的日常出行需求假构想要参与其续航里程可以装上一...。

如题主想要了解的,西风流行f600发起机是国产还是出口的?,关系内容引见有以下,西风流行f600发起机是国产是沈阳三菱产的,合资的,1、这款车驳回的是2.0的发起机,觉得这个发起机能源十分好,开起来特意不错,另外就是这款车在急减速的时刻,觉得车子提速方面十分轻松,全体还是挺满意的,这款的操控性相当好,转向的手感也不错,开起来很轻松;2...。

458和488是法拉利旗下两款不一样的车型,两款车的能源、形状、内饰、售价都会有必定的差异,截至到2019年7月,法拉利458曾经片面停产,市面上在售的为488车型法拉利458搭载了一款4.5升人造吸气的8缸发起机,因此被称作,458,在458Italia的基础上进一步改善的空气能源学和电子辅佐系统让488GTB变成了一辆十分容易上...。

瑞星手机安全助手下载-瑞星手机安全软件安卓版下载,瑞星最新推出的安卓手机杀毒软件,提供查杀病毒、隐私保护、防骚扰、号码查询和手机优化五大功能,您可以免费下载安卓手机瑞星手机安全助手。

图片来源,http,sytycdism.com,play,sim,city,online.html所有者,sytycdism,2018年,自动驾驶、车路协同、飞行汽车......关于未来出行的话题热度只增不减,主机厂紧追自动驾驶潮流,抱团取暖;科技公司、新创企业依赖自身优势,研发新技术,快速抢滩未来出行市场,当自动驾驶已走过十余...。

从前靠天吃饭,现在知天而作,未来智慧务农,一、AI种植、40万元总预算本届比赛亮点多多2024年9月20日,2024年光明多多垂直农业挑战赛暨第四届,多多农研科技大赛,正式启动,在启动仪式上,上海市农业农村委员会党组成员、副主任、上海市乡村振兴局副局长夏明林先生表示,近年来,拼多多作为上海本土电商平台,在带动全国农产品销售、助力乡村...。

距离2022年结束还剩一个多月,几十个江浙沪的芯片猎头,突然都聚集到了上海张江美满电子,Marvell,中国总部的楼下,想多认识几个被美满裁掉的员工,就连遇到在美满楼下散步的人也要问上一嘴,您是不是美满员工,从美满离职的人我要认真聊一聊,芯片猎头欣怡知道美满是少有的在中国有核心研发团队的芯片外企,,这次裁员的规模让人震惊,美满多...。

11月26日,中国市场监管报记者从广西壮族自治区人民政府新闻办公室召开的,广西市场监管部门推行有温度的执法,助推经济社会高质量发展,新闻发布会上获悉,自今年7月推行有温度的执法新模式以来,广西市场监管系统编制办事指南1.4万件,服务经营主体10万户次,确立15方面共158项包容审慎监管措施,适用不予处罚、从轻处罚、减轻处罚案件累计1....。

最新方法怎么看电视台,只需要在电视上装一个当贝市场就可以轻松解决,1、下载当贝市场,http,www.dangbei.com,安装包并拷贝到U盘,2、打开东芝电视,按下遥控器的设置键,打开设置界面,点击,更多设置,3、在设置界面找到,通用,选择,商场模式,,把商场模式改为,开启,状态,4、成功开启以后,把U盘接到电视的USB接口...。
