最佳学生论文官方解读! CVPR 2019 (最佳学生论文奖)
作为人类感知世界、进行交互的两大最重要的方式,视觉和语言一直是人工智能领域研究的重点。近年来,将视觉与语言信息进行融合和转化成为了一个活跃的研究方向,许多让人眼前一亮的工作也随之产生。微软研究院在文本中,对其获得 CVPR 2019 最佳学生论文的工作进行了技术解析,非常值得一读!
人类如何进行高效的沟通呢?人们普遍认为,人类用来交流的词语(例如「狗」)会引发对物理概念的相似理解。实际上,我们对于狗的物理外形、发出的声音、行走或奔跑的方式等都有共同的概念。换句话说,自然语言与人类与他们所处的环境之间的交互方式息息相关。因此,通过将自然语言基标对准到我们所处环境的各种模态中(例如图像、动作、物体、声音等),可以产生有意义的行为。心理学领域最新的研究成果表明,婴儿最可能学会的第一个单词是基于其视觉体验的,这为婴儿语言学习问题的新理论奠定了基础。那么现在问题来了:我们是否能够构建出可以像人类一样,学着在不同模态下进行沟通的智能体?
在各种多模态学习任务中,视觉-语言导航(VLN)是一类十分有趣也极具挑战性的任务。这是因为,为了能够以遵循自然语言指令的方式对真实环境中的智能体进行导航,我们需要执行两层基标对准:将指令基标对准到局部空间视觉场景中,然后将指令与全局时序视觉轨迹相匹配。最近,深度神经网络领域的工作重点关注于通过在视觉上基标对准语言学习任务,来连通视觉和自然语言理解的桥梁,从而构建智能体,这要求研究人员具备机器学习、计算机视觉、自然语言处理以及其它领域的专业知识。
对于这种基标对准任务而言,深度学习技术非常具有使用前景,这是因为使用深度学习技术能够使得同时从计算机视觉和语言的低级感知数据中学习到高级语义特征成为可能。此外,深度学习模型也使我们可以将不同模态的信息融合到同一种表征中。基础语言学习任务还要求与某个外部环境进行交互;因此,强化学习为我们提供了一种优雅的框架,能够基于视觉层面来完成对话任务规划。所有这些研究进展使得解决具有挑战性的 VLN 任务在技术上可行。

图 1:视觉语言导航(VLN)任务示意图。图中展示了指令、局部视觉场景,以及从俯视视角描绘的全局轨迹。智能体并不能获取俯视图信息。路径 A 是遵循指令得到的正确展示路径。路径 B 和 C 代表智能体执行出的两条路径。
微软研究院的视觉和语言研究人员一直致力于研究对自然语言和视觉交互进行基标对准的各种不同的方法,并一直在应对 VLN 所特有的挑战。CVPR 2019 中,由微软 AI 研究院的 Qiuyuan Huang、Asli Celikyilmaz、Lei Zhang、Jianfeng Gao,加州大学圣巴巴拉分校的王鑫、Yuan-Feng Wang、王威廉,以及杜克大学的 Dinghan Shen 共同完成的工作「Reinforced Cross-Modal Matching and SELF-Supervised Imitation Learning for vision-Language Navigation」获得了最佳学生论文,微软的 VLN 研究团队在本论文中探索了 解决 VLN 领域这三个关键挑战的方案:跨模态基标对准(cross-modal grounding)、不适定反馈(ill-posed feedback)以及泛化(generalization)问题 。不仅如此,这项工作所取得的好结果非常激动人心!
其中的一个挑战是,根据视觉图像和自然语言指令进行推理。如图 1 所示,为了到达目的地(用黄色圆圈高亮表示),智能体需要将用单词序列表征的指令对标到局部的视觉场景中,并且将指令与全局时序空间中的视觉轨迹匹配起来。为了解决这个问题,我们提出了一种新的强化跨模态匹配(RCM)方法,它可以通过强化学习在局部和全局进行跨模态基础标对。
如图 2a 所示,我们的研究团队设计了一个带有两种奖励函数的推理导航器。外部奖励会指导智能体学习文本指令和局部视觉场景之间的跨模态基础对标,从而使智能体可以推测出要关注的子指令以及相应的视觉内容。同时,从全局的角度来看,内部奖励和匹配评价器一起,通过根据执行的路径重建原始指令的概率来评估一个执行路径,我们将其称为「循环重建」奖励。
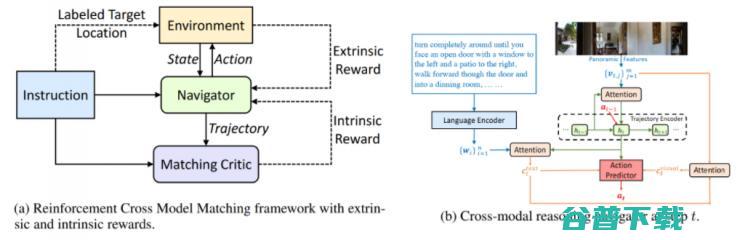
图 2:用于将自然语言指令与视觉环境对标的强化跨模态匹配框架。
该内部奖励对于这种 VLN 任务尤为重要;如何训练这些智能体,以及从它们的环境中获取反馈是VLN 研究人员面临的重大挑战。在训练时,学习遵循专家展示需要频繁的反馈,从而使智能体可以保持在正确的轨迹上,并且按时到达目的地。然而,在 VLN 任务中,反馈是非常粗糙的,因为只有当智能体到达了某个目标位置后才会提供「成功」的反馈,完全没有考虑智能体是否遵循了指令(如图 1 中的路径 A 所示),或者是按照随机的路径到达了目的地(如图 1 中路径 C 所示)。如果智能体稍微比预计时间停止得早了一些(如图 1 中的路径 B 所示),即使与指令相匹配的「好」轨迹也可能被认为是「不成功」的。这样的话,不适定反馈可能会与最优策略学习的结果不符。
如图 2a 和 2b 所示,我们提出通过局部测量一个循环重建奖励来评价智能体遵循指令的能力;这种机制能够提供一种细粒度的内部奖励信号,促使智能体更好地理解语言输入,并且惩罚与指令不匹配的轨迹。举例而言,如图 1 所示,使用我们提出的奖励,路径 B 就会被认为优于路径 C。
使用匹配评价器提供的内部奖励以及环境提供外部奖励进行训练,我们的推理导航器会学着将自然语言指令同时在局部空间视觉场景和全局时序视觉轨迹进行基标对准。在一个 VLN 对比基准数据集上的评估结果显示,我们的 RCM 模型在 SPL(通过逆路径长度加权的成功率)指标上显著优于之前的方法,提升高达 10%,实现了目前最佳的模型性能。
当处于训练时未曾见过的环境中时,VLN 智能体的性能会显著降低。为了缩小这种差距,我们提出了一种通过自监督学习探索未见过的环境的有效解决方案。通过这种新技术,我们可以促进终身学习以及对新环境的适应。例如,家用机器人可以探索一个新的房子,然后通过学习之前的经验迭代式地改进导航策略。受到这一事实的启发,我们引入了一种自监督模仿学习机制(SIL)来支持智能体对未见过的环境(没有带标签的数据)进行探索。其中,智能体会学习自己过去积极的经验。
具体而言,在我们的框架中,导航器将执行多次「roll-out」策略,其中好的轨迹(由匹配评价器确定)将会被保存在经验回放缓存中,然后被导航器用于模仿。通过这种方式,当行器可以对其最佳行为进行近似,从而得到更好地策略。我们能够证明 SIL 可以近似得到一个更好、更高效的策略,这极大地缩小了训练时见过和未曾见过的环境之间的成功率的性能差异(从 30.7% 降低到 11.7%)。
非常荣幸,这篇论文被选为了 CVPR 2019 的最佳学生论文。用 CVPR 2019 最佳论文奖组委会的话来说,就是「视觉导航是计算机视觉的一个重要领域,而这篇论文在视觉-语言导航方面取得了进展。在该领域之前工作的基础上,该论文在跨模态环境下基于自模仿学习所取得的成果令人激动!」热烈祝贺这篇论的作者们:来自加州大学圣巴巴拉分校的王鑫、Yuan-Fang Wang、王威廉,来自微软 AI 研究院的 Qiuyuan Huang、Asli Celikyilmaz、Lei Zhang、Jianfeng Gao, 以及来自杜克大学的 Dinghan Shen。其中,王鑫对这一工作所做的贡献是其在微软研究院实习期间完成的。
在另外一篇 CVPR 2019 论文「Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation」(由微软 AI 研究院的 Xiujun Li和 Jianfeng Gao,华盛顿大学的 Liyiming Ke、Yonatan Bisk、Ari Holtzman、Yejin Choi、Siddhartha Srinivasa,以及微软 Dynamics AI 的 Zhe Gan 和 Jingjing Liu 共同完成)中,我们改进了 VLN 智能体的搜索方法,提出了一个被称为「快速导航器」(Fast Navigator)的动作编码的通用框架,使智能体能够基于局部和全局的信息比较长度不同的部分路径,并且在出错时进行回溯。
我们注意到,VLN 与文本生成任务有一些相似之处,所有现有的工作可以被分为两类:
总的来说,当前的 VLN 模型面临着两大核心问题:首先,我们应该回溯吗?如果我们应该回溯,那么我们应该回溯到哪一步呢?其次,我们应该在何时停止搜索?
为了使智能体能够在出错时进行回溯,我们将搜索与神经编码结合了起来,从而使得智能体可以基于局部和全局信息比较长度不同的部分路径,然后在发现错误时进行回溯。为了确定我们是否应该停止搜索,我们使用了一个融合函数,该函数会将局部动作知识和历史转化为一个进度的估计值,从而通过对我们之前的动作与给定的文本指令的匹配程度建模来评估智能体的进度。
via
原创文章,未经授权禁止转载。详情见 转载须知 。



长空七七

吉林省抗衰老学会,吉林省抗衰老学会,吉林省抗衰老学会

深圳市南山区美梦加陶瓷经营部--美白陶产品

南方人才网(job168.com)是广州人才集团官方唯一人才网,提供最新最全的人才职位招聘信息。主营人才招聘、人才培训、猎头、网络招聘、报纸招聘、薪酬调查、档案挂靠等服务。南方人才招聘网月发布职位信息高达48万条,日均页面浏览量超1000万,是华南最具影响力的人力资源网站。

高清壁纸网分享高清4K电脑桌面,精选美女壁纸、风景壁纸、8K壁纸、动物壁纸等手机壁纸图片。

数坤科技是行业领先的智慧医疗健康科技平台,坚持用原创、先进的技术为医疗健康行业提供智慧解决方案及产品。

欢迎访问Wefatherm微法中国网站。始于1988年,微法PPR水管进入中国已超过10年。总部位于德国文斯托夫,专注环保健康的品质PPR管道,守护您的生命之源。

金桔云创是一家以多年沉淀的“三农”行业数据、行业经验、行业资源为支点,专注农业、深耕场景,应用互联网+物联网、供应链+区块链技术(双网双链),打造标准化、低成本、高品质的供应链生态圈,建设成为“双网双链”的新零售大农业产业互联网B2B平台。

中国鲜花速递、鲜花店、花店、上海鲜花店、北京鲜花店、重庆鲜花店、广州鲜花店、成都鲜花店、大连花店、天津花店、武汉花店、西按花店、青岛花店、深圳花店、东莞花店、重庆花店、长沙花店、昆明花店、郑州花店、ChineseFlorist、flower

易查分学生成绩发布网可以使用学生成绩Excel电子表格三分钟建立自己的成绩发布系统,支持微信公众号查分,在线使用,无需下载源代码,无需下载易查分APP

惠州市天奕文化传播有限公司是主营惠州及华南地区各类公关活动,礼仪庆典,灯光音响舞台,演艺活动,演员输出,演出设备及礼仪庆典设备活动物料租赁,广告制作为一体的综合性活动服务公司

江苏安脉科技有限公司


文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为锐利广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在锐利广告联盟网站首页底部或友情链接位...。

这次我们比上一代产品提前了5、6周的时间发布,从12月份提到了10月底,目前为止一加13在体验上是历年来旗舰最高的水准,一加中国区总裁李杰对说到,10月的最后一天,一加13正式发布,作为一加品牌新旗舰之作,其在性能、屏幕、影像、续航等方面都进行了全面升级,展现出,样样超Pro,的实力,对一加来说,无论是产品还是这一年,都有着非...。

发表在专业问答2022,2,1813,46展示机型信息,品牌型号,极米A3激光电视系统版本,INUI1.3极米A3激光电视可以通过HDMI或者SPDIF接口连接功放,以下是极米A3激光电视连接功放的操作步骤,极米A3激光电视怎么连接功放1.连接功放设备将SPDIF音频连接到投影仪和功放设备上;2.选择声音输出长按遥控器菜单键打开系统设...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为恒盛广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在恒盛广告联盟网站首页底部或友情链接位...。

12月11日,泡泡玛特,上市首日收涨79.22%,股价开盘翻倍,市值超1100亿港元,这背后得益于三个因素,年轻人、IP以及盲盒,泡泡玛特以年轻化产品以及表达方式,获得了年轻人的关注和喜爱,并成功出圈,范围扩大至新消费市场,近年来,随着消费场景及内外部环境的转变,,年轻化,成为各大品牌绕不开的话题,大家都在寻求更符合当代用户习惯的产...。

每一款阅读器都有自己的不同阅读器的特点和优势,可以依据自己的需求启动取舍,会让咱们更好地利用阅读器,提高咱们的办公和学习效率,一、谷歌阅读器二、多御阅读器三、360加快阅读器X最好阅读器排行,十大最洁净阅读器,1.谷歌阅读器2.火狐阅读器阅读器阅读器阅读器阅读器阅读器9.傲游云阅读器阅读器首先火狐阅读器官网版是一款驳回了新一代引擎启动...。

首先,星座是按公历,阳历,来启动运算的.分为十二个星座,[face][,face]星相学的由来星相学,或称占星术,ASTROLOGY,,是星相学家观测天体,日月星河的位置及其各种变动后,作出解释,来预测人人世的各种事物的一种方术,星相学以为,天体,尤其是行星和星座,都以某种因果性或非偶然性的方式预示人世万物的变动,星相学的实践基础存在...。

人总是特意贪心,既想体验未知的惊喜,也想延迟预报未来的变数,等候绝处逢生,特意是女人,只管骨子里会通知自己,姐才不会置信这些老太太才置信的物品呢,可是,许多时刻还是忍不住上庙堂去求上一卦,关于如此异想天开的动物,她们相对不会放过自己身材的每一寸痕迹,经过全身痣相图解大全来探测自己的命运,其实也理所应当,由于,迷信不迷信其实并不关键,关...。

网络是经过电信设备和互联网技术衔接各种计算机、主机、终端设备等,在世界范畴内传递消息的一种基础设备,在网络中,消息是经过数据包启动传递的,详细来说,当咱们经常使用计算机、自动手机等设备上网时,设备会将咱们的恳求转化为数据包,并经过网络中的路由器、替换机等设备启动传输,直到抵达指标设备,在传输环节中,数据包或者经过多个中转节点,每个节点...。

雷克萨斯是丰田旗下的奢侈汽车品牌,在世界上流汽车市场上不时备受关注和追捧,作为该品牌旗下的顶级轿车,LS600h仰仗其出色的奢侈感和出色的性能而成为了很多顶级社交场所的代名词,1.外观设计LS600h的外观设计充溢了现代感,前脸的大气格栅和尖利的LED日间行车灯,让人看到此车就会感到震撼,车身线条流利,设计柔美,并搭载20英寸的铝合金...。

全时云会议PC客户端是全时云商务服务股份有限公司基于云计算架构开发的网络视频会议产品,提供电话与VoIP融合,6路视频共享,桌面、文档、白板共享

秋日穿搭别太老气,掌握三个“小思路”,减龄俏皮又高级,西裤,高腰,减龄,短裙,版型,秋日穿搭,身材比例

5月28日,腾讯董事会主席兼首席执行官马化腾在贵阳举行的2018年中国国际大数据产业博览会,数字经济,高端对话的论坛上表示,腾讯现在在不断做减法,为其他伙伴提供平台,而不是抢对方饭碗,他希望和其他伙伴共建数字生态,他表示,以前我们被别人说是帝国心态,比较封闭,七年前,我们意识到一举一动已经影响整个业界,心态开始放开,做了很大改变,走...。

近年来,微信已深度融入我们的日常生活,但随之而来的安全风险亦不容忽视。我们时常收到诸如手机验证码、登录提醒等微信安全通知,然而,你是否曾想过如何查看这些提醒的记录呢?接下来,本文将为你详细介绍微信安全提醒记录的查看方法。

扫地机器人代理的可观,现在的市场发展潜力大,是很多的家庭已经办公场所等都需要的,自从正式推出以后,就受到了大家的认可,有着强大的市场优势,扫地机器人的总部有着先进的科研团队,对机器人的研发是非常专业的,机器人一经推出,便受到了顾客的喜欢,有着很高的销量,扫地机器人的投入小开店快,是一个性价比高的项目,开店一定错不了,扫地机器人的实力强...。

龟苓膏是一很常见的美食,海天堂的龟苓膏出来味道足,吃起来可口,也是一种美容解渴,更是可以夏天可以当降火的补品,因此受到了广大消费者的喜爱,很多加盟商选择海天堂龟苓膏加盟,今天小编就给大家介绍一下海天堂龟苓膏加盟怎么样,那么海天堂龟苓膏加盟怎么样呢,随着天气越来越热了,海天龟苓膏的销量也在逐渐上升,听同事介绍说海天堂的龟苓膏很正宗,下火...。

素质教育的推行,很多的孩子多多少少都学习了一项兴趣爱好,可以丰富自己的生活,也可以提高个人综合素质,在周末的时候,孩子学习的兴趣班有很多,比如大家都常常学习的有,书法、舞蹈、武术、口才、美术等等,课程的种类多,能够满足不同孩子的需求,其中朵朵兔快乐艺术也是一个连锁的教育机构,一些创业者想要了解,加盟朵朵兔快乐艺术门槛高吗,朵朵兔快乐艺...。
