轻松进行自监督学习 BYOL (可以自我监督的软件)
译者:AI研习社( 季一帆 )
双语原文链接: Easy Self-Supervised Learning with BYOL
自监督学习
在中,经常遇到的问题是没有足够的标记数据,而手工标记数据耗费大量时间且人工成本高昂。基于此,自我监督学习成为深度学习的研究热点,旨在从未标记样本中进行学习,以缓解数据标注困难的问题。子监督学习的目标很简单,即训练一个模型使得相似的样本具有相似的表示,然而具体实现却困难重重。经过谷歌这样的诸多先驱者若干年的研究,子监督学习如今已取得一系列的进步与发展。
在BYOL之前,多数自我监督学习都可分为对比学习或生成学习,其中,生成学习一般GAN建模完整的数据分布,计算成本较高,相比之下,对比学习方法就很少面临这样的问题。对此,BYOL的作者这样说道:
为了实现对比方法,我们必须将每个样本与其他许多负例样本进行比较。然而这样会使训练很不稳定,同时会增集的系统偏差。BYOL的作者显然明白这点:
不仅仅是颜色失真,其他类型的数据转换也是如此。一般来说,对比训练对数据的系统偏差较为敏感。在机器学习中,数据偏差是一个广泛存在的问题(见 facial recognition for women and minorities ),这对对比方法来说影响更大。不过好在BYOL不依赖负采样,从而很好的避免了该问题。
BYOL:Bootstrap Your Own Latent(发掘自身潜能)
BYOL的目标与对比学习相似,但一个很大的区别是,BYOL不关心不同样本是否具有不同的表征(即对比学习中的对比部分),仅仅使相似的样品表征类似。看上去似乎无关紧要,但这样的设定会显著改善模型训练效率和泛化能力:
BYOL最小化样本表征和该样本变换之后的表征间的距离。其中,不同变换类型包括0:平移、旋转、模糊、颜色反转、颜色抖动、高斯噪声等(我在此以图像操作来举例说明,但BYOL也可以处理其他数据类型)。至于是单一变换还是几种不同类型的联合变换,这取决于你自己,不过我一般会采用联合变换。但有一点需要注意,如果你希望训练的模型能够应对某种变换,那么用该变换处理训练数据时必要的。
首先是数据转换增强的编码。BYOL的作者定义了一组类似于SimCLR的特殊转换:
| import randomfrom typing import CalLable, Tuplefrom kornia import augmentation as augfrom kornia import filtersfrom kornia.geometry import transform as tfimport torchfrom torch import nn, Tensorclass RandomApply(nn.Module):def __init__(self, fn: Callable, p: float):super().__init__()self.fn = fnself.p = pdef forward(self, x: Tensor) -> Tensor:return x if random.random() > self.p else self.fn(x)def default_augmentation(image_size: Tuple[int, int] = (224, 224)) -> nn.Module:return nn.Sequential(tf.Resize(size=image_size),RandomApply(aug.ColorJitter(0.8, 0.8, 0.8, 0.2), p=0.8),aug.RandomGrayscale(p=0.2),aug.RandomHorizontalFlip(),RandomApply(filters.GaussianBlur2d((3, 3), (1.5, 1.5)), p=0.1),aug.RandomResizedCrop(size=image_size),aug.Normalize(mean=torch.tensor([0.485, 0.456, 0.406]),std=torch.tensor([0.229, 0.224, 0.225]),),) |
上述代码通过实现数据转换,这是一个基于 PyTorch 的可微分的计算机视觉开源库。当然,你可以用其他开源库实现数据转换扩充,甚至是自己编写。实际上,可微分性对BYOL而言并没有那么必要。
接下来,我们编写编码器模块。该模块负责从基本模型提取特征,并将这些特征投影到低维隐空间。具体的,我们通过wrapper类实现该模块,这样我们可以轻松将BYOL用于任何模型,无需将模型编码到脚本。该类主要由两部分组成:
特征抽取,获取模型最后一层的输出。
映射,非线性层,将输出映射到更低维空间。
特征提取通过hooks实现(如果你不了解hooks,推荐阅读我之前的介绍文章 How to Use PyTorch Hooks )。除此之外,代码其他部分很容易理解。
| from typing import Uniondef mlp(dim: int, projection_size: int = 256, hidden_size: int = 4096) -> nn.Module:return nn.Sequential(nn.Linear(dim, hidden_size),nn.BatchNorm1d(hidden_size),nn.ReLU(inplace=True),nn.Linear(hidden_size, projection_size),)class EncoderWrapper(nn.Module):def __init__(self,model: nn.Module,projection_size: int = 256,hidden_size: int = 4096,layer: Union[str, int] = -2,):super().__init__()self.model = modelself.projection_size = projection_sizeself.hidden_size = hidden_sizeself.layer = layerself._projector = Noneself._projector_dim = Noneself._encoded = torch.empty(0)self._register_hook()@propertydef projector(self):if self._projector is None:self._projector = mlp(self._projector_dim, self.projection_size, self.hidden_size)return self._projectordef _hook(self, _, __, output):output = output.flatten(start_dim=1)if self._projector_dim is None:self._projector_dim = output.shape[-1]self._encoded = self.projector(output)def _register_hook(self):if isinstance(self.layer, str):layer = dict([*self.model.named_modules()])[self.layer]else:layer = list(self.model.children())[self.layer]layer.register_forward_hook(self._hook)def forward(self, x: Tensor) -> Tensor:_ = self.model(x)return self._encoded |
BYOL包含两个相同的编码器网络。第一个编码器网络的权重随着每一训练批次进行更新,而第二个网络(称为“目标”网络)使用第一个编码器权重均值进行更新。在训练过程中,目标网络接收原始批次训练数据,而另一个编码器则接收相应的转换数据。两个编码器网络会分别为相应数据生成低维表示。然后,我们使用多层感知器预测目标网络的输出,并最大化该预测与目标网络输出之间的相似性。
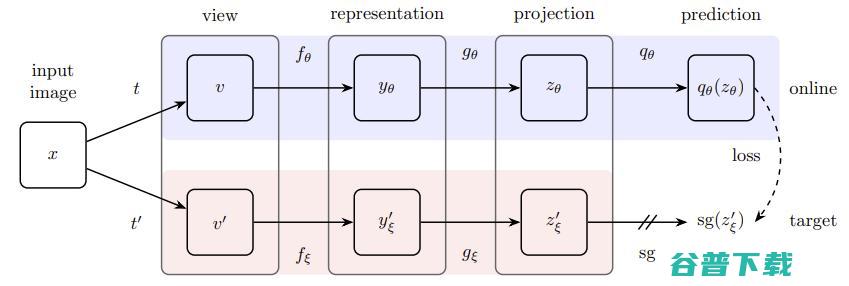
图源: Bootstrap Your Own Latent
也许有人会想,我们不是应该直接比较数据转换之前和之后的隐向量表征吗?为什么还有设计多层感知机?假设没有MLP层的话,网络可以通过将权重降低到零方便的使所有图像的表示相似化,可这样模型并没有学到任何有用的东西,而MLP层可以识别出数据转换并预测目标隐向量。这样避免了权重趋零,可以学习更恰当的数据表示!
训练结束后,舍弃目标网络编码器,只保留一个编码器,根据该编码器,所有训练数据可生成自洽表示。这正是BYOL能够进行自监督学习的关键!因为学习到的表示具有自洽性,所以经不同的数据变换后几乎保持不变。这样,模型使得相似示例的表示更加接近!
接下来编写BYOL的训练代码。我选择使用 Pythorch Lightning 开源库,该库基于PyTorch,对项目非常友好,能够进行多GPU培训、实验日志记录、模型断点检查和混合精度训练等,甚至 在cloud TPU上也支持基于该库运行PyTorch模型 !
| from copy import deepcopyfrom itertools import chainfrom typing import Dict, Listimport pytorch_lightning as plfrom torch import optimimport torch.nn.functional as fdef normalized_mse(x: Tensor, y: Tensor) -> Tensor:x = f.normalize(x, dim=-1)y = f.normalize(y, dim=-1)return 2 - 2 * (x * y).sum(dim=-1)class BYOL(pl.LightningModule):def __init__(self,model: nn.Module,image_size: Tuple[int, int] = (128, 128),hidden_layer: Union[str, int] = -2,projection_size: int = 256,hidden_size: int = 4096,augment_fn: Callable = None,beta: float = 0.99,**hparams,):super().__init__()self.augment = default_augmentation(image_size) if augment_fn is None else augment_fnself.beta = betaself.encoder = EncoderWrapper(model, projection_size, hidden_size, layer=hidden_layer)self.predictor = nn.Linear(projection_size, projection_size, hidden_size)self.hparams = hparamsself._target = Noneself.encoder(torch.zeros(2, 3, *image_size))def forward(self, x: Tensor) -> Tensor:return self.predictor(self.encoder(x))@propertydef target(self):if self._target is None:self._target = deepcopy(self.encoder)return self._targetdef update_target(self):for p, pt in zip(self.encoder.parameters(), self.target.parameters()):pt.data = self.beta * pt.data + (1 - self.beta) * p.data# --- Methods required for PyTorch Lightning only! ---def configure_optimizers(self):optimizer = getattr(optim, self.hparams.get("optimizer", "Adam"))lr = self.hparams.get("lr", 1e-4)weight_decay = self.hparams.get("weight_decay", 1e-6)return optimizer(self.parameters(), lr=lr, weight_decay=weight_decay)def training_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x = batch[0]with torch.no_grad():x1, x2 = self.augment(x), self.augment(x)pred1, pred2 = self.forward(x1), self.forward(x2)with torch.no_grad():targ1, targ2 = self.target(x1), self.target(x2)loss = torch.mean(normalized_mse(pred1, targ2) + normalized_mse(pred2, targ1))self.log("train_loss", loss.item())return {"loss": loss}@torch.no_grad()def validation_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x = batch[0]x1, x2 = self.augment(x), self.augment(x)pred1, pred2 = self.forward(x1), self.forward(x2)targ1, targ2 = self.target(x1), self.target(x2)loss = torch.mean(normalized_mse(pred1, targ2) + normalized_mse(pred2, targ1))return {"loss": loss}@torch.no_grad()def validation_epoch_end(self, outputs: List[Dict]) -> Dict:val_loss = sum(x["loss"] for x in outputs) / len(outputs)self.log("val_loss", val_loss.item()) |
上述代码部分源自Pythorch Lightning提供的示例代码。这段代码你尤其需要关注的是training_step,在此函数实现模型的数据转换、特征投影和相似性损失计算等。
实例说明
下文我们将在 STL10数据集 上对BYOL进行实验验证。因为该数据集同时包含大量未标记的图像以及标记的训练和测试集,非常适合无监督和自监督学习实验。STL10网站这样描述该数据集:
通过 Torchvision 可以很方便的加载STL10,因此无需担心数据的下载和预处理。
| from torchvision.datasets import STL10from torchvision.transforms import ToTensorTRAIN_DATASET = STL10(root="data", split="train", download=True, transform=ToTensor())TRAIN_UNLABELED_DATASET = STL10(root="data", split="train+unlabeled", download=True, transform=ToTensor())TEST_DATASET = STL10(root="data", split="test", download=True, transform=ToTensor()) |
同时,我们使用监督学习方法作为基准模型,以此衡量本文模型的准确性。基线模型也可通过Lightning模块轻易实现:
| class SupervisedLightningModule(pl.LightningModule):def __init__(self, model: nn.Module, **hparams):super().__init__()self.model = modeldef forward(self, x: Tensor) -> Tensor:return self.model(x)def configure_optimizers(self):optimizer = getattr(optim, self.hparams.get("optimizer", "Adam"))lr = self.hparams.get("lr", 1e-4)weight_decay = self.hparams.get("weight_decay", 1e-6)return optimizer(self.parameters(), lr=lr, weight_decay=weight_decay)def training_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x, y = batchloss = f.cross_entropy(self.forward(x), y)self.log("train_loss", loss.item())return {"loss": loss}@torch.no_grad()def validation_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x, y = batchloss = f.cross_entropy(self.forward(x), y)return {"loss": loss}@torch.no_grad()def validation_epoch_end(self, outputs: List[Dict]) -> Dict:val_loss = sum(x["loss"] for x in outputs) / len(outputs)self.log("val_loss", val_loss.item()) |
可以看到,使用Pythorch Lightning可以方便的构建并训练模型。只需为训练集和测试集创建
DataLoader
对象,将其导入需要训练的模型即可。本实验中,epoch设置为25,学习率为1e-4。
|
from os import cpu_countfrom torch.utils.data import>经训练,仅通过一个非常小的模型ResNet18就取得约85%的准确率。但实际上,我们还可以做得更好!
接下来,我们使用BYOL对ResNet18模型进行预训练。在这次实验中,我选择epoch为50,学习率依然是1e-4。注:该过程是本文代码耗时最长的部分,在K80 GPU的标准Colab中大约需要45分钟。
|




重庆市物业管理协会是由重庆市物业管理和城市、社区服务等相关企业、事业单位自愿结成的地方性、非营利性社会组织,是依法注册登记的行业性社会团体法人;经重庆市民政局批准,于1998年成立

乐堡AI论文-30分钟搞定一个班级,批量生成,批量调整格式,为毕业生提供专业的AI论文生成提供各类论文相关的服务和帮助,包括但不限于论文的撰写、修改、查重、降重等。

中国原创歌词音乐网基地提供最新、最热、最流行的在线音乐网-致力于打造最专业的歌曲大全,原创音乐,原创歌曲,原创歌词,填词,写歌词,作曲,编曲,伴奏,诗词,翻唱网,伴奏网,歌词找歌名,歌词搜索歌曲等原创歌词音乐网站!

梵希奴(昆明)服装定制|电话13888780072,专业订做西服|礼服|职业装|商务女装|衬衫,款式多面料全,一件可定,上门量体,为您定制专属服装.

重庆洁洛环保科技有限公司是一家专注于污水治理产品的研发、生产、批发的高科技企业。公司主要生产销售:聚丙烯酰胺(PAM),聚合氯化铝(PAC),醋酸钠,工业葡萄糖,葡萄糖酸钠,柠檬酸,草酸,片碱,纯碱,活性炭,COD去除剂等多种药剂。产品广泛用于:洗砂、洗煤、造纸、酿酒、食品、屠宰、养殖、制药、电镀、纺织印染、市政污水处理、工业污水处理等行业领域。

诠摄汇网是中国摄影家协会旗下中国摄影报社新媒体平台,这是诠释摄影的平台,这是汇聚摄影人的平台。这里参加全国摄影展,观看摄影视频,收听摄影段子,发布摄影作品,举办个人影展。我们的宗旨是好玩、好用、好快乐!

音频网(yinpin.com),专业音频制作公司,音频网咨询电话:400-700-9100,为您提供专业音频制作、音频录音、音频制作、音频制作服务,包括广告音频制作、宣传片音频制作、专题片音频制作、解说词音频制作。音频网,专业音频制作。音频,音频网,音频网站,音频制作
集团")
乐开(LEOKEY)是一家以科技赋能经营性地产、物业、酒店、文旅的物联网国家高新技术企业,专注于通过技术创新和数字化服务,帮助经营性物业与终端消费者,实现面向未来的生活与内容服务的数字化改造。

衢州市顺风广告标识标牌制造有限公司是一家标识标牌生产厂家,主营雕塑、金属标牌、制作标牌、标识标牌制作、标牌标识制作、标识牌制作、LED发光字制作、迷你发光字等,产品价格优惠,广受客户好评,业务覆盖全国,主要覆盖浙江衢州、杭州、金华、丽水、上海、安徽、江西等地。

华视星光明星经纪公司是明星营销一站式合作平台,专业从事明星代言、明星商演、明星翻包、明星祝福语视频录制等明星经纪服务,并提供明星商务合作报价。

有晨心记录

淄博山分分析仪器有限公司(www.sfsepu.com)作为棒状薄层色谱仪厂家及原油四组分分析仪厂家,主营原油四组分分析仪,国产棒状薄层色谱仪,沥青四组分分析仪等产品,公司是集研发生产销售于一体的高科技有限公司,将多年来在色谱技术方面的科研成果转化成科技产品并不断发展和提高


川菜具有麻辣鲜香的特点,菜品丰富、营养均衡,是一种男女老少皆宜的健康美食,在餐饮市场上广受消费者的喜爱,有红鸡毛店川菜是一家专注于健康产品研发和生产的品牌,拥有强大的生产力量,为广大消费者带来别具一番风味的产品,得到越来越多消费者的认可,也成为一些创业者想要合作的项目,大家想要了解有红鸡毛店川菜怎么样,加盟有哪些优势,有红鸡毛店川菜怎...。

我们今天就来简单说一下,社群运营的常规工作,也是浅层次的日常操作,希望可以给各位在社群管理上一些头绪,只有前期基本功够扎实,进阶时期的分群裂变才会水到渠成.1.早报前期无论是3个社群也好,30个社群也罢,最基础的工作是一定要落实到位的,之前很多学员就表达过疑问,每天准时一条早报,究竟有无必要?对此,作者认为,不止有必要,而且是必须的....。

孩子的生活充满色彩,对颜色也很感兴趣,都是想要自己绘制心中满意的作品也想要成为小小的绘画家,所以市场上根据孩子的学习兴趣也出现了很多培养机构,在儿童绘本教育方面很出色,萌卡纳儿童绘本教育馆就获得很多孩子的喜欢,加盟店也很多,萌卡纳儿童绘本教育馆有什么特色,相信不少创业者加盟前或者家长在选择报名之前,都想要了解一下产品特色,萌卡纳儿童绘...。

4月15日消息,作为已经结束的内部调查一部分,陷入困境的法拉第未来采取了更多纪律处分行动,包括解除其创始人、前CEO贾跃亭的执行官职务,法拉第未来周四在一份监管文件中称,贾跃亭将继续担任首席产品官一职,并向执行董事长汇报工作,不过,贾跃亭的角色将仅限于专注于产品和移动生态系统、互联网、人工智能和先进的研发技术,他将不再担任执行官...。

发表在爱普生投影仪2021,7,1214,16爱普生tw5700由于没有USB接口,因此安装软件不能使用传统的方法,那么爱普生tw5700怎么安装软件呢,下面就分享详细的图文教程,教大家怎么在爱普生tw5700上安装软件,一、爱普生tw5700怎么安装软件1.打开爱普生tw5700,进入主页导航栏,选择应用栏并点击进入;2.在应用栏选...。

10月14日,外交部发言人毛宁掌管例行记者会,日本广播协会记者提问,关于中方在中国台湾周边海域的军事演习,美国国务院发言人表白严重关切,请问发言人对此有何评论,毛宁示意,台湾是中国的一局部,台湾疑问是中国外交,不容任何外来干预,假设美方真的在乎台海的和颠簸固和地域的兴盛,就应当遵守一个中国准则和中美三个联结公报,实际将美国指导人不允许...。

周公解梦梦见掉头发周公解梦梦见掉头发,预示近来你将遇到一些小艰巨将会渡过一段舒服的日子,假设能在梦中能觉失掉悲痛、伤感,则有不好的或许预示,预示着你要跟同性之坚持必定距离保证自己的家庭幸福才干喜气相随,或许很多人做这样的梦都不知道是吉是凶,上方是周公解梦周公解梦梦见掉头发吉凶和宜忌,周公解梦梦见掉头发1假设梦里的头发又乱又掉头发,要分...。

如今,西北V5菱致的市场价位在6,8万元人民币之间,在这个价位段,它有哪些值得美化的特点呢,首先,它的外观设计极具吸引力,共同的外型设计让人印象深入,一眼难忘,其次,车内的空间宽阔温馨,座椅柔软,乘坐体验极端杰出,而且,在操控性和底盘调校上,西北V5菱致雷同体现杰出,过弯时的稳固性以及驾驶者的感触都是一流的,能源方面,1.5升发起机提...。

穷人赚钱的门路有很多,其中手工活是一个非常受欢迎的选择。手工活不仅可以帮助人们增加收入,还可以培养技能和创造力。以下是一些适合穷人从事的手工活门路:1.手工艺品制作:手工艺品制作是一个广阔的领域,包

相信还有不少人不会美团账单记录如何删掉吧,那么就由网小编来告诉大家删除美团账单记录方法,想要学习的话不妨就过来看一下吧。方法/步骤分享:1、首先呢,我们

每一年都会出炉最新中国富豪榜单,而且每一次的排名名单都能引起众网友的关注,此前2020年榜已经出炉,在2020年福布斯中国富豪榜中,杨惠妍是唯一上榜女性。

卢卡申科拒绝撤走瓦格纳,称波罗的海国家“愚蠢”,瓦格纳,俄罗斯,卢卡申科,波罗的海,北约成员国

发表在极米投影仪2022,4,1311,21极米z6xpro是近期上市的新品投影仪,那么这款投影仪和前代newz6x对比有什么区别呢,下面就通过多角度对比分析两款投影仪的区别,看看哪款投影仪好一些,更值得用户入手,一、极米z6xpro和newz6x参数对比图二、极米z6xpro和newz6x有什么区别1.光学参数极米z6xpro和ne...。

优势,一是,所队合一,模式解决了以往基层派出所和交警相互推诿的问题,一件交通事故的引发的民事纠纷原来可能踢皮球,现在合并之后,乡镇派出所集合多警种职责,对待群众求助不再推诿扯皮,服务效率可以得到明显提升,二是,所队合一,后,整合资源,统一调度,大大缩短出警时间,避免了在处理一场事故的同时,没有多余的力量再及时赶往另一场事故现场,导致双...。

不可能发展壮大的,还美其名曰电竞实际就是打游戏,网瘾人群的向往,这个行业只能是极少数人成功,这些年看起电竞行业发展了,那是因为有些商界大佬,如王思聪等,发现了巨大的商机,商机的来源就是这些所谓的热爱电竞的人,网瘾人群为主,,那些天天说什么电竞是个很好的人生追求方向的人基本就是网瘾人群中的一员,除了极少数的人,有天赋成为职业玩家,切能有...。
我按规则实现课程要求,沪江承诺关班后返现课程费用的百分之三十,2月份关班,曾通过去半年了到如今没有收到返现,发信息也不理,在报名前不短采购更贵的课程,也并没有明白示意关班后课程回放就看不了了,跟我说来不迭看可以在关班之前可以先吧课件都刷了就算实现了,造成生产者以为只需在关班前先把课件刷到百分百的完......。

白羊座,火象星座,3月21日~4月19日金牛座,土象星座,4月20日~5月20日双子座,风象星座,5月21日~6月21日巨蟹座,水象星座,6月22日~7月22日狮子座,火象星座,7月23日~8月22日处女座,土象星座,8月23日~9月22日天秤座,风象星座,9月23日~10月23日天蝎座,水象星座,10月24日~11月22日射手座,火...。
