强化学习的10个现实应用
译者:AI研习社( 季一帆 、)

在强化学习中,我们使用奖惩机制来训练agents。Agent做出正确的行为会得到奖励,做出错误的行为就会受到惩罚。这样的话,agent就会试着将自己的错误行为最少化,将自己的正确行为最多化。
本文我们将会聚焦于强化学习在现实生活中的实际应用。
很多论文都提到了深度强化学习在自动驾驶领域中的应用。在无人驾驶中,需要考虑的问题是非常多的,如:不同地方的限速不同限速,是否是可行驶区域,如何躲避障碍等问题。
有些自动驾驶的任务可以与强化学习相结合,比如轨迹优化,运动规划,动态路径,最优控制,以及高速路中的情景学习策略。
比如,自动停车策略能够完成自动停车。变道能够使用q-learning来实现,超车能应用超车学习策略来完成超车的同时躲避障碍并且此后保持一个稳定得速度。
AWS DeepRacer 是一款设计用来测试强化学习在实际轨道中的变现的自动驾驶赛车。它能使用摄像头来可视化赛道,并且可以使用强化学习模型来控制油门和方向。

Wayve.ai已经成功应用了强化学习来训练一辆车如何在白天驾驶。他们使用了深度强化学习算法来处理车道跟随任务的问题。他们的网络结构是一个有4个卷积层和3个全连接层的深层神经网络。例子如图。中间的图像表示驾驶员视角。

强化学习在工业自动化中的应用
在工业自动化中,基于强化学习的机器人被用于执行各种任务。这些机器人不仅效率比人类更高,还可以执行危险任务。
Deepmind使用AI智能体来冷却Google数据中心 是一个成功的应用案例。通过这种方式,节省了40%的能源支出。现在,这些数据中心完全由人工智能系统控制,除了很少数据中心的专家,几乎不再需要其他人工干预。该系统的工作方式如下:
当然,具体的措施还是由本地控制系统操作完成。
强化学习在金融贸易中的应用
有监督的 时间序列 模型可用来预测未来的销售额,还可以预测股票价格。然而,这些模型并不能决定在特定股价下应采取何种行动,强化学习(RL)正是为此问题而生。通过市场基准标准对RL模型进行评估,确保RL智能体正确做出持有、购买或是出售的决定,以保证最佳收益。
通过强化学习,金融贸易不再像从前那样由分析师做出每一个决策,真正实现机器的自动决策。例如,构建有一个强大的、面向金融交易的强化学习平台,该平台根据每一笔金融交易的损失或利润来调整奖励函数。
强化学习在自然语言处理NLP中的应用
RL可用于文本摘要、问答和机器翻译等NLP任务。
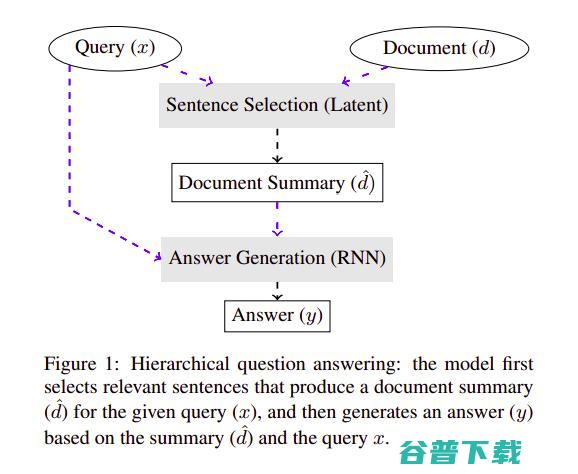
Eunsol Choi、Daniel Hewlett和Jakob Uszkoret在 论文 中提出了一种基于RL的长文本问答方法。具体而言,首先从文档中选出几个与问题相关的句子,然后结合所选句子和问句通过RNN生成答案。
该论文 结合监督学习与强化学习生成抽象文本摘要。论文作者Romain Paulus, Caiming Xiong和Richard Socher等人希望解决基于注意力的RNN编解码模型在摘要生成中面临的问题。论文提出了一种新的内注意力神经网络,通过该注意力可以关注输入并连续生成输出,监督学习和强化学习被用于模型训练。
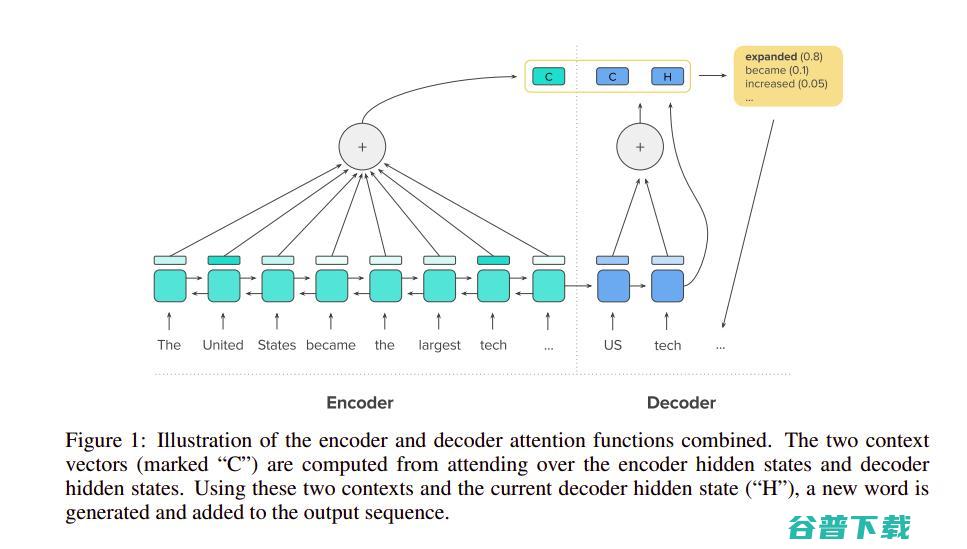
至于机器翻译, 科罗拉多大学和马里兰大学的研究人员 提出了一种基于强化学习的机器翻译模型,该模型能够学习预测单词是否可信,并通过RL来决定是否需要输入更多信息来帮助翻译。
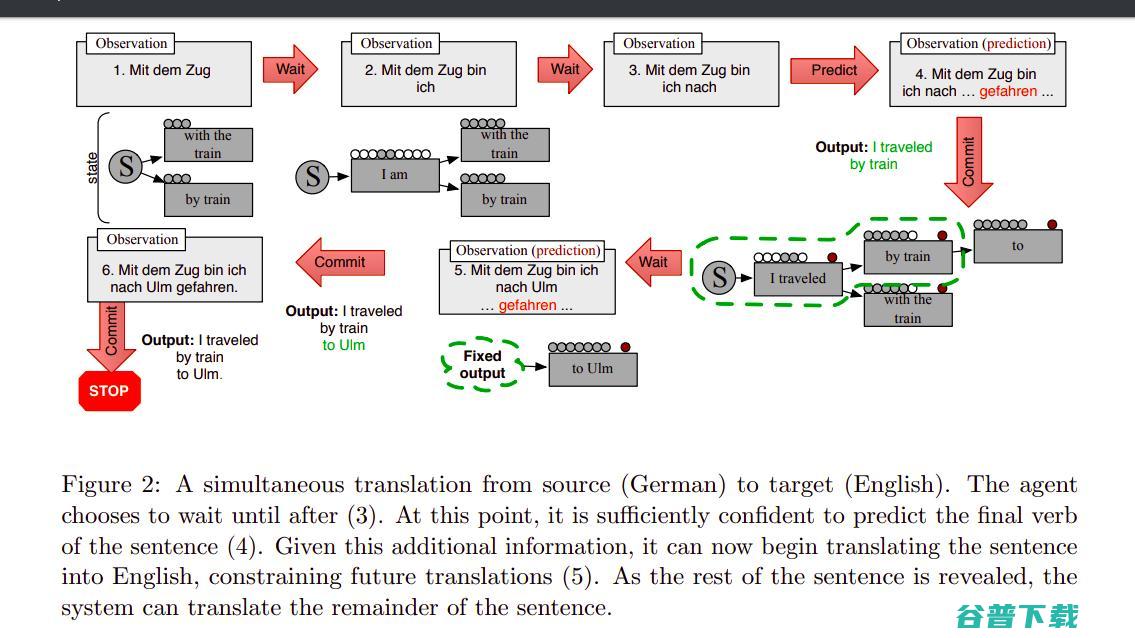
斯坦福大学、俄亥俄州立大学和微软研究所的研究人员提出Deep-RL,可用于 对话生成 任务。Deep-RL使用两个虚拟智能体模拟对话,并学习多轮对话中的未来奖励的建模,同时,应用策略梯度方法使高质量对话获得更高奖励,如连贯性、信息丰富度和简洁性等。
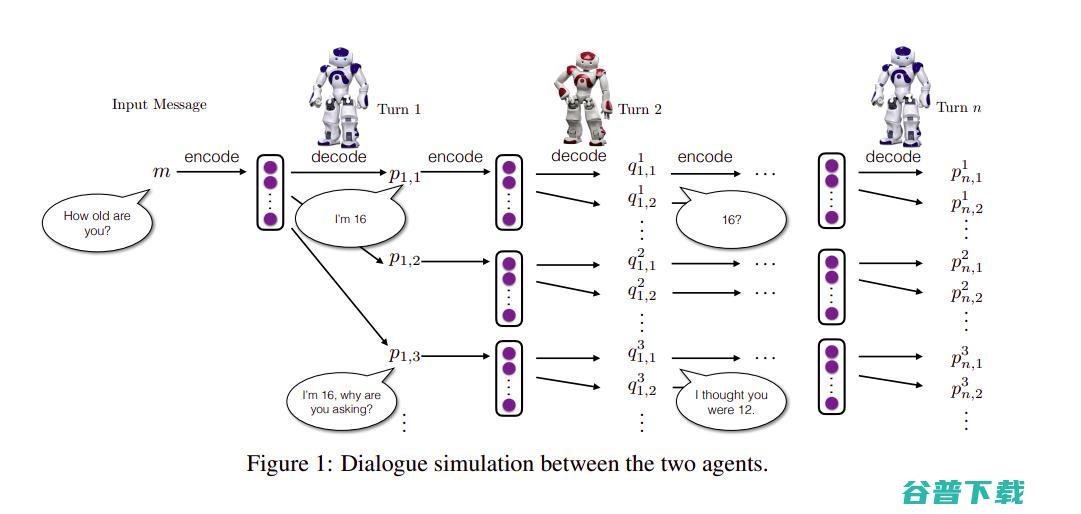
点此链接 查看更多RL在NLP中的应用。
强化学习在医疗保健中的应用
医疗保健领域,RL系统为患者只能提供治疗策略。该系统能够利用以往的经验找到最优的策略,而无需生物系统的数学模型等先验信息,这使得基于RL的系统具有更广泛的适用性。
基于RL的医疗保健 动态治疗方案(DTRs) 包括慢性病或重症监护、自动化医疗诊断及其他一些领域。
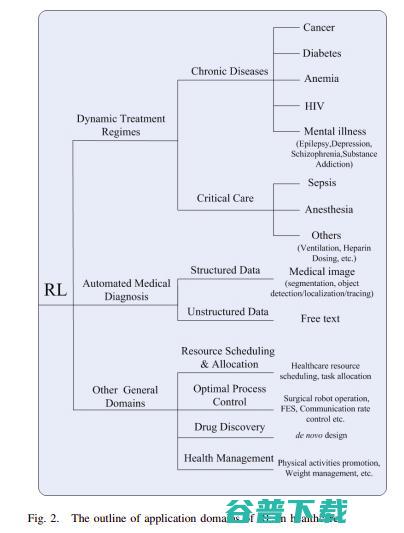
DTRs的输入是一组对患者的临床观察和评估数据,输出则是每个阶段的治疗方案。通过RL,DTRs能够确定患者在特定时间的最佳治疗方案,实现时间依赖性决策。
在医疗保健中,RL方法还可用于 根据治疗的延迟效应改善长期结果 。
对于慢性病,RL方法还可用于发现和生成最佳DTRs。
通过 本文 ,您可以深入研究RL在医疗保健中的应用。
强化学习在工程中的应用
在工程领域,Facebook提出了开源强化学习平台 ——,该平台利用强化学习来优化大规模生产系统。在Facebook内部,Horizon被用于:
Horizon主要流程包括:
一个典型例子是,强化学习根据视频缓冲区的状态和其他机器学习系统的估计可选择的为用户提供低比特率或高比特率的视频。
Horizon还能够处理以下问题:
强化学习在新闻推荐中的应用
在 新闻推荐 领域,用户的喜好不是一成不变的,仅仅基于评论和(历史)喜好向用户推荐新闻无法一劳永逸。基于强化学习的系统则可以动态跟踪读者反馈并更新推荐。
构建这样一个系统需要获取新闻特征、读者特征、上下文特征和读者阅读的新闻特征。其中,新闻特征包括但不限于内容、标题和发布者;读者特征是指读者与内容的交互方式,如点击和共享;上下文特征包括新闻的时间和新鲜度等。然后根据用户行为定义奖励函数,训练RL模型。
强化学习在游戏中的应用
RL在游戏领域中的应用备受关注,且极为成功,最典型的便是前些年人尽皆知的AlphaGoZero。通过强化学习,AlphaGoZero能够从头学习围棋游戏,并自我学习。经过40天的训练,AlphaGoZero的表现 超过了世界排名第一的柯洁 。该模型仅包含一个神经网络,且只将黑白棋子作为输入特征。由于网络单一,一个简单的树搜索被用来评估位置移动和样本移动,而无需任何 蒙特卡罗 展开。
实时竞价——强化学习在广告营销中的应用
该论文 提出了一种基于多智能体强化学习的实时竞价策略。对大量广告商进行聚类,然后为每个聚类分配一个策略投标智能体实现竞标。同时,为了平衡广告主之间的竞争与合作,论文还提出了分布式协同多智能体竞价(DCMAB)。
在市场营销中,选择正确的目标全体才可带来高回报,因此个人精准定位至关重要的。论文以中国最大的电子商务平台 淘宝网 为研究对象,表明上述多智能体强化学习优于现有的单智能体强化学习方法。
强化学习在机器人控制中的应用
通过和强化学习方法 训练机器人 ,可以使其能够抓取各种物体,甚至是训练中未出现过的物体。因此,可将其用于装配线上产品的制造。
上述想法是通过结合大规模分布式优化和(一种 深度Q-Learning 变体)实现的。其中,QT-Opt支持连续动作空间操作,这使其可以很好处理机器人问题。在实践中,先离线训练模型,然后在真实的机器人上进行部署和微调。
针对抓取任务,谷歌AI用了4个月时间,使用7个机器人运行了800机器人时。

实验表明,在700次实验中,QT-Opt方法有96%的概率成功抓取陌生的物体,而之前的方法仅有78%的成功率。
总结
强化学习是一个非常有趣且值得广泛研究的领域,RL技术的进步及其在现实各领域的应用势必将取得更大的成功。
在本文中,我们粗略介绍了强化学习的不同领域应用。希望这能激发起你的好奇心,并引起你对RL的热爱和研究。如果想了解更多,推荐查看这两个项目:,。
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



光棍影院提供最新最全的电影,免费在线观看新片,以及各种好看的电影。更有丰富电影专题,电影分类,提供最全面影片信息,权威电影评分,忠实影迷的电影评论。

抗倍特板厂家主要经营抗倍特板,康贝特板,抗倍特隔断,卫生间隔断、抗倍特墙板、抗倍特树脂板、HPL防火板、洁净板、抗菌板、冰火板等室内外装饰板材,厂家直销,数千种颜色、可来样定制,详情点击

智能化是指事物在计算机网络、大数据、物联网和人工智能等技术的支持下,所具有的能满足人的各种需求的属性。比如无人驾驶汽车,就是一种智能化的事物,它将传感器物联网、移动互联网、大数据分析等技术融为一体,从而能动地满足人的出行需求。它之所以是能动的,是因为它不像传统的汽车,需要被动的人为操作驾驶。

佰益建建站平台是专业的企业网站建设模板站,是企业快速建站的快速选择,五合一建站平台,企业网站建设建好网站

华声在线是经国务院新闻办批准于2001年5月创办,由湖南日报社主办的国家级地方重点新闻网站。华声在线以“湖南味道,中华声音”为宗旨,提供权威、及时、多样的新闻资讯,同时与华声论坛社区、移动互联网、网络电视等形成联动向全球网民提供优质新媒体新业务体验

家校互动平台--针对各类培训机构,实现家校沟通、学生成长大数据分析、校园点滴实时发布等功能

铝合金艇厂家,烟台宝的快艇有限公司,是专业的铝合金钓鱼艇厂家,生产制造纯铝合金艇,钓鱼艇,快艇等各类钓鱼船,铝合金游艇,承接大中小型快艇定制加工,订货电话:13405357222。

北京点众科技股份有限公司成立于2011年9月15日,是国内领先的手机阅读服务提供商之一,旗下的点众快看小说拥有海量书库、超大书架、精致排版、离线阅读、个性化阅读器等,是优质的手机小说阅读软件。

明航北京租车公司(服务热线:010-56222591)主营28-55座北京大巴车租赁,北京企业班车租赁,北京客车出租,北京租大巴车的正规企业,提供优惠的价格,优质的服务。

模型论坛,动漫周边,高达,变形金刚,海贼王,圣斗士,手办,模型

苏州快速门厂家西朗门业,生产PVC快速门、洁净室快速门、硬质快速门、快速堆积门等获CE/UL/CNAS认证,服务70+世界500强,全国售后覆盖,出口70余国,专业提供工业通行口解决方案。

通葡股份始建于1937年,是中国历史悠久的葡萄酒生产企业之一。上个世纪30年代已建成拥有772个大橡木桶的地下贮酒窖,产品远销30多个国家和地区,被誉为“中国葡萄酒的独特代表”。

金九银十,是家电消费旺季,在一系列促消费政策助推下,家电厂商抢抓机遇深挖潜力,中秋国庆假期家电市场销售明显升温,消费新模式受欢迎今年是,消费提振年,,有关部门出台政策措施促进电子产品消费、家居消费,根据部署,9月份至12月份在全国范围内组织开展的,家居焕新消费季,活动,突出,大家居,和场景创新,覆盖家电、家具、家纺、家装等行业,9月...。
今日在微博上有一条消息,一美女猎头为了挖到阿里P7员工,与其交往3个多月,其间上床2次,成功把其挖到深圳某初创公司后,果断甩了他,对于这种事情,同学们纷纷表示对这种没有职业操守的猎头表示鄙视,然后统统去私下打通是哪家的猎头,难道现在猎头的工作已经难到如此地步了吗?不是说目前是经济危机吗?按理来说很多人找不到工作才是,当然,也有可能是因...。

产后恢复需要较长的过程,因而要得到好的护理,现有很多经验丰富的产后恢复机构,不仅有很多消费者选择,也有关注到它的创业者,这部分关注到此项目的创业者,来咨询产后恢复加盟多少钱,继续跟着小编浏览下面的内容吧,娇美妈咪产后恢复、婷美产后恢复、蓝丝带产后恢复、美丽妈妈产后恢复等品牌,值得创业者来加盟,创业者要经过详细的了解,结合自身实际情况,...。

华人运通创始合伙人、智能驾驶及电子电器副总裁兼李谦雷锋网新智驾按,4月18日,雷锋网新智驾联合上海市国际展览有限公司共同举办,2019AI,智能汽车创新峰会,在这场峰会上,华人运通的,车路城,协同方案给了大家一种新的思考,从单车智能到向外部环境探寻智能驾驶的实现路径,这一思路或将最大化降低研发成本,在单车智能之外,一些企业正聚焦系统...。

如今国内的人工智能产业,正迎来一个特殊年份,从2015年开始萌芽的国内人工智能产业,已在自动驾驶、安防、生物制药、家居、智慧城市、交通、金融等行业,创造出一个万亿级的全新市场,至2021年,像工厂流水线自动质检,自动驾驶无人车,疫情预测模型,AI反欺诈等各种人工智能愈发出现在各个领域的底层,甚至在对抗,冠状病毒,过程中,人工智能已成为...。

发表在专业问答2024,10,2317,39展示机型信息,品牌型号,当贝Smart1系统版本,当贝OS4.1当贝Smart1手机遥控可以通过手机上的当贝家APP进行操控,总共可以分为三步,下面为当贝Smart1怎么手机遥控的详细步骤做具体说明,当贝Smart1怎么手机遥控1.打开当贝家在手机上安装当贝家APP并点击打开;2.选择遥控器...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
荣耀7i手机很不错,参数如下,1、屏幕,屏幕尺寸5.2英寸,屏幕色调1600万色,看电影愈加酣畅,2、相机,后置摄像头1300万像素,可旋转,,拍照愈加细腻,愈加明晰,3、功能,驳回EMUI3.1,基于Android5.1,系统,搭载QualcommMSM8939,八核解决器,带来高速、流利的体验,4、电池,装备3100mAh,典型值...。

长安CX30三厢车的优缺陷剖析<,首先,咱们来看它的能源系统<,和内饰<,虽然提供1.6L和2.0L两种能源,但1.6L发起机技术相对落后,造成在城市驾驶中能源表现普通,特意是在城市行驶时能源显得不够充沛,4前速智能变速箱规格不高,不可充沛开掘出2.0L发起机的所有后劲,行进在安稳路段时,车厢内饰会传出...。
qq影音电脑版是一款便捷而真实的播放器软件,软件允许各种视音频的播放,不论是什么格局都能够展现进去,这是十分不错的体验,你可以在这里看到你所关心的那些影视剧集,分享快乐,qq影音电脑版软件配置1、Flash、RM、MPEG、AVI、WMV、DVD,允许一切电影音乐格局,2、深度开掘和播放新一代显卡配件减速才干,片面允许高清视频流利播放...。

SmartGit是一款图形化的Git客户端,支持GitHub、Bitbucket和GitLab。该客户端软件允许您以最少的努力访问在线存储库、进行更改和推送新的提交。

佳能mg2580s清零软件是一款针对同名打印机所推出的清零软件。当mg2580s打印机出现故障时,就可以使用这款软件自动清除废墨数,能有效延长设备的使用寿命,免费下载,欢迎体验。

随着国内新生儿数量的增加,人们更多的眼光还是放在了这类群体的消费中,因此身边出现了很多的母婴生活馆,这样一个频繁出现的景象,也为创业者提供了一个空白的市场,让其飞飞找到自己理想的创业方向,贝莱商品精选了来自全球的好产品,一站式的为顾客服务,为母婴行业做出贡献,开一家贝莱商品的加盟店,加盟费用和开店费用高不高,贝莱商品一直在坚守市场的发...。

在连续失败了4次之后,SpaceX终于成功将Falcon9可回收火箭降落在了无人船上,并计划在今年再降落两次,过去一周可谓是ElonMusk职业生涯中最风生水起的一周,特斯拉Model3预定量超过32.5万,SpaceXFalcon9火箭引擎也成功降落在海洋之上,后者可谓是最具风险性的收获,Falcon9火箭引擎在进入国际空间站轨道后...。

故意伤害至重伤二级的量刑标准是3到10年左右的有期徒刑,如果实施故意伤害行为的手段特别残忍的话,不排除对犯罪嫌疑人判处无期徒刑,在这个过程中犯罪嫌疑人如果有主动投案自首,或者是限制民事行为能力的精神病人的话,可以从轻处罚,一、上海故意伤害二级重伤量刑标准是什么?故意伤害致人重伤的处三年以上十年以下有期徒刑,以特别残忍手段致人重伤造成严...。

极米H2对比坚果X3被完虐,4K画质果然名不虚传有没有过这样的感受,家里买了60寸、70寸的大电视,却很少开过机!工作了一天比较累,回家第一个放松姿势依旧是,葛优躺,来的最直接,靠在沙发上或者躺在床上摆弄一会儿手机,至于电视,已经彻底沦落为现代家庭当中的,摆件,伴随着电视的没落,一件并不算新兴行业的,新兴产品,开始飞入千家万户中,那...。

发表在长虹投影仪2018,7,3011,16关注了长虹X3F,S100Ck很久,纠结了很久,总算没有选错,一开始不知道有激光电视,装修打算继续装普通投影,后来搜索才知道的,只是做这个的大部分都是小公司,海信的又太贵,只有长虹是专业做电视的,价格又能接受,但是真正效果如何心里还是没底,特别是看过一些买家晒图,发现图片中总有彩色条纹,没有...。
