ICCV 2021放榜!发现一篇宝藏论文 (iccv2024截稿日期)

经过漫长的等待,ICCV 2021终于迎来放榜时刻!
最终1617篇论文被接收,接收率为25.9% ,相比于2017年(约29%),保持了和2019年相当的较低水平。
而投稿量则依旧逐年大幅增长,从2017年的2143篇,到2109年的4328篇,再到如今的6236篇,相比上一届多了50%左右。
你看邮件的时候是这表情吗?

官方皮起来也是接地气、真扎心、没谁了哈哈~
也就在今天,AI科技评论发现了一项非常厉害的研究,号称
近来,Vision Transformer (ViT) 模型在诸多视觉任务中展现出了强大的表达能力和潜力。
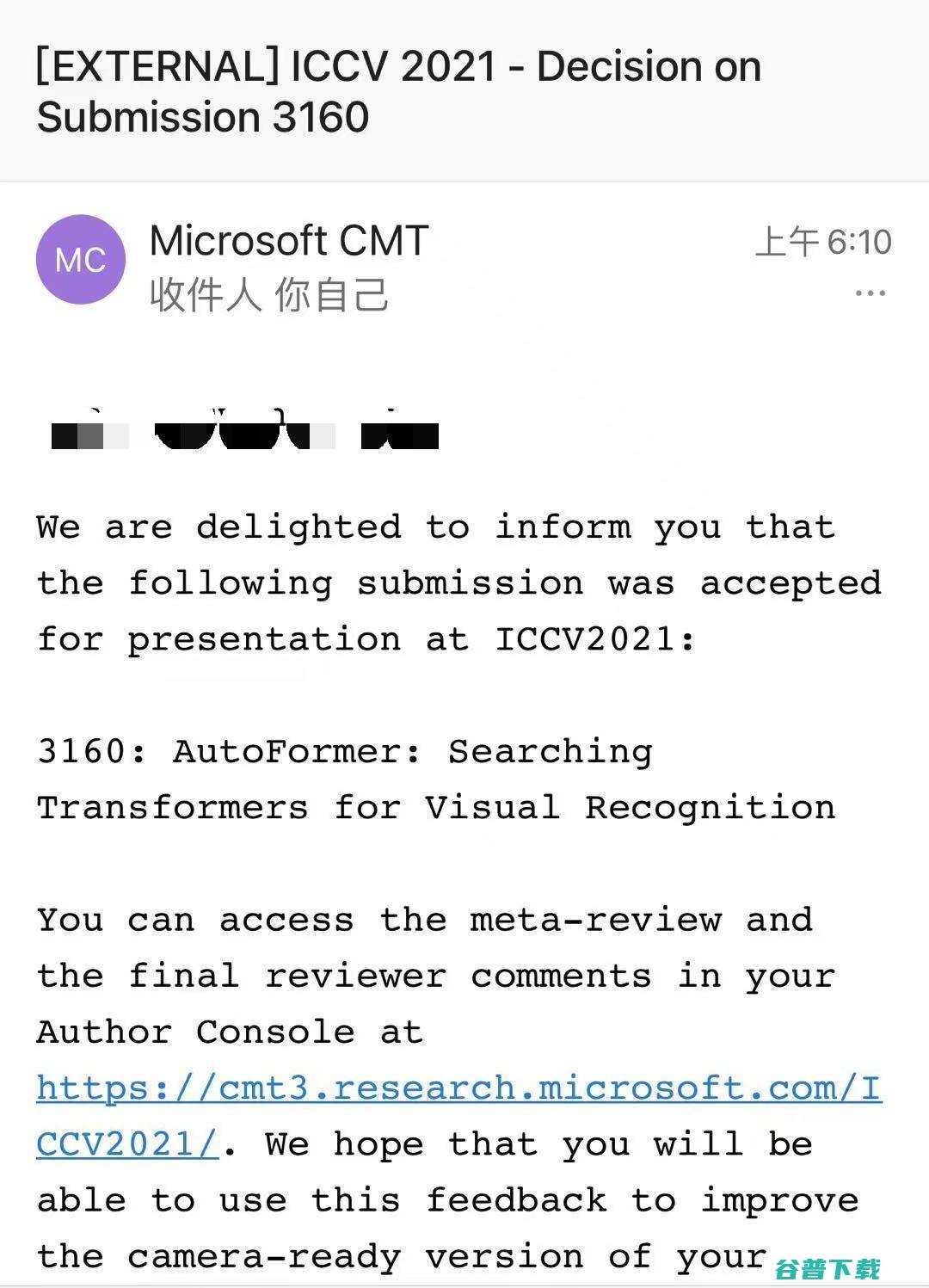
纽约州立大学石溪分校与微软亚洲研究院的研究人员提出了一种新的 网络结构搜索方法AutoFormer ,用来自动探索最优的ViT模型结构。
AutoFormer能一次性训练大量的不同结构的ViT模型,并使得它们的性能达到收敛。
其搜索出来的结构对比手工设计的ViT模型有较明显的性能提升。

最近的研究发现,ViT能够从图像中学习强大的视觉表示,并已经在多个视觉任务(分类,检测,分割等)上展现出了不俗的能力。
Vision Transformer 模型的结构设计仍然比较困难。 例如,如何选择最佳的网络深度、宽度和多头注意力中的头部数量?
作者的实验发现这些因素都和模型的最终性能息息相关。然而,由于搜索空间非常庞大,我们很难人为地找到它们的最佳组合。

图1: 不同搜索维度的变化会极大地影响模型的表现能力
本文的作者提出了一种专门针对Vision Transformer 结构的新的Neural Architecture Search (NAS) 方法 AutoFormer。AutoFormer大幅节省了人为设计结构的成本,并能够自动地快速搜索不同计算限制条件下ViT模型各个维度的最佳组合,这使得不同部署场景下的模型设计变得更加简单。

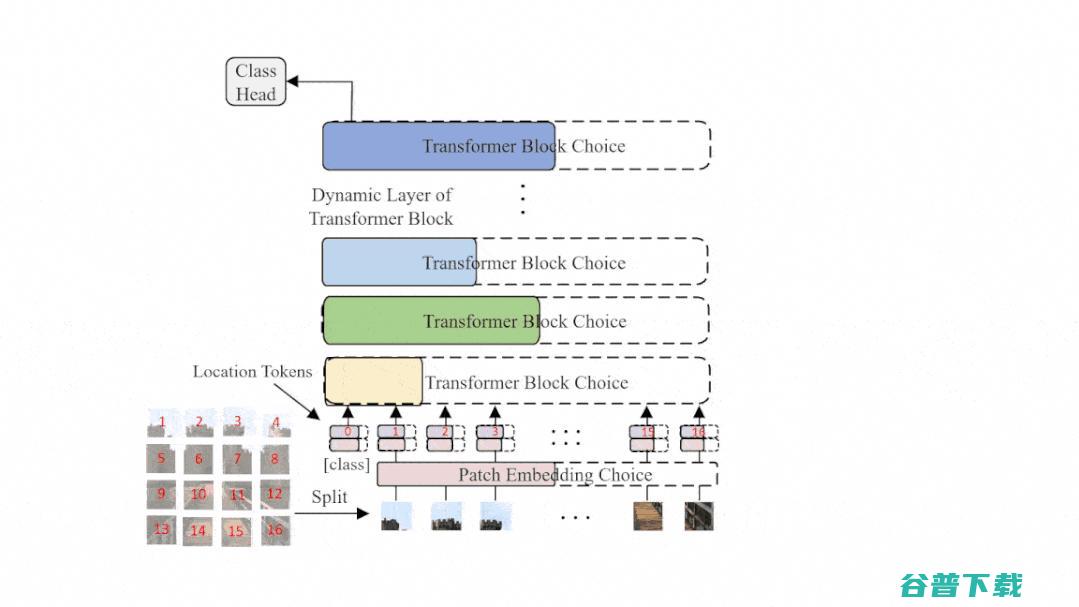
图2: AutoFormer的结构示意图,在每一个训练迭代中,超网会动态变化并更新相应的部分权重
常见的One-shot NAS 方法[1, 2, 3]通常采取权重共享的方式来节省计算开销,搜索空间被编码进一个权重共享的 超网 (supernet) 中,并运用超网权重作为搜索空间中结构权重的一个估计。其具体搜索过程可分为两个步骤, 第一步是更新超网的权重

第二步是利用训练好的超网权重来对搜索空间中结构进行搜索。
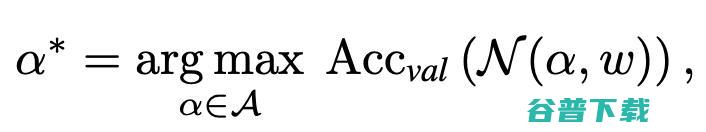
在实验的过程中,作者发现经典One-shot NAS方法的权重共享方式很难被有效地运用到Vision Transformer的结构搜索中。这是因为 之前的方法通常仅仅共享结构之间的权重,而解耦同一层中不同算子的权重。
如图3所示,在Vision Transformer的搜索空间中,这种经典的策略会遇到收敛缓慢和性能较低的困难。
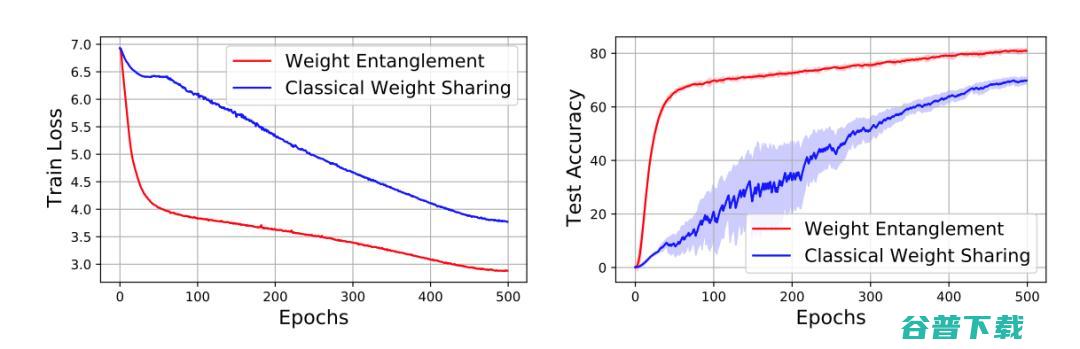
图3 权重纠缠和经典权重共享的训练以及测试对比
受到OFA [4], BigNAS [5] 以及Slimmable networks [6, 7] 等工作的启发,作者提出了一种新的权重共享方式—— 权重纠缠 (Weight Entanglement)。
权重纠缠进一步共享不同结构之间的权重,使得同一层中不同算子之间能够互相影响和更新 ,实验证明权重纠缠对比经典的权重共享方式,拥有占用显存少,超网收敛快和超网性能高的优势。
同时,由于权重纠缠,不同算子能够得到更加充分的训练,这使得AutoFormer能够一次性训练大量的ViT模型,且使其接近收敛。(详情见实验部分)
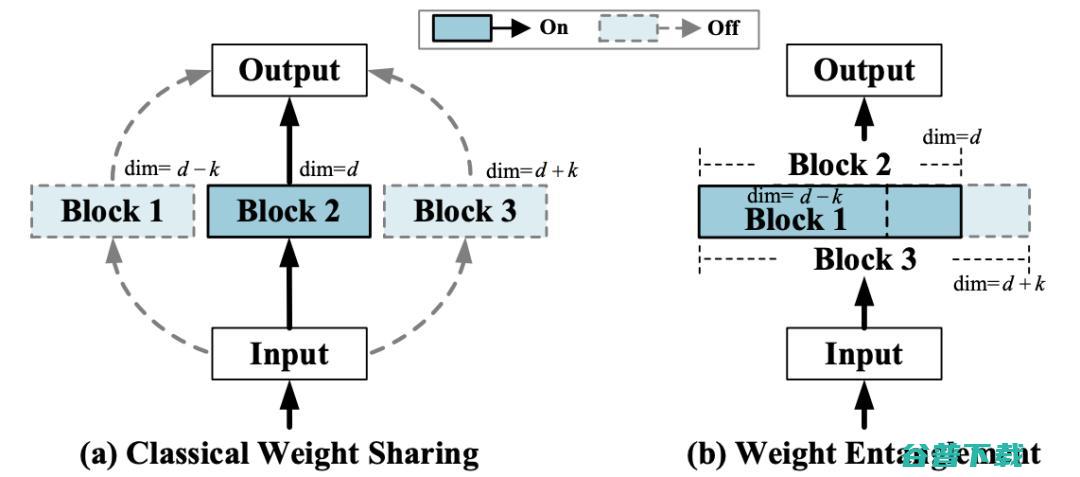
图4 权重纠缠和权重共享的对比示意图
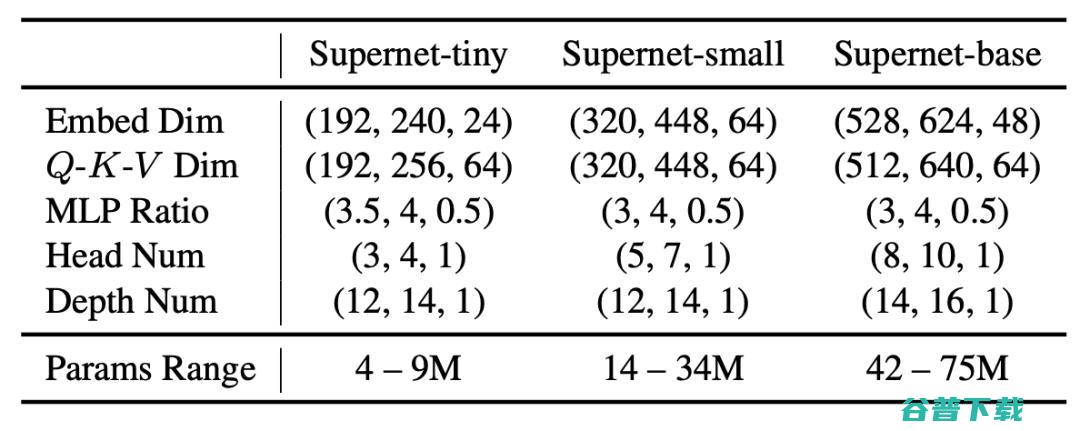
作者设计了一个拥有超过备选结构的巨大搜索空间,其搜索维度包括ViT模型中的 五个主要的可变因素 :宽度 (embedding dim)、Q-K-V 维度 (Q-K-V dimension)、头部数量 (head number)、MLP 比率 (MLP ratio) 和网络深度 (network depth),详见表1。
为了验证方法的有效性,作者将AutoFormer搜索得到的结构和近期提出的ViT模型以及经典的CNN模型在ImageNet上进行了比较。
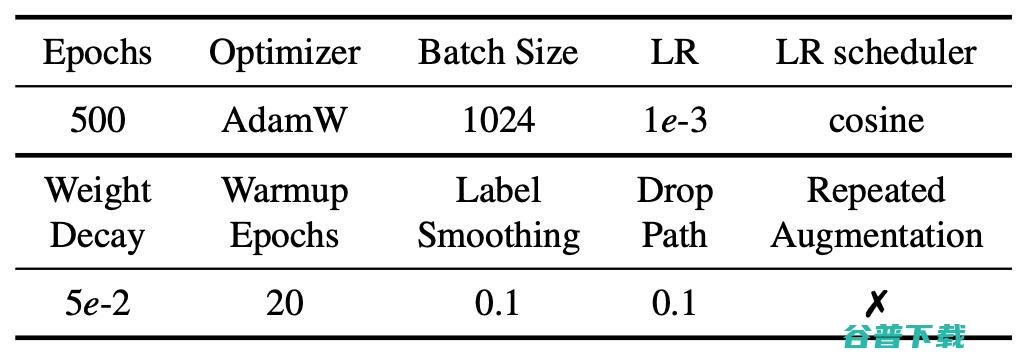
对于训练过程,作者采取了DeiT [8]类似的数据增强方法,如 Mixup, Cutmix, RandAugment等, 超网的具体训练参数如表2所示。 所有模型都是在 16块Tesla V100 GPU上进行训练和测试的。
搜索得到的结构在ImageNet数据集上明显优于已有的ViT模型。
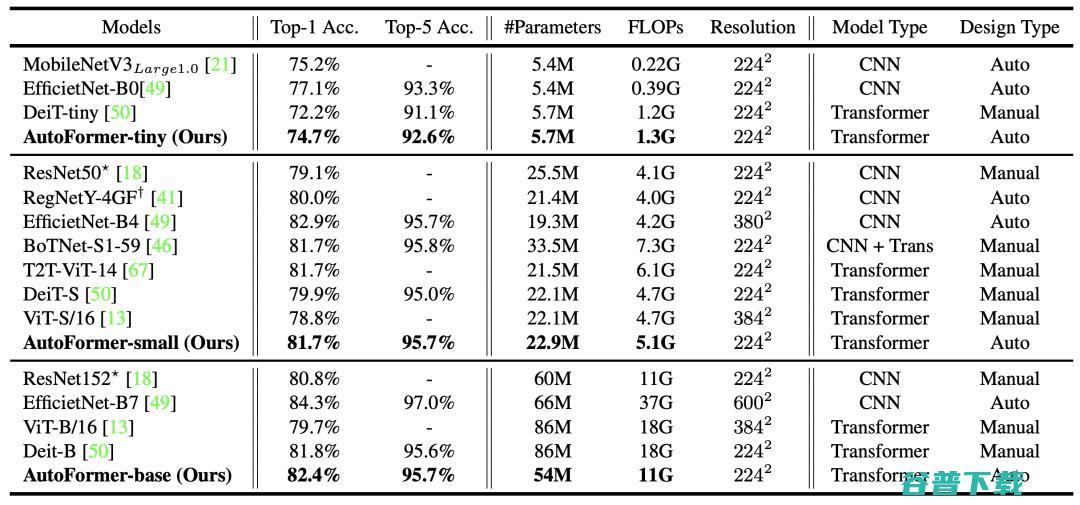
表3:各个模型在ImageNet 测试集上的结果
在下游任务中,AutoFormer依然表现出色,利 用仅仅25%的计算量就超越了已有的ViT和DeiT模型 ,展现了其强大的泛化性能力。

表4:下游分类任务迁移学习的结果
够同时使得成千上万个Vision Transformers模型得到很好的训练 (蓝色的点代表从搜索空间中选出的1000个较好的结构)。
不仅仅使得其在搜索后不再需要重新训练(retraining)结构,节约了搜索时间,也使得其能在各种不同的计算资源限制下快速搜索最优结构。
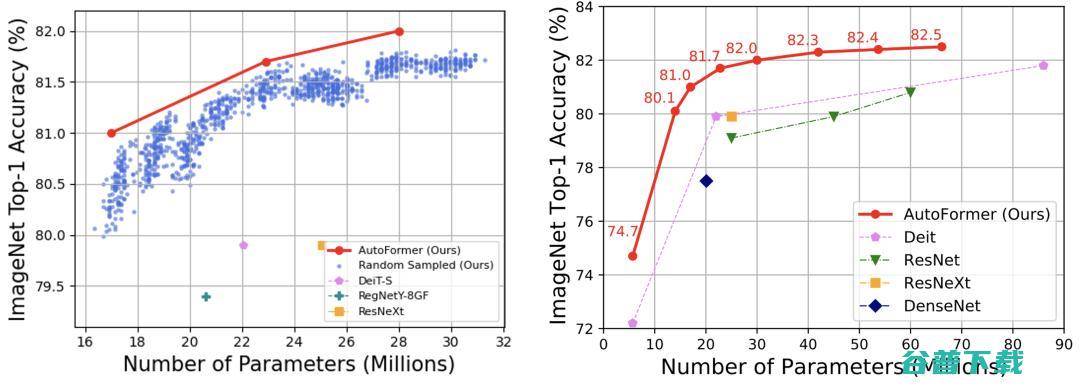
图5:左:AutoFormer能够同时训练大量结构,并使得其接近收敛。蓝色的点代表从搜索空间中选出的1000个较好的结构。右:ImageNet上各模型对比
本文提出了一种新的专用于Vision Transformer结构搜索的One-shot NAS方法—— AutoFormer。AutoFormer 配备了新的权重共享机制,即权重纠缠 (Weight Engtanglement)。在这种机制下,搜索空间的网络结构几乎都能被充分训练,省去了结构搜索后重新训练(Retraining)的时间。大量实验表明所提出的算法可以提高超网的排序能力并找到高性能的结构。在文章的最后,作者希望通过本文给手工ViT结构设计和NAS+Vision Transformer提供一些灵感。在未来工作,作者将尝试进一步丰富搜索空间,以及给出权重纠缠的理论分析。

若二维码过期或群内满200人时,添加小助手微信(AIyanxishe3),备注ICCV2021拉你进群。

特约稿件,未经授权禁止转载。详情见 转载须知 。



股海明灯,股海明灯论坛是由黑马王子老师创办,独创量学理论,在伏击涨停,盘前预报,牛股预报方面积累了丰富的股票知识,并开设量学云讲堂,是学习量学知识,涨停技巧,股票选股公式的股票论坛。

辽宁孚泰化工机械有限公司主营主动封隔器被动封隔器 封隔膜LMU氮气包 气囊隔膜橡胶密封件特种橡胶制品

安徽省宝地园林绿化有限公司,宝地园林,安徽宝地园林,合肥宝地园林,合肥园林公司,安徽园林公司,宝地园林绿化,合肥园林绿化,安徽园林绿化

微信引流软件是一款微信推广工具,本软件以官方原版为基础,通过模式方式,实现微信的开放式营销。

百望云官方热线:40085-12366。百望云是专业的电子发票及财税服务商,提供票据合规管控、智慧财税、财务供应链协同、数据科技等产品和服务,助力企业数字化转型。

深圳电通纬创微电子股份有限公司

南京乐游星空信息科技有限公司是江苏省内最大的游戏及应用内分发渠道商之一。专注于游戏发行和运营。优质的APP分享服务,以及线下销售服务.

深圳市鹏深冷暖设备有限公司主营:防爆空调、防爆除湿机、防爆加湿机、船用空调、全新风防爆空调、直膨屋顶式中央空调、防爆冰箱冷柜、防爆冷库机组、防爆机房空调、防爆直膨式风管式空调,防腐船用空调、石化,电力,军用系列产品齐全
")
西北农林科技大学林学院(林业科学研究院)

留学点评网是由全球知名院校毕业生联合发起的留学社区平台,提供美国留学中介机构、加拿大留学机构、留学中介机构申请、出国留学学校推荐信息,为学生提供全方位出国留学相关功能服务支持。

安徽鼎彩光电集团坐落于安徽滁州,专业从事电子电器生产、销售的大型综合性企业。联系电话:15005504847/18055026808

内蒙古德明电子科技有限公司是是一家集研发、生产、销售和售后服务于一体的公司,公司以强大的科技优势为依托,以智能控制核心,不断拓展其应用领域,产业涵盖了无线LORA传感器、NB-IOT温湿度、无线压力变送器采集、网关采集器、智慧农业传感器,无线i/o采集板,温室大棚远程温湿度监测系统、测量仪表及环境动力监控系统等产品定制,智控领域一流方案供应商,欢迎来电咨询厂家手机:15384841043

雷锋网消息,据微博用户鼎盛风清称,荷兰政府将根据瓦森纳国际协议,禁止阿斯迈,ASML,公司向中国出口极紫外,EUV,光刻机,不过,雷锋网了解到,该消息还未最终证实,雷锋注,图为微博截图美国施压荷兰,禁止向中国出口EUV光刻机据,路透社,报道,美国方面为,阻止荷兰向中国出售芯片制造技术,,暗中进行了大量工作,据悉,美国的单方面,阻止运动...。

无论是在各种餐饮店,还是学校食堂、大型的超市内,亦或者是在自己家里,人们总是会看到各种丸子的踪影,可见,人们还是比较喜欢丸子这一美食的,所以,丸子制作项目便成为了时下的新宠,那么,丸子制作加工好吗,想知道的话,请接着往下看吧!何为丸子,丸子,是一种油炸或者是水煮食品,它是人们使用面粉、淀粉、鱼肉等食材制作而成的,其外形跟球差不多,饱满...。

编者按,备货少,声量足,小米MIX秒光是一件意料之中的事情,虽说在这个,PPT手机,泛滥的时代,没抢到一台概念机不足为谈,但得不到的永远在骚动,祛魅比盲目点赞也更靠谱,本期硬创公开课,,唯物,邀请了声学博士陈孝良从他的专业角度对这款手机进行解读,内容方面深入浅出,相信无论是消费者还是从业者,均能从中获益,以下为演讲实录,由,唯物,整理...。

截止至2019年三月,目前贵州省有27个火车站,详细站名如下,安顺、草海、从江、都匀、都匀东、独山、福泉、贵定、贵定南、贵定县、贵阳、贵阳北、凯里、凯里南、六盘水、六枝、龙里、龙里北、麻尾、榕江、三都县、三穗、桐梓、玉屏、铜仁、铜仁南、遵义,1、贵阳市火车站贵阳市火车站主要包括,贵阳北站、贵阳东站、贵阳站等,其中,贵州站位于贵州省贵阳...。

发表在综合交流大区2018,12,2615,05很多朋友对于投影机的亮度表现其实并没有太多的概念,到底一款投影拥有如何的亮度表现就算是够用了,自己又应该购买什么亮度表现的投影机呢,今天我们就来说说这个比较实际的问题,不同的投影机有不同的标准,首先我们从销量最大的商务和教育投影机说起吧,商务和教育投影机对于亮度的表现要求比较高,一般来说...。

发表在专业问答2022,9,1320,53展示机型信息,品牌型号,当贝X3系统版本,当贝OS2.0hdmi线最长支持30米,hdmi线的数据传输率达到了5Gbps,因此最远可支持30米,并且同时可以应付一个1080p的视频和一个8声道的音频信号,hdmi线最长支持多少米常见的hdmi线长度在0.5米到10米,最长支持30米,这是因为h...。

细微的划痕,可以去市场买点水蜡或硬蜡,拿一块海绵或绒布,沾上蜡之后涂抹至划痕处即可,在经常使用硬蜡的时刻必定把漆面解决洁净,假设是比拟深的划痕,可以尝试着用水蜡或许粗蜡启动打磨,用后成果会很显著,以上就是经常出现的细微划伤修复的方法,假设划伤很深就须要喷漆来解决了,汽车划痕如何修复,汽车划痕修复方法有打蜡、水砂纸打磨、牙膏涂抹,细微剐...。

1、领克汽车是由吉利控股个人吉利汽车个人与沃尔沃汽车合资成立的新时代上流品牌领克03是领克品牌第一款轿车产品,也是CMA基础模块架构打造的第一款轿车,于2018年8月31日亮相成都国内车展,并于2018年10月19日正式上市作为;LYNKCO中文名领克是由吉利控股个人吉利汽车个人与沃尔沃汽车合资成立的新时代上流品牌,集欧洲技术欧洲设计...。

原题目,国台办,需要美方切勿一再向,台独,权利收回失误信号,美在台协会,台北办事处参与台方组织的金门,八二三炮战,纪念优惠,称安保协作是美台同伴相关关键一环,蔡英文宣称,敌对靠的是松软的国防,,捍卫,主权,绝不畏缩,对此,国台办发言人马晓光示意,台湾是中国的一局部,台湾疑问决不准许外部权利插手干预,民进党当局挟洋自重,依仗外力加大寻衅...。

绘客数位板驱动是一款由绘客官方出品的数位板驱动,它除了可以为电脑识别和正常使用绘客T系列数位板提供支持以外,还支持设置数位板,包括工作区域、映射区域、笔压等,用户只需将数位板连接电脑并安装此驱动即可使用。功能特点1、106英寸大板:拥有106英寸大感应板面,只有大舞台才能将您的才艺尽情展现,绘客数位板出厂自带石墨膜,使用寿命更长2、8192级压感:

PDF猫压缩是一款功能简单高效的解压缩软件,软件支持大部分的压缩包格式,解压缩速度快,提供多种解压缩方式,清晰优先、常规压缩、缩小优先三种压缩类型供用户选择,软件压缩速度快,有需要的小伙伴欢迎下载体验

吓尿!童年阴影这么搞!,宋慈,狄仁杰,欧阳震华,洗冤录2,洗冤集录,童年阴影

经历了三个月的奋战,国内疫情态势终于开始趋缓,伴随着多省市持续,0新增,,各地打响复工复产的口号,学生们开学复课也提上了日程,截止到3月28日,已经有17省市陆续公布了2020年春季具体的开学时间,疫情的阴霾逐渐消散,人们的生产生活回归正转,似乎一切都预示着曙光的来临,这场疫情阻击战即将吹响最终的号角,但对于一向反周期的教培行业来说,...。

不到20天GMV突破百万,经营中心转向了淘工厂,、,链接上架半个月成长至搜索TOP2,准备重点运营淘工厂,……9月13日,在北京举行的中国国际服务贸易交易会,以下简称,服贸会,上,淘工厂商家与产地发展负责人张鹏分享了几组淘工厂,星厂牌,商家成长的案例和数据,图说,淘工厂在,服贸会,上发布了,星厂牌计划,这些只是缩影,淘工厂,上淘...。

11月18日,比亚迪成立30周年暨第1000万辆新能源汽车下线发布会在深圳市深汕特别合作区比亚迪小漠工业园举办,发布会上,比亚迪股份有限公司董事长兼总裁王传福首次讲述比亚迪30年创业经历,从30年前小厂房里20人的创业团队,凭着,敢想、敢干、敢坚持,的工程师精神,发展到如今近百万名员工的世界级企业,比亚迪坚持用技术创新满足人们对美好生...。

2007年11月20日10,59,我得知央视新闻记者郦振国在西藏日喀则地区采访途中遭遇车祸牺牲的消息,虽然不认识他,甚至以前没有听说过这个名字,但听到这个消息,我心中不禁涌起了一种失去朋友般的悲痛感,今天,了解到更多的详情,尽管已是凌晨,我还是忍不住写下这篇文章,以此来表达对郦振国的悼念,同时也悼念那些为新闻事业献出生命的战友们,据同...。

1.江南布衣,这个品牌以设计新颖、风格独特的女装而闻名,适合追求个性化的20,35岁女性,2.哥弟和歌丽娅,这两个品牌提供多样化的时尚选择,适合不同场合穿着,是年轻女性的热门选择,3.千百惠,该品牌以优雅的设计和优质的面料受到许多都市女性的喜爱,4.太平鸟,太平鸟以其时尚、休闲的女装而受到20,35岁女性的青睐,5.艾格和ONLY,这...。
