连看好莱坞大片都学会了!贾佳亚团队用2token让大模型卷出新境界 (看看好莱坞大片)
家人们谁懂,连大模型都学会看好莱坞大片了,播放过亿的GTA6预告片大模型还看得津津有味,实在太卷了!
而让LLM卷出新境界的办法简单到只有2token——将每一帧编码成2个词即可搞定。等等!这种大道至简的方法有种莫名的熟悉感。不错,又是出自香港中文大学贾佳亚团队。
这是贾佳亚团队自8月提出主攻推理分割的LISA多模态大模型、10月发布的70B参数长文本开源大语言模型LongAlpaca和超长文本扩展术LongLoRA后的又一次重磅技术更新。而LongLoRA只需两行代码便可将7B模型的文本长度拓展到100k tokens,70B模型的文本长度拓展到32k tokens的成绩收获了无数好评。
这次,贾佳亚团队的新作多模态大模型LLaMA-VID,可支持单图、短视频甚至长达3小时电影的输入处理。须知当前,包括GPT-4V在内的多模态模型 [1,2,3]基本只能支持图像输入,面对实际场景中对多图像长视频的处理需求支持十分有限,面对几十分钟甚至几个小时的长视频更显无能为力。
可以说,LLaMA-VID的出现填补了大语言模型在长视频领域的空白。

电影搭子LLaMA-VID的一手体验
先拿最近爆火的GTA6预告片试试手感。

LLaMA-VID能够准确理解预告片里出现的场景,并能分析预告片中游戏吸引人的地方在于广泛的活动场景和惊艳的视觉效果。
而根据游戏中的场景和特征,LLaMA-VID还能推测出预告片是Rockstar公司游戏GTA6的推广,并说出游戏的背景城市为迈阿密。
针对网络上流行的短视频和图片,LLaMA-VID也不在话下。

LLaMA-VID能够分析短视频中知名表情包的笑点,因为视频中人物夸张的表情以及对周围人物的情绪感染不断加深并强化。

也能扮演“福尔摩斯”,像侦探来根据室内的环境分析人物性格。
接下来,LLaMA-VID将通过看经典电影来展示自己的看家本领。首先是励志、温情的《阿甘正传》:
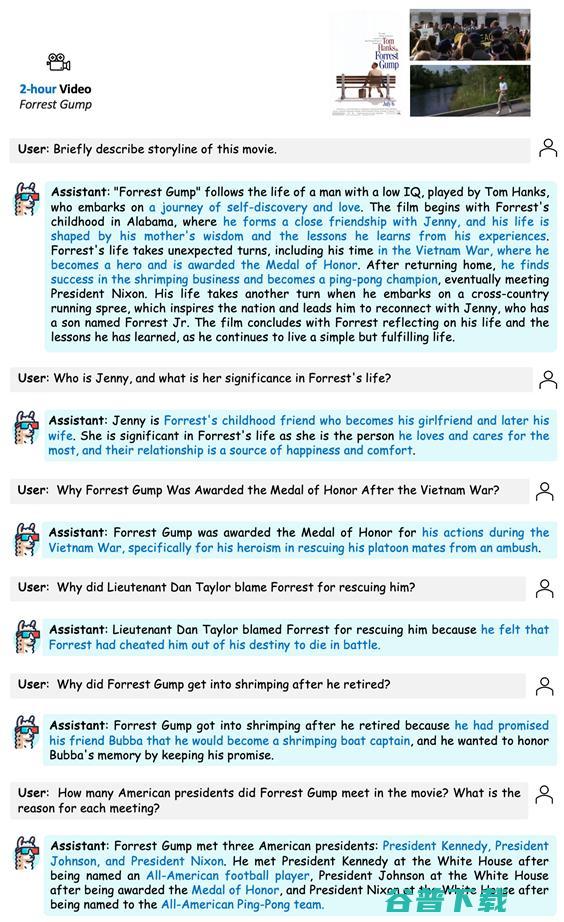
可以看出,LLaMA-VID对角色的理解与分析十分准确。
如珍妮对于阿甘的意义(孩童时期的朋友,后来成为阿甘的妻子,是阿甘生活和心灵的慰藉);阿甘在战争及退伍后的事件分析(丹中尉责怪阿甘救了自己,无法战死沙场),并对接见阿甘的美国总统如数家珍(肯尼迪、约翰逊、尼克松分别因为全美橄榄球运动员、越战荣誉勋章、和全美乒乓球队接见阿甘)。
这一次直接挑战超长视频,让LLaMA-VID看一部近3小时的、刺激的科幻大片《星际穿越》,并与其进行对话。
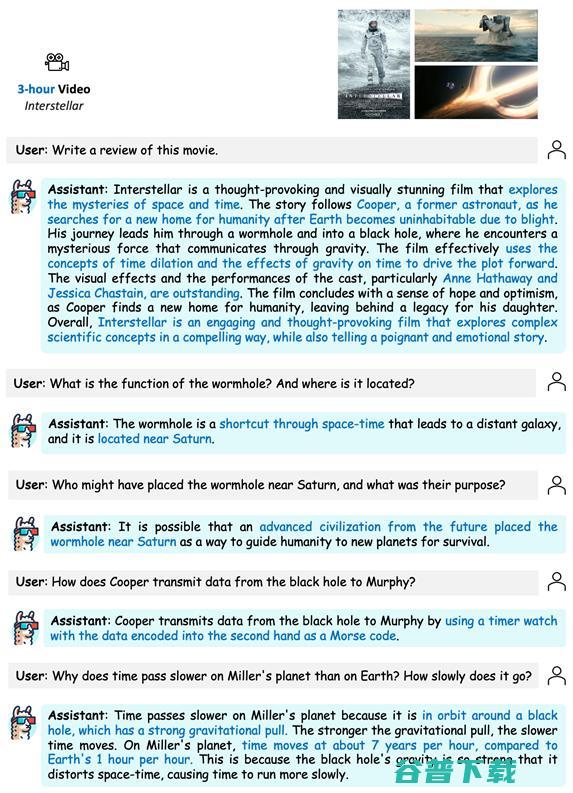
可以看出,LLaMA-VID不仅能结合电影情节和人物轻松对电影进行点评,而且能很精准地回答出剧中所涉的细节。
例如,虫洞的作用和创造者是谁(未来的智慧生物放置在土星附近,用于帮助人类进行远距离星际穿越),男主库珀是如何将黑洞中的信息传递给女儿墨菲(通过手表以摩斯密码的方式传递数据),以及米勒星球上相对地球时间的快慢及原因(米勒星球由于在黑洞附近,导致1小时相当于地球7年)。
不得不说,这个电影搭子实在太强大了,又狠话又多那种!
16个图片视频量化指标直接Promax
见识过电影搭子的超能力后,不妨来看看贾佳亚团队是如何开发LLaMA-VID的。
要知道,当前的多模态模型无法处理长视频的主要原因在于传统多模态大模型对单张图片的编码token数量过多,导致在视频时间加长后所需要的token数急剧增加,使模型难以承受。
以当前多模态大模型的技术标杆GPT-4V为例。由于每张图像都需要过多的Token进行编码,GPT-4V很难将所有的视频帧全部送入大模型。例如对于GTA6预告片(1分30秒)的输入,GPT-4V采用抽取5帧的策略进行逐帧分析:
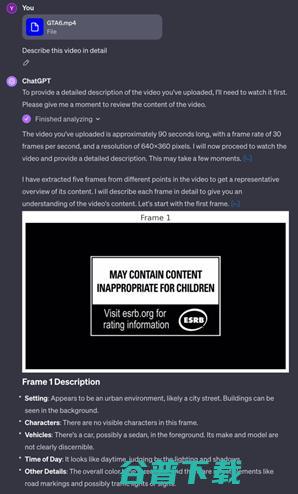

这不仅会使用户对视频内容无法获得直观的理解,并难以处理更长的视频输入。
如果让GPT-4V对视频进行统一分析,则会出现报错并无法处理:

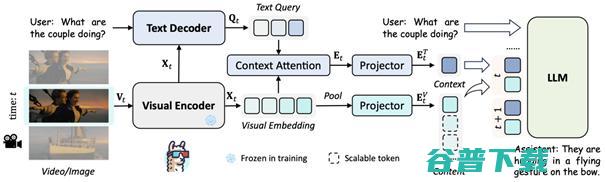
为解决这个问题,贾佳亚团队重新设计了图像的编码方式,采用上下文编码 (Context Token) 和图像内容编码 (Content Token) 来对视频中的单帧进行编码,从而将视频中的每一帧用2个Token来表示。
其中,上下文编码根据用户输入的问题生成,从而保证了在极限压缩视频消耗的同时,能尽可能保留和用户问题相关的视觉特征。而图像内容编码则更加关注图像本身的内容信息,来对上下文编码未关注到的环境进行补充。
简单来说,对于上下文编码 (Context Token),LLaMA-VID利用文本解码器(Text Decoder)根据用户的输入和图像编码器(Visual Encoder)提取的特征来生成输入指令相关的跨模态索引(Text Query),并使用所生成的索引对图像编码器生成的特征利用注意力机制(Context Attention)进行特征采样和组合,从而生成高质量的指令相关特征。
而对于图像内容编码 (Content Token) ,LLaMA-VID直接根据用户需求对图像特征进行池化采样。这对于单张图片或短视频,可保留绝大多数的图像特征从而提升细节理解,而面对几个小时的长视频时,则可将每帧的图像特征压缩成2个Token。
用这种方式,LLaMA-VID可以将3个小时的电影或视频精简为数个Token,直接使用大语言模型进行理解和交互。
这种Token生成方法非常简洁,仅需几行代码即可实现高效的生成。

此外,LLaMA-VID还收集了400部电影并生成9K条长视频问答语料,包含电影影评、人物成长及情节推理等。结合之前贾佳亚团队所发布的长文本数据集LongAlpaca-12k(9k条长文本问答语料对、3k短文本问答语料对), 可轻松将现有多模态模型拓展来支持长视频输入。

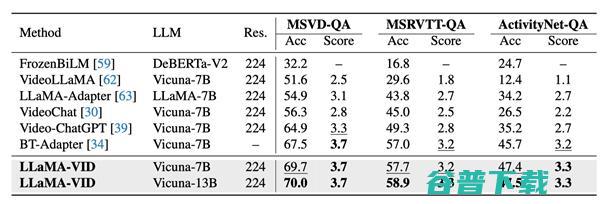
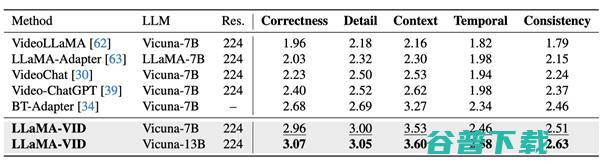
在16个视频、图片理解及推理数据集上实现了promax的效果
与现有方法相比,LLaMA-VID所提出的创新之处在于,仅用2个Token来处理视频中的图片即已大幅超越以往的模型,在MSVD-QA,MSRVTT-QA,ActivityNet-QA等多个视频问答和推理的榜单上实现了SOTA。而随着语言模型的增大,效果还能进一步增强。
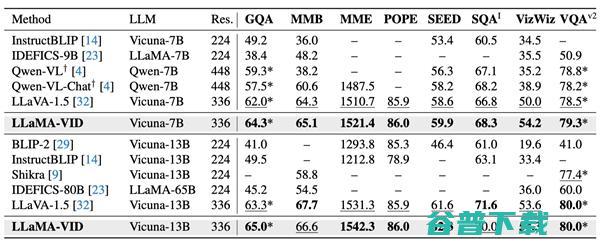
而面对现有的多模态模型如LLaVA-1.5,LLaMA-VID仅需加入1个所提出的上下文编码 (Context Token)拓展,能在GQA、MMBench、MME、SEED等8个图片问答指标上获得显著的提升:
值得一提的是,LLaMA-VID的视频理解和推理能力已经出了Demo,可以在线跟电影对话的那种。
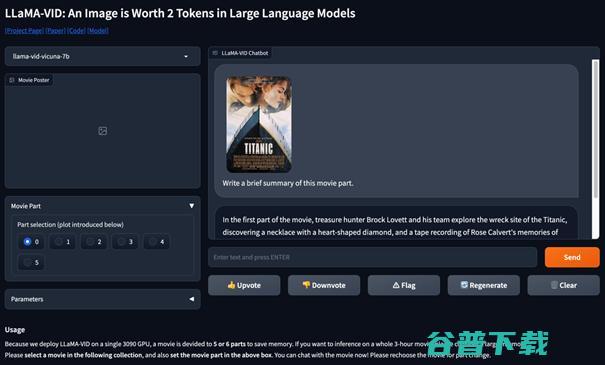
操作也极其简单,只需选择电影海报和对应的电影段,即可直接和电影交流(部署在单块3090,需要的小伙伴可以参考code用更大的显存部署,直接和整个电影对话)。
同时也支持用户上传短视频进行互动。

如果对描述指令有疑惑的,Demo也给出了一些示例,感兴趣的小伙伴们不妨来pick一下这个电影搭子。

Github地址:
Demo地址:
论文地址:
参考文献
[1] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv:2306.02858, 2023.
[2] KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv:2305.06355, 2023.
[3] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatGPT: Towards detailed video understanding via large vision and language models. arXiv:2306.05424, 2023.
版权文章,未经授权禁止转载。详情见 转载须知 。


面向全国的经销商及消费者,提供汽车报价、购车指南、汽车法规、车型介绍、进口汽车、国产汽车、汽车维修、二手汽车、汽车保险、汽车论坛、违章查询、车市分析、修车养车、汽车改装、降价信息等。

9377手游是国内火爆的手机游戏平台,多款热门游戏随心下载,经典奇迹荣耀归来,休闲塔防小游戏玩不停;更有游戏助手畅玩云游戏,社区福利领不停!来9377手游,一起玩更快乐。

TOSAFE(拓西)专业生产和销售逃生门锁、消防通道锁、推杠锁、防火门监控器、联动闭门器、闭窗器、电磁门吸、防火锁、消防锁、温控防火窗启闭装置、防火门监控系统、常闭式防火门控制系统、常开式防火门控制系统、活动式防火窗控制系统及其它一些建筑消防系统产品。

天津市禹王防水有限公司是中国防水协会会员单位,是专门从事防水材料生产和防水施工的专业公司,占地3万平方米,总资产4000多万元。公司经过二十余年的发展,现已成为集防水材料生产、防水施工、桥面凿毛处理、路面封层处理、土工材料五大门类,集科研、设计、生产、施工成套服务为一体的综合性公司。

164580谐音“要螺丝,我帮您”,帮您实现小螺丝的大梦想。专业的标准紧固件、非标紧固件、塑料螺丝、钢丝螺套、不锈钢螺丝采购平台。

临淄区朱台镇科龙厨房设备厂是一家甲醇灶、醇基燃料灶、大锅灶、灶壳、植物燃油灶等产品的生产供应厂家,作为两炒一温甲醇灶、不锈钢大锅的供应批发商,产品深受多地欢迎。

极米科技专注于智能投影和激光电视领域。公司主要产品包含RS系列投影、H系列投影、Z系列投影、便携系列投影和激光电视系列等。

卡盟达优选是一款为签约站长定制的外卖管理系统,提供高效可视化的操作界面和各种实用管理工具。通过卡盟达优选,用户可以轻松管理外卖业务,享受最便捷、高效、优质的电子商务服务体验。该系统由卡盟达优选领先的技术研发团队打造,为广大用户提供全面的系统支持和服务。

嗨球科技立足于体育产业,借助互联网技术和创新商业模式整合优质体育资源聚焦于体育大数据、足球青训、体育文产三项业务,是集规划、设计、运营于一体的体育产业策划运营商同时也是集数据和资讯服务于一体的综合性体育数据平台。

云IDE首页

义乌康源生殖综合门诊部主要针对前列腺、生殖器感染、性功能障碍、生殖整形、男性不育等进行有效的治疗,义乌康源男科综合门诊部拥有专业的医生一对一在线咨询:0579-85821788


要知道给别人打工怎么着都不如自己创业做老板好,现在很多人都想要开美容院,毕竟现在不只是女生会去做美容,男生们平时也会去做美容了,因此美容院的市场是越来越大了,那新手想开美容院怎么入手呢美容院的装修如果是一个新客户进美容院,首先关注的肯定都是美容院的环境情况,因为当美容院的环境非常好,吸引消费者进门的时候,才可以让她们产生想要进行美容的...。
今日傍晚,华为云BU总裁郑叶来发微博就,开源,和,自主可控,的话题分享了个人观点,引发评论,原文如下,互联网公司真是善于转移矛盾的焦点,我们学不会啊!所谓开源和自主可控问题,本不想回应这个,中山装和西装,式的问题,但考虑到很多人已经被搅糊涂了,分享一下我的几个观点,1、从应用的连续性出发,相当长时间政府和企业都会使用混合云解决方案,也...。

由中国中文信息学会社会媒体处理专委会主办、哈尔滨工业大学承办的第七届全国社会媒体处理大会,SMP2018,将于2018年8月2,4日在哈尔滨召开啦,目前购票注册即享早鸟优惠,7月11日将恢复原价,详情请戳http,smp2018.cips,smp.org,register.htmlSMP专注于以社会媒体处理为主题的科学研究与工程开...。

斯坦福大学的ChelseaFinn团队又出新成果了,ChelseaFinn团队一直是斯坦福走在具身智能研究前沿的团队之一,之前火遍全网的ALOHA炒菜机器人就是出自这个团队之手,团队领头人ChelseaFinn的创业公司Pi更是创立不到一个月就拿下来自红杉资本、OpenAI等公司的7000万美元融资,最近,ChelseaFinn团队在...。

腾讯云副总裁沙开波在开场致辞中表示,腾讯云分布式云形成了不同云计算形态、不同部署位置和不同规模的全场景覆盖,即便是强合规的政府、金融等场景,腾讯云分布式云都能通过加速云边端协同,实现一致管理、高效便捷的建云、上云、用云、管云,助力企业IT降低部署和维护成本,可以说,腾讯云分布式云已经成为企业数字化转型云平台底座的首选,中国信通院云...。

发表在当贝投影仪2022,12,911,30当贝U1和坚果O1S是如今销量火爆的两款超短焦产品,其中当贝U1采用的是激光光源,而坚果O1S则是LED光源,具体两款投影仪在相同环境下有怎么样的画质表现呢,下面就为大家分享,看看当贝U1和坚果O1S画质实拍对比效果究竟如何,看看哪款投影仪的画质表现更好,当贝U1和坚果O1S画质实拍对比既然...。

发表在专业问答2023,6,1213,52展示机型信息,品牌型号,当贝F6系统版本,当贝OS4.01920×1080是形容分辨率的,表示画面分辨率达到1080P,并不能用分辨率来判断尺寸大小,屏幕分辨率仅决定定位图像的细节,在显示屏上使用时,仅仅表示显示屏的清晰度,1920x1080是多大尺寸1920x1080是全高清分辨率,意思是长...。

怎么安装软件看电视直播教程,具体方法如下,最新方法怎么看电视台,只需要在电视上装一个当贝市场就可以轻松解决,1、下载当贝市场,http,www.dangbei.com,安装包并拷贝到U盘,2、打开东芝电视,按下遥控器的设置键,打开设置界面,点击,更多设置,3、在设置界面找到,通用,选择,商场模式,,把商场模式改为,开启,状态,4...。

1、玛莎拉蒂底盘100mm左右,这车的底盘适宜在较好的路上传驶总裁系列的地盘比GT高一点点玛莎拉蒂Maserati是一家意大利奢侈汽车制作商,1914年12月1日成立于博洛尼亚Bologna,公司总部现设于摩德纳Modena,品牌的标记,2、有玛莎拉蒂gt依据厂商在出厂时设置是可以其显示屏是可以和手机衔接的,因此是有蓝牙的玛莎拉蒂GT...。

奇瑞共有21个车系,微型车有QQ3,QQ6,QQme,旗云1,瑞麒M1五款车;小型车有风波2,A1,瑞麒M5三款车;紧凑型车有A3,A5,停产,,旗云,停产,,旗云2,旗云3,风波,停产,,瑞麒G3,未上市,六款车;中型车有西方之子和瑞麒G5二款车;中大型车西方之子6,未上市,和瑞麒G6,未上市,二款车;MPV车西方之子Cross,停...。

剑灵剑客技能加点,剑灵What加点?剑灵移动武士加点剑灵移动武士加点降剑式。剑灵剑客加点How加点剑客1,首先是回内的技巧,毫无疑问,剑会在4点钟归还,剑灵召唤技能加点题主是否想问“剑灵召唤师技能加点什么”?How剑灵刺客的天赋加点本教程介绍刺客的天赋剑灵希望对你有所帮助。1、剑灵职业PVE加点基础攻略只气功篇上一个版本的气功在PVE的效果并不理想,但是这一次PVE的气功有了很大的提升,伤害系数全面加强,使得气功在副本输出中有了相当的地位。气功的输出手法是有分类的,但是这两种加点是完全不同的。一类是常规的

方正T36扫描仪驱动,方正T36扫描仪驱动是这款方正t36扫描仪的官方驱动程序,安装驱动后,扫描仪才能正常工作,有需要的赶快下载吧!,您可以免费下载。

01Testbuy赶跟卖针对FBM的跟卖,可以做做Testbuy赶跟卖,用新的vps注册一个买家号,买家号不要去买,自己注册的就好了,不然容易被取消订单,先在跟卖店铺下测试单,并且发邮件警告,如果不停止跟卖就开ATOZ,申请退货,一般跟卖就会撤走了,或者找国外真人买家购买产品,举报这个跟卖的上架的产品货不对版,02Pengding赶跟...。

消费者希望能够在丰富的选择中,品尝到美味的火锅,他们对火锅菜品的选择标准,主要包括味道、新鲜程度、菜品种类多样性和食材质量,今天,小朝哥就为公布一下,受消费者喜爱的火锅菜品排名,一、虾滑和牛肉虾滑的鲜美口感和丰富的营养价值,得到了消费者的高度认可,尤其是在夏季,虾滑几乎成为了人们的共同选择,其次,牛肉也是备受消费者喜爱的火锅菜品之一,...。

在深圳,低空经济应用又添新场景,10月23日,美团无人机福田口岸航线正式开航,这是国内首条设在口岸区域的常态化无人机配送航线,航线开通后,每日在港深之间往返的市民,在口岸附近点外卖或可享受,空投,服务,下单后最快10分钟即可在指定降落点取货,省去了在过万人群中找寻自己外卖员的烦恼,▲国内首条口岸场景无人机配送航线在深开航,管乐摄,为了...。

雷锋网消息,2月26日,51Talk在京举行2019年战略发布会,现场,51Talk创始人兼CEO黄佳佳宣布,51Talk要做第一家全国普惠在线教育品牌,在此基础上,51Talk发布了致力于教育普惠的,1,2,1,战略及H5互动教学产品,妖果AI,,并联合金鹰卡通卫视、幼教品牌巧虎、美国知名出版社TCM成立了普惠教育联盟,活动现场,黄...。

2023年4月1日,上海市公安局闵行分局发布警情通报,称一名37岁的华山医院医生周某某在新龙路某小区内,因家庭纠纷将其32岁护士妻子徐某某掐脖致死,案发当天上午,邻居们发现两人发生激烈争吵并伴有肢体冲突,遂报警请求帮助,警方接到报警后迅速赶到现场,但未能立即进入房间,最终在控制住周某某后发现徐某某已无生命迹象,周某某被控制,徐某某的母...。
