在无人驾驶中 激光雷达给摄像头填了哪些坑 (在无人驾驶中摄像机提供的感知能力有哪些)

编者按:本文内容来自速腾聚创 CEO 邱纯鑫在雷锋网硬创公开课的分享,由雷锋网旗下栏目“新智驾”整理。

激光雷达与摄像头性能对比
在无人驾驶环境感知设备中,激光雷达和摄像头分别有各自的优缺点。
摄像头的优点是成本低廉,用摄像头做算法开发的人员也比较多,技术相对比较成熟。摄像头的劣势,第一,获取准确三维信息非常难(单目摄像头几乎不可能,也有人提出双目或三目摄像头去做);另一个缺点是受环境光限制比较大。
激光雷达的优点在于,其探测距离较远,而且能够准确获取物体的三维信息;另外它的稳定性相当高,鲁棒性好。但目前激光雷达成本较高,而且产品的最终形态也还未确定。
就两种传感器应用特点来讲,摄像头和激光雷达摄像头都可用于进行车道线检测。除此之外,激光雷达还可用于路牙检测。对于车牌识别以及道路两边,比如限速牌和红绿灯的识别,主要还是用摄像头来完成。如果对障碍物的识别,摄像头可以很容易通过深度学习把障碍物进行细致分类。但对激光雷达而言,它对障碍物只能分一些大类,但对物体运动状态的判断主要靠激光雷达完成。

多线激光雷达----多少线合适?
目前,国外和国内做激光雷达的厂商并不多。比如 Velodyne 推出 16 线、32 线和 64 线激光雷达产品。Quanergy 早期推出的 8 线激光雷达产品 M-8(固态激光雷达在研)。Ibeo 主要推出的是 4 线激光雷达产品,主要用于辅助驾驶。速腾聚创(RoboSense)推出的是 16 线激光雷达产品。
到底多少线的激光雷达产品才能符合无人驾驶厂商,包括传统汽车厂商、互联网造车公司的需求?
多线激光雷达,顾名思义,就是通过多个激光发射器在垂直方向上的分布,通过电机的旋转形成多条线束的扫描。多少线的激光雷达合适,主要是说多少线的激光雷达扫出来的物体能够适合算法的需求。理论上讲,当然是线束越多、越密,对环境描述就更加充分,这样还可以降低算法的要求。
业界普遍认为,像谷歌或百度使用的 64 线激光雷达产品,并不是激光雷达最终的产品形态。激光雷达的产品的方向肯定是小型化,而且还要不断减少两个相邻间发射器的垂直分辨率以达到更高线束。
激光雷达产品参数包括四方面:测量距离、测量精度、角度分辨率以及激光单点发射的速度。我主要讲分辨率的问题:一个是垂直分辨率,另一个是水平分辨率。
现在多线激光雷达水平可视角度是 360 度可视,垂直可视角度就是垂直方向上可视范围。分辨率与摄像头的像素是非常相似的,激光雷达最终形成的三维激光点云,类似于一幅图像有许多像素点。激光点云越密,感知的信息越全面。
水平方向上做到高分辨率其实不难,因为水平方向上是由电机带动的,所以水平分辨率可以做得很高。目前国内外激光雷达厂商的产品,水平分辨率为 0.1 度。
垂直分辨率是与发射器几何大小相关,也与其排布有关系,就是相邻两个发射器间隔做得越小,垂直分辨率也就会越小。可以看出来,线束的增加主要还是为了对同一物体描述得更加充分。如果是不通过减少垂直分辨率的方式来增加线束,其实意义不大。
如何去提高垂直分辨率?目前业界就是通过改变激光发射器和接收器的排布方式来实现:排得越密,垂直分辨率就可以做得很小。另一方面就是通过多个 16 线激光雷达耦合的方式,在不增加单个激光雷达垂直分辨率的情况下同样达到整体减小垂直分辨率的效果。
但是,这两种方法都有一定的缺陷。
第一种方法,如果在不增加垂直可视范围情况下增加线束,是有一定天花板的。因为激光发射器的几何大小很难进一步再缩小,比如说做到垂直 1 度的分辨率,如果想做到 0.1 度,几乎不可能。
第二种方法,多传感器耦合,即多个激光雷达耦合,因为它不是单一产品,那么对往后的校准将会有很高的要求。
 激光雷达和摄像头分别完成什么工作
激光雷达和摄像头分别完成什么工作
无人驾驶过程中,环境感知信息主要有这几部分:一是行驶路径上的感知,对于结构化道路可能要感知的是行车线,就是我们所说的车道线以及道路的边缘、道路隔离物以及恶劣路况的识别;对非结构道路而言,其实会更加复杂。
周边物体感知,就是可能影响车辆通行性、安全性的静态物体和动态物体的识别,包括车辆,行人以及交通标志的识别,包括红绿灯识别和限速牌识别。

对于环境感知所需要的传感器,我们把它分成三类:
今天主要讲的是感知周围物体的传感器,即:激光雷达、毫米波雷达和摄像头。其实他们都有各自的优缺点。

在无人驾驶环境感知中,摄像头完成的工作包括:

对车道线的检测主要分成三个步骤:
第一步,对获取到的图片预处理,拿到原始图像后,先通过处理变成一张灰度图,然后做图像增强;
第二步,对车道线进行特征提取,首先把经过图像增强后的图片进行二值化( 将图像上的像素点的灰度值设置为 0 或 255,也就是将整个图像呈现出明显的黑白效果),然后做边缘提取;
第三步,直线拟合。
车道线检测难点在于,对于某些车道线模糊或车道线被泥土覆盖的情况、对于黑暗环境或雨雪天气或者在光线不是特别好的情况下,它对摄像头识别和提取都会造成一定的难度。

另一个是障碍物检测。上图是我们在十字路口做的实验,获取到原始图像后,通过深度学习框架对物体进行识别。在这当中,做训练集其实是主要的难点。

还有一个是道路标识的识别,这一部分的研究比较多,这里不再赘述。

激光雷达能够完成什么工作?
第一是路沿检测,也包括车道线检测;第二是障碍物识别,对静态物体和动态物体的识别;第三是定位以及地图的创建。
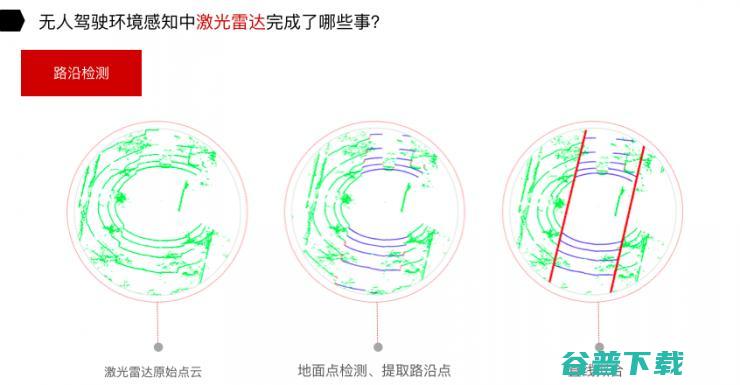
对于路沿检测,分为三个步骤:拿到原始点云,地面点检测、提取路沿点,通过路沿点的直线拟合,可以把路沿检测出来。

接下来是障碍物识别,识别诸如行人、卡车和私家车等以及将路障信息识别出来。

障碍物的识别有这样几步,当激光雷达获取三维点云数据后,我们对障碍物进行一个聚类,如上图紫色包围框,就是识别在道路上的障碍物,它可能是动态也可能是静态的。
最难的部分就是把道路上面的障碍物聚类后,提取三维物体信息。获取到新物体之后,会把这个物体放到训练集里,然后用 SVM 分类器把物体识别出来。

如上图,左上角、左下角是车还是人?对于机器而言,它是不清楚的。右上角和右下角(上图)是我们做的训练集。做训练集是最难的,相当于要提前把不同物体做人工标识,而且这些标识的物体是在不同距离、不同方向上获取到的。
我们对每个物体,可能会把它的反射强度、横向和纵向的宽度以及位置姿态作为它的特征,进行提取,进而做出数据集,用于训练。最终的车辆、行人、自行车等物体的识别是由SVM分类器来完成。我们用这种方法做出来的检测精确度还是不错的。

利用激光雷达进行辅助定位。定位理论有两种:基于已知地图的定位方法以及基于未知地图的定位方法。
基于已知地图定位方法,顾名思义,就是事先获取无人驾驶车的工作环境地图(高精度地图),然后根据高精度地图结合激光雷达及其它传感器通过无人驾驶定位算法获得准确的位置估计。现在大家普遍采用的是基于已知地图的定位方法。

制作高精度地图也是一件非常困难的事情。举个例子,探月车在月球上,原来不知道月球的地图,只能靠机器人在月球上边走边定位,然后感知环境,相当于在过程中既完成了定位又完成了制图,也就是我们在业界所说的 SLAM 技术。
激光雷达是获取高精度地图非常重要的传感器。通过 GPS、IMU 和 Encoder 对汽车做一个初步位置的估计,然后再结合激光雷达和高精度地图,通过无人驾驶定位算法最终得到汽车的位置信息。
高精地图可分为基础层、道路信息层、周围环境信息层和其他信息层。
比如基础层,有车道的宽度、坡度、倾斜角、航向、高程、车道线信息、人行道和隔离带等等。之后还有信息层,相当于告诉每一个道路上限速的标记、红绿灯标记,还有一个就是环境信息层,相当于周围建筑物的三维模型。其他信息层,比如说天气信息、施工信息等等,天气信息非常重要,它提供一个场景信息,比如说天气非常恶劣的时候,比如下雨天,如果高精度地图能提供天气信息,或者无人驾驶汽车车身所携带的传感器,能够感知到下雨信息,这时非常有利于指导无人驾驶汽车做一些决策。
现在对高精度地图的定义,不同地图厂家有不同定义的方式。做高精度地图是为了辅助无人驾驶,所谓高精度地图就是相比之前的导航地图,前者精确度更高,可以达到厘米级;另一个就是高精度地图包含更多的信息量,比如说车道的宽度、倾斜度等信息。
激光雷达与摄像头的融合

激光雷达与摄像头融合,其实相当于是激光雷达发挥激光雷达的优势,摄像头发挥摄像头的优势,他们在某些地方是做得不够好,需要两个传感器甚至多个传感器信息进行底层的融合。
在融合的时候,首先第一步,标定。比如说左上角(上图),我看到凳子,左下角激光雷达也看到的是凳子,那么我通过标定的方式告诉它,其实两个是同一个物体。
其实摄像头发现同一个物体是非常容易的,比如做人的跟踪或车的跟踪。对于激光雷达而言, 要去识别前后帧是否同一辆车和同一个行人是非常困难的。

激光雷达有一个好处:如果可以通过摄像头告诉它前后两帧是同一个物体,那么通过激光雷达就可以知道物体在这前后两帧间隔内:运动速度和运动位移是多少。这是非常关键的,因为只有做运动物体的跟踪才能做一些预测。
人在驾驶的过程中,他得时刻知道周围物体的运动状态。对于无人驾驶,除了对车辆进行位置的估计以及导航之外,其实还需要对周边物体、运动物体的跟踪和预测,这是非常有意义的。
精彩问答:
问:高精度地图的制作,是不是应该与 SLAM 的建图结合满足在无 GPS 下的定位?
邱纯鑫: 这是对的,我们也用 SLAM 的方式去局部做地图构建,刚开始如果做高精度地图,还是得用 SLAM 方法去做。
有些道路,特别是城市道路或巷道,GPS 非常不可信。所以说大家还是得充分考虑在有 GPS 如何去制作高精度以及在没 GPS 情况下如何去做高精度地图。
问:考虑到对远距离小物体的检测,需要激光雷达有更高的水平角分辨率,那么目前 0.1 度的角分辨率能不能再提升,限制在哪里?
邱纯鑫: 水平分辨率 0.1 度可以做得更小,这个没有限制,激光雷达单点出点数做得更高没问题。垂直分辨率确实是有限制,除非用固态激光雷达,要不然现在通过多个激光发射器和接收器堆叠的方式来实现 0.1 度的角度分辨率几乎是很难再提升了。
假如说激光雷达角度分辨率还有出点数已经满足要求。那么,剩下一个问题就是过车规,毕竟激光雷达是安装在车上的。所以车的温度,湿度,抗震性都要充分考虑。
目前激光雷达本身有两个主要的问题:一方面是雷达本身的参数是否可以提高;另一方面是如何过车规。
问:你认为目前激光雷达用于自主车驾驶和 SLAM 研究中还有哪些亟待解决的科研和技术问题?另外,激光雷达和相机的融合,您觉得用于车载 SLAM 的话最好是和几个(单目、双目、三目、全景)相机的融合?在相机和激光雷达融合中,您觉得还有哪些亟待解决的科研和技术问题?
邱纯鑫: SLAM 不仅仅是无人驾驶汽车的问题。对 SLAM 而言,一个是定位,一个是制图。
目前看,在拼接尤其是前后两帧拼接的时候,如何才能拼接得更加准确;另一个是多次拼接的时候,如何能够覆盖累计的误差。比如,做一个大闭环,第一次扫描到的环境就很难跟第 1000 个拼接起来,能否做到全局的校准?所以我觉得 SLAM 的问题不仅仅是无人驾驶的问题,可能室内存在 SLAM 的问题。
激光雷达和相机的融合,到底用单目,双目,三目还是全景去做。其实我们现在用的是单目,利用单目相机对物体速度的识别主要还是通过标定的方式,然后看物体在图片中所占据的大小,从而来做大致的距离估算。
目前大家用双目的想法,其实还主要是解决单目对距离无法判断的问题。双目、三目和全景我们还没有去尝试,所以不太好判断。
问:激光雷达的设备体积,理论上最小能达到多少?成本如果大批量生产的话可以缩减到多少?有可能进入 3D 成像领域么?
邱纯鑫: 目前我们也想把它体积做到更小,并在更小的情况下能够做到线数越多。目前还没有一个理论说最小能做到多小,但体积做太大已经没有意义。
如果未来推出固态激光雷达产品,比如体积只有一个指甲盖的大小,那么它的应用领域,肯定不仅仅是在无人驾驶上,还可以应用到其他领域。
问:对应图像数据使用 OpenCV;那么,点云数据的处理,目前都有哪些主流开源库可供使用?
邱纯鑫: 目前还没有很好的一个开源库。之前有一个叫 PCL(Point Cloud Library),我觉得这个库做得并不好,所以我们也没怎么去用,还是自己在做。
问:相机和激光雷达融合中还有哪些要去解决的技术问题?
邱纯鑫: 首先是标定,如何标定才更好?再有一个就是时间戳的问题。相机在这一时刻获取到的图片跟激光雷达获取到的三维信息如何很好匹配下来。算法融合,运动物体跟踪,通过摄像获取同一个物体,通过激光雷达去识别同一个物体的距离信息。
原创文章,未经授权禁止转载。详情见 转载须知 。


诗词赏析网为您提供全面、准确的汉语诗篇,包括诗词、古诗、诗歌、散文、随笔、美文等诸多内容。

月饼网提供国内外时事热点资讯,实时更新每日资讯,精选社会热点、汽车热点、科技资讯、互联网动态、娱乐、生活、教育、时尚等行业资讯信息,打造专业资讯阅读平台。

上海唐仪电子科技有限公司(www.shtangyi.com)是专业的甲苯,二甲苯气体检测仪,一氧化碳浓度检测仪,氰化氢浓度检测仪供应商,多年来,公司致力于分析测量技术、工程组网技术以及智能化软件分析管理技术的研究开发,在各种气体检测仪器、气体分析仪器、环境监测仪器、环境集成监测监控系统等设备及系统的研发上方面取得了重大的突破。欢迎来电洽谈

今天学啥是职业教育资格考试培训门户网站,给广大考生提供金融、职业、建筑、财会、外语、考研等专业考试资讯、报名时间、成绩查询、真题答案等考试服务是各类考生顺利通过考试的好帮手也是培训机构招生的最佳渠道。

在线测吉凶免费提供车牌号码吉凶查询,如果你刚拿到车牌号,就赶紧来测试一下车牌号吉凶吧。

五彩缤纷的童年,是快乐的开始。无论何时我们都可以保持童心,用绘画放松心灵,享受美好时光!童年简笔画专注于优质简笔画分享。网站收集了大量优质的、简单易学的简笔画及教程,让我们一起享受画画带来的美好时光吧!

安居搜房为您提供全国各地最新最全面的新房、二手房楼盘信息以及各地区2018年房价走势图,及时了解各地楼市实时新闻快讯、房地产资讯、政策法规、购房百科、旅游攻略等最新消息,无论是选房还是看房,所有问题答案均在安居搜房房地产信息网!

宁夏禾牧欣农牧科技有限公司是专业的牛羊生物发酵饲料厂家,自主研发的专利技术,使产品牛羊肉达到国家富硒标准。公司主营富硒滩羊饲料、牛羊预制饲料、牛羊育肥饲料、牛羊专用饲料、牛羊饲料预混料及牛羊饲料批发等。产品畅销宁夏吴忠、中卫、固原、内蒙、甘肃、陕西、青海等地。

陕西省老医协生殖医学医院(西安生殖医学医院)是西安市正规男科医院,医院以前列腺疾病、性功能障碍、包皮包茎、生殖感染、及泌尿外科疾病为主要诊治项目,医院环境优美,医护人员热情专注。

苏州传奇农业科技有限公司

启与高哦付游戏网-启与高哦付游戏网。

上格房产网是一个房产知识平台,分享房产、装修、家居、家电等房产内容,为用户提供有价值的知识


香港服务器想要备案该怎么办?使用香港服务器的用户基本都是国内用户,为了方便节省时间成本的目的,而且对网站各方面还没什么影响,开通即用,而国内服务器在建设网站时,上线需要进行备案才能开通访问,香港对网站服务器的管理也比较宽松,所以很多用户在网站服务器上都喜欢选择香港服务器,对优化排名效果也是很好的,然而最近由于对互联网的进一步管理,使得...。
今天给大家介绍个空闲时间可以赚钱的纯,信息差,项目,导航地图标注商家,导航地图标注是什么?很多开车出行的朋友都应该用过百度地图、高德地图或腾讯地图,在搜索框搜索商家名称可以找到商家位置,地图搜索与网站关键词搜索相比更为直观,所以对于商家而言,地图搜索绝对是一种商业属性的推广,既然是一种推广,就能为商家带来收益,所以商家需求也就自然生成...。

朝九晚五的工作是常态,但是对于有家庭有孩子的人们来说,就会与自己的生活轨道相冲突,选择了工作,就没有时间照顾孩子,那就选择托管中心解决这一实际问题,像是贝尔安亲托管就有着不错的口碑,那么,贝尔安亲托管的费用高吗,有假期托管课程吗,贝尔安亲托管的费用高吗贝尔安亲托管的加盟费用是一个区间数据,灵活去选择就不会带来过重的加盟负担,为了给孩子...。

堂堂一国总统,冲动地发动一场自我政变,但最后却这样虎头蛇尾,这是对国家的不负责任,对政党的不负责任,事实上,也是对他自己和夫人的不负责任,...。

发表在综合交流大区2024,7,515,33暑假不知不觉来了,小朋友们终于迎来了每年最长的假期了,可以好好看电视了,但是家长会担心孩子看电视近视,那么暑假用什么看电视不容易近视呢,暑假适合小朋友看电视的设备有哪些,下面就分享对人眼刺激小的设备,一、暑假用什么看电视不容易近视答案是投影仪,投影仪是通过漫反射进行成像的,具体是将光投射在墙...。

寻找好的陪聊平台,体验玩家通常会推荐微信公众号,尤其是微信公众号小酒馆的树洞,提供了丰富且贴心的互动体验,在这里,你可以享受到陪聊、陪玩、哄睡的温馨服务,甚至还有温柔的提醒,帮助你按时起床,无论你感到不开心还是无聊,这里都能提供一个倾诉的平台,小酒馆的用户群体中,小哥哥小姐姐们以其出色的颜值,为平台增添了一抹亮丽的风景线,他们不仅外貌...。

我和好友在6月25日携程APP,订购了价值16910元的七日五晚菲律宾长滩岛自内行,这是一个双人机票和酒店打包的套餐,出行时期是8月22日至8月28日,订购后,由于机票不时未出票号感觉十分奇异,在7月5日与客服电话咨询,客服示意,机票保证没有疑问,假设由于他们机票的要素不可成行,携程会做出2,3倍的抵偿,截止至8月12日,购置的套餐机...。

一共有十二个星座,详细如下,白羊座,3月21日~4月19日金牛座,4月20日~5月20日双子座,5月21日~6月21日巨蟹座,6月22日~7月22日狮子座,7月23日~8月22日处女座,8月23日~9月22日天秤座,9月23日~10月23日天蝎座,10月24日~11月22日射手座,11月23日~12月21日魔羯座,12月22日~1月1...。

我以为9元时代曾经是最高的油价,后续不会再有下跌的空间,一,国际油价迈入九元大关,只管如今有很多人选用新动力汽车,但是毕竟开燃油车的车主还是更多一点,有车的车主都知道去加油站加油的时刻,油分为92和95,咱们不时比拟关心的油价也进入了一个新的高度,国际的油价终于迈进了九元大关,其实这个九元大关指的是九五,由于九二的油价在8.6元每升左...。

林肯市区引擎概述林肯市区,这款大型奢侈轿车,曾经风行一时,搭载了两款弱小的人造吸气发起机,4.1升和4.6升,为其提供了澎湃的能源,其中,4.1升人造吸气发起机是一款V8结构的能源源,能够输入最大功率164kw,并在3000转每分钟时到达最大扭矩372牛米,该发起机融入了多点电喷技术,且驳回了铝合金缸盖和缸体,轻量化设计有助于优化燃油...。

出口公众迈腾和国产公众迈腾的半轴长度是相反,,出口公众和国产公众不一样的就是排量不同,性能不同,外观的差异是不显著的,国产公众迈腾的性能弱一点,出口公众的迈腾性能高一点,很多物品都比拟耐磨,还有就是开起来的舒过度不同,进行快慢也不一样,假设可以还是选用出口的公众迈腾,最后一代原汁原味的公众车,如今再想感触可没时机了!不少好友想知道这辆...。

重庆分类目录网站收录软件相关的优秀网站大全分类检索,为上网用户提供软件网站排行榜与您分享、收藏!

随着网络普及,各种联机游戏极其丰富,高品质3a大作纷纷呈现,玩家在开放世界中自由探索,但有一部分玩家依旧想要选择适合一个人长期玩的单机手游,此类型游戏不需要受网络所限制,随时随地打开游戏就能体验,单机类型游戏进度及玩法由自己决定,今天为大家推荐几款比较耐玩的单机游戏,单机类型中的精品游戏被称为国民级塔防手游,作为正统续作及正版ip,画...。

9月22日消息,据TechPowerUp消息,明基今日发布三款全新4KHDR智能投影机,专为3A游戏设计,据报道,明基新款投影仪型号为X3100i、X500i和X300G,售价分别为2399美元,当前约17537元人民币,、1699美元,当前约12420元人民币,和1799美元,当前约13151元人民币,参数方面,X3100i、X5...。

年轻人理想中的家是什么样子,从客厅到卧室,都是自己喜欢的二次元画风;从冰箱到空调,也都有自己挑选、搭配的,皮肤,,里里外外都是元气满满的动漫感,这样的生活,什么时候才能实现,5月26日,以,Z力场·次元穿越,为主题的Leader品牌发布会在东莞启动,现场发布的全球首套Leader,养成系,家电,就让这样的生活成为了现实,大家总以为家电...。

在蛋白质,小分子复合体预测方面,,药物设计和酶设计,等领域的项目未来是否加速落地,当下火热的AIGC技术,能为AI生命科学领域带来多少可能,在CASP比赛创建者JohnMoult教授看来,这一比赛从来不是闭门造车,或是学术界的圈地自嗨,2018年,在第13届CASP比赛中,一个顶着谷歌子公司帽子的参赛选手亮相,其AlphaFold系统...。

其实我们在互联网做的绝大部分引流操作,都是流量借力,当下,大部分巨头占据着互联网、移动世界的头部地位,除了它们以外,另一些在当今互联网世界占据主流和一线位置的企业,在风投资金的支持下,也开始瓜分头部世界,对于新创业团队来说,越来越难以挤入,头部,位置,我们既然挤进头部位置是几乎不可能的,那我们就要学会在巨头上面生存,对于我们而言,这才...。
