助力 Python 老司机都开火箭了!Cython 实现百倍加速 NLP (助力油和液压油一样吗)

SpaceX 猎鹰重型发射器,版权归
在去年我们发布了用 Python 实现的 基于神经网络的相互引用解析包(Neural coreFerence resolution package) 之后,在社区中获得了惊人数量的反馈,许多人开始将该解析包用到各种各样的应用中,有一些应用场景甚至已经超出了我们原本设计的对话框用例(Dialog use-case)。
后来我们发现,虽然这个解析包对于对话框消息而言,解析速度完全够用,但如果要解析更大篇幅的文章就显得太慢了。
因此我决定要深入探索解决方案,并最终开发出了 NeuralCoref v3.0 。这个版本比之前(每秒解析几千字)的要快出百倍,同时还保证了相同的准确性,当然,它依然易于使用,也符合 Python 库的生态环境。
在本篇文章中,我想向大家分享我在开发 NeuralCoref v3.0 过程中学到的一些经验,尤其将涉及:
我的标题其实有点作弊,因为我实际上要谈论的是 Python,同时也要介绍一些 Cython 的特性。不过你知道吗?Cython 属于 Python 的超集,所以不要让它吓跑了!
以下给出了一些可能需要采用这种加速策略的场景:
百倍加速第一步:代码剖析

你需要知道的第一件事情是,你的大部分代码在纯 Python 环境下可能都运行良好,但是其中存在一些瓶颈函数(Bottlenecks functions),一旦你能给予它们更多的「关照」,你的程序将获得几个数量级的提速。
所以你应该从剖析自己的 Python 代码开始,找出那些低效模块。其中一种方法就是使用:
你很可能会发现低效的原因是因为一些循环控制,或者你使用神经网络时引入了过多的 Numpy 数组操作(我不会花费时间在这里介绍 Numpy,这个问题已经有 太多文章 进行了讨论)。
那么我们该如何来加速循环呢?
在 Pyhthon 中加入 Cython 加速循环计算

让我们通过一个简单的例子来解决这个问题。假设有一堆矩形,我们将它们存储成一个由 Python 对象(例如对象实例)构成的列表。我们的模块的主要功能是对该列表进行迭代运算,从而统计出有多少个矩形的面积是大于所设定阈值的。
我们的 Python 模块非常简单:
其中 check_rectangles 函数就是我们程序的瓶颈!它对一个很长的 Python 对象列表进行迭代,而这一过程会相当缓慢,因为 Python 解释器在每次迭代中都需要做很多工作(查找类中的方法、参数的打包和解包、调用 Python API 等等)。
Cython 语言是 Python 的一个超集,它包含有两种类型的对象:
定义这种循环最直接的一种方法就是,定义一个包含有计算过程中我们所需要用到的所有对象的结构体。具体而言,在本例中就是矩形的长度和宽度。
然后我们可以将矩形对象列表存储到 C 的结构数组中,再将数组传递给 check_rectangles 函数。这个函数现在将接收一个 C 数组作为输入,此外我们还使用关键字取代了(注意:也可以用于定义 Cython C 对象)将函数定义为一个 Cython 函数。
这里是 Cython 版本的模块程序:
这里我们使用了原生的 C 数组指针,不过你还有其它选择,特别是 C++ 中诸如向量、二元组、队列这样的结构体 。在这段程序中,我还使用了一个来自提供的内存管理对象,它可以避免手动释放所申请的 C 数组内存空间。当不再需要使用 Pool 中的对象时,它将自动释放该对象所占用的内存空间。
有很多办法来测试、编译和发布 Cython 代码。Cython 甚至可以像 Python 一样 直接用于 Jupyter Notebook 中。
通过 pip install cython 命令安装 Cython。

使用 %load_ext Cython 指令在 Jupyter notebook 中加载 Cython 扩展。
然后通过指令,我们就可以像 Python 一样在 Jupyter notebook 中使用 Cython。
如果在执行 Cython 代码的时候遇到了编译错误,请检查 Jupyter 终端的完整输出信息。
大多数情况下可能都是因为在之后遗漏了标签(比如当你使用 spaCy Cython 接口时)。如果编译器报出了关于 Numpy 的错误,那就是遗漏了 import numpy 。
正如我在一开始就提到的,请好好阅读 这份 Jupyter notebook 和这篇文章,它包含了我们在 Jupyter 中讨论到的所有示例。
Cython 代码的文件后缀是,这些文件将被 Cython 编译器编译成 C 或 C++ 文件,再进一步地被 C 编译器编译成字节码文件。最终 Python 解释器将能够调用这些字节码文件。
你也可以使用将一个 .pyx 文件直接加载到 Python 程序中:
你也可以将自己的 Cython 代码作为 Python 包构建,然后像正常的 Python 包一样将其导入或者发布,更多细节请参考 这里 。不过这种做法需要花费更多的时间,特别是你需要让 Cython 包能够在所有的平台上运行。如果你需要一个参考样例,不妨看看 spaCy 的安装脚本 。
在我们开始优化自然语言处理任务之前,还是先快速介绍一下、和这三个关键字。它们是你开始学会使用 Cython 之前需要掌握的最主要的知识。
你可以在 Cython 程序中使用三种类型的函数:
关键字的另一个用途就是,在代码中表明某一个对象是 Cython C/C++ 对象。所以除非你在代码中使用声明对象,否则这些对象都会被解释器当做 Python 对象(这会导致访问速度变慢)。
使用 Cython 和 spaCy 加速自然语言处理
这一切看起来都很好,但是......我们到现在都还没开始涉及优化自然语言处理任务!没有字符串操作,没有 unicode 编码,也没有我们在自然语言处理中所使用的妙招。
此外 Cython 的官方文档甚至 建议不要使用 C 语言类型的字符串:
那么当我们在操作字符串时,要如何在 Cython 中设计一个更加高效的循环呢?
spaCy 处理该问题的做法就非常地明智。
将所有的字符串转换为 64 位哈希码
spaCy 中所有的 unicode 字符串(一个标记的文本、它的小写形式文本、它的引理形式、POS 标记标签、解析树依赖标签、命名实体标签等等)都被存储在一个称为 Stringstore 的数据结构中,它通过一个 64 位哈希码 进行索引,例如 C 类型的。

StringStore 对象实现了 Python unicode 字符串与 64 位哈希码之前的查找映射。
它可以从 spaCy 的任何地方和任意对象进行访问,例如 npl.vocab.strings 、 doc.vocab.strings 或者 span.doc.vocab.string 。
当某一个模块需要在某些标记(tokens)上获得更快的处理速度时,你可以使用 C 语言类型的 64 位哈希码代替字符串来实现。调用 StringStore 查找表将返回与该哈希码相关联的 Python unicode 字符串。
但是 spaCy 能做的可不仅仅只有这些,它还允许我们访问文档和词汇表完全填充的 C 语言类型结构,我们可以在 Cython 循环中使用这些结构,而不必去构建自己的结构。
与 spaCy 文档有关的主要数据结构是 Doc 对象,该对象拥有经过处理的字符串的标记序列(“words”)以及 C 语言类型对象中的所有标注,称为,它是一个 TokenC 的结构数组。
TokenC 结构包含了我们需要的关于每个标记的所有信息。这种信息被存储成 64 位哈希码,它可以与我们刚刚所见到的 unicode 字符串进行重新关联。
如果想要准确地了解这些漂亮的 C 结构中的内容,可以查看新建的 spaCy 的 Cython API 文档 。
接下来看一个简单的自然语言处理的例子。
假设现在有一个文本文档的数据集需要分析。
我写了一个脚本用于创建一个包含有 10 份文档的列表,每份文档都大概含有 17 万个单词,采用 spaCy 进行分析。当然我们也可以对 17 万份文档(每份文档包含 10 个单词)进行分析,但是这样做会导致创建的过程非常慢,所以我们还是选择了 10 份文档。
我们想要在这个数据集上展开某些自然语言处理任务。例如,我们可以统计数据集中单词「run」作为名词出现的次数(例如,被 spaCy 标记为「NN」词性标签)。
采用 Python 循环来实现上述分析过程非常简单和直观:
但是这个版本的代码运行起来非常慢!这段代码在我的笔记本上需要运行 1.4 秒才能获得答案。如果我们的数据集中包含有数以百万计的文档,为了获得答案,我们也许需要花费超过一天的时间。
我们也许能够采用多线程来实现加速,但是在 Python 中这种做法并不是那么明智 ,因为你还需要处理 全局解释器锁(GIL) 。另外请注意,Cython 也可以 使用多线程 !Cython 在后台可以直接调用 OpenMP。不过我没有时间在这里讨论并行性,所以请查看 此链接 以了解更多详情。
现在让我们尝试使用 spaCy 和 Cython 来加速 Python 代码。
首先需要考虑好数据结构,我们需要一个 C 类型的数组来存储数据,需要指针来指向每个文档的 TokenC 数组。我们还需要将测试字符(「run」和「NN」)转成 64 位哈希码。
当所有需要处理的数据都变成了 C 类型对象,我们就可以以纯 C 语言的速度对数据集进行迭代。
这里展示了这个例子被转换成 Cython 和 spaCy 的实现:
代码有点长,因为我们必须在调用 Cython 函数之前在 main_nlp_fast 中声明和填充 C 结构。
这串代码虽然变长了,但是运行效率却更高!在我的 Jupyter notebook上,这串 Cython 代码只运行了大概 20 毫秒,比之前的纯 Python 循环快了大概 80 倍。
使用 Jupyter notebook 单元编写模块的速度很可观,它可以与其它 Python 模块和函数自然地连接:在 20 毫秒内扫描大约 170 万个单词,这意味着我们每秒能够处理高达 8 千万个单词。
对使用 Cython 进行自然语言处理加速的介绍到此为止,希望大家能喜欢它。
关于 Cython 还有很多其它的东西可以介绍,但是已经超出了这篇文章的初衷(这篇文章只是作为简介)。从现在开始,最好的资料也许是这份综述性的 Cython 教程 和介绍 spaCy 自然语言处理的 Cython 页面 。
如果你还想要获得更多类似的内容,请记得给我们点赞哟!
Via 100 Times Faster Natural Language PROcessing in Python ,雷锋网 AI 研习社编译整理
版权文章,未经授权禁止转载。详情见 转载须知 。



深圳市前程网络科技服务中心,南山西丽电脑上门维修组装升级、网络IT维护运维外包、数据恢复、计算机配件、联想lenovo,戴尔DELL,华硕ASUS,华为HUAWEI,小米MI,苹果APPLE,惠普HP,宏基ACER等品牌代理销售,网络设备,打印复印机出租,硒鼓加粉,监控摄像头,共享网管,智能WIFI覆盖,网站建设,小程序开发,电信宽带,电脑及配件回收等

剧情百科网是专业的电视剧分集剧情介绍网站,提供最新热门电视剧及分集剧情介绍,热门电影剧情介绍及演员表资料等.看剧情,就来剧情百科!

4399大鱼吃小鱼小游戏大全收录了国内外大鱼吃小鱼类小游戏、大鱼吃小鱼2中文版、大鱼吃小鱼单机游戏、大鱼吃小鱼无敌版、大鱼吃小鱼下载。好玩就拉朋友们一起来玩吧!

商洛之窗是商洛日报社主办的综合性新闻网站。突现商洛特色,追求本土一流权威媒体品质,突出新闻性、娱乐性、资料性,重点覆盖商洛网民。

广东健策电子有限公司专业代理三匠散热风扇,三匠鼓风机,微型电脑鼓风机,支架风扇

轻壹是专注中医健康养生的知识分享平台,收集大数据中医健康养生大数据,中医养生视频,中医电子书,中医视频课程,穴位视频功效应用解读,中医药材方剂;传播贴切生活的健康养生知识,针灸、艾灸、推拿、等中医小知识等;提升大众基础健康理念。

深圳市披克科技有限公司是一家以打造门禁管理系统的整体安全解决方案为愿景的科技创新企业。公司产品线丰富,涵盖了非接触式IC卡的各个应用领域,包括智能访客系统、手机门禁系统、智慧停车系统、电梯管理系统、车辆出入管理系统、车位引导及反向寻车、智能车牌识别等,

昆山优诺捷测量设备有限公司

安徽庆卓网络科技有限公司

孝感市欣宁净化科技有限公司创建于2008年,是一家专业从事洁净室及相关授控环境系统工程设计、咨询、施工及激光打标加工,并经营空调设备及五金水暖材料为一体的专业化企业。本公司以孝感市为公司总部

居居侠APP是隶属于湖南居居时代数字科技有限公司一家以信息智能动态交付技术为核心的口碑自装交付平台公司以工匠服务驱动研发,攻克家装行业最难以解决的施工批量交付难题,同时打通F2C家装全案供应链,结合公司智能可视化预算系统以及DIY选款系统,并通过12年互联网技术沉淀,砍掉90%订单运营成本,为业主打造设计、施工、材料一体化的超高信价比的新型自装模式。

寿光市彤泰防水材料有限公司,创建于2003年,是一个集防水材料研制、开发、生产销售、设计施工于一体的专业化新型防水材料生产企业。


2021年,我国将发展托育服务体系列为,KPI,在,十四五,期间,每千人口拥有3岁以下婴幼儿托位数由1.8个提高到4.5个,意味着2025年中国托位总量要达到630万个,据数据显示,我国现有0,3岁婴幼儿4200万,其中1,3的家庭有着比较强烈的托育服务的需求,但实际入托率为5.5%左右,供需缺口还很大,KPI和民众需求的推动,使得...。

人们在生活中会经常使用到香,各种各样的香满足于不同人群的使用需求,在市场上出现不停种类、不同规格的香,分别有,香柱、香粉、塔香、线香等等,按照香味分为,桂花香、檀香、茉莉香等等,适合的场合也不同,广大市面可以根据自身的需求和用途选择合适的香,庞大市场需求量加速该行业的发展速度,稳固制香厂的市场地位,是很有发展前途的创业好项目,那么,制...。

想要发家致富吗,想要过上好的生活吗,如果你有梦想那就快快行动吧,经过自己的努力与奋斗创造不一样的人生,近些年来,加入创业大军的人群越来越庞大,也收获了意想不到的财富,眼光犀利的人们看好餐饮行业,人们纷纷前来分一块蛋糕,包卟同包子是众多创业者青睐的品牌,公司在经济方面和生产技术方面的实力相当强大,是一家具有规模性的美食企业,在业界拥有超...。

比亚迪汽车现已成为国产车企中的一把好手,这源于比亚迪汽车不断对夯实自身的技术实力,不断的研发出具有代表性的创立技术,而现在比亚迪汽车亦成为很多消费者的购车优选,那这样是否能够验证比亚迪汽车销量怎么样呢,下面随着小编的脚步一起来了解下,比亚迪汽车销量比亚迪汽车坚持以科技创立,不断的研发具有专利代表性的技术,为消费者提供更加智能化,更加安...。

火锅相信是大家比较熟悉的食物,很多人们会选择在家里在做火锅吃,买上自己喜欢的食物和一些火锅底料,大家围坐在一起也是非常开心的一件事情,市面上的火锅产品也是不断增多,火锅串串比较受大家的的欢迎,也让很多的创业者们看到了其中的商机,纷纷想要选择加盟其中,签年时光串串香加盟店美食多吗,接下来就由小编为大家简单的介绍一下吧,签年时光店内的装修...。

在全国各地的城市里奶茶店开一家火一家,每家店的生意都异常的火热,前来购买产品的食客都源源不断,呈现朝阳发展的现状,由于市场需求量的不断增大,加速奶茶行业在市场上前行的步伐,各大商家研发出更多口味的新产品,满足广大市民的饮食之需,赢得越来越多消费者的喜爱,在市场上发展的空间巨大,不少创业者发现奶茶行业存在的巨大商机,想要知道中国奶茶店品...。

现在的父母不仅重视孕前护理,同样也非常重视产后的母婴护理等问题,备孕妈妈从产前道产后的期间里使用到大量的母婴用品,包括孕妇服饰、孕妇营养品、孕妇护肤品、婴儿服饰、婴儿奶粉、婴儿尿裤、婴儿护理产品等,近几年来由于二胎政策的开放,加速了孕婴店的市场发展,也为准备创业的人群带来好的智慧之选项目,有眼光的智慧之选商发现孕婴行业存在很大的市场需...。

董记无骨烤鱼饭是一种新式快餐,主打鱼肉美食,也主打各种快餐美食,是市场新兴美食店铺,有很多的顾客前来购买,凭借着独特的口味和实惠的价格受到了顾客和加盟商的信任与好评,很多人想知道无骨烤鱼饭加盟店怎么样,接下来就为大家介绍,无骨烤鱼饭加盟店怎么样董记无骨烤鱼饭是一个发展多年的企业,主打快餐,小吃等,价格实惠,好吃不腻,在市场上发展很稳定...。

健康饮用水管对于现在装修行业来说有着很大的需求,水管工程属于隐蔽工程,对于水管的质量,品牌的认可度都很高,龙胜管业品牌创办时间就很长,在市场经营已经有20多年时间,龙胜管业品质怎么样,加盟费用高吗,龙胜管业经过很多年的努力以后,能够在给水管、采暖管、开关插座、灯具照明、集成吊顶、换气扇等一些领域做的更出色,把水电建材产品做好生产和批发...。

2017年6月2日,丽博橱柜丨全屋定制,大干30天,再下30城,拓展招商启动会在公司总部四楼会议室胜利召开,公司总经理何国平、零售业务总监胡国帅、拓展部经理沈林金以及拓展部的招商精英们共同参加了启动大会,会上,零售业务总监胡国帅对项目执行的各项细节进行了深入的剖析和指导,并视频,亮剑精神,,向全体招商精英们传达了,狼性团队,就是组织严...。

某宝几乎是每个人都知道的一个购物平台,在这个信息化的时代,选择某宝进行网购的人也越来越多,而且某宝也为网购者提供很多扶持,比如说很多物品都提供了七天退货的服务,这也让越来越多的人愿意相信某宝是一个可以给人们带来性价比比较高的商品,随着越来越多的人开始网购开网店的人也越来越多,很多创业加盟商都认为开网店是很挣钱的,都想某宝这个平台开一家...。

520的浪漫是玫瑰和咖啡缺一不可,近日,万咖啡,WanVita,推出新品咖啡——粉红拿铁,助力520爱的表达,萃取棚晒阿拉比卡咖啡豆,加入新鲜牛奶和超级食物甜菜根粉,制成爱意满满的红粉拿铁,颜值和风味俱佳,一杯红丝绒质感的粉红拿铁,用粉红的色彩唤醒人们内心深处的天真烂漫,万咖啡招牌饮品粉红拿铁,2020年,万达酒店及度假村在宁波万达美...。
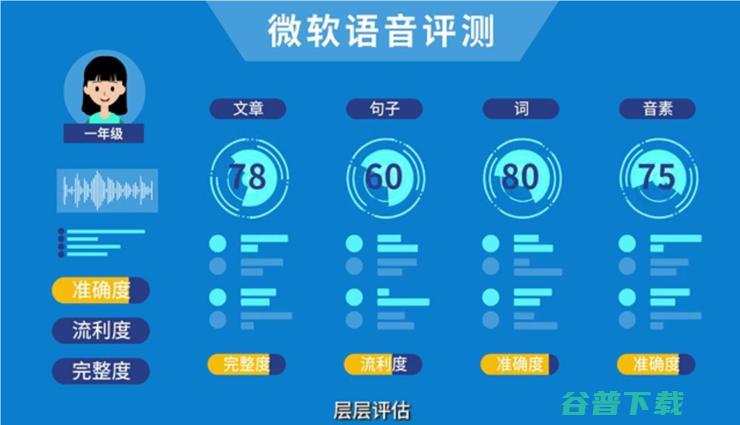
近年来,随着人工智能技术的不断成熟,企业数字化转型步伐的加快,AI的触角逐渐深入到各个场景,使人类的生产生活变得更加智慧化,在听觉方面,智能语音技术成为各大科技公司们攻坚的重要领域,一家老牌科技巨头微软,在语音合成技术、语音识别技术上深耕多年,面向全球合作伙伴开放和落地其技术能力,提供多种智能语音解决方案,5月中旬,在2020微软Bu...。

发表在综合交流大区2023,5,914,41很多人购买家用投影仪的首选,但在购买激光投影产品时,面对,三色激光,和,ALPD激光,这两种激光显示技术,很多消费者产生了疑惑,同样是激光光源,三色激光和ALPD激光到底有什么区别,三色激光和ALPD激光各有什么优缺点,应该如何选择呢,本文就为大家一一解惑,一、三色激光和ALPD激光成像原理...。

面食行业一直是一个具有广阔发展前景的行业,吸引了众多创业者的目光,山西刀削面作为行业中的具有特性的品牌之一,不仅为加盟者提供了多样的加盟选择,还为加盟商提供了多重优惠扶持政策,让加盟商在各自的领域里实现较大的经营成果,以下是对山西刀削面加盟的详细分析,以及为什么它成为了加盟者的理想选择,加盟前景加盟山西刀削面,大致在半年至一年内实现目...。

据新华社报道,第十五届中国国际航空航天博览会将于11月12日在广东珠海揭幕,参与航展的中外战机以及航展物资正陆续达到珠海,其中一架俄罗斯第五代隐形战役机苏,57备受注目,让中国军迷兴奋的不光是苏,57战役机初次在珠海为中国观众展现飞机功能,更由于驾驶这架编号054的苏,57战役机航行员是俄罗斯传奇试飞员谢尔盖·博格丹,现年62岁的博格...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
