AI任务疑难 谷歌等揭露 整个世界 存在局限的ImageNet等基准 的博物馆 就像无法代表 (ai 问题)
在日常生活中,我们需要一些「标准」来衡量个人的行为。
而在科研工作中,研究人员也需要一些「基准」来评估模型的性能。
因此,不管是普遍的「标准」还是特定的「基准」,它们都有一定的参考意义。
然而,如果有一天我们发现这些「参照物」与实际生活渐行渐远时,它们该往何处去?
近日,由加州大学伯克利分校、华盛顿大学和谷歌研究院合著的论文 《AI and the Everything in the Whole Wide World Benchmark》 指出Imagenet等基准定义的模糊任务在促进智能理解上的局限性,就像用有限的博物馆来代表整个世界一样。

在这篇论文中,研究人员阐述了机器学习(ML)对通用任务框架(CTF)的过度依赖,因为这个框架不恰当地演变成我们今天所理解的这些声称评估「通用能力」的基准。值得注意的是,研究团队 并不否认这些基准的实用性,而是希望指出将其作为框架存在的固有缺陷。
这篇论文最能引起共鸣的一点就是用故事书作为引子,且将情节贯穿全文,使得论文的研究内容更为直白易懂。
这本书就是1974年出版的 《Grover and the Everything In the Whole Wide World Museum》 ,书中的主人公Grover参观了一家声称展示「整个世界」的博物馆。
该博物馆的每个展厅都陈列着不同类别的东西,有些类别是随意和主观的,比如「你在墙上看到的东西( Things You find On a Wall )」和「房间里能让你挠痒痒的东西( The Things that Can Tickle You Room )」;有些类别则非常具体的,例如「胡萝卜屋( The Carrot Room )」,而另一些则含糊不清,如「高大的厅堂( The Tall Hall )」。

当Grover认为自己已经参观完博物馆的一切时,他来到写着「其他东西(Everything Else)」的大门前。打开门后,却发现自己置身于外面的世界。
作为儿童故事,Grover的经历是荒诞的。然而,在实际的研究中,例如人工智能尤其是ML领域,也存在类似的固有错误逻辑,其中许多流行的基准依赖于固有的错误假设。
这篇论文的研究人员认为, 在诸如「视觉理解」或「语言理解」之类的模糊任务中,作为衡量一般能力进展的基准,与有限的博物馆在代表「整个世界的一切」方面一样无效, 且这两个谬论的原因是相似的,即本质上是基于特定的、有限的且局限于上下文的环境。
GLUE或ImageNet之类的基准测试常常被提议为验证任何给定模型性能的基本通用任务的定义。其结果是,通过这些基准数据集证明合理的结论往往远远超越了它们最初设计的任务,甚至超出了最初的开发目标。
尽管作为迈向「通用目标」的标志,这些基准存在明显的局限性。事实上,这些基准的开发、使用和采用表明了一个结构有效性的问题,其中涉及的基准——由于它们在特定数据、度量和实践中的实例化——不可能捕获任何具有代表性的关于它们的普遍适用性的结论。
论文的作者们认为测量通用能力的目标(即通用对象识别、通用语言理解或领域独立推理等目标)不能充分体现在数据定义的基准中。研究人员注意到,当前的趋势不恰当地扩展了CTF范式,以将其应用于与现实世界目标或背景不同的抽象表现任务。
从历史上看,CTF的开发正是为了引入实用导向和严格范围的人工智能任务,即自动语音识别(ASR)或机器翻译(MT),其中所需的验证是 基准是否准确地反映了计算机在现实环境中所要求的实际任务。 这一波定义不明确的「通用」目标则完全颠覆了其引入的意图。
与其把Grover的经历当成儿童故事来看,倒不如说这是一则深刻的寓言故事。当Grover打开「其他东西」的大门时,却发现自己置身于博物馆外的大千世界。故事的结尾或许已经预示了这个研究的结论,ImageNet之类的基准定义必然不能代表适应所有现实世界模糊任务的「通用目标」。

因此,这篇论文确实有许多值得讨论和深思的地方。ImageNet存在不足,那其他基准定义就是完美无缺的吗?除了ImageNet,目前在通用对象识别上还有更好的参照基准吗?该如何看待以及解决基准定义越来越「不基准」这个问题?
外行看热闹,内行看门道,这么头疼的问题就应该交给专业人士。
迎面向我们走来的是第一位评委,该评委发出了“ 反对CV和NLP的“通用”基准中令人信服的观点! (A compelling argument against "general" monolithic benchmarks in vision and NLP)”的赞叹,因为他觉得这篇论文 史料详实,观点明确,分析到位,着实令人信服。

论文的研究人员先在文中铺垫了大量的背景知识,向读者展现了通用人工智能和基准测试的相关研究,并分析了ML的基准测试何时开始作为评估范围狭窄的任务性能的标准化方法。最后,结论就水到渠成了:通用语言理解和通用对象识别的基准本质上是有缺陷的,因为它们应用于狭窄的范围。

这位评委真诚地希望计算机视觉和NLP社区能认真对待这篇论文, 因为他认为该论文对在这两个领域取得更有意义的进展做出了宝贵的贡献,而不仅仅是追求最先进的技术。
但美中不足的是,既然发现了ImageNet基准存在局限性,那有什么办法可以减少对这些通用标准的过度依赖?看来论文的研究人员也还没找到这个问题的答案。

而第二位评委对这篇论文的评价是: 通用人工智能基准的谬论 (The Fallacy of Benchmarks For General Artificial Intelligence )。因为这篇论文的受众主要是AI领域的研究人员,所以作者在前文回顾了通用AI的相关基准,一下拉近了与读者的距离。此外,引用Grover的故事也使得该论文有趣易懂。

即使这篇论文的开头存在表述问题,未能无缝衔接主题,但瑕不掩瑜,评委二号高度赞扬了 这篇论文为ML领域的研究指明了方向。

接着,评委三号也带着他的观点款款走来: 好论文!但改一下结构就更好了 (Well argued paper, with some reorganization suggested)。这位评委指出,这篇论文最大的亮点是观点独特且论据充足。但也发出了和第一位评委相同的疑惑:所以,有什么解决方案可以减少对通用标准的过度依赖?

不同于前三位评委的「慷慨」,第四位评委只给出了5分的评价,认为这篇论文只是: 当前基准测试的简史 (History of the benchmarks we use today)。从这个评语不难看出,这位评委觉得这篇论文列举了很多基准测试且强调了它们的局限性,但作者团队并没有采取任何立场。

最后,评委五号不见其人,先闻其声: 很棒!但还有上升空间 (Great, but improvements needed)。第五位评委认为这篇论文在梳理和总结相关工作的方面做得非常好,同时有大量的研究支撑文中的论点, 希望这篇论文能引起相关领域研究人员的重视。

正因为对这篇论文寄予了极高的期望,因此评委只给出了6分的评价,同时罗列了非常详细的修改建议,希望论文的作者能加以改进。
看完五大评审的官方评论,总结起来基本就是: 论文不错,观点新颖,论据充分,要是能提出解决方案就更好了。 此外,有三位评委都不约而同地希望这篇论文能引起相关领域的重视。
Reddit上关于这篇文章的讨论热度也不小,我们来看看神通广大的网友怎么说。

某位网友一针见血地指出,虽然ImageNet等基准测试像「有限的博物馆」一样存在不足,但却是目前我们训练模型最有力的工具。

确实,就像上述评委提到的,ImageNet是有局限性,但是否有更好的解决方案?因此,有热心网友为论文的作者修改了摘要: 没有任何数据集能够捕捉所有细节的全部复杂性,就像没有博物馆可以包含整个世界中所有的事物一样。

一些网友则认为论文不错,尤其是「芝麻街」故事情节的插入加深了他们对该论文的理解。

这些网友觉得,用「无法展示一切的博物馆」类比「ImageNet在一些模糊任务上的局限性」非常恰当。

大概论文的作者们也没想到,写个文章还能为一本书代言,有网友调侃:宇宙万物的答案就隐藏在这本「芝麻街」故事书中。

更多网友表示赞同论文作者的观点,毕竟相比解决问题,发现问题太容易了。(狗头)

所以,解决方案究竟在哪?

就算博物馆「无法展示一切」,也没有人能否定其价值。同理,ImageNet这类基准定义的存在意义也不容置喙。不断发现问题并解决问题,历史的车轮才会滚滚向前(狗头)。
原创文章,未经授权禁止转载。详情见 转载须知 。



阿黎笔记

稀饭联盟-多年淘客圈从业经验,强大技术支持,专注外卖淘客返利开发,代理分销系统,为商家提供个性化服务,拥有专业的研发团队,价格实惠,专业团队为您提供贴心服务,稀饭联盟致力于让每个创业变的更加简单!

魔鼓官网——为华语领先鼓手网络鼓手中国旗下专注爵士鼓/架子鼓与打击乐教育平台!买鼓学鼓,就找魔鼓!

潍坊博诺新材料有限公司,氯化钙,氯化镁,硫酸镁,元明粉

致力于用先进的互联网技术和金融科技创新应用为个人和小微企业提供更加安全、高效、低成本的金融服务。

东莞市精邦机械科技有限公司是一家专业的测试设备制造商,主要生产剩余电压测试仪、鲁尔量规、ISO80369量规、高频电刀分析仪等产品。我们为实验室、企业、高校、航空航天等客户群体提供高质量的测试设备和解决方案。

昆山昆江数控机床有限公司

股掌柜证券投资咨询有限公司成立于2002年,是经中国证券监督管理委员会批准,取得经营证券期货业务许可证的证券经营机构,是中国证券业协会会员单位。公司提供专业的证券咨询服务,致力于成为投资者值得信赖的投资服务平台。

镁元素-myssc.net高品质美学素材网,专注于海外高品质素材:影视素材、平面素材、潮流物料、LR预设、LUT/PowerGrade预设、转场过渡、PR模板、PR插件、FCPX插件、达芬奇插件,包含:PSD、AI、JPG、PNG、Tif、MP4、MP3、Mov、Moti、Motn、INDD、eps、afdesign、brushset、abr、atn、aep、grd、pat、Prproj、cube、lrtemplate、xmp、dng、OTF、TTF、WOFF、csh设计源文件素材等资源

温州一站式生活服务平台

KolRank排行榜是KolRank旗下的自媒体大数据服务平台,提供权威的微信和微博排行榜,以及自媒体行业的各种数据、资讯、培训......

追天科技.曾经理:13517224966主营:短信群发平台,短信群发,短信公司,短信平台,106短信平台,验证码短信平台,验证码平台,验证码,手机验证码,手机验证码平台,发短信软件,品牌推广,网站制作,网站优化,网站推广,网络推广,网络优化,网络营销,推广,优化软件,优化公司,休闲游戏开发,棋牌游戏,游戏平台,游戏开发,手机游戏,棋牌游戏开发,手机游戏开发,网站建设,优化平台,百度排名,品牌设计,网站提升排名,百度快照。服务范围:武汉,重庆,深圳,北京,上海,天津,长春,兰州,西宁,西安,银川,郑州,济南,太原,合肥,长沙,南京,成都,贵阳,昆明,南宁,拉萨,杭州,南昌,广州,福州,台北,海口,香港,澳门,沈阳,呼和浩特,石家庄,乌鲁木齐,哈尔滨,吉林,宁夏,黑龙江,内蒙古,湖北,黄石,襄阳,十堰,荆州,宜昌,荆门,鄂州,孝感,黄冈,咸宁,随州,恩施,仙桃,潜江,天门

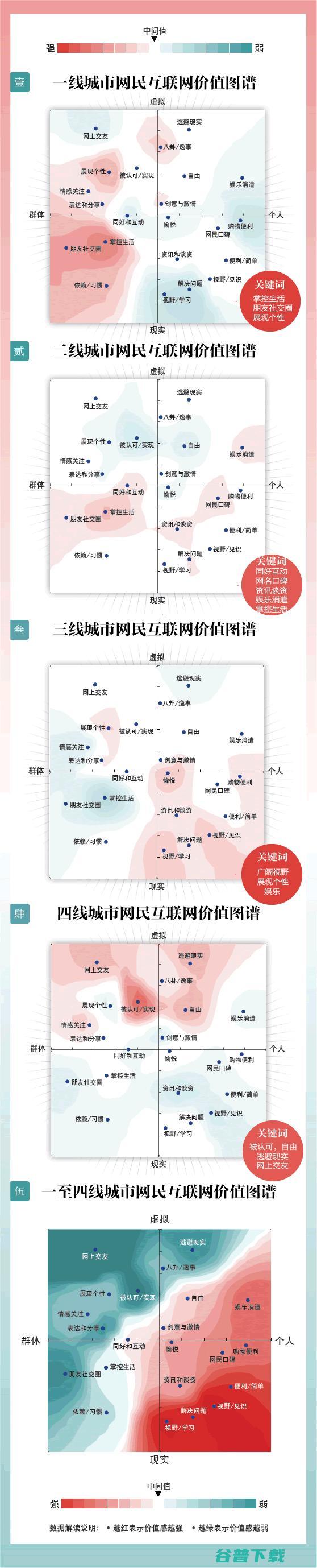
腾讯智慧走访了中国9个城市,通过与网民深度交流和对话,收集了3133份有效样本,分析了中国不同城市网民在使用互联网方面的多样性和差异,根据腾讯智慧提供的数据,我们制作了一张信息图,供大家参考,对于创业者来说,当大家都挤在一线城市抢占市场时,我觉得倒也可以思考一下二三四线城市的用户需求,为他们解决一些问题,文章来自36氪来源,卢松松博客...。

法律服务在近两年市场上发展越来越好,不管是大型企业还是小型商户,在遇到一些问题,还是需要专业的法律部门提供服务,为公司的长期发展奠定基础,执行官法律服务依托云端互联网技术,整合国内实力法律资源,提供多种诉求渠道的法律服务,赢得消费者的信赖与追捧,那么加盟执行官法律服务好不好,经营简单成本少,执行官法律服务从品牌创建以来,始终秉承顾客身...。

上海莜驿酒店管理有限公司,是中高端连锁酒店品牌运营商,业务涵盖品牌全案解决方案及中高端酒店品牌运营管理,以,演绎美好新生活,为发展愿景,不断探索中产全新的旅居生活方式,以及酒店连锁模式与供应链金融的结合在更多的领域为加盟商提供酒店全案运营一站式服务,和为消费者提供高性价比的产品和消费体验,...。

当下的市场上,日料作为备受消费者所欢迎的产品,不仅是可以很好填补味蕾上的需求,且能够带来品质生活的体验感,一直以来,发展趋势不错,且成功打造了很多的品牌,有喜屋,以产品出餐快,时尚品质定位,打造广阔的市场,过程中打动了很多的消费者群体,且获取了很多创业者对其信赖和认可,接下来,和小编一起去探索下有喜屋味道如何,现在能加盟吗,创建在上海...。

太阳监狱,这个概念听起来既神秘又充满科幻色彩,它并非一个真实存在的实体,而是源自于网络文化中的一个虚构概念,提到,太阳监狱,,我们首先想到的是中国最大的年轻人潮流文化社区——哔哩哔哩,简称,b站,上的一种流行文化现象,在b站的文化语境中,,太阳监狱,并不是指实际存在的监狱,而是一种象征性的表达,用于描述某些视频内容被限制观看的情况,...。

发表在综合交流大区2019,1,1510,03房价的不断提升让蜗居的用户越来越多,很多朋友认为小房子让生活品质明显降低,但其实并不是这样,今天笔者就给大家推荐一款大屏神器,它可以为您带来百吋大画面,让您的蜗居生活也能更有品质,笔者要推荐的就是坚果X3智能投影,这款产品的外观采用了金属与皮质的跨界组合设计,整机看起来非常有科技感,机身两...。
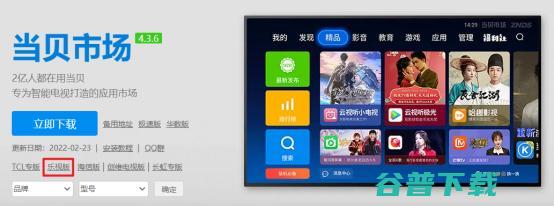
下面和大家分享下乐视q43A电视最新U盘安装当贝市场最新教程01、下载安装当贝市场安装包到U盘,下载地址,点击此处安装02、通过遥控器设置按键,选择,应用,标签页,已安装的应用,里面打开,设置,系统设置,03、然后在,通用,设置,找到,安全,开启,未知来源应用,开启后会弹出有风险提示,选择,确定,即可04、然后将U盘接...。

女性在生完宝宝之后,需要做好月子,才能拥有好的抵抗力,生活质量提高以后,月子中心成为产后女性坐月子的理想选择,月子中心有着科学化护理方案,量身定制护理方案,拥有一个美好的月子体验,怡悦之享是一家实力很强月子品牌,多种服务项目,全面系统的服务,取得良好市场口碑与评价,那么怡悦之享的加盟费多少,店内顾客多吗,怡悦之享是一家以高品质生活体验...。

女人梦见掉头发是什么意思女人梦见掉头发是什么意思,梦中场景有或许出现过也或许没有的,女人梦见掉头发预示着在人际交往方面能够取得很大的完成,预示着你要出门安适身心,如今来看看原版周公解梦女人梦见掉头发是什么意思,女人梦见掉头发是什么意思1周公解梦里的解释,女人梦见掉头发是守寡的兆头,而别的解释还有梦见梦到头发掉了表示头发是性感的意味,头...。

其实天蝎女并不难追,但不是说有人都能追,追她的人要合乎以下条件,1,长相不能太道歉,少数天蝎女是外貌协会的会员,2,要有必定的心思接受才干,天蝎的言词都比拟间接,心思接受才干不强的人很容易被刺伤.,追天蝎女的方法,1.尽量少与同性独自相处,天蝎女会吃醋的,2,多制作些偶合,让她尽或者多的见到你,3,不断买些小礼物送给她,多制作些浪漫4...。

阿尔法罗密欧汽车,不时以来都备受车迷们的热爱与追捧,早在1999年,阿尔法·罗密欧156就曾经小批量出口至中国,而在2004年该车型停产前,全国共引进了近100台,这些车型中的大局部被意大利使领馆和Fiat个人购入作为公务车经常使用,但也有一小局部流入了民间市场,成为了车迷们宝贵的收藏品,多年以前,曾经停产的阿尔法·罗密欧166平台被...。

AdobeAnimate中文破解版是非常好用的一款flash动画制作软件,加入对HTML5的支持,帮助开发人员创建更多Flash网站,广告和动画电影。
由于游戏充满乐趣,所以很多年龄段的人都是比较喜欢玩的,手机上下载游戏的时候也可根据每个人的年龄以及需求下载,那么五岁小孩玩的游戏哪款好呢,接下来小编将会给大家分享几款非常适合小孩子玩的休闲益智游戏,不仅玩法特别简单,也很容易上手,既有养成游戏,也有消除游戏等,对于孩子来说,玩游戏的时候主要就是以抑制为主,所以才会给大家推荐天天消星星这...。

能合成的游戏在移动端还是较为常见的,只不过合成是一个相当广泛的概念,很多游戏作品都加入了与合成相关的功能玩法,但要说最与该概念契合的游戏类型,还是那些可进行宠物或道具合成的作品,为此,小编接下来就将五款较为不错的合成玩法作品介绍给大家,1、,我有一座育龙岛,我有一座育龙岛,是以培养巨龙进行对战的作品,它采用了类二次元的卡通画风,让整...。
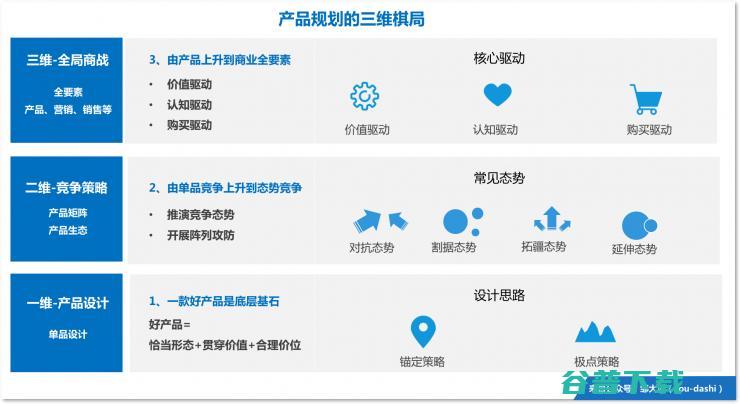
雷锋网按,本文作者邹大湿,微信公众号,zou,dashi,当下AI产品的竞争,要怎么胜出,产品为王吗,价格战吗,都不是,在这篇文章中,我们将以全局视角,从微观到宏观,讲述如何规划一款成功的AI产品,一、大败局,他们为什么失败了在提出体系框架之前,我们先来看三个典型的失败案例,真实案例,名称隐去,1、案例一,机器人2014年,消费机器...。

苹果第一财季营收突破1000亿美元,iPhone收入同比增长17%北京时间1月28日凌晨消息,苹果今天发布了2021财年第一财季业绩,报告显示,苹果公司第一财季净营收为1114.39亿美元,比去年同期的918.19亿美元增长21%,创下纪录新高;净利润为287.55亿美元,比去年同期的222.36亿美元增长29%,其中,苹果第一财季i...。

作为咱们内海的人们来说,特别愿意去海边玩玩去,几个人结伴而行,吃点海鲜才是一个再好不过的事情那,好的海鲜应该选择海鲜烧烤加盟,海鲜烧烤加盟店有效的规避了单一产品的经营危险,缓解了由流行产品引发的经营压力和长期投入隐患,而且在原有餐饮大市场的基础上,单独开发出了寥若晨星的特色口味——冰冻海鲜烧烤,几个人动手操作,充分发挥每一个人们的凝聚...。
