ASSIA (assiassion什么意思)
雷锋网 AI 科技评论按:2018 年 5 月 31 日-6 月 1 日,中国自动化学会在中国科学院自动化研究所成功举办第 5 期智能自动化学科前沿讲习班,主题为「深度与宽度强化学习」。
如何赋予机器自主学习的能力,一直是人工智能领域的研究热点。在越来越多的复杂现实场景任务中,需要利用深度学习、宽度学习来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的强化学习,优化解决问题的策略。深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用,使其被认为是迈向通用人工智能的重要途径。
本期讲习班邀请有澳门大学讲座教授,中国自动化学会副理事长陈俊龙,清华大学教授宋士吉,北京交通大学教授侯忠生,国防科技大学教授徐昕,中国中车首席专家杨颖,中科院研究员赵冬斌,清华大学教授季向阳,西安交通大学教授陈霸东,浙江大学教授刘勇,清华大学副教授游科友等十位学者就深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用进行报告。
雷锋网 AI 科技评论在本文中将对 6 月 1 日杨颖、赵冬斌、刘勇、游科友、徐昕的 5 场精彩报告进行介绍。
杨颖:轨道交通车辆预测与健康管理(PHM)技术应用
杨颖是中国中车首席专家,教授级高级工程师,中车株洲电力机车有限公司副总工程师。
本报告专注于相关内容,中国的轨道交通发展迅猛,列车数量在过去六年里几乎翻了两番。传统的定期保养模式现在问题重重,且这种模式花费不菲。在该背景下急需一个新的车辆保养方案。中国中车株洲和深圳铁路公司联合开发了一个轨道交通车辆预测与健康管理系统来降低车辆保养所需的人工费用以及其他费用。借助 PHM 系统,可以把定期保养模式转换为有条件保养模式,这样就可以延长检查保养周期,从而延长列车在安全健康状态下的运营时间。
赵冬斌:深度强化学习算法及应用
赵冬斌是中国科学院自动化研究所研究员、博导,中国科学院大学岗位教授。
本报告专注于深度强化学习算法的应用。将具有「决策」能力的强化学习 (RL: Reinforcement Learning) 和具有「感知」能力的深度学习 (DL: Deep Learning) 相结合,形成(DRL: Deep RL) 方法,成为人工智能 (AI: Artificial Intelligence) 的主要方法之一。2013 年,谷歌 DeepMind 团队提出了一类 DRL 方法,在视频游戏上的效果接近或超过人类游戏玩家,成果发表在 2015 年的《Nature》上。2016 年,相继发表了所开发的基于 DRL 的围棋算法 AlphaGo,以 5:0 战胜了欧洲围棋冠军和超一流围棋选手李世石,使围棋 AI 水平达到了一个前所未有的高度。2017 年初,AlphaGo 的升级程序 Master,与 60 名人类顶级围棋选手比赛获得不败的战绩。2017 年 10 月,DeepMind 团队提出了 AlphaGo Zero,完全不用人类围棋棋谱而完胜最高水平的 AlphaGo,再次刷新了人们的认识。并进一步形成通用的 Alpha Zero 算法,超过最顶级的国际象棋和日本将棋 AI。DRL 在视频游戏、棋类博弈、自动驾驶、医疗等领域的应用日益增多。本报告介绍了强化学习、深度学习和深度强化学习算法,以及在各个领域的典型应用。
刘勇:正则化深度学习及其在机器人环境感知中的应用
刘勇是浙江大学教授、博导,浙江大学求是青年学者。
本报告专注于正则化深度学习方法。近年来,随着人工智能技术的飞速发展,深度神经网络技术在图像分析、语音识别、自然语言理解等难点问题中都取得了十分显著的应用成果。然而该技术在机器人感知领域的应用相对而言仍然不够成熟,主要源于深度学习往往需要大量的训练样本来避免过拟合、提升泛化能力,从而降低其在测试样本上的泛化误差,而机器人环境感知中涉及的任务与环境具有多样化特性,且严重依赖于机器人硬件平台,因而难以针对机器人各感知任务提供大量标注样本;其次,对于解不唯一的病态问题,即使提供大量的训练数据,深度学习方法也难以在测试数据上提供理想的估计,而机器人感知任务中所涉及的距离估计、模型重构等问题就是典型的病态问题,其输入中没有包含对应到唯一输出的足够信息。针对上述问题,本报告以提升深度学习泛化能力为目标、以嵌入先验知识的正则化方法为手段、以机器人环境感知为应用背景进行了介绍。
总体上看目前刘勇教授研究内容共有四项,分别是:
就目前的研究结果来说,正则化统一框架下深度学习性能有明显的提升,在一系列机器人环境感知应用上取得当前领先表现。在接下来的工作中,刘勇教授团队将专注于无监督学习,定性与定量感知任务相结合,结合机器人声学、触觉等传感器等内容。
游科友:分布式优化算法与学习
游科友是清华大学副教授、博导,国家优青,国家青年千人。
本报告专注于分布式优化算法等问题,随着训练参数与样本规模的的急激增长,深度学习在实际应用系统中显示出了巨大的应用前景。分布式与并行优化是指通过多求解器起来协作求解的一类优化问题,其在大规模数值计算、机器学习、资源分配、传感器网络等有重要的研究意义和应用价值,并成为了大规模优化与学习中最具挑战性的问题之一。本报告首先讨论了分布式优化的几个典型难题;其次。以鲁棒性凸优化为例,提出了分布式原-对偶求解算法与分布式 Polyak 算法,并以严格证明了算法的有效性。
游科友老师团队的在本报告中提到的主要内容包括:
徐昕:自评价学习控制中的特征表示与滚动优化
徐昕是国防科技大学教授、博导,国防科技卓越青年人才。
本报告专注于强化学习的优化方法。以强化学习 (reinforcement learning) 为代表的自主学习技术对于提升各类机器人系统的优化决策与控制性能具有重要意义。在复杂不确定环境中机器人系统面临诸多优化决策与控制问题。面对这些问题,徐昕教授介绍了自评价学习在控制系统中的应用,自评价学习控制中的特征表示方法,以及滚动优化的方法。
以上是雷锋网 AI 科技评论全部报道,中国自动化学会第 5 期智能自动化学科前沿讲习班。两天时间,十位专家为大家带了十分精彩又干货十足的报告,对深度与宽度强化学习技术在游戏、机器人控制、参数优化、机器视觉等领域中的成功应用进行了深入介绍。
原创文章,未经授权禁止转载。详情见 转载须知 。



UMA是一个基于创新技术的联合营销平台,是中国互联网业具有品牌影响力的优质受众营销联盟,亦是中国互联网垂直行业第一个大数据平台。

太和广源医养养老院失能照护践行一切为了“活”和“动”、不卧床、积极康复、早快准的医疗风险管理”的养护理念,为北京海淀区的失能老人提供康复护理。

深圳市中方智能已经位列国内智能安防行业三甲,我们的优质服务贯穿整个产品周期,以技术为先导,服务为依托,保证用户满意,与用户共同发展.欢迎各界新老朋友来我公司参观、考查、指导工作,来人来电来函洽谈合作事宜.

海洋认证官网提供海洋认证OBP认证服务,为您的产品提供权威的海洋认证认可,保障您的质量和信誉。

专业的贵州旅游综合服务平台,提供贵州旅游包车,贵州旅游私家团定制,贵州景点景点推荐,贵州旅游攻略咨询及贵州旅游路线攻略信息。

上海栎晖商贸有限公司是一家致力于泵阀、轴承、气动元件、编码器、减速机、以及管路等液压产品和进口机械零部件销售的公司
")
65软件工作室从08年开始,将致力于开发环评专业辅助软件(EIAPro)系列产品。目前,基于08年新版大气导则的大气环评专业辅助系统EIAProA(EIAProfessionalAssistantSystemSpecialforAir)已经问世,欲详细了解请拔打0574-87245107

南京恒磊光学技术研究有限公司

浙江经纬焊割技术有限公司

最好的潮流单品网购指南

山东九拓仪器设备有限公司

安徽未来文化传播有限公司公司业务范围:文化传播、礼仪服务、承办各类演出;明星经纪业务、戏曲、曲艺、器乐表演;广告设计、制作、发布、展览、展示、代理;文化艺术交流策划、体育赛事活动策划、会展、影视动漫;建筑装修装饰工程、展览展示工程施工,文化工艺用品销售等。


明明自己没有设置过,打开网页浏览器却直接到了一个陌生网站,想改回原来的主页设置颇费周折,甚至无能为力,很多网民有过类似经历,在安装了一些软件后,自己的浏览器主页就被修改和锁定,随着互联网治理的深入,网络环境在逐步改善,但据用户最近的反映和记者的调查,,浏览器主页劫持,流量劫持,等现象依然猖獗,损害着广大网民的权益,在复杂的互联网技术...。
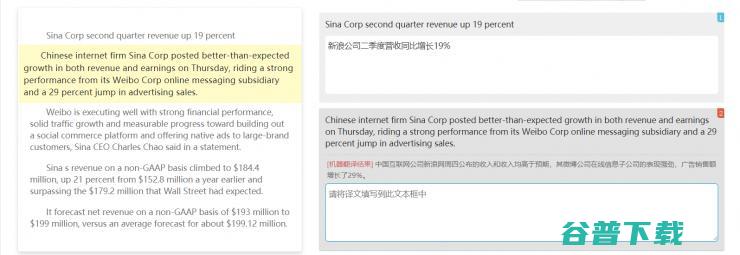
从2016年到2017年,或许是翻译行业的从业者们最人心惶惶的年头,科技企业挟AI令,翻译,,隔几天就发布一个新数字,不断推高机器翻译的准确程度,似乎这个行业已然成为,AI替代人类,最早的炮灰,机器翻译的进步,得益于神经网络的应用,不过,即便比统计模型基础上的机器翻译大有进步,神经网络翻译,NMT,的质量,其实也还远未达到专业人类译员...。

医保局是公务员单位,医疗保障局是公务员,医保局是国务院直属机构,根据第十三届全国人民代表大会第一次会议批准的国务院机构改革方案,组建中华人民共和国国家医疗保障局,作为国务院直属机构,其工作人员是国家公务员,是国家机构人员,是维护国家法律规定贯彻执行相关义务的公职人员,公务员是各国负责统筹管理经济社会秩序和国家公共资源,维护国家法律规定...。

将于12月1日到职的欧盟外交与安保政策初级代表博雷利外地期间11日在社交媒体发文称,当日他观赏了乌克兰边陲左近的进攻工事并示意他在前线亲眼目击了,乌克兰军队的力气和韧性,此外,博雷利还呐喊称,,更多、更快的,对乌,军事援助至关关键,据此前报道,博雷利外地期间9日称其已达到乌克兰首都基辅,这是俄乌抵触迸发以来他第五次访问基辅,博雷利...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

手机清算木马病毒最强的软件有,手机管家,腾讯手机管家,猎豹清算巨匠,网络手机卫士,金山手机卫士,信安卫士,等,1、,360手机卫士加快版,这款由360公司研发的手机版防护软件一经推出就收获了少量的好评,很多手机用户都示意经常使用这款软件先手机的经常使用显著顺畅了许多,这款软件除了一些基础防护配置外,它还会对手机启动活期的扫...。
提起怎样算两人八字合不合不要钱,大家都知道,有人问请问怎样算两团体的八字合不合,另外,还有人想问测算两团体八字合不合,你知道这是怎样回事,其实算两团体生辰八字合不合,上方就一同来看看请问怎样算两团体的八字合不合,宿愿能够协助到大家!怎样算两人八字合不合不要钱1、怎样算两人八字合不合不要钱,请问怎样算两团体的八字合不合,记好你们两团体的...。

水象星座包含巨蟹座、天蝎座和双鱼座,1、巨蟹座水象的巨蟹座,出现的是最单纯、基本的外形,巨蟹座很注重感情,擅长包全自己和他人,就像螃蟹一样,总是寻觅一个隐密的中央寓居,关于外人的侵入十分敏感;此外,他们的侵略性很强,常会以迅雷不迭掩耳的速度被动反击,巨蟹座的主宰行星是月亮,不只管理着潮汐变化,也深上天影响人的情感,2、天蝎座水象的天蝎...。

作为天津一汽的策略转型车型,威志V2确实提高了很多,这款源自威姿平台的新车,也正是天津一汽进行全新车型序列的冲锋车型,那么你知道威志v2两厢是什么发起机吗,威志v2两厢车驳回的是四缸人造吸气发起机,这款发起机的最大马力是91Ps,最大功率是67kw,最大扭矩是120n.m,发起机是一种能够把其它方式的能转化为机械能的机器,如内燃机、外...。

为什么现在全网那么多大佬都在讲打造个人打造到底有什么魔力能让这么多人去追捧它也可能你听了这么久的到至今都不知道具体是啥普通人跨越阶级最好的投资选择来七叔给你贴个度娘上的回答当你不断被个人打造相关内容脑时甚至会觉得当下以及未来确实它还挺重要的时候终于下决心也要打造自己的个人好家伙结果能看上眼的个人打造课程都贵的离谱不由让...

奔图M6202NW一体机驱动是这款PantumM6202NW黑白激光一体机的官方驱动程序,这款一体机集打印机、复印、扫描功能一体,驱动一键安装、WIFI手机直连打印、体积小颜值高、20PPM高速打印复印、一键身份证复印!产品参数打印速度20ppm(A4)21ppm(Letter)首页打印时间小于7.8秒最大月打印量10,000页建议月打印量250页到2000页分辨率(dpi)最大12001200dpi打印语言GDI处理器600MHz内存128MB双面

为了帮助各位学术青年更好地学习前沿研究成果和技术,AI科技评论联合Paper研习社,paper.yanxishe.com,,重磅推出,今日Paper,栏目,每天都为你精选关于人工智能的前沿学术论文供你学习参考,以下是今日的精选内容——ReadingWikipediatoAnswerOpen,DomainQuestionsMachine...。

11月11日,14日,以,云网融合,数智相生,为主题的2021国际数字科技展,DTS,暨天翼智能生态博览会在广州琶洲成功举办,本次博览会是中国电信举办的国际数字科技展,也是中国电信回归A股以来主持召开的最大规模行业盛会,展会共设置智能生态馆、产业数字化馆、数字湾区馆、数字生活馆和论坛馆五大主题场馆,中国电信集团系统集成有限责任公司,以...。
时隔4年再次回归,又叠加五一假期,今年的北京车展吸引了近千家国内外汽车产业企业参展,全球首发车117台、概念车41台——一大波新车也借此机会陆续登场,相比于四年前,中国车市变化明显,自主品牌销量占比反超海外品牌,新能源汽车的月渗透率首次突破50%,更为残酷的是,众多品牌正陷入愈加白热化的价格战,光是在四月,前脚有问界新M7起售价下调2...。

2019年以来,人社部已发布四批共56个新职业,3月18日,人社部会同国家市场监督管理总局、国家统计局向社会正式发布了18个新职业,分别是,集成电路工程技术人员、企业合规师、公司金融顾问、易货师、二手车经纪人、汽车救援员、调饮师、食品安全管理师、服务机器人应用技术员;电子数据取证分析师、职业培训师、密码技术应用员、建筑幕墙设计师、碳排...。

2024年7月15号晚,家里老年人在沪太路百安居优食净食器柜台经过诱骗模式买了一台净食器,还送了几个不知道是什么牌子的三无产品,电话打给售后,说只要半夜一小时退款,为什么百安居这个品牌会有骗子公司入驻,这个和外面诈骗老年人买保健品的骗子有什么区别,而且收款方还是团体,是预备捞一票走人么,还有分两笔收款的?...。
