深度强化学习 (强化学习)


原始的深度强化学习是纯强化学习,其典型问题为马尔科夫决策过程(MDP)。马尔科夫决策过程包含一组状态S和动作A。状态的转换是通过概率P,奖励R和一个折衷参数gamma决定的。概率转换P反映了转换和状态转变的奖励之间的关系,状态和奖励仅依赖上一时间步的状态和动作。
强化学习为Agent定义了环境,来实现某些动作以最大化奖励(这些动作根据policy采取)。对Agent的优化行为的基础由Bellman方程定义,这是一种广泛用于求解实际优化问题的方法。为了解决Bellman优化问题,我们使用了一种动态编程的方法。
当Agent存在于环境中并转换到另一个状态(位置)时,我们需要估计状态V(s)(位置)-状态值函数的值。一旦我们知道了每个状态的值,我们就可以找出执行Q(S, A)-动作值函数的最佳方法(只需遵循值最高的状态)。
这两个映射或函数相关性很高,可以帮助我们找到问题的最佳策略。从状态值函数我们可以看出遵循策略的Agent,处于的S状态有多好。

但是,动作值函数q(s,a)是从状态S开始,采取动作A,并遵循策略π的折现收益,并告诉我们从特定状态采取特定动作的效果。

很明显,状态值函数和Q函数之间的区别在于值函数体现状态的良好性,而Q函数体现状态中的动作的良好性。
MDP由Bellman方程求解,Bellman方程是以美国数学家Richard Bellman的名字命名的。该方程有助于寻找最优的策略和价值函数。代理根据所施加的策略选择操作(策略——正式地说,策略定义为每种可能状态下操作的概率分布)。代理可以遵循的不同策略意味着状态的不同值函数。然而,如果目标是使收集到的奖励最大化,我们必须找到最好的可能的政策,称为最优政策。

另一方面,最佳状态值函数的值,比所有其它值函数(最大返回值)都要大,因此,最佳值函数也以通过代入最大Q值来进行估算:

最后,值函数的贝尔曼等式(Bellman equation)可表示如下:
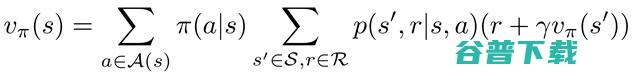
类似地,Q函数的贝尔曼等式可表示如下:

基于最佳状态值函数以及上述的状态值函数、动作值函数的等式,我们可以写出最终的最佳值函数的等式,该等式称作贝尔曼最佳等式:
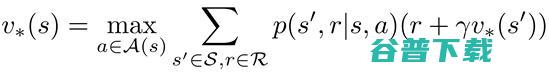
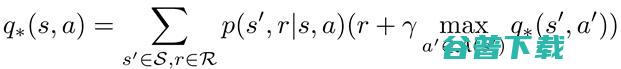
通常,强化学习的问题通过Q学习算法来解决。这里,如上所言,智能体与环境交互并接收奖励。目标是用足最佳策略(选择动作的方法),以取得最大奖励。在学习过程中,智能体更新Q(S,A)表(当回合结束时,任务完成,目标达到)。
Q学习算法通过以下步骤实现:
2、用epsilon贪心策略选取一个行动,然后进入下一个状态S’
3、根据更新等式来更新前一个状态的Q值:
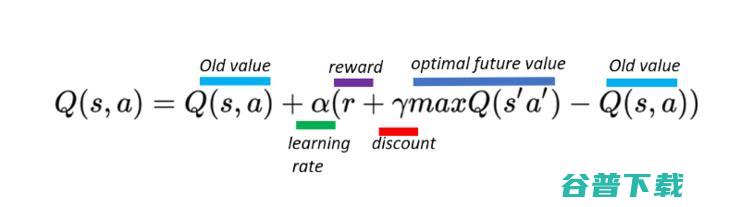
最好是从解决来自OpenAI gym的 Frozen Lake 开始。
在冻湖环境里(最好能熟悉OpenAI的描述),智能体可处理16种状态,执行4个不同的动作(在一个状态中)。在这种情况下,我们的A(S,A)表的大小是16x4。
Frozen Lake代码如下,你也可以点击 此处 查看~

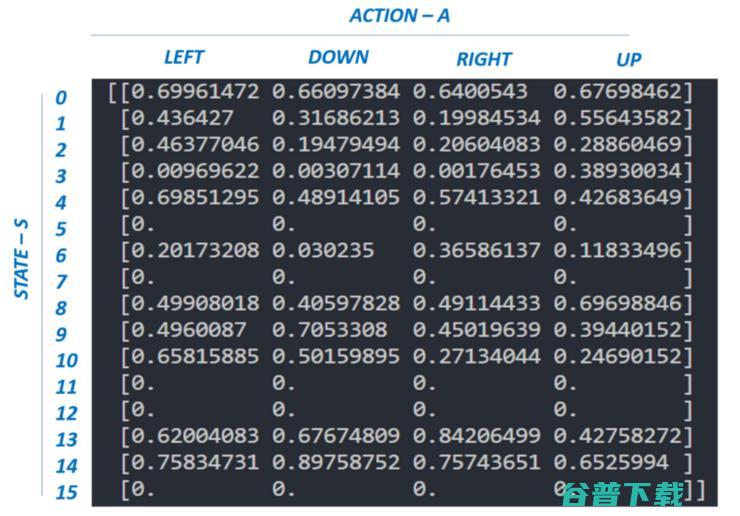
请注意上面给出的Q算法属于时序差分学习算法(Temporal Difference Learning algorithms)(由Richard S. Sutton于1988年提出)。Q算法是一种线下策略(off-policy)算法(这种算法具有从旧的历史数据学习的能力)。Q学习算法的扩展是SARSA(在线策略(on-policy)算法)。唯一区别在于Q(S,A)表的更新:
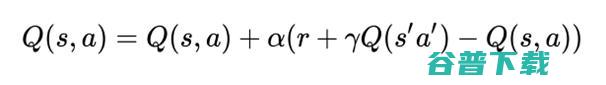
2. 深度强化学习(深度Q网络--DNQ)
当所有可到达的状态处于可控(能够迭代)并且能存储在计算机RAM中时,强化学习对于环境来说是足够好用的。然而,当环境中的状态数超过现代计算机容量时(Atari游戏有12833600个状态),标准的强化学习模式就不太有效了。而且,在真实环境中,智能体必须面对连续状态(不离散),连续变量和连续控制(动作)的问题。
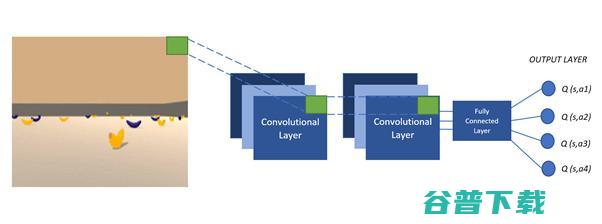
知道了智能体所处的环境的复杂性(状态数量,连续控制),标准的、定义明确的强化学习Q表就得被深度神经网络(Q网络)取代了,后者可以把环境状态映射为智能体动作(非线性逼近)。网络架构,网络超参数的选择以及学习都在训练阶段(Q网络权重的学习)中完成。DQN允许智能体探索非结构化的环境并获取知识,经过时间积累,他们可以模仿人类的行为。
下图(在训练过程中)描述了DQN的核心概念,图中,Q网络做非线性逼近,把状态映射为动作值。
在训练过程中,智能体与环境交互,并接收数据,这些数据在Q网络的学习过程中会用到。智能体探索环境,建立一个转换和动作输出的全图。开始时,随机进行动作,随着时间推移,这样做越来越没效果。在探索环境时,智能体尽量查询Q网络(逼近)以决定如何行动。我们把这种方式(综合了随机行为和Q网络查询)称为epsilon贪心方法(epsilon贪心动作选择块),也就是说利用概率超参数epsilon在随机和Q策略间进行选择。
我们所讲的Q学习算法的核心来自于监督学习。
如前所述,我们的目标是用深度神经逼近一个复杂的非线性函数Q(S,A)。
跟监督学习一样,在DQN中,我们定义损失函数为目标和预测值之间的方差,我们也更新权重尽量减少损失(假定智能体从一个状态转换到另一个状态,进行了某个动作a,获取奖励r)。

在学习过程中,我们使用两个不相关的Q网络(Q_network_local和Q_network_target)来计算预测值(权重θ)和目标值(权重θ’)。经过若干步骤后,目标网络会被冻结,然后拷贝实际的Q网络的权重到目标网络权重。冻结目标Q网络一段时间再用实际Q网络的权重更新其权重,可以稳定训练过程。
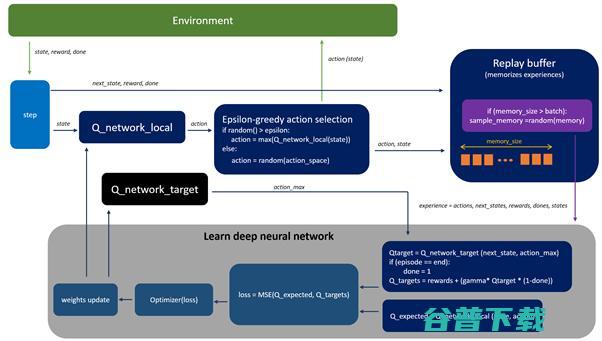
为使训练过程更稳定(我们要避免用比较关联的数据来训练网络,如果基于连续更新最后转换来进行训练的话, 这种情况就有可能发生),我们引入重播缓冲区,它能记住智能体所经历的行为。然后,用重播缓冲区里的随机样本来进行训练(这可以减少智能体的经历之间的关联性,并有助于智能体从更广泛的经历中进行学习)。
2. 预处理环境,并把状态S输入DQN, 后者会返回该状态中所有可能的动作的Q值。
3. 用epsilon贪心策略选取一个动作:当有概率epsilon时,我们选择随机动作A,当有概率1-epsilon时,选取具有最高Q值的动作,例如A=argmax(Q(S, A, θ))。
4. 选择了动作A后,智能体在状态S中执行所选的动作,并进行到新状态S ,接收奖励R。
5. 把转换存储在重播缓冲中,记作
6. 下一步,从重播缓冲区中抽取随机批次的转换,并用以下公式计算损失:
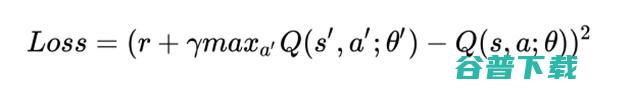
7. 针对实际网络参数,执行梯度下降,以使损失最小化。
8. 每隔k步之后,拷贝实际网络权重到目标网络权重中。
在这一段中,我展示Udacity(深度强化学习)的工程代码的结果。
本工程的目标是训练智能体如何在方块环境中通过移动来采集黄色香蕉。工程要求在100个连续回合中获取+13的平均分。
b. 在导航工程中,使用下列参数设置神经网络架构和超参数:
以下是每回合的奖励图,显示出智能体在玩了2247回合后,能收到的平均奖励(超过100回合)有至少+13。
输入层FC1:37节点输入,64节点输出
隐藏层FC2:64节点输入,64节点输出
隐藏层FC3:64节点输入,64节点输出
输出层:64节点输入,4节点输出----动作的大小
BUFFER_SIZE = int(1e5) # 重播缓冲区大小BATCH_SIZE = 64 # 最小批量大小GAMMA = 0.99 # 折扣率TAU = 1e-3 # 用于目标参数的软更新LR = 5e-4 # 学习率UPDATE_EVERY = 4 # 更快网络的快慢Epsilon start = 1.0Epsilon start = 0.01Epsilon decay = 0.999
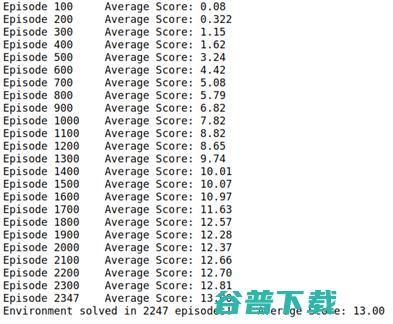

图2. 智能体学习的平均得分
如果有深度学习的相关经验,那么未来工作将主要集中于图像处理方面(从像素中学习)。下图展示了DQN的架构,图中,我们输入游戏画面,Q网络逼近游戏状态中所有动作的Q值。动作由我们讨论过的DQN算法进行选择。
其次,未来的工作将集中在生成一个决斗(Dueling)式DQN。在这个新的架构中,我们指定新的优势函数,这个函数计算出智能体执行的一个动作,比其它动作好了多少(优势可为正也可为负)。
Dueling DQN架构与上面讲的DQN相同,只不过最后的全连接层分成两股(见下图所描述)。
若环境的一个状态有确定数量的动作空间,绝大多数计算出来的动作对状态没有什么影响。此外,有些动作有冗余效应。在这种情况下,新的dueling DQN将会比DQN架构估算出来的Q值更精确。
其中一股计算值函数,另一股计算优势函数(用于决定哪个动作更优)。

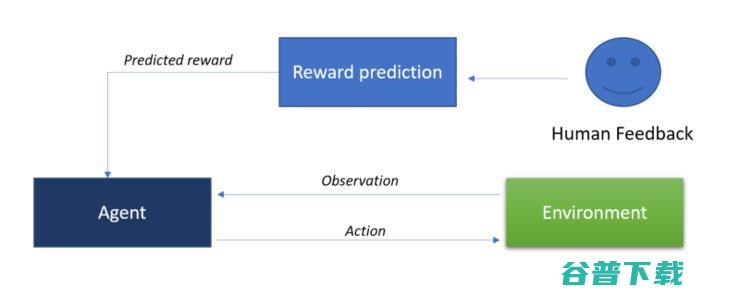
最后,我们考虑一下从人类的偏好中进行学习 (OpenAI和Deep Mind) 。这个新概念的核心思想是从人类的反馈中学习。接收人类反馈的智能体,将尽力进行人类期望的动作,并相应地设置奖励。人类与智能体的直接交互 ,会有助于降低设计奖励函数和复杂的目标函数的难度。
你可以通过我的Github找到本工程的全部源码:
想要继续查看该篇文章相关链接和参考文献?
点击【 深度强化学习-深度Q网络(DQN)介绍 】即可访问!
福利大放送——满满的干货课程免费送!
「好玩的python:从数据挖掘到深度学习」该课程涵盖了从Python入门到CV、NLP实践等内容,是非常不错的深度学习入门课程,共计9节32课时,总长度约为13个小时。。
课程页面:
「计算机视觉基础入门课程」本课程主要介绍深度学习在计算机视觉方向的算法与应用,涵盖了计算机视觉的历史与整个课程规划、CNN的模型原理与训练技巧、计算机视觉的应用案例等,适合对计算机视觉感兴趣的新人。
课程页面:
现AI研习社将两门课程免费开放给社区认证用户,只要您在认证时在备注框里填写「Python」,待认证通过后,即可获得该课程全部解锁权限。心动不如行动噢~
原创文章,未经授权禁止转载。详情见 转载须知 。



荔枝FM是专业的音频分享平台,汇集了听音乐,英语,睡前故事,儿童故事,有声小说,相声段子,历史人文,有声书,故事等数亿条音频,超过2亿用户选择的网络电台,随时随地,想听就听,你喜爱的音频尽在荔枝FM。

在“雨后池塘”里,每个蛙友都拥有一套小屋,温馨而雅致。我将用欢歌和笑语,把可爱的小屋装扮,倾注深深的爱与痴迷…有家的感觉真好!


无锡寻源节水技术有限公司是一家专业的漏水检测技术企业,拥有一支技术能力强、经验丰富的查漏队伍,长期致力于地下管道漏水探测及修复,更新等技术,优质优量的完成客户给我们的每一个查漏需求。

长沙开源虎软件科技长期专注于定制开发各种大型软件系统,业务范围涉及:小程序开发、app开发、软件开发、网站开发、微信开发、大型软件系统深度定制,OctShop商城系统,OctIM在线客服系统等等。为众多企业提供软件系统研发服务,提供专业的技术解决方案。

买基金找鼎信汇金,网上买基金高效安全;主动管理系列私募基金,专业团队勤勉尽责。提供优质、全面的投资咨询及基金销售服务。

浙江省公共就业服务平台由浙江省人力资源和社会保障厅主办,版权归属浙江省职业介绍服务指导中心。浙江省公共就业服务平台建于2001年,作为省级公共就业服务网络平台,多年来始终坚持公益服务,为广大招聘企业和求职者搭建政府桥梁。平台主要功能有职介服务、校企合作、就业培训等。
")
米奥探客(DataThink)是一个全球贸易数据查询服务平台,提供全球进出口贸易数据查询服务,包括海关进出口数据查询、进出口商联系方式查询,以及提供邮件营销、客户开发与管理系统等服务。旨在帮助外贸企业主动寻找并开发精准客户,推动业绩持续增长。

索比光伏网是中国光伏太阳能产业权威网站,为用户提供最新的光伏太阳能资讯、光伏发电政策、光伏电站项目、光伏企业、光伏产业,光伏发电,太阳能光伏论坛,光伏逆变器,光伏供求、光伏展会、光伏电站、分布式光伏发电、光伏组件、电池片、多晶硅、光伏上网电价等光伏行业信息。

辽宁嘉顺科技有限公司成立于2005年5月,位于“中国镁都”辽宁省大石桥市,公司历经17年快速平稳发展,形成集研发、生产、销售、服务于一体的高新技术企业。产品涵盖特种高温、耐高温防潮、重硅防潮电工级氧化镁粉,防火电缆、矿缆级氧化镁粉,铁盘粉等。适用于各种民用、工业用电热元件及矿物绝缘防火电缆中。

物产中大金石集团有限公司(以下简称物产中大金石)前身为中大房地产集团,始建于1992年,为上市公司、世界五百强——物产中大集团的重要成员企业,注册资金8亿元。


恰逢商汤科技十周年庆典,,2024商汤十周年国际论坛,迈向AI2.0共融新时代,在香港科学园成功举办,来自全球的行业领袖、政府代表、AI专家共聚于此,共同探讨AI行业的未来,活动上,商汤科技董事长兼首席执行官徐立表示,当下正处在AGI的转折点,在人工智能2.0时代,商汤的核心战略是无缝集成数字基础设施、人工智能模型和应用,集团将以此为...。

发表在峰米投影仪2020,12,1511,22峰米4kmax是峰米科技在近段时间推出的新品激光电视,这是一款价格两万多的高端设备,在早期宣传的时候就提出了是一款亮度很高的产品,作为一款价格昂贵的激光电视,峰米4kmax是抖动4k吗,还是真4K,下面就深度分析了解一下峰米4kmax的参数配置,看看这款激光电视究竟怎么样,一、峰米4kma...。

发表在专业问答2021,11,514,26功放与音箱的功率匹配一般分为三种形式,功放功率大于音箱功率;功放功率与音箱功率基本相等;功放功率小于音箱功率,理论上说,音箱的额定功率要等于功放的额定输出功率,但是无法满足这样的等式时,尽量选大功率功放,功放与音箱的功率匹配功放功率大于音箱功率的形式比较常见,因为功放功率大,在听音乐时会感觉低...。

第一天入职时,一个一起入职的同事从包里掏出键盘准备干活,这时俺说,你是写PHP的吧?,这哥们大惊,问,你咋知道的?,俺说,你看,你键盘上的4键都要磨没了,这哥们五体投地,叹道,这还是第一次有人在我掏出键盘时就看出这一点,当时其他人看俺眼神都变了,第二天,路过一个同事桌旁,俺说,你是写Python的吧?,这哥们大惊,他屏幕上是...。

据最新信息,70岁的出名金融大佬、摩根士丹利国内公司董事长乔纳森·布鲁默,确认遇难,至此,英国奢侈游艇,贝叶斯,号遇风暴漂浮事情造成的死亡人数到达6人,其中包含有,英国比尔·盖茨,之称的出名软件技术企业家迈克·林奇,摩根士丹利国内公司董事长乔纳森·布鲁默及其妻子朱迪,高伟绅律师事务所律师莫维洛及其妻子内达,以及游艇厨师雷卡尔多·托马斯...。

美国入选总统特朗普外地期间11月10日晚经过社交媒体发表,他将任命美国移民与海关执法局前代理局长汤姆·霍曼在新政府中主管边陲事务,特朗普在帖文中称,霍曼将,担任咱们国度的边陲,包含但不限于南部边陲、北部边陲、一切海上和航空安保,特朗普将打击合法移民作为其竞选的外围内容,承诺将把合法移民大规模驱逐出境,霍曼曾在特朗普的第一个任期内担任...。

这几张看起来,觉得怪怪的,要什么没什么的觉得,其实不算丑,然而什么都不够突出,扮演媒体或许没有经过肢体和表情展现进去,或许说太个别了,很多人的好友圈的既视感...。

华阳陆地钻研核心、中国南海钻研院和中国国内法学会7月11日在京联结发布了,南海仲裁案判决再批驳,报告,所谓,南海仲裁案判决,出台距今已有8年,报告重申了中国对仲裁案以及仲裁判决的立场,强调中国政府不会抵赖仲裁庭作出的合法判决,也不会接受任何基于判决的主张和执行,近日,中方发布,仁爱礁合法,坐滩,军舰破坏珊瑚礁生态系统考查报告,黄岩岛...。

外地期间7月11日,美国国防部颁布申明,发表向乌克兰提供额外2.25亿美元的安保声援,以满足乌克兰主要安保和国防需求,据悉,这是拜登政府自2021年8月以来从国防部库存中向乌克兰提供的第61批装备,该方案将为乌克兰提供防空系统和阻拦器、火箭系统和火炮弹药以及反坦克武器等,△美国防部总部——五角大楼,资料图,此外,美国正在与德国、罗马尼...。

荣威汽车旗下的轿车车型包含荣威360、荣威i6、荣威i5等,荣威旗下的轿车车型在A+级轿车市场具备必定的市场位置,汽车在十万元左右的车型中具备杰出的竞争长处,荣威是上海汽车个人旗下的汽车品牌,在2006年正式推出,荣威汽车的品牌秉承着品牌科技成功的口号,表白了荣威以国内化的视线翻新的汽车制作理念打造汽车,荣威旗下的产品有荣威350,荣...。

灰灰影音图片加载不出来怎么办?很多用户都喜欢用灰灰影音看电视电影,不过最近有很多用户都发现图片加载不出来的情况,这是怎么回事呢,下面2265小编来告诉大家。 小编在使用过程中并没有遇到此问题哦!所以很可能是你手机内存不足,或者是网络问题,建议清理手机

艺术疗愈:2023艺术旌阳“去有花开的地方”城乡生长计划启幕,公共艺术,城市,乡村,人文,青年艺术家

Wi,Fi是什么,它是一个基于IEEE802.11标准的无线局域网技术,如今,Wi,Fi已经覆盖了绝大部分的室内场景,你的手机、电脑、智能音箱都已经离不开Wi,Fi,但是,大部分人应该对现在的Wi,Fi使用体验并不满意,有时候,Wi,Fi信号满格却上不了网,有时候,你又疑惑为什么100兆带宽的光纤网络却慢如蜗牛,还有的时候,Wi,Fi...。

近日,悉尼动物园与西悉尼大学合作,让动物园变成高科技乐园,该动物园预计在2017年末开张,届时不仅游客能拥有炫酷的高科技体验,动物们也有这个福利,西悉尼大学在上周五举办了一个黑客马拉松,旨在实现两个目标,给予游客高科技体验和保护动物,如果目标实现,游览动物园会变成完全,高科技,的体验,游客只要下载一个app,连接WiFi,就能在整个游...。
紫魅入门级投影控发表于2018,11,08首先,小米开创了投影界标注光源流明的新时代,5000光源流明,好吓人啊,海信的售价7万才标3000,坚果的3万标4000,艾洛维的1.5万标3500,小米1万的,5000啊,这是多么吸引人的一个参数,5000流明啊,白天哪怕不配抗光幕也足够了吧,但是,请看清楚,小米标注的是光源流明,不是ANS...。
温馨提示,TCL电视第三方刷机固件下载下面为大家分享TCL电视怎么看电视直播方法,有需要的朋友可以参考下,新系统版本安装软件方法,免U盘安装的方法有个弊端,就是很多,白瓢,软件应用市场没有,所以家里有智能电视的,有个U盘真的很重要,1,把拷贝好apk安装包的U盘插入电视,然后在,应用,里找到,电视卫士,并打开;,2,选择,应用管理,...。

1.海澜之家,这个平价且优质的国民男装品牌,因其时尚商务风格而被誉为,男人的衣柜,公司专注于为20至45岁的男性顾客提供设计时尚、品质上乘的产品,其产品线涵盖商务、时尚和休闲三个系列,丰富多样的选择能够满足不同消费者的需求,2.优衣库,这个日本著名的服装品牌,以仓储式自助购物模式闻名,其服装以简约自然的设计、卓越的品质和易于搭配的时...。
