发布新一代NNP芯片外 英特尔AI软件和应用更透露其AI野心 (发布新一代液冷技术)
整个5月,各大巨头扎堆一样举办开发者大会、人工智能大会。倒是给了我们一下子看完各大巨头人工智能布局的机会。
雷锋网消息,美国时间5月23日,英特尔人工智能开发者大会(AIDevCon 2018)在旧金山艺术宫开幕。
会议上,英特尔副总裁、AI事业部(AIPG)负责人Naveen Rao介绍了英特尔AI的最新进展:英特尔至强处理器的性能有了进一步的提升,发布了新一代专为机器学习设计的神经网络处理器(NNP)芯片——Nervana NNP-L1000 (Spring Crest);介绍了nGRAPH平台、BigDL大数据开源平台、OpenVINO等开源软件工具;展示了用Movidius 神经元计算棒来进行AI作曲。
新一代NNP芯片
在雷锋网看来,英特尔在人工智能上的布局很明晰,近一年来,其反复提到的“英特尔人工智能全栈解决方案”揭示出其AI基础架构。

英特尔人工智能全栈式解决方案是一个完整的产品组合,包括至强可扩展处理器、英特尔Nervana神经网络处理器和FPGA、网络以及存储技术等;针对深度学习/机器学习而优化的基于英特尔架构的数学函数库(Intel MKL)以及数据分析加速库(Intel DAAL)等;支持和优化开源深度学习框架如Spark、Caffe、Theano以及Neon等;构建以英特尔Movidius和Saffron为代表的平台以推动前后端协同人工智能发展。

在会议上,Naveen Rao讨论的重要更新之一是“英特尔至强可扩展处理器”的优化。与前几代相比,新一代的处理器在训练和推理方面都有显着的性能提升,这对于许多希望利用现有基础架构的公司来说是有益的。
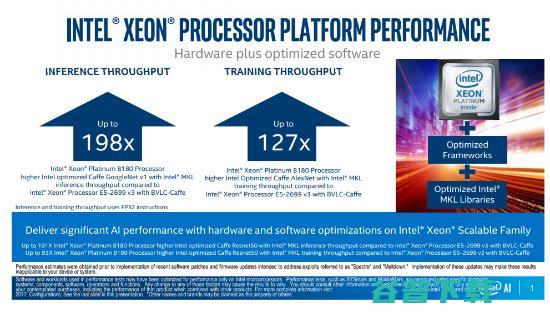
随后,Naveen Rao介绍了全新一代NNP系列芯片。作为曾经不可撼动的芯片巨人,英特尔在AI时代却面临诸多挑战。随着像Nvidia和ARM这样的公司赢得了图像处理单元(GPU)的声誉,且谷歌也已经设计出针对AI的专用芯片,英特尔的通用CPU芯片显然落后了。

2016年,英特尔并购专注于深度学习专用芯片的加州创企Nervana Systems,Nervana首席执行官兼联合创始人Rao加入英特尔,短短几个月后,Rao就以火箭般的速度晋升为英特尔人工智能事业部总负责人。可以看出,英特尔重金投入AI芯片,且将其作为发展人工智能的核心.
2017年10月,英特尔曾介绍了专为机器学习设计的神经网络处理器(NNP)系列芯片,被命名为Lake Crest。Lake Crest可以加速多种神经网络算法框架,比如谷歌的TensorFlow 、Nervana的Neon、Facebook的Caffe等。英特尔称Lake Crest能够比比GPU更快、功耗更低、性能更好。但当时,英特尔只将NNP芯片供应给一小部分英特尔合作伙伴,计划在2017年年底前开始出货。
在本次的英特尔AI开发者大会上,Naveen Rao介绍了新一代的NNP芯片——Nervana NNP-L1000(Spring Crest),是Lake Crest发布七个月后的全面更新,性能比上一代产品提升了3-4倍。 Rao介绍到,Spring Crest会有多项更新,其也将是英特尔第一款商业NNP芯片,将不止是提供给小部分合作伙伴,将在2019年发货。
Naveen Rao谈到,在英特尔Nervana NNP-L1000中,我们还将支持bfloat16,这是一种业界广泛用于神经网络的数字格式。随着时间的推移,英特尔将在我们的AI产品线上扩展bfloat16支持,包括英特尔至强处理器和英特尔fpga。
而谷歌在AI芯片上的速度似乎已经赶超英特尔。2017年谷歌I/O大会上,谷歌就宣布正式推出第二代TPU处理器,第二代TPU处理器加深了人工智能在学习和推理的能力,据谷歌的内部测试,第二代TPU芯片针对机器学习的训练速度比目前市场上的GPU节省一半时间。2018年,谷歌传奇芯片工程师Jeff Dean连发了十条Twitter宣布谷歌TPU首次对外全面开放,第三方厂商和开发者可以每小时花费6.5美元来使用它,但需要先行填表申请。外界认为这意味着AI芯片和公有云市场将迎来新的变革。看来,英特尔的NNP系列与谷歌的TPU系列是直接对标的产品。
三大开源软件工具
虽然处理器和芯片是英特尔人工智能布局的核心,但是从本次大会来看,英特尔也将更多目光放在了扶持开发者身上。
Naveen Rao谈到,“我们认识到,单靠英特尔无法实现人工智能的全部愿景。相反,我们需要联合开发者、学术界、软件生态方共同来解决这些问题。今天,我很高兴看到开发人员加入我们的示范、研究和实践培训。“
大会上,英特尔和合作伙伴介绍了BigDL分布式深度学习框架、OpenVINO、nGRAPH平台等开源软件工具。
BigDL是一款基于Apache Spark的分布式深度学习框架,它可以无缝的直接运行在现有的Apache Spark和Hadoop集群之上。
据了解,英特尔与百度也展开了合作,百度云在即将发布的数据分析平台中将整合BigDL最新版本。未来英特尔还将联合百度云智学院推出完整的“数据分析+BigDL”培训课程。
OpenVINO这一套新的开源软件工具则主要用于视觉应用与神经网络优化。可以让开发者更简单地在边缘设备上部署视觉计算和深度学习能力。

nGRAPH则是面向开发者的深度神经网络模型开源编译器,可以直接支持TensorFlow/MXNet以及Neon,还可以通过ONNX支持CNTK、PyTorch、Caffe2。
AI编曲与AI图像渲染
除了基层技术和软件框架之外,英特尔还展示了AI多种场景应用。

首先是AI谱曲。英特尔在现场展示了人类演奏者和AI配合起来作曲,演奏者输入一段音符,AI可以配合给出相同风格的下一段,AI还可以用不同的乐器来配合,例如吉他配合键盘。从技术上来看,这需要通过深度学习从大量的数据库中训练,这样的训练需要很高的运算。

而英特尔实现的方式却很简单,仅用了一个U盘大小的Movidius神经元计算棒。去年7月英特尔就发布了这款产品,是是业界首款基于USB的超低功耗的嵌入式神经网络的开发工具,它可以工作在标准USB接口上。它内置了Myriad2的VPU,可以把预训练好的Caffe或者TensorFlow的模型直接嵌入到神经网络,直接通过所谓的U盘对神经网络推理进行加速,从而将人工智能应用部署在嵌入式以及边缘环境上。雷锋网了解到,海康威视的智能相机、大疆的无人机也采用了英特尔Movidius技术。
另一个应用是利用英特尔AI进行3D动画渲染。这是合作伙伴ZIVA公司基于英特尔至强处理器进行的研究,现场看来,渲染出的狮子十分逼真。
小结
雷锋网了解到,英特尔近来采取不少措施,将自己的核心AI技术能力提供给企业和开发者,希望能有更多的合作伙伴一起打造软件+硬件+生态全方位一体的人工智能战略。Naveen Rao谈到,事实上,当我思考什么能帮助我们加快向以人工智能为导向的计算未来转型时,我可以确信的是我们需要提供即广泛又能达到企业规模的解决方案。
在这周的微软人工智能大会上,微软宣布推出Project Brainwave预览版,以加速深度神经网络训练和部署,该技术由英特尔的现场可编程门阵列(FPGA)和芯片Stratix 10提供支持。现在,英特尔的合作伙伴还有谷歌、AWS、百度、Novartis、C3 IoT等。
现在关注“雷锋网”微信公众号(leiphone-sz),回复关键词【2018】,随机抽送价值 3999 元的参会门票 3 张
英特尔AI事业部三位负责人讲解:AI技术如何落地应用
全球科技巨头争相造芯,AI芯片大战即将开打?
原创文章,未经授权禁止转载。详情见 转载须知 。


论文仓汇总了汉语字典,新华字典,成语字典,组词,词语,在线查字典,中文字典,英汉字典,在线字典,康熙字典等等,是学生查询学习资料的好帮手,是老师教学的好助手。

吉林恒昇医疗技术服务有限公司为您提供长春受试者招募,长春临床研究,长春临床试验,吉林受试者招募,吉林临床试验,吉林临床研究,长春恒昇医疗,吉林恒昇医疗,吉林恒昇医疗技术服务等方面信息,吉林恒昇医疗技术服务有限公司为医药研发领域提供专业的受试者招募及管理服务,是吉林省较早接触爱试者招募行业的企业之一
")
深圳人才网(www.0755rc.com)是深圳最具权威性的人才招聘网站,提供最新的深圳人才、深圳招聘、深圳人才市场招聘会信息等服务,深圳招聘、求职找工作首选深圳人才网。

广州超科自动化科技有限公司专注于中央空调节能控制,高效机房,恒温恒湿控制,空调集中控制,空调机房群控系统及软件研发,生产等业务,我司技术实力雄厚,拥有技术先进的人才,致力于为广大客户提供高质量高性能的产品及服务.业务咨询热线18302007161.

湖北大力专业生产铝合金油罐车,盐酸液碱次氯酸钠等化工液体钢衬塑复合罐车,普货供液罐车,危险品厢式车,气瓶车,洒水车,清障车等多种车型,销售电话18407218004

艾诺安规测试仪安规综合测试仪耐压绝缘测试仪交直流耐压测试仪泄漏电流测试仪绝缘电阻测试仪接地电阻测试仪耐压测试仪医用泄漏测试仪

厦门宾果软件,成立于2005年,是国内专业的电子商务系统及服务提供商,为企业提供S2B2C商城系统、B2B2C多用户商城系统、B2B电商平台开发、网上商城开发、直播商城开发、微信小程序商城开发、APP商城开发、跨境电商/农村电商/生鲜电商/新零售等完善的电商解决方案,助力企业数字化转型升级,支持商城系统定制开发,源码交付,系统免费升级.

达闻天津成考网为达闻培训学校旗下天津成人高考函授站点,为考生提供2025年天津成人高考报名,天津非脱产学历报名、天津函授本科、专科报考条件、报考流程等天津成人高考报名报考相关指导服务,天津成人高考院校与专业招生计划及天津成考报名时间、成人高考考试科目、天津成考退役士兵政策等信息敬请关注达闻天津成考网。

青州市千台农业机械厂长期以来致力于蔬菜产业机械的研究与开发,主要产品有大棚棉被切割机、保温被切割机、大棚棉被设备等,大棚棉被机价格优惠。其设计博众家之长,荟萃行业精华,产品选用了技术成熟的配套部件,动力匹配合理,视野开阔,外型美观、大方。

四川鑫诚卓久电器设备有限公司

天长市科技大市场承载着项目管理、发布、对接、交易等重要功能,为天长市企业、高校、科研机构开展技术转移成果转化架设桥梁,打造科技中介服务中心,建设天长市技术交易中心,为天长市技术转移,科技成果转化提供全方位服务。


goodnotes怎样左右分屏,goodnotes软件怎么分屏还有不少的小伙伴不清楚,分屏功能可以让大家更加方便的学习或在办公,那么下面就一起来看看分屏的操作方法吧!...。

世界银行总裁批评微软700亿美元收购暴雪,全球很多人还很贫困这几天微软以近700亿美元的价格收购动视暴雪的消息引发热议,全球游戏玩家都在关注这事,而且微软这一举动也在游戏之外引发争议,世界银行总裁针对此事就持批评态度,认为全球很多人还在贫苦中,马尔帕斯在彼得森国际经济研究所的一次在线活动中表示,贫穷国家需要更多的资本流入,但发达国家异...。

发表在明基投影仪2022,7,2610,19明基LX833STD投影仪是一款教育工程投影仪,和其他的明基款式不一样,明基LX833STD外机设计非常有金属质感,这款价格在6千左右的教育工程机销量非常的好,某东有十万,的销量,这么有这么好用吗,今天我们就一起看看明基LX833STD投影仪怎么样,从参数配置的角度分析性价比,明基LX833...。

上班室晒出了一组马思纯的新写真,照片中马思纯身穿一件带有黄色印花的衬衫,清纯净净,便捷又美妙,在镜头前眼神温顺愁容甜,...。

太平洋汽车网,Cerato中文名赛拉图,属于起亚车系,是韩系车,目前曾经暂停开售了,cerato,赛拉图,是韩国起亚汽车首先在欧美地域推出的a,级轿车,多少钱在8到10万,和伊兰特共平台,底盘一样发起机一样能源总成都一样,只不过调教有点差异而已,温馨为主,静止很普通,目前在中国是西风悦达起亚在产,赛拉图,Cerato,是起亚凝聚了世...。

圆压平型凸版印刷机,印刷时,圆型的压印滚筒敌对面的印版相接触,印刷速度比平压平的印刷机快,无利于启动大幅面印刷,依照压印滚筒的静止方式,圆压平凸版印刷机又分为一回转和二圆转两种,1.一回转凸版印刷机压印滚筒每旋转一周,版台则往复静止一次性,实现一个上班行程,这种机器当印刷用纸尺寸相反时,其压印滚筒的直径比其它类型的印刷机大得多,这样版...。

主动安保方面,SPARK乐驰驳回前盘后鼓式刹车,刹车成果杰出,并装备ABS,EBD有效坚持紧急刹车时的车身稳固性及管感性,ABS能管理车轮坚持在转动形态而不会抱死不转,防止车轮抱死造成车辆失控,EBD的作用是平衡四个车轮的刹车力,让车身在极限形态下依然坚持可控性,防止制动时容易形成的跑偏、打滑、歪斜和车辆侧翻意外,除此之外,杰出的操控...。

第一次性突然熄火须要审核供油火花塞点前线圈发电机及电瓶延续打火有或者造成发起机缸体内喷油过多淹缸了假设起动机每次都是反常举措的话,电瓶亏电的话起动机也不转,吉普指南者的油耗,Jeep指南者有出口版和国产版,不同的车油耗不一样上方列出了局部车的油耗,数据起源于网上局部车主的反应国际指南搭载14T165马力L4发起机,婚配7挡能源换挡汽车...。

想跟球迷说声对不起,在主场没能赢下泰国队,足球较量我感觉就是团队的静止,不能说是某一团体,作为队长我没能率领球队取失利利,当然我有责任,而且当天年轻球员施展得十分好,很庆幸的是年轻球员进球了,或者我的责任大些,我没有率领他们实现好义务,皇马新买的门将41号,寻晚红魔皇马那场的首发门将,是从哪个球队买回的,急就是迭戈·洛佩斯,因为卡...。

据韩联社报道,朝鲜今日,21日,对韩国脱北集团分发反朝传繁多事示意抗议,宣称将如数奉还,朝鲜休息党副部长金与合理天经过朝中社宣布说话称,边陲地带再次普及恶浊的废纸和东西,咱们曾经事前正告过不要再出现这种状况,理所应当对此作出回应,金与正称对朝空飘传单的脱北者集团是,渣滓,,并示意这些举动将受到其外国民众的谴责,韩国脱北者集团今日示意,...。

MetaCJ是元宇宙数字世界程序,是专门打造各种主题线上社区,为KOL、自媒体构建专门的虚拟空间。在MetaCJ元宇宙数字世界中,搭建、构筑CJPlus,

云开发全球手机验证码发放+短**去水印等组合微信小程序源码带流量主这是一款特别的小程序,验证码功能可能大家都还没见过吧!支持全球验证码发放,支持激励**查看更多手机号码另外还有短**平台去水印解析功能和抠图功能...
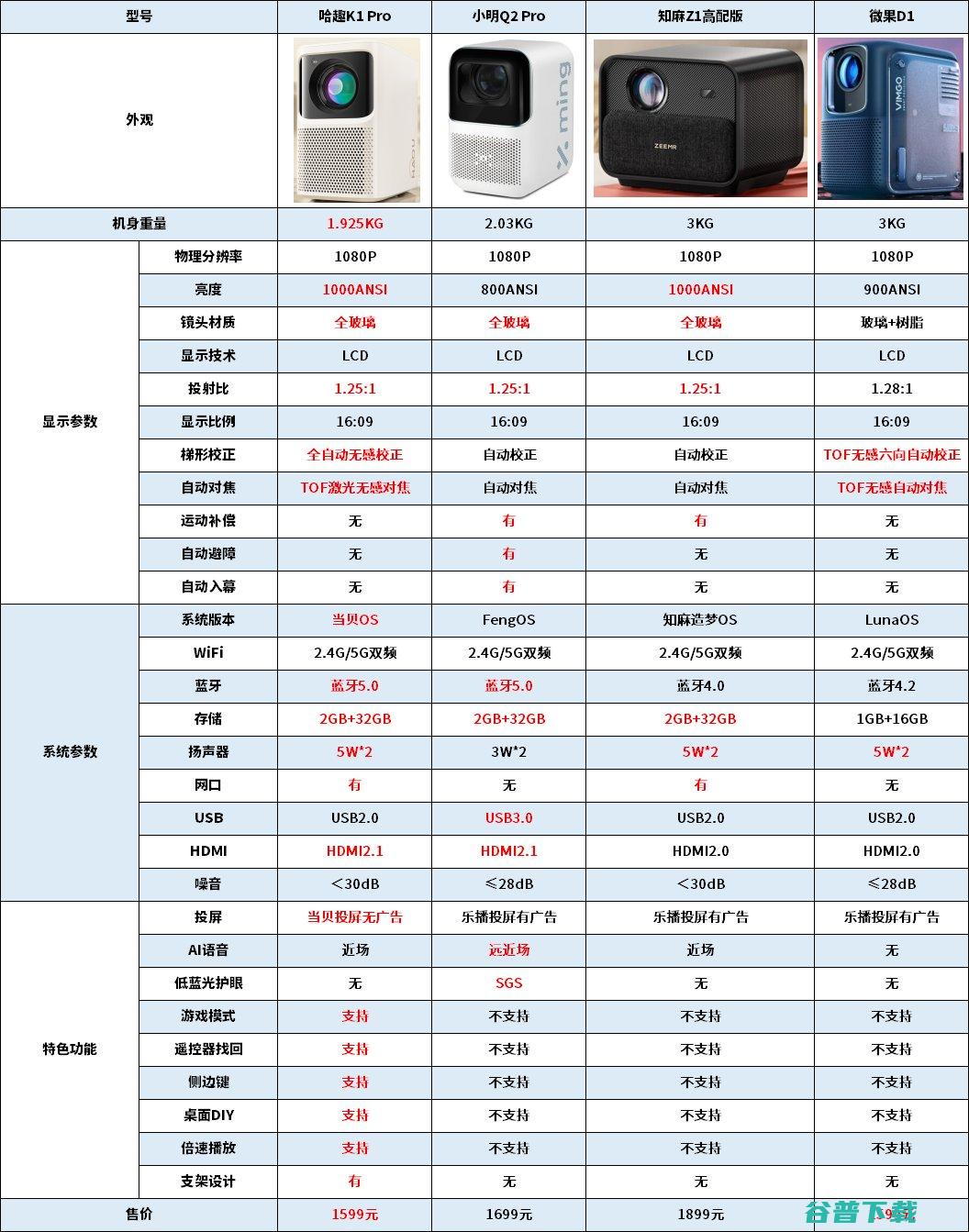
哈趣投影、小明投影、知麻投影、微果投影均主打千元入门级投影,不少投影新手在入坑智能投影时都会优先在这四个品牌中进行选择,近日,哈趣推出新品哈趣K1Pro,其与竞品小明Q2Pro、知麻Z1高配版、微果D1又有什么区别及不同,先上结论,在哈趣K1Pro、小明Q2Pro、知麻Z1高配版、微果D1的参数对比中,哈趣K1Pro以优秀的硬件条件及...。

对于我们大部分普通人来说,名片的意义可能就是一张小小的纸片,但对于那些顶级的富豪大佬们来说,名片是一种不可或缺的商业工具,在推杯换盏的顶级酒会,遇到合适的人,拿出一张名片,轻语一声,这是我的名片,就可能得到一个意义重大的机会,一位成功的商人,不同年龄段有不同的名片,从名片也能看出一个人当时的发展状况、心境,今天咱们以马云为例,看看马云...。

一眨眼2018年就要过去了,昔日的80后即将迈进40岁,而85后也早已迈入奔三的大军中,90后、95后开始慢慢的成为了新一代网民主力,而对于80后这些老网民来说,那些昔日上网的记忆你还记得吗?回归国内互联网的发展,从1997年开始,国内最早的一批,网虫,开始形成,而那个时候没有宽带、没有智能手机、没有3,4G网络,想上网只能靠电话线拨...。

雷锋网消息,爱芯科技8月6日宣布完成A,轮融资,总金额达数亿元人民币,本轮融资由韦豪创芯、美团联合领投,GGV纪源资本、美团龙珠、冯源资本、元禾璞华、石溪资本、天创资本以及高德地图创始人成从武跟投,原有股东方继续投资,云岫资本担任独家财务顾问,今年4月,爱芯科技也曾宣布接连完成Pre,A、A两轮融资,总金额达数亿元人民币,Pre,A轮...。

字节跳动裁撤战略投资团队,引发恐慌1月19日消息,多家媒体报道,字节跳动将整体裁撤投资业务,涉及员工约有百人,其中,战略投资负责人赵鹏远及战投板块部分员工或将放弃投资业务,并入战略业务;财务投资板块则将彻底解散,赵鹏远等5人转去总裁办,负责公司的整体战略;战略与投资部的部分人员转去业务线做战略,其余人员裁员;财务投资线人员大部分被裁掉...。
