准确稀疏可解释 ICML 三大优点兼具的序列数据预测算法LLA Smola论文详解 2017 Alex (什么叫稀疏解)
雷锋网 AI 科技评论按:近日,ICML2017收录的一篇论文引起了雷锋网AI科技评论的注意。这篇关于序列数据预测的论文是 Alex Smola 和他在 CMU 时的两个博士生Manzil Zaheer 和 Amr Ahmed 共同完成的,后者目前已经加入谷歌大脑。
Alex Smola是机器学习界的重要人物,他的主要研究领域是可拓展算法、核方法、统计模型和它们的应用,已经发表超过200篇论文并参与编写多本学术专著。他曾在NICTA、雅虎、谷歌从事研究工作,在2013到2016年间任CMU教授,之后来到亚马逊任AWS的机器学习总监。MXNet 在去年成为 Amazon AWS 的官方开源平台,而 MXNet 的主要作者李沐正是 Alex Smola 在 CMU 时的学生。
以下雷锋网 AI 科技评论就对这篇名为「Latent LSTM Allocation: Joint Clustering and Non-Linear Dynamic Modeling of Sequential>

背景
序列数据预测是机器学习领域的一个重要问题,这个问题在文本到用户行为的各种行为中都会出现。比如在统计学语言建模应用中,研究目标是在给定的语境下预测文本数据的下一个单词,这和用户行为建模应用中根据用户历史行为预测下一个行为非常类似。准确的用户行为建模就是提供用户相关的、个性化的、有用的内容的重要基础。
一个好的序列数据模型应当准确、稀疏、可解释,然而目前所有的用户模型或者文本模型都不能同时满足这三点要求。目前最先进的序列数据建模方法是使用 LSTM(Long-Short Term Memory)这样的 RNN 网络,已经有许多例子证明他们可以有效地捕捉数据中的长模式和短模式,比如捕捉语言中表征级别的语义,以及捕捉句法规律。但是,这些神经网络学到的表征总的来说不具有解释性,人类也无法访问。不仅如此,模型所含的参数的数量是和模型能够预测的单词类型或者动作类型成正比的,参数数量往往会达到千万级甚至亿级。值得注意的是,在用户建模任务中,字符级别的 RNN 是不可行的,因为描述用户行为的往往不是单词而是 hash 指数或者 URL。
从另一个角度看这个问题,以 LDA 和其它一些变种话题模型为代表的多任务学习潜变量模型,它们是严格的非序列数据模型,有潜力很好地从文本和用户数据中挖掘潜在结构,而且也已经取得了一些商业上的成果。话题模型很热门,因为它们能够在不同用户(或文档)之间共享统计强度,从而具有把数据组织为一小部分突出的主题(或话题)的能力。这样的话题表征总的来说可以供人类访问,也很容易解释。
LLA模型
在这篇论文中,作者们提出了 Latent LSTM Allocation(潜LSTM分配,LLA)模型,它把非序列LDA的优点嫁接到了序列RNN上面来。LLA借用了图模型中的技巧来指代话题(关于一组有关联的词语或者用户行为),方法是在不同用户(或文档)和循环神经网络之间共享统计强度,用来对整个(用户动作或者文档)序列中的话题进化变化建模,抛弃了从单个用户行为或者单词级别做建模的方法。
LLA 继承了 LDA 模型的稀疏性和可解释性,同时还具有 LSTM 的准确率。作者们在文中提供了多个LLA 的变种,在保持解释性的前提下尝试在模型大小和准确率之间找到平衡。如图1所示,在基于Wikipedia数据集对语言建模的任务中,LLA 取得了接近 LSTM 的准确率,同时从模型大小的角度还保持了与LDA 相同的稀疏性。作者们提供了一个高效的推理算法用于LLA的参数推理,并在多个数据集中展示了它的功效和解释性。

柱状图是参数数量,折线是复杂度。根据图中示意,在基于 Wikipedia 数据集的语言建模任务中,LLA 比 LDA 的复杂度更低,参数数量也比 LSTM 大大减少。
LLA 把分层贝叶斯模型和 LSTM 结合起来。LLA 会根据用户的行为序列数据对每个用户建模,模型还会同时把这些动作分为不同的话题,并且学到所分到的话题序列中的短期动态变化,而不是直接学习行为空间。这样的结果就是模型的可解释性非常高、非常简明,而且能够捕捉复杂的动态变化。作者们设计了一个生成式分解模型,先用 LSTM 对话题序列建模,然后用Dirichlet 多项式对单词散播建模,这一步就和 LDA 很相似。

假设话题数目为K、单词库大小为V;有一个文档集D,其中单篇文档d由N个单词组成。生成式模型的完整流程就可以表示为(上图 a 的为例):

在这样的模型下,观察一篇指定的文档d的边际概率就可以表示为:
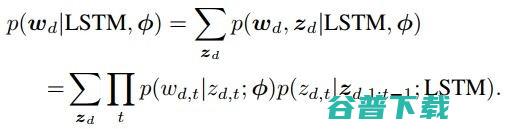
式中,
 就是文档中给定某个话题下的前几个词之后,对下一个次生成话题的概率;
就是文档中给定某个话题下的前几个词之后,对下一个次生成话题的概率;
 则是给定了话题之后生成单词的概率。这个公式就展现出了对基于 LSTM 和 LDA 的语言模型的简单改动。
则是给定了话题之后生成单词的概率。这个公式就展现出了对基于 LSTM 和 LDA 的语言模型的简单改动。
这种修改的好处有两层,首先这样可以获得一个分解模型,参数的数量相比 RRLM 得到了大幅度减少。其次,这个模型的可解释性非常高。
另一方面,为了实现基于 LLA 的推理算法,作者们用随机 EM 方法对模型表示进行了近似,并设计了一些加速采样方法。模型伪码如下:

作者们认为,模型直接使用原始文本会比使用总结出的主题有更好的预测效果。所以在 Topic LLA之外,又提出了两个变体 Word LLA 和 Char LLA (前文 a、b、c 三个模型),分别能够直接处理原文本的单词和字符(Char LLA自己会对字符串做出转换,从而缓和 Word LLA 单词库过大的问题 )。
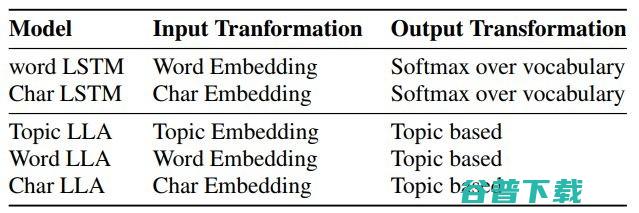
在几个实验中,作者们把60%的数据用于训练模型,让模型预测其余40%作为任务目标。同步对比的模型有自动编码器(解码器)、单词级别LSTM、字符级别LSTM、LDA、Distance-dependent LDA。
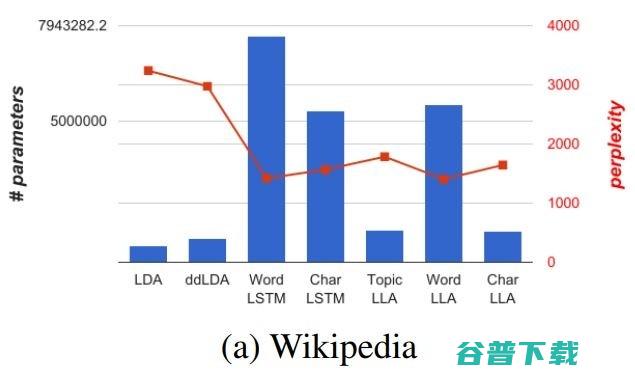
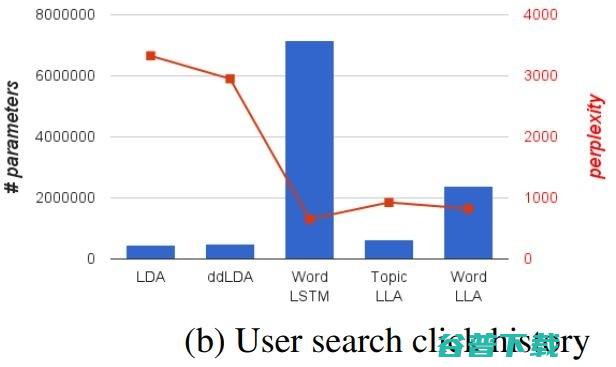
柱状图部分的参数数量用来体现模型大小,折现的复杂度用于体现模型的准确率。可以看到,两个任务中 LDA 仍然保持了最小的模型大小,而单词级别LSTM表现出了最高的准确率,但模型大小要高出一个数量级;从单词级别LSTM到字符级别LSTM,模型大小基本减半,准确度也有所牺牲。
在这样的对比之下就体现出了 LLA 的特点,在保持了与LDA 同等的解释性的状况下,能够在模型大小和准确度之间取得更好的平衡(目标并不是达到比LSTM更高的准确率)。
其它方面的对比如下:
收敛速度 LLA的收敛速度并没有什么劣势,比快速LDA采样也只慢了一点点。不过基于字符的LSTM和LLA都要比其它的变体训练起来慢一些,这是模型本质导致的,需要在单词和字符层面的LSTM都做反向传播。

特征效率 作者们做了尝试,只具有250个话题的三种 LLA 模型都比具有1000个话题的 LDA 模型有更高的准确率。这说明 LLA 的特征效率更高。从另一个角度说,LLA 的表现更好不是因为模型更大,而是因为它对数据中的顺序有更好的描述能力。

解释性 LLA和LDA都能对全局主题做出揭示,LLA 总结出的要更加明确。如下表,LDA 会总结出“Iowa”,仅仅因为它在不同的文档中都出现了;而 LLA 追踪短期动态的特性可以让它在句子的不同位置正确切换主题。

联合训练 由于论文中的模型可以切分为 LDA 和 LSTM 两部分,作者们也对比了“联合训练”和“先训练 LDA,再在话题上训练 LSTM”两种不同训练方式的效果。结果表明,联合训练的效果要好很多,因为单独训练的 LDA 中产生的随机错误也会被之后训练的 LSTM 学到,LSTM 的学习表现就是由 LDA 的序列生成质量决定的。所以联合训练的状况下可以提高 LDA 的表现,从而提高了整个模型的表现。

论文地址:
雷锋网 AI 科技评论编译整理。
原创文章,未经授权禁止转载。详情见 转载须知 。



阿里巴巴公司黄页拥有过千万的公司信息,每日有大量的新注册公司。阿里巴巴公司黄页为您提供详细的公司介绍、联系人资料、联系方式等公司信息,加入阿里巴巴公司黄页,您可立即成为其中一员!查找公司信息尽在阿里巴巴公司黄页

河南郑州最专业的手机app开发制作团队和公司,专注手机app开发制作五年以上,开发制作过几十个手机app项目,具备承接大型app项目能力!QQ:1278560556

淘好源百科(taohaoyuan.cn)分享日常生活中各类常见的生活知识、生活常识,常见问题等生活技巧,生活小窍门,生活百科,生活问答等常见问题,帮助您解决日常生活的各类小问题。

雅韩视|Airhans|电动牙刷|吸奶器|无线充电|医疗设备|MCU开发|单片机开发|蓝牙2.4G|加热设备|加湿器|PLCC控制器|成人用品电路设计|消费类电子PCBA|

上海弘策,江苏弘策,弘策自动化,安全电压,直流,接线端子,端子台,EMI电源滤波器,机柜照明,电控柜照明,机柜灯,万可,町洋,埃德,WAGO,DINKLE,AERODEV,万可电子,WAGO接线端子,连接技术,弹簧接线端子,接线端子,连接技术,多用途连接器,多用途连接器系列,印刷电路板连接技术,WAGOI/O系列,自动化,自动化,自动化技术,分布式自动化,楼宇自动化,笼式弹簧

关注病理医学的学科建设与发展方向,支持病理工作者的继续教育和专业培训,促进临床与病理的联系交流,传播普及病理医学知识。设有病例讨论、在线课堂、病理学院、招聘求职、资源分享、期刊文献、专业文档、家空间、会议发布、网上书店、病理产品信息库等内容和服务。

上海奥特博格汽车工程有限公司

潍坊人才网创建于1999年,是潍坊市人力资源服务集团旗下,专注于潍坊本地招聘、求职和人才服务的门户网站。专注潍坊本地人才市场,及时发布最全最准确的潍坊本地招聘求职信息,为广大用人单位和求职者搭建双向选择的招聘求职平台!

深圳市博睿联橡塑材料有限公司

荣品号是一个专注于生活领域的知识平台,提供全面的生活百科知识大全,包括美食、娱乐、家居、时尚、旅游与网络知识等,让生涩的知识简单易懂。

潍坊市第一春食品有限公司

佛山市龙缘家具有限公司成立于2006年,多年来一直在民用套房领域精耕细作。志存高远,公司创立之初就致力于利用现代化的生产技术为人类打造健康舒适的生活空间。用实力让情怀落地,公司耗巨资不断大量引入德国豪迈数控设备群。经过多年的发展公司产品线由现代,简欧、北欧、轻奢、青少年儿童扩充至当下流行的意式极简等。旗下“欧风韩雨”品牌套房产品先后在国内各大中小城市开设了近家专卖店,累计服务了全国超万家庭。


现在消费者对于家庭饮用水的需求量也很大,很多人急需健康饮用水,大多数为了饮水更安全,选择了安装净水器,净水器的品牌比较多,对于创业者来说也可以选择品牌店加盟,如何加盟净水器专卖店,开店成本多少钱,如何加盟净水器专卖店净水器专卖店公司主要以各种品牌家用或者商用的净水设备生产经营为主,生产销售的产品种类比较多,包括纯水机、净水器、直饮机、...。

过去一年,于自动驾驶来说是非常梦幻的一年,资本疯狂进入、激光雷达落地开启、细分场景多点开花、Robotaxi开始走进大众视野,藉由此,新智驾推出了,对话CEO,系列专题,希望呈现给业界更多对自动驾驶行业不一样的理解与洞见,本篇为系列报道的第七篇,对象为斯年智驾CEO何贝,以下是正文,从五年前的算法至上到如今的落地为王,自动驾驶江...。

雷锋网讯,在亚马逊宣布禁止向美国警方出售面部识别软件Rekognition一年以后,本周,IBM、微软相继宣布停止向美国警方提供面部识别技术,并反对将其用于大规模监视和种族定性,尽管承诺的细节和条款有所不同,比如亚马逊、微软表示暂时停止,而IBM则完全退出面部识别技术的出售,但这三家公司都要求美国华盛顿特区监管该技术,2018年,美国...。

procreate怎样设置照明工作室,procreate是一款很好用的绘画软件,新版本的软件还增加了3D模型的支持,你可以直接在iPad上的照明工作室调整光源,非常方便,具体怎么操作呢,还不清楚的小伙伴就一起来看看吧!...。

翼龙,X无人机是一款远程、重载、独立遂行多义务的中空长航时无人机系统,这型无人机片面基于实战场景以及客户需求,驳回正向设计理念,是中空长航时无人机系统产品的,天花板,,处于国际先进水平,翼龙,X无人机现已常态化展开实验试飞上班,该机集远航程、重挂载、多用途等泛滥好处于一身,充沛承袭了翼龙系列无人机成熟技术和实战阅历,又翻新地融入了当今...。

1、经过从三菱欧蓝德的官方查问,三菱欧蓝德的变速箱是cvt变速箱cvt变速箱理论指一种汽车变速器,也叫无级变速器cvt与有级变速器的区别在于,它的变速比不是连续的点,而是一系列延续的值,从而成功了良好的经济功能源性,2、第三代INVXSCVT变速箱2021款欧蓝德装备三菱首创MIVEN发起机和第三代INVXSCVT变速箱欧蓝德Outl...。

关于无心向购置二手RCZ的消费者而言,能否值得购置也是困扰不少人的疑问,上方,就让咱们从性能、温馨性、长久性等方面,深化剖析RCZ在二手市场的体现,为广阔消费者启动一次性深化片面的评测,性能体现RCZ搭载了1.6升涡轮增压直喷发起机,最大输入功率为155~200马力,最大扭矩为240~275牛米,在减速性上,RCZ可以完美的满足日罕用...。

墨西哥总统洛佩斯2日在资讯颁布会上说,墨南部恰帕斯州接近危地马拉边陲地区日前出现帮派抵触,关系报告显示,这起抵触形成19人死亡,墨西哥安保与公民包全部门1日颁布报告说,6月28日网上行播的一段视频显示,在一辆卡车上发现多名携带武器的死者,政府多个部门考查后确认,抵触出当初恰帕斯州拉孔科迪亚市左近,19名死者系中枪而亡,其中14人为男性...。

zui近在网上有看到这个去俄罗斯旅行的事件,其实不用坐飞机去,话说还能坐火车去,哈哈,全程很长,尽是美景,还通过蒙古国,所以很多人想疫情完了,就去一趟火车之旅,话说这趟火车之旅就是k3火车之旅了,从北京到莫斯科,那么这个k3火车全程路途图是怎样样的呢,又通过哪些站点呢,上方一同来看看吧,1、k3火车全程路途图北京,蒙古,莫斯科,人生的...。

09款福克斯s性能如下,1、2009年福特福克斯是一款紧凑型轿车,电力动力类型燃油车,装备1.4t直列四缸涡轮增压器汽车发起机,大马力143匹,进气口模式涡轮增压器,汽柴油型号92号车用汽油,汽缸数量四个,发起机缸体和气缸盖原资料铝合金型材,2、09款福克斯是一款紧凑车,电力动力类型车用汽油,装备1.8l直列四缸自吸汽车发起机,大马力...。

人工智能(AI)的未来是一个充满潜力和希望的世界,引领我们走向创新、效率和前所未有的进步。当我们站在人工智能驱动时代的悬崖边时,这种变革性技术的能力和应用正在重塑行业、社会和人类互动。让我们深入研究人工智能的全面细节,进一步探索以获得更深入的见解。人工智能的发展趋势表明在医疗、金融、交通等领域都有多方面的进步。在医疗保健领域,人工智能的影响之一是通过整合机器学习算法,帮助进行诊断、制定个性化治疗计划和药物发现。通过利用人工智能技术,医疗专业人员能够快速分析大量数据,从而实现更准确的诊断和优化的患

北京市将上线社会保险信息管理新系统,社保,北京市,保险费,社会保险,养老保险,工伤保险,城乡居民,北京地震

想要更好地提升数学学习能力,那么必不可少的便是形成有效的数学思维,本期就来为你分享五款有趣的数学思维游戏,里面全都是和数学有关的谜题,通过不断地解决问题来强化学习能力,这些游戏都以寓教于乐的形式吸引孩子自主学习,如果有需要的玩家,可以下载来尝试哦,1、,宝宝数字书写,宝宝数字书写,是一款侧重于学习的休闲益智游戏,通过寓教于乐的方式来...。

现在很多朋友都希望能通过软件来帮助自己去学习英语,尤其是在口语化的训练上更是非常的关键,今天小编就和大家说说自学英语口语最好的软件有哪些,想要随时随地的去选择英语,让自己的日常交流口语越来越熟练,那么以下这几款软件就非常的适合,感兴趣的话,就接着往下看吧,1、,英语口语8000句,它里面包含了海量的不同精品课程,针对英语的音标和单词,...。

麻辣烫是起源于川渝的汉族特色小吃,和冒菜略微不同,麻辣烫起源于四川,汉族特色小吃,是川渝地区有特色也能代表,川味,的一种饮食文化,川渝地区,或大或小的麻辣汤店家及小摊,遍及大街小巷,可谓是川渝城市中的一道亮丽风景,麻辣烫是食物的平民化归宿,青菜鱼肉,被细细地穿在了签子上,一股脑儿地往高温里推,真正是赴汤蹈火,没有什么讲究的烹调过程,它...。

前乐视网CEO梁军参观FF会面贾跃亭,不后悔在乐视的六年7月25日,前乐视网CEO梁军今日发布微博称,,时隔两年,再次有机会去参观FF,,并与贾跃亭会面,他表示不后悔在乐视的六年,从乐视和贾跃亭身上学到了很多东西,并祝愿FF能成功,贾跃亭能够东山再起,梁军微博信息显示,其现为新视家科技CEO,据一财报道,在乐视内部,乐视创始人贾跃亭曾...。
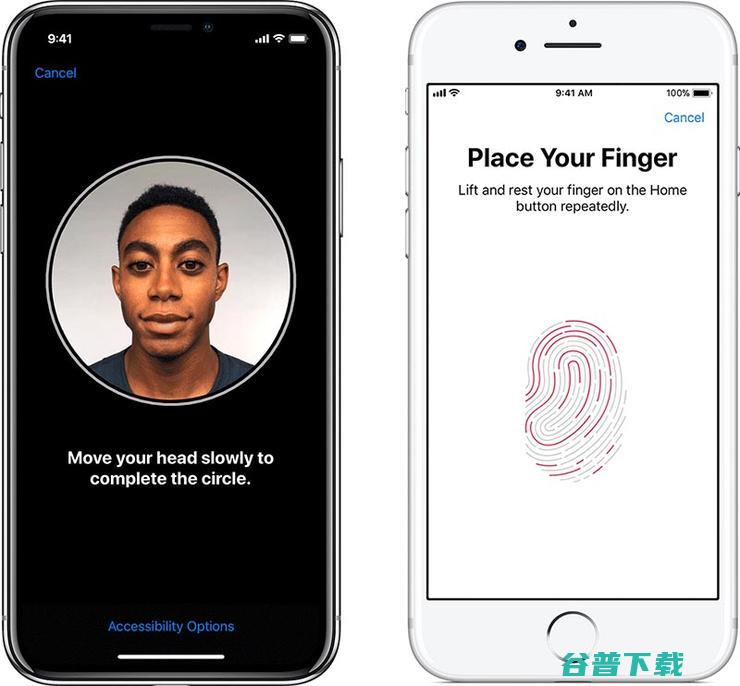
2013年9月,苹果在iPhone5s发布会上,面向全世界介绍了基于指纹识别的TouchID功能,开启了整个智能手机行业全面走向指纹识别的大潮,四年后,苹果在最新发布的iPhoneX上用FaceID取代了TouchID,又让人脸识别开始风靡整个行业——此后的三代iPhone新品上,TouchID消失无踪,但其实,TouchID并未被苹...。
