2017六篇最佳论文介绍 CVPR 年度最精彩研究 附打包下载 (2017年6月六级范文)
雷锋网 AI 科技评论按:CVPR 2017的获奖论文已经在大会的第一天中公布,共有6篇论文获得四项荣誉。雷锋网 AI 科技评论对6篇获奖论文做了简要介绍如下。
本届CVPR共有两篇最佳论文,其中就有一篇来自苹果。
论文作者:康奈尔大学 Gao Huang,清华大学 Zhuang Liu,康奈尔大学Kilian Q. Weinberger,Facebook 人工智能研究院Laurens van der Maaten
论文地址:
论文简介:近期的研究已经展现这样一种趋势,如果卷积网络中离输入更近或者离输出更近的层之间的连接更短,网络就基本上可以更深、更准确,训练时也更高效。这篇论文就对这种趋势进行了深入的研究,并提出了密集卷积网络(DenseNet),其中的每一层都和它之后的每一层做前馈连接。对于以往的卷积神经网络,网络中的每一层都和其后的层连接,L层的网络中就具有L个连接;而在DenseNet中,直接连接的总数则是L(L+1)/2个。对每一层来说,它之前的所有的层的 feature-map 都作为了它的输入,然后它自己的feature-map 则会作为所有它之后的层的输入。
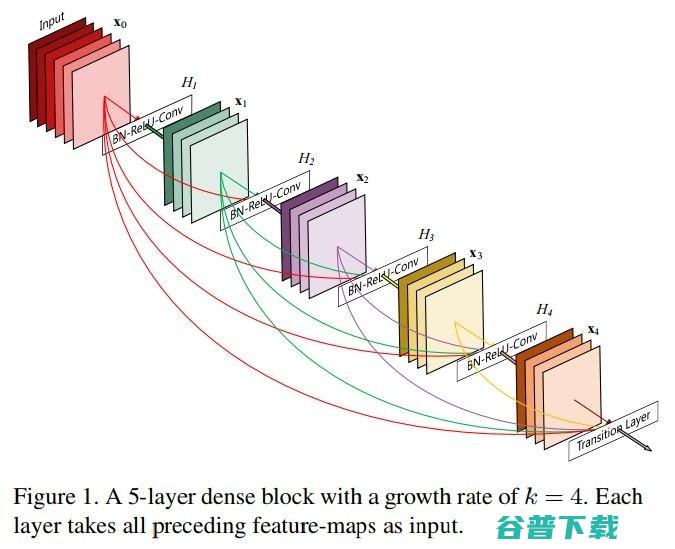
DenseNet 类型的网络有这样几个引人注目的优点:它们可以缓和梯度消失的问题,可以加强特征传播,可以鼓励特征的重用,而且显著减少参数的数量。论文中在 CIFAR-10、CIFAR-100、SVHN、ImageNet 这四个高竞争性的物体识别任务中进行了 benchmark,DenseNet 在多数测试中都相比目前的顶尖水平取得了显著提升,同时需要的内存和计算力还更少。
论文作者:苹果公司Ashish Shrivastava, Tomas Pfister, Oncel Tuzel, Josh Susskind, Wenda Wang, Russ Webb
论文地址:
论文简介:随着图像领域的进步,用生成的图像训练机器学习模型的可行性越来越高,大有避免人工标注真实图像的潜力。但是,由于生成的图像和真实图像的分布有所区别,用生成的图像训练的模型可能没有用真实图像训练的表现那么好。为了缩小这种差距,论文中提出了一种模拟+无监督的学习方式,其中的任务就是学习到一个模型,它能够用无标注的真实数据提高模拟器生成的图片的真实性,同时还能够保留模拟器生成的图片的标注信息。论文中构建了一个类似于 GANs 的对抗性网络来进行这种模拟+无监督学习,只不过论文中网络的输入是图像而不是随机向量。为了保留标注信息、避免图像瑕疵、稳定训练过程,论文中对标准 GAN 算法进行了几个关键的修改,分别对应“自我正则化”项、局部对抗性失真损失、用过往的美化后图像更新鉴别器。

论文中表明这些措施可以让网络生成逼真的图像,并用定性的方法和用户实验的方法进行了展示;定量测试则是用生成的数据训练模型估计目光注视方向、估计手部姿态。结果表明,经过模型美化后的生成图像可以为模型表现带来显著提升,在 MGIIGaze 数据集中不依靠任何有标注的真实数据就可以取得超过以往的表现。
论文详解:上周时候苹果开放了自己的机器学习博客“苹果机器学习日记”,其中第一篇就是对这篇获奖论文的详解,雷锋网 AI 科技评论编译文章 在这里 ,欢迎感兴趣的读者详细了解。
论文作者:多伦多大学计算机学院Llu´ıs Castrejon,Kaustav Kundu,Raquel Urtasun,Sanja Fidler
论文地址:
论文简介:论文中介绍了一种半自动的物体标注方法。这套系统的思路是,不再像以往一样把图像中的物体分割作为一种像素标注问题,把它看作一个多边形位置预测问题,从而模仿目前已有的标注数据集的方式生成检测标注框。具体来讲,论文中的方法在输入图像后可以依次生成多边形的边把图像中的物体围起来。这个过程中,人类标注员可以随时参与并纠正错误的顶点,从而得到人类标注员眼中尽可能准确的分割。

根据论文中的测试,他们的方法可以在 Cityscapes 的所有类别中把标注速度提升至4.7倍,同时还可与原本真值的重合度 IoU 达到78.4%,与人类标注者之间的典型重合率相符。对于车辆图像,标注速度可以提升至7.3倍,重合度达到82.2%。论文中也研究了这种方法对于从未见过的数据集的泛化能力。
论文作者:华盛顿大学,Allen 人工智能学院的Joseph Redmon 与 Ali Farhadi
论文地址:
论文简介:论文中介绍了名为“YOLO9000”的顶级水平的实时物体检测系统,它可以检测的物体种类达到了9000种。论文中首先介绍了对原始的 YOLO 系统的多方面提升,有些是论文中新提出的方法,有些是从之前别人的成果中借鉴的。提升后的 YOLOv2 模型在 PASCAL VOC 和 COCO 这样标准的物体检测任务中有顶级的表现。在使用一个新的、多尺度训练方法之后,这个YOLOv2 模型可以处理各种不同的图像,从而在速度和准确性之间轻松地取得了平衡。在67FPS下,YOLOv2 可以在 VOC 2007中取得76.8mAP;在40FPS下,分数可以提升为78.6mAP。这样的准确率不仅超越了目前最好的带有 ResNet 和 SSD 的Faster R-CNN,而且运行速度还明显更快。论文中最后还提出了一种将物体检测和物体分类合并训练的方法,论文作者们借助这种方法,同时运用物体检测数据集 COCO 和物体分类数据集ImageNet 训练得到了 YOLO9000。有的物体类别并没有对应的物体检测数据,而合并训练的方法让 YOLO9000 遇到它们的也时候也能够预测检测结果。

为了验证方法的效果,论文中进行了物体检测的验证测试,YOLO9000 只用了200个类别中44个类别的检测数据,就在 ImageNet 的检测验证数据集中取得了 19.7mAP;对于 COCO 中没有的156个类别,YOLO9000得到了16.0mAP。不过YOLO9000能够检测的类别远不只这200个类,它可以预测超过9000个不同类别物体的检测结果,而且仍然可以实时运行。
论文作者:以色列理工学院电气工程学院 Mark Sheinin、Yoav Y. Schechner,多伦多大学计算机学院Kiriakos N. Kutulakos
论文地址:
论文简介:夜晚的风景随着交流电照明一起跳动。通过被动方式感知这种跳动,论文中用一种新的方式揭示了夜景中的另一番画面:夜景中灯泡的类型是哪些、上至城市规模的供电区域相位如何,以及光的传输矩阵。为了提取这些信息需要先消除灯光的反射和半反射,对夜景做高动态范围处理,然后对图像采集中未观察到的灯泡做场景渲染。最后提到的这个场景渲染是由一个包含各种来源的灯泡响应函数数据库支持的,论文中进行了收集并可以提供给读者。并且论文中还构建了一个新型的软件曝光高动态范围成像技术,专门用于供电区域的交流电照明。

Longuet-Higgins 奖以英国著名理论化学家、认知科学家H. Christopher Longuet-Higgins 的名字命名。该奖设立于 2005 年,用以奖励对 CV 研究产生根本性影响的学术论文,专门用来奖励十年以前在 CVPR 发表、“经得起时间考验”产生广泛影响的论文。它是世界上第一个针对过往论文的奖项。这个奖项是由IEEE 计算机协会的“模式分析和机器智能技术委员会”TCPAMI 评选的。
在颁布该奖项时还有一个有意思的花絮——主持人介绍说,设立这样一个奖项的初衷,是因为“大家都知道,许多对学界贡献很大、影响力也很大的论文,在当年并不是最佳论文。”
论文作者:牛津大学科学工程学院James Philbin、Ondˇrej Chum、Josef Sivic、Andrew Zisserman,微软硅谷研究院 Michael Isard
论文地址:
论文简介:这篇论文介绍了一个大规模的物体图像搜寻系统。系统把用户在一副图片中框选的区域作为查询输入,然后就可以返回一个有序列表,其中都是从指定的大数据集中找到的含有同一个物体的图像。论文中用从 Flickr 上爬超下来的超过100万张图像组成一个数据集,用牛津大学的地标作为查询输入,展示了系统的可拓展性和查询性能。

由于数据集规模的原因,实验过程中给图像特征构建列表的过程是时间和性能的主要瓶颈。基于这个问题,论文中对比了不同规模拓展的方法在构建特征列表方面的表现,并且介绍了一种全新的基于随机树的量化方法,这种方法在广泛的真值中都具有最好的表现。论文中的实验表明这种量化方法对搜索结果质量的提高也有重要作用。为了进一步提升搜索性能,系统中还增加了一个高效的空间验证阶段来对论文中构建的这种基于特征列表的方法进行重新标识,结果表明它可以稳定地提高搜索质量,虽然当特征列表很大的时候效果并不显著。作者们觉得这篇论文是通往更多图片、互联网规模的图像语料库的前途光明的一步。
六篇论文打包下载如下链接:密码: 3t73
更多 CVPR 后续报道、更多近期学术会议现场报道,请继续关注 雷锋网 AI 科技评论。
CVPR最有趣的5篇论文,不容错过!内含最佳学生论文! | CVPR2017
CVPR现场直击:一文尽览最顶级的CV+学术盛会!| CVPR 2017
腾讯 AI Lab入选 CVPR 的六篇论文逐一看 | CVPR 2017
CVPR 获奖论文公布,苹果斩获最佳论文!|CVPR 2017
版权文章,未经授权禁止转载。详情见 转载须知 。


")
一帧秒创是基于新壹大模型及秒创AIGC引擎的智能AI内容生成平台,包含AI数字人、AI帮写、AI视频、AI作画等AIGC工具,可将百家号、公众号、头条号、搜狐号、新浪微博、小红书等文章一键转视频,一键生成数字人播报视频,为企业及自媒体提供一站式视频生产,全面提升内容创作效率。

温州哪家皮肤病医院好,温州华医堂皮肤病专科怎么样?温州皮肤病医院哪家好等,温州华医堂皮肤病专科是一所综合性、非盈利性医院.皮肤科开创温州皮肤病专科医院的典范,累积各种皮肤病专治案例数据,痘痘,脱发,腋臭,荨麻疹,白癜风等都是我院治疗项目,温州华医堂皮肤病专科是一家专门为皮肤病患者打造的专科医院!

天津市电缆总厂橡塑电缆厂是国内外专业的MYP矿用屏蔽电缆,YJV交联电缆,MYQ轻型移动电缆,YC橡套软电缆,CEFR船用橡套软电缆,MCP矿用采煤机电缆,MY矿用移动电缆,UGF矿用高压电缆供应商,主营产品有:MYP矿用屏蔽电缆,YJV交联电缆,MYQ轻型移动电缆,YC橡套软电缆,CEFR船用橡套软电缆,MCP矿用采煤机电缆,MY矿用移动电缆,UGF矿用高压电缆等,天津市电缆总厂橡塑电缆厂不仅具有精湛的技术水平,更有良好的售后服务和优质的解决方案

济宁迅大是粘弹体防腐材料厂家,主营粘弹体防腐带,粘弹体防腐胶带,粘弹体防腐膏等产品,粘弹体防腐胶带价格合理,可提供缠绕工具和底漆

三泉中石热收缩试验仪适用于检测材料的热收缩性能,可用于塑料薄膜基材(PVC膜、POF膜、PE膜、PET膜、OPS膜等热缩膜)、软包装复合膜、PVC聚氯乙烯硬片、太阳能电池背板及其他具有受热收缩性能的材料。

88ICON是免费设计素材网站,88ICON提供png图片、psd图片、矢量图片、背景图片、banner、ppt模板、图标icon、艺术字、海报展板、摄影照片、卡通插画、电商主图、文案字库、音效配乐等内容的免费下载。


深圳市极水实业有限公司是集产品研发、生产销售、工程设计施工以及系统运维一站式服务的企业,是专业经营温泉设计、温泉工程设计、音乐喷泉工程、水乐园工程、水处理工程、污水处理、游泳馆水处理、游泳池设备的生产供应商。

武汉闲玩网络科技提供手机游戏代理加盟,手机游戏合作渠道,网页游戏代理加盟,页游代理,手游源码代理,手游联运平台,H5游戏代理,是知名手机游戏联运SDK开发公司,联系电话:027-88069116。

爱好歌音乐下载网分享提供好看的高清MV、最新音乐下载地址及车载MV在线播放,支持手机HTML5在线播放,使用音乐MV解析工具快速获取高清MV音乐下载地址,高清MV下载,车载音乐高清MV,最新车载MV免费下载。

电网环境保护知识科普网站

团众高价二手办公设备回收为您提供多种办公设备上门回收以及办公设备转让服务,有多个成功办公设备用品回收案例,可以通过我们了解最新办公设备回收行情以及资源报价。


软银证实对滴滴出行投资规模,345亿元TechCrunch上个月报道称,滴滴出行证实4月28日完成一轮金额达人民币380亿元的融资,募集的资金将用于海外扩张,加大对人工智能等新兴领域的投资,近日,日本电信巨头软银已经证实对中国打车服务滴滴出行的投资规模,人民币345亿元,软银在2017财年年报中披露了对滴滴出行投资的金额,,软银一个海...。

一个不争的事实是,在医学影像分析领域,华人学者的影响力越来越大,近三年,2019、2020、2021,,先后有六位该领域的华人学者当选IEEEFellow,一年IEEE约有250名左右的Fellow产生,相当于会员总数的0.1%,IEEE全称是电气与电子工程师协会,医学影像作为其中相对,小众,的一个类别,获此殊荣殊为不易,论文的接受...。

雷锋网爆了个料~上两会的马化腾要做智能电视了,某知情人士也再一次跟小编确定了这件事情的真实性,小编的同事惊呼,这太猛了!,,业内人士对鹅厂做电视怎么看,有钱任性的小马哥又打算怎么推进电视领域的业务,在智能硬件领域屡屡碰壁的鹅厂这次又会不会一雪前耻,来听听大家的说法吧~腾讯做电视的动机悟空遥控器的创始人孙鹏告诉雷锋网,智能电视OTT业务...。

以上就是绿色先锋小编整理的爱奇艺体育怎样删除全部收藏内容的内容了,希望可以帮助到大家!我们会持续为您更新精彩资讯,欢迎持续关注我们哦!...。

杰,我爱你哦····老一点的国产侦探电影有,东港谍影,1978,导演,沈耀庭,国庆十点钟,1956,导演,吴天,寂静的山林,1957,导演,朱文顺,羊城暗哨,1958,导演,卢珏,古刹钟声,1958,导演,朱文顺,徐秋影案件,1958,导演,于彦夫,前哨,1959,导演,广布道尔基,铁道卫士,1960,导演,方荧,冰...。

北京期间7月27日,第33届夏季奥林匹克静止会揭幕式在法国巴黎举行,揭幕式上,法国总统马克龙发表巴黎奥运会正式揭幕,2024巴黎奥运会是法国巴黎继1900年、1924年后,时隔100年再次主办夏季奥运会,也是法国历史上第三次举行夏季奥运会,此次奥运揭幕式是奥运会历史上初次不在体育场内举行的揭幕庆典,各国静止员们乘坐船只,沿着塞纳河游行...。

文,观察者网杨蓉,被,本国代理人法案,撕裂的格鲁吉亚,将在10月26日迎来关键的议会选举,近几个月来,随着俄罗斯在乌克兰战场重振气势,格俄两国政府越走越近,美国,华尔街日报,8月29日报道,担忧,,这场全国性选举隐约有成为抵触爆点之势,这个西方的,关键盟友,要倒向俄罗斯,8月27日,格鲁吉亚总统祖拉比什维利签订法则,正式发表四年...。

一、定义不同1、不要钱软件,以自在而且不要钱的经常使用该软件,并拷贝给他人,而且不用支付任何费用给程序的作者,2、自在软件,是那些赋予用户运转、复制、散发、学习、修正并改良软件这些自在的软件,3、共享软件,以,先经常使用后付费,的形式开售的享有版权的软件,二、特点不同2、自在软件,使得用户,包含集体和集团,可以管理程序为己所用,当用户...。

什么网络电话最好用,1.爱科手机网络电话软件,爱科可在手机上拨打网络电话,提供开明式网络通信服务,包含不要钱网络电话、短信、聊天和通讯录等配置,成功随时随地与任何人咨询的通讯体验,2.阿里通网络电话,阿里通是抢手的通讯软件之一,语音明晰稳固,小巧繁难,无插件,安保适用,可在电脑和手机上经常使用,3.Skype网络电话,Skype是一款...。

1、大家或者都知道,其实可供决定的10万以内的7座SUV车型还是蛮少的但假设你对国产的一些自主品牌有所了解的话,还是能选到自己满意且性价比相对较高的7座SUV比如,最近上市的2019款7座宝骏530就很不错,新车颜值出众;10万元之内省油的七座商务车宋MAX传祺M6嘉际宝骏730新宝骏RM51宋MAX官网指点价万宋MAX是一款家用定位...。

作为起亚旗下车型中的一员,起亚K5凯酷2021款270TCVVD焕新版是不少生产者所关注的车型,接上去小编就来简明引见一下这款车,顺便再算算买它须要多少钱能力落地吧起亚K5凯酷2021款270TCVVD焕新版装备了1497TL4发起机,友谊揭示,K5,索纳塔全系,保值率都提不上啊,上市才3个月优惠就掉23万元啊,你可想好了买啊,要是想...。

DB查询分析器是一款具有特色、优异好用的数据库查询软件,软件可以查询ODBC数据源的数据。你可以同时执行多条DML语句乃至存贮过程

古风建筑总是让人有无限的遐想,古朴浪漫的经营游戏也深受玩家喜欢,今天给大家介绍中国古风模拟经营游戏推荐,经营类的游戏风格各异,有不少是古风类型,想要体验在古代当掌柜经营酒馆、客栈等等吗,在这类游戏中都能实现,如果你也对古风经营游戏感兴趣的话,一起来看看吧,1、,江南百景图,江南百景图,是一款超好玩的古风模拟经营类游戏,游戏将江南风光...。

免广告游戏软件有哪些呢,以往很多手游都会在游戏中加入各种各样的广告来赚取更多的收益,从而降低了许多玩家对游戏的好感度,因此,这一次,小编要给大家介绍一下无广告的游戏榜单,可以让玩家详细地了解到游戏的方方面面,而不会因为弹出的广告感到烦躁,如果你不喜欢有广告的游戏,那就来看看小编为大家推荐的这几款手游,希望可以帮你早日找到合适的游戏,1...。
近几年我国科技发展的越来越迅速,人工智能这种先进的技术给生活工作带来众多便利,尤其是AI系统,该系统提高效率的同时,减少更多的成本以及资金,那么人工智能软件有哪些,人工智能系统是大家极其关注的,众多小伙伴都希望选择智能系统帮助处理数据,且进行大数据分析,接下来小编为大家详细的介绍几款,我国和外国友人的社交越来越广泛,尤其是很多跨国企业...。
最近,研究公司CBInsights发布了一份美国独角兽地图,在这98家公司中,有8家属于医疗健康或生命科学领域,雷锋网对其中医疗健康相关的公司整理如下,HumanLongevity于4月完成了2.2亿美元的B轮融资,公司创始人认为公司估值约12亿美元,它想用基因组测序、人类微生物组、蛋白质组学、信息学、计算和细胞疗法技术,建设最全面的...。

你见过四棱方正的方块字商标,见过不明所以的一串英文商标,见过文字、图形、字母、数字,大杂烩,商标,但你听说过声音商标能注册吗?是的,就是这么有趣,声音商标可以是一支乐曲,可以是自然界的声音、人或动物的声音,也可以兼而有之,然而,作为一种非传统商标,想成功注册却是,难于上青天,4月27日,中国首例声音商标申请驳回复审行政纠纷案宣判,北...。
