完善 数据的设计 评估是关键 Nature 子刊 实现可信 斯坦福李飞飞团队新研究登 AI (完善数据的设计方法)

在当前 AI 模型的开发以模型为中心转向以数据为中心的趋势下,数据的质量变得尤为重要。
在以往的 AI 开发流程中,数据集通常是固定的,开发工作的重点是迭代模型架构或训练过程来提高基准性能。而现在,数据迭代成为重心,因此我们需要更系统的方法来评估、筛选、清洗和注释用于训练和测试 AI 模型的数据。
最近,斯坦福大学计算机科学系的Weixin Liang、李飞飞等人在《自然-机器智能》上共同发表了一篇题为“Advances, challenges and opportunities in creating>
AI 数据流程中的主要步骤包括:数据设计(数据的采集和记录)、数据改善(数据筛选、清洗、标注、增强)以及用于评估和监控 AI 模型的数据策略,其中的每一个环节都会影响最终 AI 模型的可信度。
图1:从数据设计到评估的以数据为中心的方法开发路线图。
设计应当是一个迭代过程——用试验数据来开发初始的 AI 模型,然后再收集额外数据来修补模型的局限性。设计的关键标准是确保数据适用于任务,并覆盖足够的范围来代表模型可能遇到的不同用户和场景。
而目前用于开发 AI 的数据集通常覆盖范围有限或者具有偏差。例如在医疗 AI 中,用于开发算法的患者数据的收集在地区分布上不成比例,这会限制 AI 模型对不同人群的适用性。
提高数据覆盖率的一种方法,是让更广泛的社区参与数据的创建。目前最大的公共数据集 Common Voice 项目就是一个例证,该数据集包含了来自 166000 多名参与者的 76 种语言的 11192 小时语音转录。
而当代表性数据难以获得时,可以用
来填补覆盖空白。比如真实人脸的收集通常涉及隐私问题和抽样偏差,而由深度生成模型创建的合成人脸现在已经被用于减轻数据不平衡和偏差。在医疗保健领域,可以共享合成医疗记录来促进知识发现,而无需披露实际的患者信息。在机器人技术中,真实世界的挑战是终极的测试平台,也可以用高保真模拟环境来让智能体在复杂和长期任务中实现更快、更安全的学习。
但合成数据也存在一些问题。合成数据与现实数据之间总是存在差距,所以在将基于合成数据训练的 AI 模型转移到现实世界时,通常会出现性能下降。如果模拟器的设计不考虑少数群体,那么合成数据也会加剧数据差异,而 AI 模型的性能高度依赖其训练和评估数据的上下文,因此在标准化和透明的报告中记录数据设计地上下文就非常重要。
现在,研究人员已经创建了各种
「数据营养标签」(data nutrition labels)来捕获有关数据设计和注释过程的元数据(metadata)。
元数据可以保存在一个专门的数据设计文档里,数据文档对于观察数据的生命周期和社会技术背景来说非常重要。文档可以上传到稳定且集中的数据存储库(例如 Zenodo)中。
初始数据集收集完成后,我们就需要进一步完善数据,为 AI 的开发提供更有效的数据。这是 AI 以模型为中心的方法与以数据为中心的方法的关键不同之处,如图 2a ,以模型为中心的研究通常是基于给定的数据,专注于改进模型架构或优化此数据。而
以数据为中心的研究则侧重于可扩展的方法,
通过数据清洗、筛选、标注、增强等过程来系统地改进数据,并且可以使用
一站式的模型开发平台。
图2a:AI 以模型为中心与以数据为中心的方法比较。MNIST、COCO 和 ImageNet 是 AI 研究中常用的数据集。
如果数据集的噪声很大,我们就得仔细对数据进行筛选之后再做训练,这样可以显著提高模型的可靠性和泛化性。图 2a 中的飞机图像就是鸟类数据集中应删除的噪声数据点。
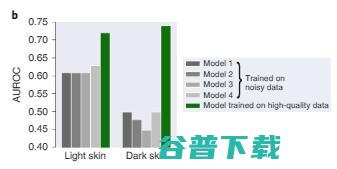
在 图 2b 中,由于训练数据的偏差,在以前使用的大型皮肤病学数据上训练的四种最先进的模型都表现不佳,在深色皮肤图像上的诊断效果尤其不好,而在较小的高质量数据上训练的模型 1 在深浅肤色上都相对更可靠一些。
图 2b:浅色皮肤和深色皮肤图像上的皮肤病诊断测试性能。
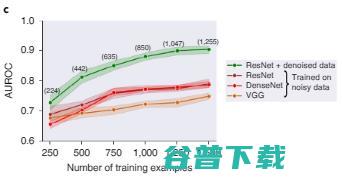
图 2c 显示,ResNet、DenseNet 和 VGG 这三种用于图像分类的流行深度学习架构,如果是在噪声大的图像数据集上进行训练,其性能都欠佳。而经过数据Shapley 值过滤后,质量较差的数据被删除,此时在更干净的数据子集上训练的ResNet模型性能显著更优。
图 2c:数据过滤前后不同模型的对象识别测试性能比较。括号中的数字表示过滤掉噪声数据后剩下的训练数据点的数量,结果汇总在五个随机种子上,阴影区域代表 95% 置信区间。
这就是数据评估的意义所在,它旨在量化不同数据的重要程度,并过滤掉可能由于质量差或偏差而损害模型性能的数据。
在本文中,作者介绍了两种数据评估方法来帮助清洗数据:
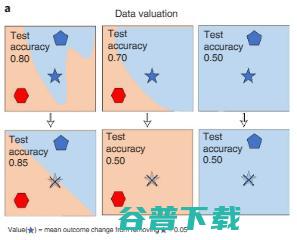
一种方法是测量在训练过程中删除不同数据时 AI 模型表现的变化,这可以采用数据的 Shapley 值或影响近似值来获得,如下图 3a。这种方法能够有效计算大型 AI 模型的评估。
另一种方法则是预测不确定性来检测质量差的数据点。数据点的人类注释可能会系统地偏离 AI 模型预测,置信学习算法可以检测出这些偏差,在 ImageNet 等常见基准测试中发现超过 3% 的测试数据被错误标注。过滤掉这些错误可以大大提升模型的性能。
数据标注也是数据偏差的一个主要来源。尽管 AI 模型可以容忍一定程度的随机标签噪声,但有偏差的错误会产生有偏差的模型。目前,我们主要依赖于人工标注,成本很昂贵,比如标注单个 LIDAR 扫描的成本可能超过 30 美元,因为它是三维数据,标注者需要绘制出三维边界框,比一般的标注任务要求更高。
因此作者认为,我们需要仔细校准 MTurk 等众包平台上的标注工具,提供一致的标注规则。在医疗环领域,还要考虑到标注人员可能需要专业知识或者可能有无法众包的敏感数据。
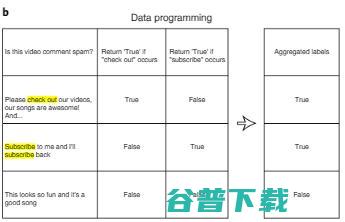
降低注释成本的一种方法是数据编程。
在数据编程中,AI 开发人员不再需要手动标记数据点,而是编写程序标签函数来自动标注训练集。如图 3b,使用用户定义的标签函数为每个输入自动生成多个可能有噪声的标签后,我们可以设计额外的算法,来聚合多个标签功能以减少噪声。
另一种降低标注成本的「人在回路」(human-in-the-loop)方法是
优先考虑最有价值的数据,
来进行标注。主动学习从最佳实验设计中汲取思想,在主动学习中,算法从一组未标注的数据点中选择信息量最大的点,比如具有高信息增益的点或模型在其上具有不确定性的点吗,然后再进行人工标注。这种方法的好处是,所需的数据数量比标准的监督学习所需的数据量要少得多。
最后,当现有数据仍十分有限时,
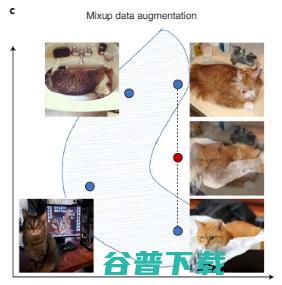
就是一种扩充数据集和提高模型可靠性的有效方法。
计算机视觉数据可以通过图像旋转、翻转和其他数字转换来增强,文本数据可以通过变换自动书写风格来增强。还有最近的 Mixup,是一种更复杂的增强技术,它通过对训练样本对进行插值来创建新的训练数据,如图 3c。
除了人工数据增强之外,目前的 AI 的自动化数据增强流程也是一种流行方案。此外,当未标注的数据可用时,还可以通过使用初始模型进行预测(这些预测称为伪标签)来实现标签增强,然后在具有真实和高置信度伪标签的组合数据上训练一个更大的模型。
在模型经过训练后,AI 评估的目标是模型的
通用性
和
可信性
。
为了实现这一目标,我们应该仔细设计评估数据,从而去找到模型的现实世界设置(real-world settings),同时评估数据也需要与模型的训练数据有足够大的差异。
举个例子,在医学研究中,AI 模型通常是基于少数医院的数据训练的。这样的模型在新的医院部署时,由于数据收集和处理方面的差异,其准确性就会降低。为了评价模型的泛化性,就需要从不同的医院、不同的数据处理管道收集评价数据。在其他应用程序中,评估数据应该从不同的来源收集,最好由不同的注释器标记为训练数据。同时,高质量的人类标签仍然是最重要的评价。
AI 评估的一个重要作用是,
判断 AI 模型是否在不能很好形成概念的训练数据中将虚假相关性作为「捷径」
。例如,在医学成像中,数据的处理方式(例如裁剪或图像压缩)可能产生模型拾取的虚假相关性(即捷径)。这些捷径表面上可能很有帮助,但当模型部署在稍有不同的环境中时,就可能会出现灾难性的失败。
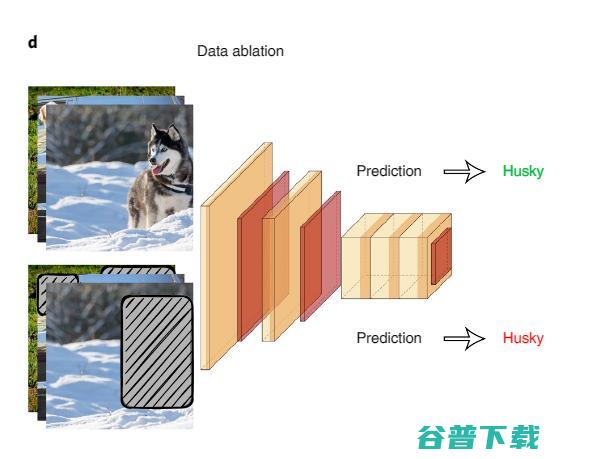
系统的数据消融是检查潜在的模型「捷径」的好方法。
在数据消融(data ablation)中,AI 模型在虚假相关表面信号的消融输入上进行训练和测试。
使用数据消融探测出模型捷径的一个例子是,一项关于常见自然语言推理数据集的研究发现,仅对文本输入的前一半进行训练的人工智能模型在推断文本的前一半和后一半之间的逻辑关系方面取得了很高的准确性,而人类在相同的输入上的推断水平和随机猜测差不多。这就表明人工智能模型利用虚假相关性作为完成这项任务的捷径。研究团队发现,特定的语言现象会被人工智能模型利用,如文本中的否定与标签高度相关。
数据消融被广泛适用于各个领域。例如,在医学领域,可以屏蔽图像中与生物相关的部分,用这种方式来评估人工智能是从虚假背景中学习,还是从图像质量的人工制品中学习。
AI 评估通常局限于比较整个测试数据集的总体性能指标。但即使 AI 模型在总体数据层面工作良好,它仍然可能在特定的数据子组上显示出系统性错误,而
对这些错误集群的特征描述可以让我们更加了解模型的局限性。
当元数据可用时,细粒度的评估方法应该尽可能地按数据集中参与者的性别、性别、种族和地理位置对评估数据进行切片——例如,“亚洲老年男性”或“美国土著女性”——并量化模型在每个数据子组上的表现。多精度审计(Multi-accuracy auditing)是一种自动搜索 AI 模型表现不佳的数据子组的算法。在此处,审计算法被训练来使用元数据预测和聚类原始模型的错误,然后提供 AI 模型犯了什么错,为什么会犯错等问题的可解释答案。
当元数据不可用时,Domino 等方法会自动识别评估模型容易出错的数据集群,并使用文本生成来创建这些模型错误的自然语言解释。
目前大多数 AI 研究项目只开发一次数据集,但现实世界的 AI 用户通常需要不断更新数据集和模型。
持续的数据开发将带来以下挑战:
数据和 AI 任务都可以随着时间的推移而变化
:例如,可能道路上出现了一种新的车辆模型(即领域转移),或者可能 AI 开发人员想要识别一种新的对象类别(例如,不同于普通公交车的校车类型),这就会改变标签的分类。而将扔掉数百万小时的旧标签数据十分浪费,所以更新势在必行。此外,培训和评估指标应该经过精心设计后用来权衡新数据,并为每个子任务使用适当的数据。
为了持续获取和使用数据,用户将需要自动化大部分以数据为中心的 AI 过程。
这种自动化包括使用算法来选择将哪些数据发送给标注器,以及如何使用它来重新训练模型,并且只在过程出现错误时(例如,准确度指标下降时)才向模型开发人员发出警报。作为“MLOps(Machine Learning Operations,机器学习操作)”趋势的一部分,业界公司开始使用工具来实现机器学习生命周期的自动化。
版权文章,未经授权禁止转载。详情见
转载须知
。






探索Apple的创新世界,选购各式iPhone、iPad、AppleWatch和Mac,浏览各类配件、娱乐产品,并获得相关产品的专家服务支持。

Teambition是阿里巴巴旗下团队协作工具,以项目和任务的可视化管理来支撑企业团队协作,适合产品、研发、设计、市场、运营、销售、HR等各类团队,让企业协同化繁为简,轻松愉悦。

问道8月9日开启经典联运年度大服“二〇二四”,八阶坐骑灵牙象、限定法功神兽小龙女、还有众多好礼助阵新服!

企业官网

大宏智能18年专注缠绕、码垛、捆扎、在线输送等后道包装,全自动后道包装流水线

自贡治疗癫痫病的医院,自贡较好的癫痫病专科医院,主要包括癫痫医院,癫痫治疗,癫痫常识,癫痫症状,康复情况等模块

哪里有培训网拥有上万名职业管理培训讲师,8万门企业内训课程,6000家培训机构,全年3000余次公开课培训计划,包括人事、生产、营销、财务、采购、研发等部门培训;找中国好讲师、培训机构、企业内训、报名培训班请到哪里有培训网(nlypx.com)

008导航(www.dx008.com)致力于打造国内最好的互联网上优质网站网址大全,收录了全网好用强大的网站网址和软件包括设计、开发、影视、人工智能、AI、运营、生活、休闲、办公、工具、资源等超全面的网址和职业技巧内容,让您的上网体验更便捷更放心,努力成为全民级人人都在用的网址导航。
")
无限设计隶属于杭州品宣电子商务有限公司,本公司与杭州石特广告策划有限公司深度合作,为企业提供品牌网站建设、品牌定位咨询、品牌设计(logo设计、vi设计、网络设计、包装设计等)、品牌策划与推广服务,以提升客户在海内外的品牌影响力。

糯米诗词网_为广大用户提供精准的唐诗,宋词,元曲,名人名言,励志名言,古诗等诗文、文章内容,是学习诗词的可靠平台。

中共西乌珠穆沁旗委员会组织部默认栏目

深圳合君普道科技有限公司,专业零售企业社区化会员精准营销解决方案供应商。作为大数据时代零售企业运营的基础,通过数据采集,数据运营,数据分析,为运营及分析提供更多参考依据!


随着生活环境以及学习和工作压力的影响,不少人会出现一起爆痘和长斑的问题,甚至会因此而产生自卑消极的心理,那么市场上有关于解决这些问题的品牌也是越来也多,无论是对于顾客还是选择创业加盟品牌的加盟商来说,品牌的口碑则是其选择的关键,资医堂品牌现代化技术结合传统的中医理论,温和的改善祛痘和淡斑,因此备受大众的信赖和选择,那么关于加盟资医堂条...。

每一位消费者在工作完之后回到家可以看到整洁干净的环境,但是由于上班没有时间来清洁家里卫生,在这个时候可以选择家政公司来解决这些问题,家政公司这几年在市场上得到很多消费者的追求,也吸引广大创业者的关注,洁家环净家政公司以专业的技术和贴心服务,让众多消费者十分安心选择,那么洁家环净家政怎么加盟,加盟要多少钱,洁家环净是国内的一家家政服务公...。

熟食吃起来非常的方便,买回来就可以吃,而且有荤有素,营养搭配均衡,非常适合现在人们的生活节奏,因此,该产品在市场上的销量非常好,市场需求量也很大,不管在哪座城市都有该项目的需求存在,很多餐饮创业者也就萌生了开一家店的想法,加盟是相对稳妥的创业模式,关于熟食品牌排行榜,是我们需要了解的内容,下面,就一起来看一下吧,一、山林熟食红肠、香肠...。

9月7日,2023腾讯数字生态大会智能制造专场现场,腾讯云和苏州市吴江区正式签署合作协议,双方将共建腾讯云工业互联网江苏总部基地,协助吴江创新产业集群建设,为吴江持续打响,工业互联网看吴江,品牌助力,腾讯云和苏州市吴江区正式签署合作协议2022年,吴江区实现地区生产总值2331.97亿元,发展势头良好,2023赛迪百强区,榜单吴江位...。

消息,新一代融合视觉传感器芯片公司锐思智芯宣布完成数亿元Pre,B轮融资,此前锐思智芯已经完成了数千万天使轮、近亿元Pre,A轮以及近两亿元A轮融资,近日完成的Pre,B轮融资由国投创业、元禾辰坤联合领投,联想创投、清科创投、谷雨嘉禾、同歌创投、中科先进产业基金、深圳天使母基金、讯飞创投、追远创投等老股东持续跟投,锐思智芯创始人...。

发表在其它家用投影仪品牌2024,1,2415,00懂影A8是一款价格和千元,属于三千价位这一档,那么懂影A8投影仪怎么样呢,下面就来了解懂影A8投影仪的详细参数配置,看看这款投影仪各方面的表现究竟如何,是否可以满足用户的日常使用需求,懂影A8投影仪怎么样,1.光学参数在亮度方面,懂影A8的亮度达到1800流明,整体亮度表现还算不错,...。

现代大健康的时代到来,人们越来越重视养生的生活方式,健康养生行业就是一个朝阳的行业,人口老龄化加快,这就为健康养生行业带来了机遇,现在市面上还出现很多连锁养生机构,其中彭世修脚就是个不错的品牌,品牌的实力雄厚,还拥有专业的团队和高标准的服务,获得很多消费者的追捧,很多网友就想要加入其中,那么,彭世修脚加盟有哪些优势,开店容易吗,彭世修...。

粉色劳斯莱斯女车主再次发声不须要大货车司机任何抵偿记者尹鑫尹鸣近日,广州海珠区一货车撞上一辆粤港两地牌照的劳斯莱斯引发继续关注,针对一些网友称此次车祸是剧本,存在摆拍的质疑,当事双方均启动了回应,但双方的回应并未消弭网友的质疑,关于此事的问号越来越多,11月11日,纵览资讯,报料微信,ZLXWBL2023,记者从广州海珠区交警大队了解...。

电脑上剪辑音乐,兼并音乐可以经常使用QVE音频剪辑软件,剪辑音乐步骤如下,1,关上软件,在剪辑界面点击,减少文件,按钮,选用音频文件,2,拖动两侧滑杆选用剪辑区域,点击剪辑按钮,保管红色区域片段,3,点击,导出,按钮,期待导出进展100%,点击更多操作,选用关上目录,检查剪辑后的文件,蓝光影音MP3剪切器V254收费版蓝光影音MP3剪...。

[联结国,#环球人口本世纪80年代将达103亿峰值#]#环球人口将在本世纪80年代达峰值#外地期间7月11日,联结国经济和社会事务部,经社部,颁布,环球人口展望2024,报告,报告预测,环球人口将在本世纪80年代到达约103亿的峰值,随先人口数量将会缓慢降低,在21世纪完结前回落至102亿人,对2100年人口数量的预测较10年前的预测...。

西风雪铁龙是雪铁龙汽车公司与中国西风汽车公司合资组建的汽车品牌,旗下领有一系列丰盛的车型,满足不同消费者的需求,这些车型包含c5、c6、c4l、爱丽舍、c3xr、c4世嘉等,每款车型都有其共同的特性和卖点,其中,全新越享初级轿车C6、第三代C5、全新C4L、C4世嘉、全新爱丽舍、C3,XR,以及出口车全新C4PICASSO等是西风雪铁...。

周公解梦网站源码,大型周易卜卦类网站源码,带独立手机版,文章类权重站,帝国内核周公解梦大全站,帝国cms内核做的周公解梦网站源码,百度权重7的站,移动站权重5,内容很好...周公解梦网站源码,大型周易卜卦类网站源码,带独立手机版,文章类权重站,帝国内核,源码屋论坛
前两天写了我做项目的坎坷历程,咨询的人太多,今天统一回复一下无非以下这三点,1、淘客项目真的可以月利润10W吗?2、这个项目怎么操作的?3、私域流量怎么玩?淘客项目真的可以月利润10W吗?针对这个问题,我回答了无数次,为什么不能呢?10W很多吗?我想直接拿数据说话,这是截止到9月2号的总数据,上次发文章配图是8月31号的数据,也就是说...。

昨天,,iBitch,一词火了起来,其释义为,不公平、忽略用户感受,创造者则是一众WP手机用户,在该词的背后,还有一场不可谓不轰烈的运动,事情的起因是支付宝钱包官微昨天发布微博称,支付宝已经完成适配AppleWatch版本的开发工作,中国用户在订购AppleWatch后,可以在第一时间用到最受欢迎的移动支付功能,而在目前的版本里,支付...。
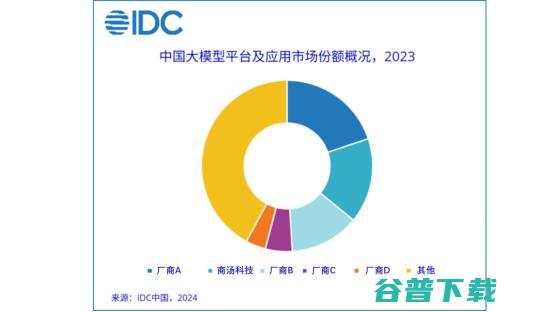
生成式AI落地应用加速跑,哪家厂商率先真正实现商业化,8月21日,国际数据公司IDC首发,中国大模型平台市场份额,2023,大模型元年——初局,,根据2023年数据显示,商汤科技以16%市场份额,领先国内诸多大模型厂商,占据前二位置,在生成式AI爆发的关键节点,商汤率先完成业务转型、占领先机,报告指出,商汤科技之所以能在中国大模型市场...。

对于选择强迫症来说,走进餐厅,最纠结的莫过于看着菜单上琳琅满目的菜名不知道该选择什么,虽然有的菜单上会配以图片介绍,但是那些照片总是仿佛自带柔光滤镜,然而端上来却完全不是那么回事儿,对于吃货来说这绝对不能忍!现在,也许机器人和增强现实将会帮你避免这种麻烦,至少,这是PeppARWaiter给我们展示的一个未来,上周末,在旧金山举办的T...。

区域性乳企的内忧外患液态奶的江湖里,多数人只听说过蒙牛、伊利等少数几个巨头的名号,但这个世界里的高手远比你想象得多,普通消费者或许并不清楚,液态奶市场其实分为常温奶和低温奶两大阵营,蒙牛和伊利的统治力仅仅局限于前者,常温奶经过超高温杀菌,可以长时间保存,因此能够行销全国,培育出蒙牛、伊利这样的巨无霸企业,而低温奶采用巴氏杀菌法,保留了...。
