AI时代的摩尔定律 黄氏定律预测AI性能将逐年翻倍 (ai时代的摩尔定律)
1965年,时任仙童半导体公司工程师,也是后来英特尔的创始人之一的戈登·摩尔(Gordon Moore)提出了摩尔定律(Moore's law),预测集成电路上可以容纳的晶体管数目大约每经过24个月便会增加一倍。
后来广为人知的每18个月芯片性能将提高一倍的说法是由英特尔CEO大卫·豪斯(David House)提出。过去的半个多世纪,半导体行业按照摩尔定律发展,并驱动了一系列的科技创新。
有意思的是,在摩尔定律放缓的当下, 以全球另一大芯片公司英伟达(NVIDIA)创始黄仁勋(Jensen Huang)名字命名的定律“黄氏定律 (Huang’s Law)”对AI性能的提升作出预测,预测gpu将推动AI性能实现逐年翻倍。
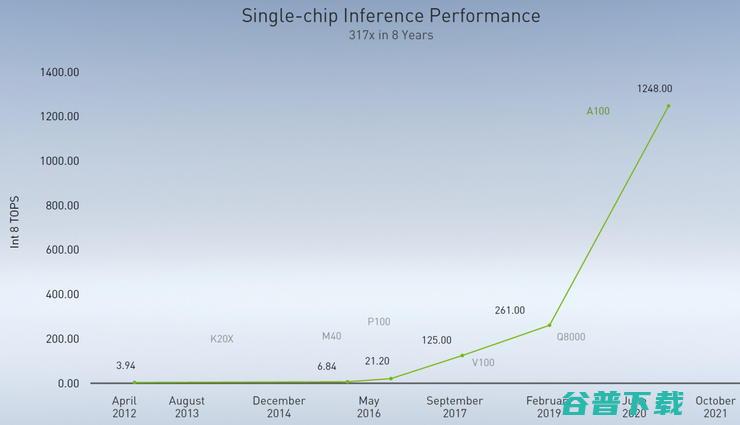
英伟达GPU助推AI推理性能每年提升一倍以上
英特尔提出了摩尔定律,也是过去几十年最成功的芯片公司之一。英伟达作为当下最炙手可热的AI芯片公司之一,提出黄氏定律是否也意味着其将引领未来几十年芯片行业的发展?
受疫情影响,一年一度展示英伟达最新技术、产品和中国合作伙伴成果的GTC China改为线上举行,黄仁勋缺席今年的主题演讲,由英伟达首席科学家兼研究院副总裁Bill Dally进行分享。Bill Dally是全球著名的计算机科学家,拥有120多项专利,在2009年加入英伟达之前,曾任斯坦福大学计算机科学系主任。加入英伟达之后,Dally曾负责英伟达在AI、光线追踪和高速互连领域的相关研究。

英伟达首席科学家兼研究院副总裁Bill Dally
雷锋网消息,在今天GTC China 2020演讲中,Dally称:“如果我们真想提高计算机性能,黄氏定律就是一项重要指标,且在可预见的未来都将一直适用。”
Dally用三个项目说明黄氏定律将如何得以实现。首先是为了实现超高能效加速器的MAGNet工具。 英伟达称,MAGNet生成的AI推理加速器在模拟测试中,能够达到每瓦 100 tera ops 的推理能力,比目前的商用芯片高出一个数量级。
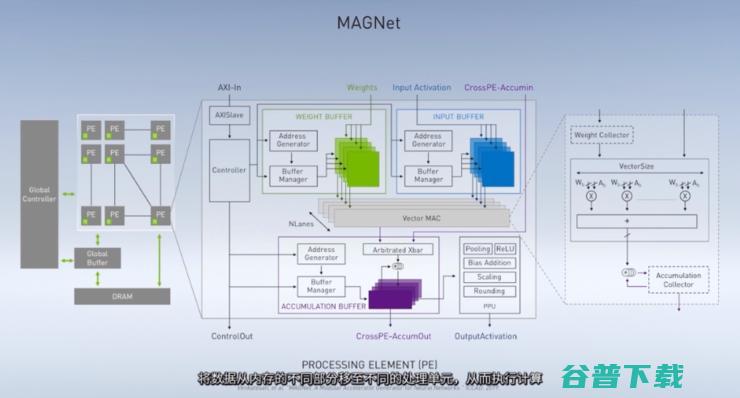
之所以能够实现数量级的性能提升,主要是因为MAGNet采用了一系列新技术来协调并控制通过设备的信息流,最大限度地减少数据传输。数据搬运是AI芯片最耗能的环节已经是当今业界的共识,这一研究模型以模组化实现能够实现灵活扩展。

Dally带领的200人的研究团队的另一个研究项目目标是以更快速的光链路取代现有系统内的电气链路。Dally说:“我们可以将连接GPU的NVLink速度提高一倍,也许还会再翻番,但电信号最终会消耗殆尽。”
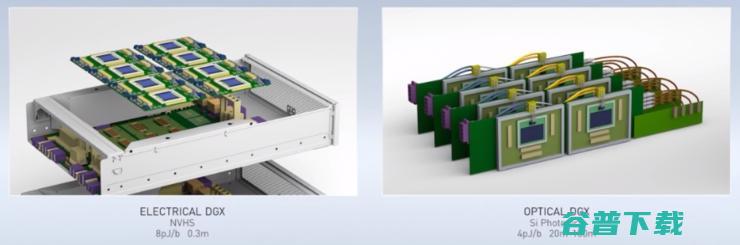

这个项目是英伟达与哥伦比亚大学的研究团队合作,探讨如何利用电信供应商在其核心网络中所采用的技术,通过一条光纤来传输数十路信号。 据悉,这种名为“密集波分复用”的技术, 有望在仅一毫米大小的芯片上实现Tb/s级数据的传输,是如今互连密度的十倍以上。


Dally在演讲中举例展示了一个未来将搭载160多个GPU的NVIDIA DGX系统模型。这意味着,利用“密集波分复用”技术,不仅可以实现更大的吞吐量,光链路也有助于打造更为密集的系统。
想要发挥光链路的全部潜能,还需要相应的软件,这也是Dally分享的第三个项目——全新编程系统原型Legate。 Legate将一种新的编程速记融入了加速软件库和高级运行时环境Legion,借助Legate,开发者可在任何规模的系统上运行针对单一GPU编写的程序——甚至适用于诸如 Selene等搭载数千个GPU的巨型超级计算机。
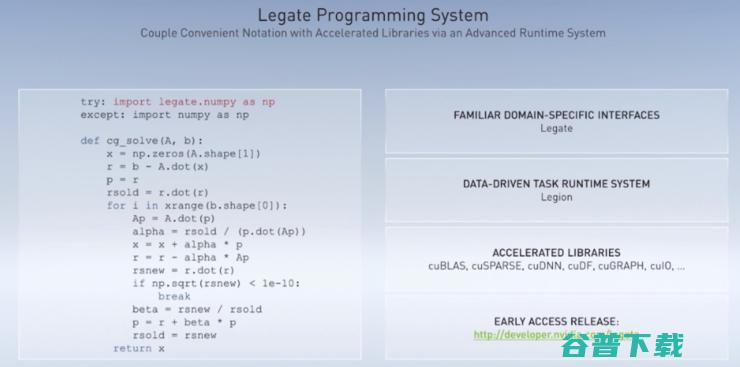
Dally称Legate正在美国国家实验室接受测试。
MAGNet、以光链路取代现有系统内的电气链路以及Legate是成功实现黄氏定律的关键,但GPU的成功才是基础。因此,GPU当下的成功以及未来的演进都尤其重要。
今年5月,英伟达发布了面积高达826平方毫米,集成了540亿个晶体管的7nm全新安培(Ampere)架构GPU A100。相比Volta 架构的GPU能够实现20倍的性能提升,并可以同时满足AI训练和推理的需求。
凭借更高精度的第三代Tensor Core核心,A100 GPU AI性能相比上一代有明显提升, 雷锋网此前报道 ,在7月的第三个版本MLPerf Training v0.7基准测试(Benchmark)结果中,英伟达的DGX SuperPOD系统在性能上开创了八个全新里程碑,共打破16项纪录。
另外,在10月出炉的MLPerf Inference v0.7结果中,A100 Tensor Core GPU在云端推理的基准测试性能是最先进英特尔CPU的237倍。
更强大的A100 GPU迅速被多个大客户采用,迄今为止,阿里云、百度智能云、滴滴云、腾讯云等众多中国云服务提供商推出搭载了英伟达A100的多款云服务及GPU实例,包括图像识别、语音识别,以及计算流体动力学、计算金融学、分子动力学等快速增长的高性能计算场景。

另外,新华三、浪潮、联想、宁畅等系统制造商等也选择了最新发布的A100 PCIe版本以及英伟达 A100 80GB GPU,为超大数据中心提供兼具超强性能与灵活的AI加速系统。
Dally在演讲中提到:“经过几代人的努力,NVIDIA的产品将通过基于物理渲染的路径追踪技术,实时生成令人惊艳的图像,并能够借助AI构建整个场景。”
与光链路取代现有系统内的电气链路需要软硬件的匹配一样,英伟达GPU软硬件的结合才能应对更多AI应用场景苛刻的挑战。
Dally在此次的GTC China上首次公开展示了英伟达对话式AI框架Jarvis与GauGAN的组合。GauGAN利用生成式对抗网络,只需简略构图,就能创建美丽的风景图。展示中,用户可通过语音指令,即时生成像照片一样栩栩如生的画作。
GPU是黄氏定律的基础,而能否实现并延续黄氏定律,仅靠少数的大公司显然不够,还需要众多的合作伙伴激发对AI算力的需求和更多创新。
英伟达已经在构建AI生态,并在GTC China上展示了英伟达初创加速计划从100多家AI初创公司中脱颖而出的12家公司,这些公司涵盖会话人工智能、智慧医疗/零售、消费者互联网/行业应用、深度学习应用/加速数据科学、自主机器/IOT/工业制造、自动驾驶汽车。
智能语音正在改变我们的生活。会话人工智能的深思维提供的是离线智能语音解决方案,在占有很少空间的前提下实现智能交互,语音合成和语音识别保证毫秒级响应。深声科技基于英伟达的产品研发高质量中英文语音合成、声音定制、声音克隆等语音AI技术。
对于行业应用而言,星云Clustar利用英伟达GPU和DGX工作站,能够大幅提升模型预测精确度以及解决方案处理性能,让传统行业的AI升级成本更低、效率更高。
摩尔定律的成功带来了新的时代,黄氏定律能否成功仍需时间给我们答案。但这一定律的提出对AI性能的提升给出了明确的预测,并且英伟达正在通过硬件、软件的提升和创新,努力实现黄氏定律,同时借生态的打造想要更深远的影响AI发展。
黄氏定律值得我们期待。
英伟达A100 GPU推理性能最高达CPU的237倍!临界点到来?
打破16项AI性能记录!英伟达A100 GPU要无人能敌?
黄仁勋烤箱里端出全球最大7nm芯片!英伟达第八代安培GPU A100发布,AI算力提升20倍,号称史上最大性能飞跃
原创文章,未经授权禁止转载。详情见 转载须知 。


找线报_活动线报,薅羊毛优惠活动分享,套路王实时更新20点试用部分人有5券,到手2.41分钱微信打开下拉点图火车出行可领20元话费小程序工银上海银证存管随便开个证卷银行卡绑工行(限上e卡秒到【什么值得买】特邀参与老用户调研,完成可领取5元京东1000-5.18红包7天套券070009不限实名泰康0.3电视TV。apk,有需要的进6点支付宝搜支付有礼领1.680.50.2网易云周卡2.66元zfb纸巾您有一份红包待领取淘宝抽奖有水支付宝5.18大毛招行2元立减金工行1元立减金两个2元立减金!!!!!!!!!!!!!!!来试试0.01元,垃圾袋13.66,吉香居暴下饭礼盒下放酱200g*1元,麦当劳冰淇淋交通银行2元贴金券立白浓缩洗衣凝珠34颗持久留香微信公众号,创维光伏,助力已满,号多的冲
中国官方网站")
深圳市浩太科技有限公司

拥有全国各地上千万家企业信息,找企业信息就到黄页网。目前网站服务免费,并支持动态发布,实时更新,现在加入免费得到首页推荐,每天十万次的显示机会让给你。

皇博轩源于中国传统文化高品质家居品牌,中国生产基地坐落于中国家具之都——佛山顺德,是集设计、研发、生产、销售、服务为一体的现代化家具制造商。旗下圣御皇博轩品牌,涵盖三大系列包含圣御·皇博轩现代客厅系列、博奥帝豪·米兰极简系列、欧拉德智慧睡眠系列,主张原创设计、时尚、潮流,致力于打造健康、高颜值的家居生活。

专业从事电路板拆解,重金属回收,电器拆解,荧光粉以及pcb线路板的生产和销售,欢迎来电咨询

想学习玉石知识?不知从何入手?玉品多提供了翡翠玉石的基础知识介绍,让你全面了解玉石的种类、颜色、质地、纹理、鉴别等知识点,助你更好地选择和欣赏玉石。

【扬中市远东轴承专用油石厂】是专业生产油石、超精油石的企业,提供油石规格,油石价格,白刚玉油石,金刚石油石等.

易运盘是专业研究周易、八字、生肖、星座、姓名学等传统神秘文化的著名站点,易运盘提供最全面、最准确的周易算卦、八字算命、姓名测试打分、称骨算命、免费取名、生肖运程、在线抽签、号码吉凶、星座运程等专业周易预测及民俗占卜等在线测试。

网商汇为你提供机械,五金,化工,塑料,电子电气,电工,仪器仪表,安防,纺织,包装,鞋包服饰,维修,家政,商务服务等分类信息,帮助中小企业运用互联网销售产品,网上营销,降低采购及广告投放成本,并提高企业核心竞争力,找客户、发信息就来网商汇。

「广东智子」专注称重配料系统,自动配料系统,粉体气力输送,混料系统,粉体输送,气力输送系统,气力输送设备,吨袋包装机,无尘投料站,电解液供料系统,注液机供液系统;等物料处理工序自动化。全方位液体,气体,粉料正压输送,负压输送!

战旗游戏直播平台提供高清、流畅的视频直播和电子竞技游戏直播。包括三国杀直播、LOL英雄联盟直播、炉石传说直播、dota2直播等各类热门游戏赛事。战旗直播为您提供全新的游戏视觉与听觉体验。
")
作为国内领先的全场景导购平台,返利网注册用户超2.4亿,与国内400多家商城平台、逾5万家商户合作,覆盖逾百万线下门店,涵盖购物、旅行、票务、学习等消费场景。


最近,川建国着实有点惨,10月30日,据路透社报道,在美国总统大选即将进入最后时刻之际,德国柏林的杜莎夫人蜡像馆把美国总统特朗普的蜡像扔进了,废品箱,连带着特朗普的口头禅,你被开除了,、,假新闻,和标志性红帽子也一起被打包扔掉,对于这个造型特殊的陈列,蜡像馆负责人在回应中对特朗普的选情显得非常不看好,这个陈设是关于美国大选的一个象...。

在被疫情长期笼罩的2020年,医疗成为了全球资本与技术市场最关注的领域,把,不作恶,作为公司行事原则的Google,也被业内寄予了将改变医疗科技旧貌的厚望,在这其中,Google2020年的医疗业务可圈可点,在多个方面展示出它不俗的技术实力和社会服务能力,与此同时也饱受多方争议,以下为HealthCareITNews发布的Google...。

包子早餐店在人们生活中需求很大,也离不开,现在很多创业者也想开包子铺,满足大家用餐需求,市场有名气的品牌比较多,其中,李与白包子铺经营很有特色,让顾客吃的满意,李与白包子铺加盟费大概多少,作为加盟商也需要了解一下所需要的费用问题,李与白包子铺公司拥有十多年的餐饮店运营经验,从成立以来就能打造有特色的餐饮品牌,建立了一支有实力,有想法的...。

12月11日,泡泡玛特,上市首日收涨79.22%,股价开盘翻倍,市值超1100亿港元,这背后得益于三个因素,年轻人、IP以及盲盒,泡泡玛特以年轻化产品以及表达方式,获得了年轻人的关注和喜爱,并成功出圈,范围扩大至新消费市场,近年来,随着消费场景及内外部环境的转变,,年轻化,成为各大品牌绕不开的话题,大家都在寻求更符合当代用户习惯的产...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

经常使用btdigg搜查引擎的步骤如下,首先,关上btdigg搜查引擎的官网网站,在阅读器的地址栏中输入btdigg的网址,而后按下回车键,即可进入btdigg的首页,其次,在btdigg的首页中,你会看到一个搜查框,在搜查框中输入你想要搜查的内容,例如电影、电视剧、音乐、游戏等的称号或关键词,输入终了后,点击搜查框旁边的,搜查,按钮...。

苹果手机收费视频软件有追剧影视大全、影视大全污浊版、番茄影视大全、难看影视大全、南瓜影视大全、好猫影视,1、追剧影视大全追剧影视大全是一款集结了当下热播的综艺剧情,人气动漫以及海外外低劣电影的运行软件,这些电影资源都是追随着实时降级的,用户们可以当先收费看,2、影视大全污浊版影视大全污浊版这款运行就和它的名字一样没有任何的广告,全网聚...。

斯柯达明锐作为一款遭到关注的车型,虽然在某些方面具有好处,但在实践经常使用环节中也存在一些不尽善尽美的中央,上方咱们将从多个维度登程,主观剖析斯柯达明锐的潜在无余,以便为消费者提供更片面的购车参考,一、油耗体现不够理想与同级别车型相比,斯柯达明锐的油耗偏高,这或者会参与日经常常使用老本,关于器重经济性的消费者来说须要审慎思考,二、噪音...。

乔治巴顿越野车是由英国汽车厂USSV打造出的一款集重型坦克和越野车为一体的超重型越野车,为何一款越野车领有姓名,乔冶·阿诗丹顿·巴顿是二战中驰名的美国军队四星上将,人叫,铁胆小将,,在纪念乔冶·巴顿将军华诞120周年纪念之时,巴顿将军的小孙女要想一辆具备战役精气且无坚不摧的十分越野车来纪念自身的爷爷,而USSV便构建了那么一款十分越野...。

思考到有些用户不太了解2021款埃尔法这款车,所以小编此处就选取埃尔法的2021款双擎2.5L尊贵版为例,并带大家经过以下几点来意识2021款埃尔法这款车,一、多少钱方面由下表来看,埃尔法的2021款双擎2.5L尊贵版全款需98.26万,其中包含500元上牌费、900元车船税、元置办税、1100元交强险和元商业险,车型称号2021款双...。

我给大家介绍几款收费看电视剧软件,1、今天影视,今天影视领有丰盛的剧集资源,笼罩了国际外的抢手精品资源,2、腾讯视频,腾讯视频是一款领有海量收费视频资源的软件,包含电影、电视剧、综艺、动漫等外容,3、优酷视频,优酷视频是一款十分好用的收费看电视剧软件,用户可以收费观看高清流利的电视剧、电影等,4、西瓜视频西瓜视频是一款由字节跳动开发的...。

NeeviaDocumentConverterPro是一款文档格式转换器,可以动态地转换MicrosoftOffice2000/XP,Office97,WordPerfect,HTML,Postscript和许多其他格式地文档为

由中国中文信息学会社会媒体处理专委会主办、哈尔滨工业大学承办的第七届全国社会媒体处理大会,SMP2018,于2018年8月2日,4日在哈尔滨召开,雷锋网作为独家战略媒体带来合作报道,SMP专注于以社会媒体处理为主题的科学研究与工程开发,为传播社会媒体处理最新的学术研究与技术成果提供广泛的交流平台,旨在构建社会媒体处理领域的产学研生态圈...。

发表在米家投影仪2021,7,611,28米家投影仪内置了智能系统,拥有不错的性能配置,支持连接手机进行投屏操作,具体米家投影仪怎么连接手机呢,下面就分享详细的操作方法,看看有哪些方法可以连接米家投影仪,一、准备工作1.米家投影仪一台;2.智能手机一部,二、米家投影仪怎么连接手机方法一,1、将米家投影仪和手机连接到同一无线网络环境中;...。

火锅是大家比较喜欢吃的美食,吃起来特别方便,而且口感也各有特色,能够让更多顾客满意,在市场上的发展空间也越来越大,聚龙火锅能够让自己的美食顾客好评不断,在市场出现以后,也能让创业者更加满意,聚龙火锅加盟费多少,大家开店之后要准备齐全费用,聚龙火锅加盟以后大概加盟费就要准备十万元左右,公司能够把火锅美食做的让更多顾客满意,一直以来,提供...。

零食产品在人们的生活中扮演非常重要的角色,不仅能够帮助消费者解决嘴馋的问题,也能够帮助人们解决饥饿的问题,在市场上具有较高的需求量,小新很忙零食是行业中名气较高的品牌,在研发方面的实力比较强大,向市场上推出高质量的零食产品,符合当下消费者的饮食标准,与此同时,也吸引到一些创业者的关注,大家想要了解小新很忙零食的发展顺利吗,店内商品多吗...。

这个疑问我会,虽然自己英语书面语不是很好,然而对英语四六级词汇还是很相熟的~给大家总结了一个表格可以先粗略看一下,含意,1、extraordinary英[ɪkˈstrɔːdnri],美[ɪkˈstrɔːrdəneri]英式发音和美式发音是不一样的adj.不同凡响的,令人惊奇的,特殊的,出色的,特意的,暂时的,特大,或多,的,特派的,...。
