神经网络压缩与加速竞赛双项冠军技术解读 2019 NeurIPS (神经网络压缩算法)
雷锋网AI开发者讯,日前,神经信息处理系统大会(NeurIPS 2019)于12月8日至14日在加拿大温哥华举行,中国科学院自动化研究所及其南京人工智能芯片创新研究院联合团队在本次大会的神经网络压缩与加速竞赛(MicroNet Challenge)中获得双料冠军!
以模型压缩和加速为代表的深度学习计算优化技术是近几年学术界和工业界最为关注的焦点之一。随着人工智能技术不断地落地到各个应用场景中,在终端上部署深度学习方案面临了新的挑战:模型越来越复杂、参量越来越多,但终端的算力、功耗和内存受限,如何才能得到适用于终端的性能高、速度快的模型?
由Google、Facebook、openAI等机构在NeurIPS2019上共同主办的MicroNet Challenge竞赛旨在通过优化神经网络架构和计算,达到模型精度、计算效率、和硬件资源占用等方面的平衡,实现软硬件协同优化发展,启发新一代硬件架构设计和神经网络架构设计等。
MicroNet Challenge竞赛对于人工智能软件、硬件的未来发展都有着非比寻常的意义,此次不仅集结了MIT、加州大学、KAIST、华盛顿大学、京都大学、浙大、北航等国内外著名前沿科研院校,同时还吸引了ARM、IBM、高通、Xilinx等国际一流芯片公司的参与。
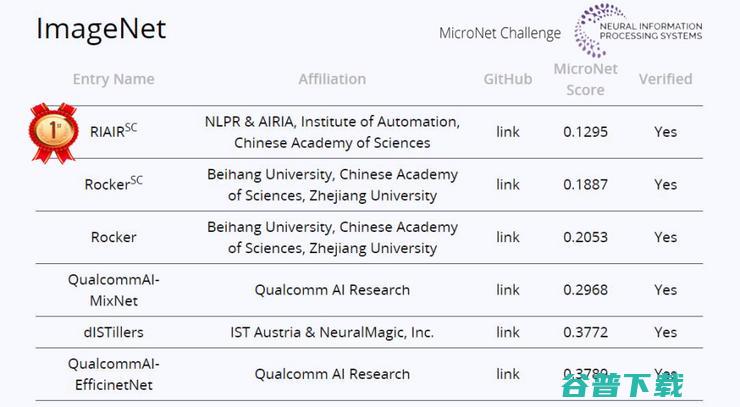
MicroNet Challenge竞赛包括ImageNet图像分类、CIFAR-100图像分类和WikiText-103语言模型三个子任务。来自自动化所程健研究员实验室的团队参加了竞争最激烈的ImageNet和CIFAR-100两个子赛道的比拼。历经五个多月的厮杀,团队一举包揽了图像类的全部两项冠军。
团队结合极低比特量化技术和稀疏化技术,在ImageNet任务上相比主办方提供的基准模型取得了20.2倍的压缩率和12.5倍的加速比,在CIFAR-100任务上取得了732.6倍的压缩率和356.5倍的加速比,遥遥领先两个任务中的第二名队伍。

同时,受组织方的邀请,团队在大会以“A Comprehensive Studyof Network Compression for Image Classification”为主题详细介绍了相关的量化和稀疏化压缩和加速技术。

针对比赛任务,团队在报告中给出解决办法:采用量化和稀疏化技术,将深度学习算法模型进行轻量化和计算提速,以大幅降低算法模型对算力、功耗以及内存的需求,让低端设备实现人工智能方案。团队成员冷聪副研究员表示,量化及稀疏化技术也是深度学习软、硬件协同加速方案的突破口。通过将其与人工智能硬件架构设计紧密结合,可以进一步降低人工智能技术落地难度,让AI更为易得易用。
NeruIPS 2019 MicroNet Challenge神经网络压缩与加速竞赛双项冠军技术解读
赛题介绍
本比赛总共包括三个赛道:ImageNet分类、CIFAR-100分类、WikiText-103语言模型。在三个赛道上,参赛团队要求构建轻量级网络,在精度满足官方要求的条件下,尽可能降低网络计算量和存储。对于ImageNet分类,要求至少达到75%的top-1精度,而对于CIFAR-100,top-1精度需要达到80%以上。
评测指标
最终评分指标包括存储压缩和计算量压缩两部分,均采用理论计算量和存储进行计算。
对于存储,所有在推理阶段需要使用的参数均需要计算在内,比如稀疏化中的mask、量化中的字典、尺度因子等。对于存储,32比特位算作一个参数,低于32比特的数按照比例计算,例如8比特数算作1/4个参数。
对于计算量,乘法计算量和加法计算量分别计算。对于稀疏而言,稀疏的位置可以认为计算量为0。对于定点量化,32比特操作算作一个操作,低于32比特的操作按照比例计算。操作的比特数认为是两个输入操作数中较大的那一个,例如一个3比特数和一个5比特数进行计算,输出为7比特数,那么该操作数为5/32。
对于ImageNet,以MobileNet-V2-1.4作为基准(6.9M参数,1170M计算量,精度大约为75%)。所以,如果参数量记为Param,计算量记为Operation,则最终评分Score为:

对于CIFAR-100,以WideResNet-29-10为基准(36.5M参数,10.49B计算量,精度大约为80%),评分公式为:

解决方案
我们主要采用稀疏化+量化的方式,主要包括模型选择、网络剪枝、定点量化、算子融合等操作,实现大规模稀疏和极低比特压缩。
首先是模型选择,复杂的模型往往具有更高的精度,参数量和计算量较大,但同时压缩空间也比较大;轻量级模型精度相对较低,但参数量和计算量相对较小,同时对网络压缩也比较敏感,因此需要再模型复杂度和精度之前进行权衡。我们选择轻量级、同时精度略高于比赛要求的网络。最终在ImageNet上选择了MixNet-S模型(精度75.98%),在CIFAR-100上选择了DenseNet-100(精度81.1%)。
在确定好模型之后,我们先对网络进行剪枝,去掉不重要的参数量和计算。在这之前,我们对每一层进行了鲁棒性分析。具体而言,对于每一层,我们进行稀疏度从0.1到0.9的剪枝,然后测试网络精度。图1显示了网络各层对不同稀疏度的影响,可以看出某几层对网络剪枝特别敏感,而其余一些层对剪枝却很鲁邦。基于此,我们确定了每一层的稀疏度,然后删除不重要的节点,再对剩余连接进行重新训练。我们可以实现在稀疏度大概为60%的情况下,精度损失只有0.4%。
 图1 网络各层对剪枝操作的鲁棒性分析
图1 网络各层对剪枝操作的鲁棒性分析
在对网络进行剪枝以后,再对网络进行定点量化。我们采用了均匀量化策略,量化公式如下:

对于激活,每层引入一个浮点数尺度因子;而对于权值,每个3D卷积核引入一个浮点数尺度因子。在给定比特数的情况下,以上优化公式唯一的待求解参数就是尺度因子,即优化目标为
 ,我们采用迭代优化的方式计算出每一层的尺度因子。在求解尺度因子之后,与网络剪枝类似,我们需要对网络进行微调来恢复精度,在网络微调阶段,我们保持尺度因子一直不变。通过以上方式,我们可以实现在激活7比特,参数大部分为3、4、5比特的情况下,网络精度损失为0.5个点,最终网络模型top-1精度为75.05%。
,我们采用迭代优化的方式计算出每一层的尺度因子。在求解尺度因子之后,与网络剪枝类似,我们需要对网络进行微调来恢复精度,在网络微调阶段,我们保持尺度因子一直不变。通过以上方式,我们可以实现在激活7比特,参数大部分为3、4、5比特的情况下,网络精度损失为0.5个点,最终网络模型top-1精度为75.05%。
最后,我们进行了算子融合,把量化中的尺度因子、卷积层偏置、BN层参数等融合成一个Scale层,以进一步降低网络的存储和计算量。最终,我们的方法在ImageNet上只有0.34M参数和93.7M计算量,相对于基准模型实现20.2倍的压缩和12.5倍的加速;而在CIFAR-100上,我们的模型存储仅有49.8K,计算量为29.4M,相对于基准模型压缩732.6倍,加速365.5倍。
雷锋网AI开发者
原创文章,未经授权禁止转载。详情见 转载须知 。



腾讯视频致力于打造中国领先的在线视频媒体平台,以丰富的内容、极致的观看体验、便捷的登录方式、多平台无缝应用体验以及快捷分享的产品特性,主要满足用户在线观看视频的需求。

百搜视频搜索是业界领先的中文视频搜索引擎之一,拥有海量的中文视频资源,提供用户满意的观看体验。在百搜视频,您可以便捷地找到海量的互联网视频,更有丰富的视频榜单、多样的视频专题满足您不同的视频观看需求。百搜视频,你的视界。

广州吉盛伟邦

北京天文馆坐落于北京市西城区西直门外大街138号,占地面积20,000平方米,建筑面积26,000平方米,于1957年正式对外开放,是我国第一座大型天文馆,也是当时亚洲大陆第一座大型天文馆。五十多年来,北京天文馆以其独特的演示手段,吸引了一代又一代的观众。现为国家AAAA级旅游景区。

中国产业经济信息网由中宣部主管、人民日报社代管的中国报业协会主办,成立于1997年,经国务院新闻办批准,首批获得国家级网络新闻媒体资格,并承担着为中国产业经济发展提供政策分析及资讯传播的责任和使命。

今日焦点——携手推动地方经济健康快速发展

泰隆盛世文化产业集团以品牌定位战略为先导,运用整合传播策略,融合“线上+线下”生活圈主流媒体加油站广告、数字化营销等,专注为客户提供品牌营销策划传播解决方案的互联网科技创新企业。


飞克机器人维修公司专业维修保养FANUC发那科、ABB、YASKAWA安川、KUKA库卡、川崎等市面常见的工业机器人。能够高效高质地维修各大品牌工业机器人的控制器、示教器、I/O板、驱动器、伺服电机、计算机板、电源板、安全电路板等所出现的各种故障。

成都坤舆空间科技有限公司是新时期,立足于新领域,以“时空大数据+”为引领的高科技信息产业发展公司。公司主要围绕区域规划、规划设计、项目实施,到运维管理为主线展开四大业务板块,开展主营业务。

洛阳市龙腾鼓厂主营产品:寺庙鼓,红鼓,腰鼓,传统民族鼓、特大战鼓、威风锣鼓、线雕龙鼓、浮雕龙鼓、彩绘鼓、绘龙鼓、红漆堂鼓、排鼓、腰鼓、太鼓、特型鼓(扇鼓,八角鼓、花盆鼓)、原木色高音战鼓及相关配件等,咨询电话18238889289.

消防维修网【www.119wei.com】专业消防维修工程人员进行维修,多年从业经验,可以维修多个厂商的消防主机问题。消防主机维修电话:4000-346--119.


说到家纺和床上用品大家都比较的熟悉了,作为人们家居生活必备的物品,国内的家纺行业发展规模巨大而且产品的市场需求量丰富,在国内诸多地区都有着很多的家纺城,里面有着诸多的家纺品牌受到了大家的青睐,要说品牌家纺想必很多人都会联想到罗莱家纺,罗莱家纺作为国内的明星品牌,在国内有着超过二十多年的品牌发展历程,在线上、线下等多种渠道都有着出色的发...。
认证可以让人信任,对于品牌来说十分重要!现在腾讯云已经推出了安全认证,使用十分的方便,但是,前提需要加入托管使用腾讯云服务器作为网站服务器即可,腾讯认证申请方法十分简单,1.使用腾讯云服务器作为网站运行托管,2.登录腾讯云官方网站,输入QQ账号密码即可,然后打开https,www.qcloud.com,product,sc,点...。

金刚狼,Wolverine,原名詹姆斯·豪利特,JamesHowlett,耐毁,别名罗根,Logan,等,身高5英尺3英寸,1.6米,,植入艾德曼金属骨架前体重195磅,88公斤,,植入艾德曼金属骨架后300磅,136公斤,金刚狼拥有超敏锐的感官能力,听力和目视距离远大于常人,他也能够通过气味追踪敌人,金刚狼也拥有超强的自愈能力,毒...。

动漫、二次元、手办……一系列词汇,不知何时开始就成了席卷现代年轻人的新的、独特文化,由此衍生出来的以动漫城、动漫实体店为代表的动漫产业,也成为行业重要产业之一,对创业者而言,关注的往往是行业动态,比如说开动漫城要多少钱,开个动漫实体店好吗,关于这类问题的答案,我们来细细叙说,有关动漫城的定义动漫,即动画、漫画的合称,指动画与漫画的集合...。

一、强化国内治理,为中国引领新型全球化奠定坚实的国内基础,中国致力于提升国家治理能力,实现市场、政府和社会三者的良性互动,增强国家的软硬实力,从而更好地参与全球治理,特别是在理念供给、政策执行、理论研究和人才培养等方面,中国加强能力建设,以改变全球化过程中的失衡与不公,获得国际社会的广泛共鸣,二、凝聚政治共识,纠正对全球化的错误认知,...。

该机构虚伪宣传,诱导生产,诈骗生产者,我原本预定好了只是体验了一下19.9的活动名目,做完前面他们把我叫到他们主任办公室,对我启动洗脑式采购,诱导我操持网贷分期做他们的其余名目,没做几次,对方又说我的脸暗沉须要修复,又让我操持了一个存款,并将之前的分期兼并,然而做了对方的名目后却并无显著效成果,因此提出解约,该机构违犯了,生产者权益包...。

央视网信息,作为中孟两国,一带一路,框架下的关键协作名目,由中国中铁承建的孟加拉国帕德玛大桥铁路衔接线名目标树立将在往年片面收官,这条线路北起首都达卡,超越帕德玛河一路向南加长至杰索尔,被外地人称为,幻想之路,终究这条线路为孟加拉国人成功了什么幻想呢,跟咱们的记者一同去实地体验一下,达卡火车站是孟加拉国最大也是最忙碌的车站,一进到外...。

外地期间7月1日下午,巴拿马入选总统何塞·劳尔·穆利诺在巴拿马首都巴拿马城的阿特拉帕会议核心宣誓到任,往年5月5日,巴拿马选举法院发表,穆利诺入选巴拿马新任总统,穆利诺1959年生于巴拿马西部市区戴维,曾任巴拿马外交部、外交和司法部以及公共安所有部长,总台记者冯丽,gulwassworninthisweekastheeleventh...。
破解版就是未经授权经常使用的软件,财务软件的破解版当然能用,当然这不扫除破解者在软件中添加后门程序,倡导最好别用!!破解版和正版没有什么差异,是在网高低载~cad破解版是什么意思cad破解版,就是破解了的CAD装置文件,楼上说的都正确,不过他们小看的中国的盗版事业了,如今的破解版,除了不用花钱,装置和注册和正版没什么不同,说真实的就是...。

朝阳群众app如何一键举报?朝阳群众是一款专门为朝阳群众打造的软件,相信很多小伙伴都知道朝阳群众的厉害,哪里有人搞事情哪里就有他们,那么朝阳群众app如何一键举报呢,下面小编来告诉大家。 朝阳群众软件图片 该APP可以让所有用户进行报案和举报。内容

腾讯软件中心提拱海量免费软件安全下载,全部软件都已经过安全杀毒检测。手机、电脑客户端版应用软件大全,最新最快速的软件下载中心。

为大家带来逆战10周年商店活动地址2022,参与到这次的逆战10周年庆活动礼包领取地址的玩家朋友们将可以领取到各种福利道具和人物武器奖励,下面我们就来看一看这次的逆战10周年商店活动详情吧,逆战10周年商店活动地址2022逆战10周年庆活动礼包领取地址

如果你的企业员工大量流失,一定是你的管理人员、你的中层管理出了问题,不信可以自己做一个实验,打电话给公司离职超过3个月以上的比较优秀的一批员工,你可以以朋友的身份很真诚地请教一个问题,当初你离开公司的真正原因是什么?,你会意外发现,80%以上的人会告诉你,老板,我现在可以告诉你了,当初我离开公司的真正原因不是那个辞职报告上写的什么...。
代码说明,本页面的认证代码为DXwap移动联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在DXwap移动联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有...。

人们对新颖的美食总是透出羡慕的眼光,为了满足内心的好奇,会想要忍不住的尝一尝,从而找到自己喜爱的美食系列,美食的种类也一直在不断地升级中,比如黄焖鸡的升级版是瓦香鸡黄焖鸡米饭,口味方面更加地奇特,具有鲜美细嫩的口感,吃的时候会散发出呲呲的声音,每弥漫出诱人的香味,很难散去,傣晓妹是经营特色瓦香鸡的连锁餐饮品牌,4年多的经验,拓展有45...。

发表在专业问答2022,5,313,31展示机型信息,品牌型号,小米电视5S、iPhone13系统版本,MIUITV3.0、iOS15.4.1将电视和手机连接同一局域网后就能够进行无线投屏了,以下是在电视上进行投屏的具体操作方法,怎么在电视上投屏1.连接局域网络先将电视和手机连接同一局域网络;2.打开电视投屏然后打开电视上的投屏工具;...。
准备工作,大麦电视、u盘、电脑当贝市场,,进入官网下载最新版本apk文件,直接下载,http,dlap1.dbkan.com,update,dangbeimarket.apk,,并拷贝进u盘,附,当贝市场官网,http,www.dangbei.com,二、将U盘插入大麦电视中,这时候会自动弹出文件管理窗口,如果没有自动弹出,那...。
