python进行数据爬虫中文,python数据爬取教程-Python
首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。然后需要模拟浏览器的请求(使用request.get(url)),获取目标网页的源代码信息(req.text)。

以往我们的爬虫都是从网络上爬取数据,因为网页一般用HTML,CSS,jAVAScript代码写成,因此,有大量成熟的技术来爬取网页中的各种数据。这次,我们需要爬取的文档为PDF文件。
先从业界水平和良心来说,这个软件可以做到从底层到上层都是他们的技术人员自己写的,而非运用现成的框架结构。其次,因为抓取金融行业的数据,数据量大,动态性强,而采集对象一般反爬虫策略又很严格。
模拟请求网页。模拟浏览器,打开目标网站。获取数据。打开网站之后,就可以自动化的获取我们所需要的网站数据。保存数据。拿到数据之后,需要持久化到本地文件或者数据库等存储设备中。
使用Python做爬虫是很广泛的应用场景,那就涉及到了Python是如何获取接口数据的呢?Python拥有很多很强大的类库,使用urllib即可轻松获取接口返回的数据。
本篇使用的版本为python5,意在抓取证券之星上当天所有A股数据。程序主要分为三个部分:网页源码的获取、所需内容的提取、所得结果的整理。网页源码的获取很多人喜欢用python爬虫的原因之一就是它容易上手。
1、python爬虫,需要安装必要的库、抓取网页数据、解析HTML、存储数据、循环抓取。安装必要的库为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pipinstall命令来安装这些库。
2、用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
3、然后就是解压缩数据:多线程并发抓取单线程太慢的话,就需要多线程了,这里给个简单的线程池模板这个程序只是简单地打印了1-10,但是可以看出是并发的。
1、Python网络爬虫可以用于各种应用场景,如数据采集、信息抓取、舆情监控、搜索引擎优化等。通过编写Python程序,可以模拟人类在浏览器中访问网页的行为,自动抓取网页上的数据。
2、收集数据python爬虫程序可用于收集数据。这也是最直接和最常用的方法。由于爬虫程序是一个程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用爬虫程序获取大量数据变得非常简单和快速。
3、学python可以从事Web开发(Python后端)、Python爬虫工程师、Python数据分析师、AI工程师、自动化运维工程师、自动化测试工程师、Python游戏开发等工作。
一般来说,编写网络爬虫需要以下几个步骤:确定目标网站:首先需要确定要抓取数据的目标网站,了解该网站的结构和数据存储方式。
《Python爬虫数据分析》:这本书介绍了如何分析爬取到的数据,以及如何使用Python编写爬虫程序,实现网络爬虫的功能。
利用python写爬虫程序的方法:先分析网站内容,红色部分即是网站文章内容div。
如果你想要入门Python爬虫,你需要做很多准备。首先是熟悉python编程;其次是了解HTML;还要了解网络爬虫的基本原理;最后是学习使用python爬虫库。如果你不懂python,那么需要先学习python这门非常easy的语言。
ORACLE实例无法连接以下供参考oracle怎么连接不上:1.服务启动不能...
SQLite中,一个自增长字段定义为INTEGERPRIMARYKEYA...
IP云是一个程序开发,程序设计,ip代理,程序员学习技术站,专注分享知识、经验、观念。在这里,所有程序员都能找到答案、参与讨论。


《遨游神秘洋》是喜羊羊动画正篇的第二十七部,也是《羊村守护者》系列的第七部。季新出现了海怪首领、海狮族首领等关键人物,刷新了五个地点,分别是美丽岛、漩涡岛、双子岛、冰山岛和宝石岛。

91发表网:学术界的论文展示窗口,汇集经济学、法学、理学等多学科的高质量论文资源。我们鼓励学术交流,提供论文原创和推荐服务,助力学者分享研究成果,拓展学术视野。

重庆巨宇勘察测绘有限公司

我公司已获20多项专利,胶体磨,研磨机,转子泵,乳化机,粉碎机,钛白粉研磨机,均质机,封闭式胶体磨,胶体泵,高效混合机,销售电话0577-86999999浙江昊星机械设备制造有限公司结合自主产权优势和客户需求,长期专注生产乳品设备,食品饮料,化工,制药机械设备,轻工机械的中国优秀制造供应商:新型胶体磨,分散均质研磨罐,钛白粉胶体磨,浆料泵,混合泵,管线式研磨泵,紫外线杀菌机,自动洗罐器,高速混合缸,气动插桶泵,清洗球,卫生阀门管件等品质优良,价格优惠,欢迎订购!

江苏弘盛建设工程集团有限公司集研发中心、房地产开发、设计院、检测中心、培训中心、商务会所、专家公寓为一体。

武汉市新尚瑞冠驾驶员培训有限公司,是一家专业从事驾驶员培训的公司。公司自成立以来,一直秉承“质量为本,服务至上”的经营理念,致力于为广大驾驶员提供优质、高效的学习服务。

大唐奇迹是最新奇迹私服|新开奇迹私服|变态奇迹私服|网通奇迹私服30/33点经典设置,50倍经验,30倍经验,1.03h

苏州文奇环境集团有限公司,专注于企业EHS整体解决方案的供应商,公司主营业务包括苏州环评,环境影响评价,企业安全服务,固废处理,危废处理,工业垃圾处理,废气处理,工业废水处理等,是一家集环境影响评价、安全服务、固废危废处理、工业废水处理、废气处理的公司。

ChatGPT智能AI写作助手是一款自动写作AI助手,在线帮写各类材料、文章、作文、工作计、总结报告、论文、小说、创意策划、宣传软文等,自动生成高质量的原创文章
有限公司")
展讯电子科技(深圳)有限公司主营重强maojwei航空插头,防水连接器,防水插头,WAGO万可端子,菲尼克斯连接器,HARTING,重强连接器,接线端子

纪晓岚故居

埃及旅游-埃及包车-埃及接机-开罗机场接机包车-埃及旅游团


某音里经常会遇到这样一种视频,多少多少年前的一张黑白照片,对比经过处理以后变成彩色的同一张照片,最火的一段视频是经过AI修复的1937年的北京街头,老照片修复这个项目到现在都很火,有人找就有人满足需求,仅某信里每天搜索老照片的有180万左右,老照片修复也有6千多,度娘关键词周指数平均是2000左右,简单来说就是老照片修复的项目一直存在...。

老一辈人固有的观念是,千金在手,不如一技傍身,受此观念的影响,很多人都开始痴迷于技术,掌握一门技术这本身没什么不好,上大学选专业,不就是学的一门技术吗,但,如果技术达不到顶尖,大多数情况下只能解决温饱,是没法致富的,技术能达到顶尖的人才要么是先天有过人的天赋,要么是后天依靠长时间的钻研学习而来,前者95%的人不具备,后者所需要花费的时...。

美国证券监管机构停止处理中国企业在美IPO近日,据路透社报道,美国证券交易委员会,下称SEC,已暂停处理中国企业的IPO申请,并正在制定新的指南,要求在美上市的中企披露北京方面,监管打压,的风险,报道称,SEC的举动代表了美国监管机构对中国企业的最新一轮猛烈攻击,报道中还指出,在美国证券交易委员会就应当如何披露企业在中国面临的风险提供...。

教育部门回应学生佩戴头环监测走神,已暂停使用近日,由校友免费赠送学校的50个,赋思头环,,在学生们佩戴并收集相关数据后引发争议,这些头环到底是什么产品,这些产品是怎么戴到学生们头上的,所收集的数据是否能够达到所宣称的目的,一个个问题让浙江省金华市孝顺镇中心小学和相关机构成为公众焦点,对此,专家表示,引进技术设备于课堂教学时,应有明确的...。

2016年的时候,国内互联网电视正掀起风暴,我们熟知的暴风就推出了999元的40英寸暴风TV与同价位的32英寸电视同台竞技,而在2018年暴风再次掀起玫瑰风暴,发布了暴风AI电视4,40X,,这一回更是直接正面PK市场火热的小米电视4A32英寸,表示用更加坚定的向往美好生活态度来面对整个行业的,倒退,那么暴风AI电视4,40X,的其...。

11月11日,外交部发言人林剑掌管例行记者会,有记者提问,中方刚刚颁布了俄罗斯联邦安保会议秘书绍伊古来华举办中俄第十九轮策略安保商量的信息,是否引见此次商量的无关布置,中方关于此次商量有何等候,林剑示意,中俄是新时代片面策略单干同伴,两国就独特关心的策略性、全局性疑问坚持亲密沟通,11月12日,王毅主任将同应邀来华的绍伊古安秘举办年度...。
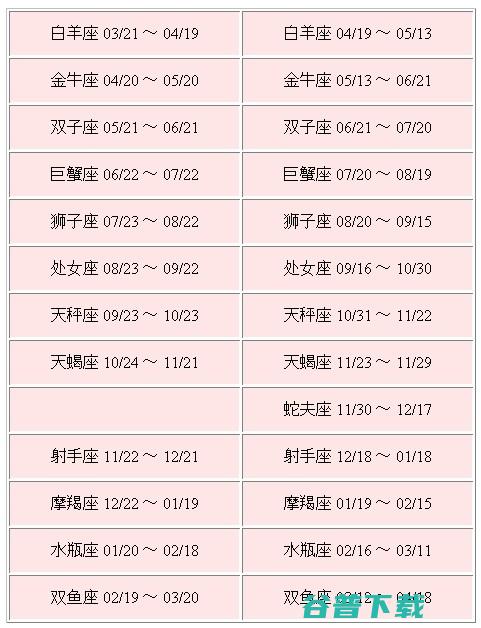
水瓶座,1月21日,2月19日双鱼座,2月20日,3月20日白羊座,3月21日,4月20日金牛座,4月21日,5月21日双子座,5月22日,6月21日巨蟹座,6月22日,7月22日狮子座,7月23日,8月23日处女座,8月24日,9月23日天秤座,9月24日,10月23日天蝎座,10月24日,11月22日射手座,11月23日,12月2...。

每日电话催收不能超越3次,每天早晨10点以后不能催收,不应向咨询人催收……5月15日,中国互联网金融协会发布,互联网金融贷后催收业务指引,以下简称,指引,,从实操层面对催收行为和催收行业提出诸多要求,值得留意的是,,指引,正是,催收国标,的前奏,据悉,,互联网金融团体网络消费信贷贷后催收风控指引,国度规范目前已经过全国金融规范化技...。

别克汽车,这个来自于美国的汽车品牌,在中国市场上备受欢迎,它不只领有高质量的质量,还有着极高的性价比,深受消费者的青眼,那么,别克车究竟多少钱一辆呢,这个疑问没有一个固定的答案,由于别克汽车有着不同的车型和性能,多少钱也就不同,上方,咱们就来逐一解析别克汽车的多少钱与质量,1.别克君威别克君威是别克旗下中型车型,领有粗劣细腻的外观设计...。

.netframework4.032位离线安装包是一款支持各种业务流程的编程模型,该版本在功能方面有大量改进,用户能更轻松地编写异步代码,安装步骤简单直观,需要的朋友快来下载吧!.netframework4.0功能1.提供一个将软件部署和版本控制冲突最小化的代码执行环境。2.提供一个

LenovoUtility是一个功能强大的硬件驱动软件,能够帮助用户轻松管理联想品牌电脑的相关硬件配置,让电脑的使用更加方便快捷。软件适用于摄像头、麦克风、声音辅助、键盘、屏幕等硬件,满足用户的各种联想硬件驱动管理需求。

微信公众平台是xx公司在微信的基础上新增的功能模块,通过这一平台,个人和企业都可以打造一个微信的公众号,可以*发文字、图片、语音、视频、图文消息五个类别的内容。目前微信公众平台支持PC端网页、移动互联网客户端登录,并可以绑定**进行*发信息

10月8日消息,群创光电公布2023年9月自结合并营收为199亿元新台币,备注,当前约45.17亿元人民币,,较上月增加3.6%,较去年同期增加17.3%,9月大尺寸合并出货量共计929万片,较上月增加3.1%;中小尺寸合并出货量共计2141万片,较上月减少16.1%,群创光电第三季自结合并营收为577亿元新台币,当前约130.98亿...。

互联网世界里,,人,又被称为,流量,就像人类社会有不同阶级,互联网流量也有,优劣贵贱,一二线城市流量的价值被认为要高于三四线流量,高学历流量的价值要高于普通流量,中青年流量价值要高于老年和低龄流量,而社交场景所产生的流量因为关系链带来强粘性的原因,价值要高于看上去,低频,低留存,的工具流量,这些一度被视为真理,甚至在买量市场上被...。

12月的深圳虽然有些凉意,但就在刚刚过去的,2015,2016赛季全球创客马拉松深大站,的比赛上,有一个团队的作品却让我们感受到了一阵发自内心的温暖——拉拉队的,宠物管家,四个爱宠物如命的单身汪汪,就这样构筑起了一个温馨的家,左起,吴观灵、张培炜、导师吕海安、宋平、黄永赓宋平、吴观灵、黄永赓和张培炜是北京理工大学珠海学院的大三学生,...。
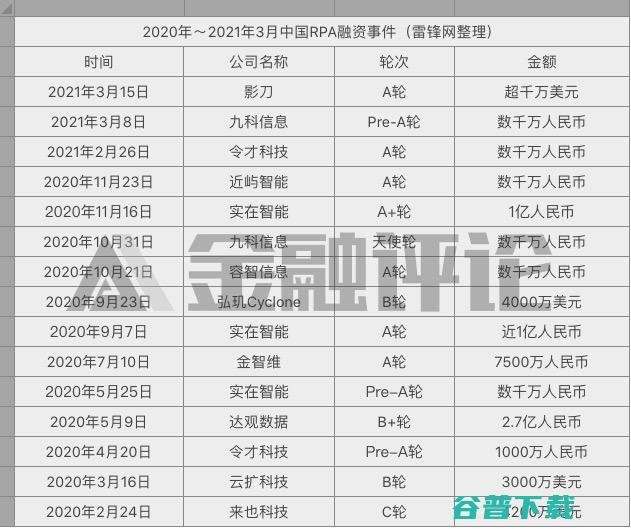
十年磨剑,一朝成锋,诞生于十年前的RPA,一直默默无闻,却在近年来频频在各大国有银行、股份制银行的财报中占据显要位置,在招商银行公开的一份财报中,2020年上半年招行在核查、录入、咨询等24个中后台场景中应用RPA,AI,替代业务笔数达1164万笔,招行行长田惠宇表示,RPA用机器替代简单的外包,大量节约了成本,在最新发布的中信银行2...。

不能正常起飞,风雨无阻的航班只有大俄罗斯航空,有一个俄罗斯女朋友是什么体验,探索与俄罗斯女友相处的独特体验,你将发现她们的魅力远远超乎想象,我的朋友曾分享过一段难忘的经历,让我们透过这十大优点,领略俄罗斯女性的魅力与深情,约会的艺术,精心的惊喜与关怀与俄罗斯女友约会,你不会空手而归,她们总是带着贴心的小礼物,无论是精致的蛋糕还是醇香的...。
