中国企业斩获无数冠军 2019 CVPR 见证华人星耀时刻! (中国企业斩获首个千米级国际深水油气总承包工程)
6 月 18 日,三大世界顶级计算机视觉会议之一「计算机视觉与模式识别会议」(Conference on Computer Vision and Pattern Recognition 2019,CVPR 2019)在美国长滩拉开帷幕,顶会吸引全球超过9200位顶尖专家、学者以及产业界人士,共同推进 CV 技术的发展与落地。
相比 2018 年,本届 CVPR 的论文提交数量增加了 56%,但论文接收率却下降了 3.9%,可见论文入选难度加大;而学术比赛报名人数也保持持续增长。但无论在论文方面还是学术比赛中,今年多家中国企业都取得了可喜的成绩,这些成绩不仅体现了这些企业的发展水平,也代表了国人的科技进步。雷锋网 AI 科技评论现将其成果整理报道如下。

商汤 62 篇论文入选 CVPR 2019,联合研究团队获得 CVPR 2019 Workshop NTIRE 2019 视频恢复比赛四个赛道冠军
商汤科技 CVPR 2019 录取论文在多个领域实现了突破,其中代表性论文有:《基于混合任务级联的实例分割算法》、《基于特征指导的动态锚点框生成算法》(高层视觉核心算法——物体检测与分割);《基于网络参数插值的图像效果连续调节》、《基于光流引导的视频修复》(底层视觉核心算法——图片复原与补);《PointRCNN: 基于原始点云的 3D 物体检测方法》(面向自动驾驶场景的 3D 视觉);《基于人体本征光流的姿态转换图像生成》(面向 AR/VR 场景的人体姿态迁移);《基于条件运动传播的自监督学习》(无监督与自监督深度学习前沿进展)等。这些突破性的计算机视觉算法不仅有着丰富的应用场景,也为 AI 行业的发展做出了巨大的贡献。
而在 CVPR 2019 Workshop NTIRE 2019 视频恢复比赛中(包含两个视频去模糊和两个视频超分辨率),来自商汤科技、香港中文大学、南洋理工大学、中国科学院深圳先进技术研究院组成的联合研究团队使用 EDVR 一套算法,获得了全部四个赛道的所有冠军,并且每个结果都大幅超越赛道第二名。
在论文《EDVR: Video Restoration with Enhanced Deformable Convolutional Networks》中,作者介绍了这种新型算法,通过一种新的网络模块 PCD 对齐模块,使用 Deformable 卷积进行视频的对齐,可以实现整个过程端到端的训练;而在挖掘时域(视频前后帧)和空域(同一帧内部)的信息融合时,作者又提出了一种时空注意力模型,来进行更好的信息融合。
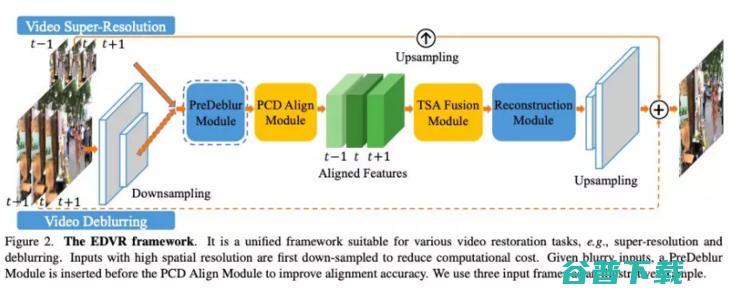
因此,在将 EDVR 算法视频超分辨率与目前行业最好的图像超分辨算法 RCAN 恢复来对同一区域进行处理时,可以明显看到 EDVR 算法视频超分辨能给到更多的细节。(该方法的代码已开源)
另外,商汤科技还在 AI CITY Challenge(CVPR 2019 Workshop)异常检测赛道中获得冠军。城市智慧交通一直都面临着数据质量差、标签数据少、缺乏高质量算法模型以及从边缘到云端的计算资源不足等挑战,而比赛中,商汤科技的设计更多地通过迁移学习、无监督和半监督的方法检测交通异常,如道路事故、车辆故障等,从而达到更好的帮助城市交通变得安全和智能这一目的。
百度 17 篇论文被大会收录,获 10 项 CVPR 2019 竞赛冠军
在今年的 CVPR 上,百度共有 17 篇论文被接收,内容涵盖了语义分割、网络剪枝、ReID、GAN 等诸多方向,并且其中很多技术都设计到无人驾驶相关场景。
其中包括《Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation》()中,提到了结合了联合训练和对抗训练来处理虚拟图像与真实图像之间语义分割网络训练差异的问题,将该技术应用在自动驾驶中,可以大大减少数据标注和采集的工作量。
《Sim-Real Joint Reinforcement Transfer for 3D Indoor Navigation》()中提出的视觉特征适应模型和策略模拟模型,可以有效将机器人在虚拟环境中学习到的策略和特征迁移到实际场景中;《ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving》一文提出目前已知自动驾驶领域最大规模的三维车辆姿态数据集,可以更好的对单张图像的车辆姿态估计。
而在 CVPR 相关竞赛任务中,百度一共获得了 10 项冠军,涵盖众多热门领域——
在 CVPR 2019 上,百度 Apollo 还首次曝光 L4 级自动驾驶纯视觉解决方案。Apollo 技术委员会主席王亮就 L4 级全自动驾驶(Fully Autonomous Driving)环境感知技术方案进行了讲解,并公开了环视视觉解决方案百度 Apollo Lite。并表示经过前期的技术研发投入和 2019 年上半年的路测迭代,依靠这套 10 相机的感知系统,百度无人车已经可以在城市道路上实现不依赖高线数旋转式激光雷达的端到端闭环自动驾驶。
旷视 14 篇论文被接收,并斩获 CVPR2019 挑战赛 6 项世界冠军
在 CVPR 2019 上,旷视研究院通过 Oral、Poster、Workshop、Demo、Booth 等形式,同世界分享在计算机视觉理论与应用领域的最新进展。
相比去年旷视科技有 8 篇论文被收录,今年他们又多了 6 篇被 CVPR 所接收。这 14 篇论文涉及行人重识别、场景文字检测、全景分割、图像超分辨率、语义分割、时空检测等技术方向。
并在顶会的 CVPR 2019 WAD(Workshop on Autonomous Driving)、CVPR 2019 FGVC(Workshop on Fine-Grained Visual Categorization)、CVPR 2019 NTIRE(New Trends in Image Restoration and Enhancement workshop)3 项挑战赛中,击败 facebook、通用动力、戴姆勒等国内外一线科技巨头与知名高校,一举拿下 6 项世界冠军,内容涵盖自动驾驶、新零售、智能手机、3D 等众多领域。
其中挑战赛 NTIRE 2019 真实图像降噪比赛,致力于恢复与增强图像质量。到目前为止,已连续举办了 3 年。今年 NTIRE 挑战赛下设 11 项比赛,旷视研究院参赛的「真实图像降噪(Real Image Denosing Challenge)」中,共有来自全球的 216 位选手、12 支队伍。和往年不同,今年的图像降噪赛是针对真实而非合成的图像去评估图像降噪器。该项比赛根据图像储存的两种格式——原始传感器数据(raw)和标准 RBG(sRGB),分为对应的两项子赛。
旷视研究院参战 raw 图像去噪,提出了针对 raw 图像的基于 U-Net 框架的「拜尔阵列归一化与保列增广」方法。团队精心设计了一种数据预处理方法,使得不同输入图像间的数据能保持网络输入一致性,从而应用到具有不同拜耳模式的输入上,在保证性能的前提下用更大的图像集合训练网络。此外,团队还提出了适用于 raw 图像的数据增广方法,这些优势可以帮助网络获得更好的泛化能力。
而且旷视的冠军算法已成功落地于 OPPO Reno 10 倍变焦版。OPPO Reno 10 倍变焦版搭载了基于旷视 MEGVII 超画质技术研发的「超清夜景 2.0」功能,能够为用户提供更好的夜拍体验。这也是旷视超画质技术首次运用在大规模量产机型上。
京东 AI 在 CVPR 2019 共发表 12 篇论文,斩获 3 项冠军和 2 项亚军
本次京东 AI 研究院在 CVPR 2019 上一共发表 12 篇论文,其中 4 篇论文入选了 oral presentation(oral presentation 的入选率只有 5%),入选 oral presentation 的四篇论文包含:
其中京东 AI 研究院提出的 ScratchDet,则从优化的角度出发,通过实验解释了梯度稳定手段之一的 BatchNorm 如何帮助随机初始化训练检测器,进而结合了 ResNet 与 VGGNet 来加强对小物体的检测。并将这一技术成功运用在了其他任务上,如人脸检测、文字检测等,这对于计算机视觉的发展有着重大的意义。
在学术比赛方面,京东 AI 研究院在 CVPR 2019 上共获得三项第一,分别是:视频动作识别、商品图片识别,以及精细粒度蝶类图片识别;而在多人人体解析、菜品类图像识别竞赛中获得第二名。
视频动作识别被视为 ActivityNet 中最核心、最基础的任务。在本届 ActivityNet 视频动作识别任务(Kinetics)比赛中,共有 15 支来自于美国卡耐基梅隆大学、百度、Facebook 人工智能研究院、上海交通大学 MVIG 实验室等国际知名研究机构的参赛队伍。而京东 AI 凭借着他们所提出的一种新框架——通过局部和全局特征传播(LGD)学习视频中的空间、时间特征,最终在众多强劲参赛者中脱颖而出。
在精细图像识别 (Fine-Grained Visual Categorization) 学术比赛中,今年比赛图片数量和商品数据类别分别是去年的 5 倍和 40 倍,挑战性相应也有大幅度提升;全球共有 96 支队伍、152 位选手通过 1600 次提交参加了竞赛,而最终京东 AI 靠着基于自研的全新精细图像分类算法获得了冠军。该算法通过按块「破坏」图像中的结构信息,然后再令已经训练的神经网络进行重点视觉区域识别与抓取,进而识别物品本身;更值得注意的是,这一技术不光可以达到高准确率,同时还有很强的兼容性。相关研究成果更多详情可在论文《Destruction and Construction Learning for Fine-grained ImageRecognition》()中获得。
字节跳动 11 篇论文入选,并收获两个冠军、一个亚军
在 CVPR 2019 上,字节跳动一共有 11 篇论文被接收,其中有两篇入选为 oral。而在学术比赛方面,字节跳动在人体姿态估计和人体分割比赛中,共收获两个冠军、一个亚军。
本届 LIP(Look Into Person)国际竞赛共吸引了超过 75 支队伍参加,包括加州伯克利大学、NHN、悉尼科技大学、东南大学、上海交通大学、中国电子科技大学、香港中文大学等全球高校以及三星、百度、京东等科技企业的人工智能研究院机构。
比赛共包含五个竞赛任务:单人人体解析分割(the single-person human parsing)、单人人体姿态估计(the single-person pose estimation)、多人人体解析(the multi-person human parsing)、基于视频的多人人体解析(multi-person video parsing, multi-person pose estimation benchmark)、基于图像的服装试穿(clothes virtual try-on benchmark)。最终,字节跳动和东南大学组成的团队、以及肖斌带领的字节跳动团队并列单人人体姿态估计比赛的国际冠军;同时,字节跳动和东南大学组成的团队还获得了单人人体分割赛道的国际亚军。
其中,在单人人体姿态估计比赛上,字节跳动和东南大学组成的团队提出了基于增强通道和空间信息的人体姿态估计网络,可参考 CVPR 2019 论文《Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information》();而肖斌带领的字节跳动团队则提出了利用高分辨率网络(HRNet)来解决人体姿态估计问题,参考 CVPR 2019 论文《Deep High-Resolution Representation Learning for Human Pose Estimation》();后一种方法已在 GitHub 上开源,感兴趣的朋友可以进行更深入的研究。
阿里 AI 获图像识别竞赛 WebVision 冠军
阿里 AI 在该竞赛由谷歌、美国卡耐基梅隆大学、苏黎世联邦理工大学等机构联合全球视觉技术领域顶级学术会议 CVPR 发起的第三届图像识别竞赛 WebVision 中获得冠军,要求参赛的 AI 模型将 1600 万张图片精准分类到 5000 个类目中,最终阿里的识别准确率 82.54%,将万物识别领域的历史纪录提升了 3 个百分点。
而就在今年 3 月中,阿里与深圳大数据研究院、香港中文大学(深圳)、大连理工大学以及中国科学技术大学共同完成《Deep Reinforcement Learning of Volume-guided Progressive View Inpainting for 3D Point Scene Completion from a Single Depth Image》被收录为 Oral Presentation。
之后与哈尔滨工业大学、香港理工大学、深圳鹏城实验室联合设计的超分辨率算法——能够很好的应对模糊降质的 DPSR 技术(来自论文《Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels》),也被 CVPR 2019 所接收。并且该算法已经开源了代码();在另一篇被接收的论文《ODE-Inspired Network Design for Single Image Super-Resolution》中,阿里与中科院、中科院大学也展示了他们一起在图像超分辨率方面做出相应研究。
深兰科技斩获 CVPR 2019 FGVC 挑战赛冠军
FGVC 全称为 Fine-Grained Visual Categorization,即区分不同的动物和植物、汽车和摩托车模型、建筑风格等,是机器视觉社区刚刚开始解决的最有趣和最有用的开放问题之一。细粒度图像分类在于基本的分类识别(对象识别)和个体识别(人脸识别,生物识别)之间的连续性;不同于传统的广义上的分类任务,FGVC 的挑战致力于子类别的划分,需要分类的对象之间更加相似,例如区分不同的鱼类、同一植物不同形态、不同的生活用品等。
在今年 CVPR 的 FGVC6 Workshop 赛区,共有十个挑战赛,每个都代表了细粒度视觉分类在某个细分领域的挑战。今年此次挑战赛共有来自全球 88 个团队参与,提交了超过 1300 份方案。而在 Kaggle 上举办的 CVPR 2019 Cassava Disease Classification(根据木薯的叶子区分不同种类的木薯疾病的任务)挑战赛中,DeepBlue AI 通过图像增强方法来降低过拟合的风险,并提高模型的鲁棒性,同时利用多个在 ImageNet 表现优异的模型,以集成方法提升精度,最终获得了冠军。
除了该项挑战赛,同期深兰科技还在在 CVPR 的另外两项比赛 2019 Workshop on Autonomous Driving (WAD) D²-City & BDD100K Tracking Domain Adaptation Challenge and the D²-City & BDD100K Detection Domain Adaptation Challenge.(目标检测迁移学习、目标跟踪迁移学习挑战赛和大规模检测插值探索赛)分获亚军和季军。
图鸭科技,包揽图像压缩大赛四项指标全部冠军
今年的 CVPR 上,机器学习图像压缩挑战赛(CLIC)由 Google 联合 twitter、Netflix 等赞助。如今由于手机像素的提升,占用大部分内存空间的图片对于移动存储设备和网站来说都是很大的负担;而对图片进行高效高质的压缩处理,已经成了众多互联网企业的极大需求。因此,在本届会议上,图像压缩也成了技术焦点之一。
在去年,图鸭科技曾夺得过该挑战赛的 MS-SSIM 与 MOS 两项第一;而今年,他们也带来了更强的技术,最终在 MS-SSIM、Transparent Track、PSNR、Perceptual Qualit 四项指标上均夺得桂冠,向世界展示了他们的技术硬实力,成为世界图像压缩历史大满贯赢家。
美团无人配送斩获 CVPR 2019 轨迹预测挑战赛冠军
美团无人配送与视觉团队在本届 CVPR 上,也获得了很好的成绩,分别在障碍物轨迹预测挑战赛(Trajectory prediction challenge)中斩获第一名和商品识别挑战赛(iMaterialist Challenge on Product Recognition)获得第二名。
对于美团无人配送与视觉团队来说,这不光只是一种荣誉,也向我们展现出了他们在自动驾驶技术和视觉图像方面进行的大量研究和产品化探索,并在场景应用方面所积累的丰硕成果。
美图影像实验室 MTlab 获 NTIRE 图像增强赛冠军
美图影像实验室 MTlab 此次参加了图像增强和图像去雾两个比赛,两个比赛均收到了超过 200 支团队报名。
最终,在图像增强赛道(Image Enhancement Challenge)中,美图影像实验室 MTlab 获得了冠军;在图像去雾赛道(Image Dehazing Challenge),美图影像实验室 MTlab 获得了季军。
滴滴获得 CVPR 2019 AI 城市大赛亚军
本届 AI 城市大赛(AI City Challenge)共有来自全球超过 200 支顶尖队伍参与,滴滴在 CVPR AI 城市比赛(AI City Challenge)中最终获得了亚军,并携手加州大学伯克利分校 DeepDrive 深度学习自动驾驶产业联盟(BDD)一同举办了 CVPR 2019 自动驾驶研讨会,详细介绍了滴滴在自动驾驶领域的探索和实践。
雷锋网 AI 科技评论
原创文章,未经授权禁止转载。详情见 转载须知 。



珠海市逸仙堂医药有限公司成立于2020年4月27日,面积80平米,现有执业药师3名,营业范围包括西药,中成药,医疗器械,日用百货,保健食品等。

科思创TPU隐形车衣|科思创|隐身车衣|车膜专家

河南省逄德电气有限公司

淄博弘瑞膜结构有限公司专业安装膜结构

山东上善堂集团创建于2012年,集团总部位于风景怡人、地理位置优越的城市——威海。凭借工业筑基础、农业创优势、科技促发展的三步走优势,集团规模不断壮大,现有固定资产4亿元,员工100余人,成为覆盖高级食品研发加工、光伏发电、农业种植、建筑装璜、园林景观、养老服务、花卉培育、医疗用品、高分子材料等多个产业于一体的现代化企业集团。

西安中童儿童康复医院,西安市中心医院医联体医院,西安市莲湖区儿童康复定点机构,是西北地区一家专门致力于儿童多动症、抽动症、自闭症、语言发育迟缓、智力低下、矮小增高、性早熟、肥胖症等疾病治疗、康复和研究的儿童专科医院。

石家庄科锐电气有限责任公司是以生产各种高压配电设备为主,产品包括鱼杆梯,玻璃钢梯,绝缘伸缩梯,三相短路接地线,智能工具柜,智能安全工具柜,绝缘胶垫,绝缘梯,临时检修围栏等,价格优惠,支持广东,湖北,江苏,山东,陕西,河南,浙江,四川各地销售批发定制,欢迎前来咨询价格,订购。

农机1688网是中国农业机械行业大型综合服务平台。提供农机化信息新闻、图片、农机补贴政策、农机视频等信息以及农机产品电子商务服务,同时提供最丰富的农业机械(拖拉机、收割机、插秧机、旋耕机、微耕机、零配件等)产品、企业、农机产品价格、农机产品型号以及经销商报价信息。
山东盛派新能源科技有限公司是一家从事电动观光车、电动巡逻车、高尔夫球车的企业,提供相关服务和产品,欢迎来电咨询。

微油科技是一家基于互联网全新大数据模式,致力于服务汽车后市场,以客户关怀与忠诚度建设为己任,致力打造成安全便捷的油•车服务平台。主营业务为车主提供非事故道路救援、油站导航、加油优惠、停车场查导、充电桩查导、洗车店查导及4S店查导等便民服务。目前,与中国石油、中国工商银行、昆仑银行、太平洋保险及全国2000余家4S店建立密切合作。

我们是一家专业的网站建设公司,致力于为客户提供高质量的网站设计和开发服务。我们拥有一支经验丰富、技术娴熟的团队,能够根据客户的需求和要求,设计出具有创意和吸引力的网站。


如果你有一个想开披萨店的梦想,也具备相应的资金实力,并且有饱满的创业热情,那么接下来你需要了解的恐怕就是怎样开披萨店了,开披萨店看似简单,实则也有一套相应的门路,智慧之选者只有掌握其中的要领,才能顺利把店开起来,并让披萨店的生意持续红火,位置决定成败,你需要慎重选址俗话说,酒香不怕巷子深,,可现在似乎已经过了那个年代,酒香也怕巷子深...。

很多创业者在选择美容品牌时都会考虑其前景如何,其中法澜娇人往往是创业者非常认可的品牌,加盟法澜娇人后不仅仅是得到设备物料技术等资源扶持,同时还利于科技赋能确保加盟者提高管理效率并且完成本地营销推广,接下来说说这个话题,专业商学院线上同步培训在加盟法澜娇人的时候,用户不用担心自身没有运营管理经验或不了解专业产品,因为法澜娇人有线下线上多...。

消息,近日,国内EDA企业芯华章宣布对国内另一EDA企业瞬曜电子进行核心技术整合,将其超大规模软件仿真技术融入芯华章智V验证平台,丰富其系统级验证产品组合,同时,瞬曜电子创始人傅勇正式加入芯华章并出任首席技术官,芯华章成立于2020年3月,以智能调试、智能编译、智能验证座舱、智能云原生等技术支柱,构建芯华章平台底座,提供全面覆盖...。

在沿海的城市,吃海鲜就是家常便饭,而在内地的城市中,海鲜就是很多的人都喜爱的美食,一些商家就为了越多的人能够吃到美味的海鲜,就创建了自助海鲜店,而在内地的城市,自助海鲜就受到消费者的欢迎,市面上的就有非常受欢迎的豪巴斯海鲜自助餐厅,该海鲜店的装修时尚大气,一些创业者也想要加入创业,那究竟自助餐现在市场红火吗,豪巴斯海鲜自助餐厅前景怎么...。

发表在瑞格尔投影仪2024,1,1509,34瑞格尔E23是一款小巧轻便的家用投影仪,采用全新光机设计,具体瑞格尔E23投影仪的详细参数配置如何呢,下面就为大家分享,看看瑞格尔E23投影仪怎么样,各方面的优缺点有哪些,是否适合家用,瑞格尔E23投影仪怎么样,1.光学参数瑞格尔E23采用西塔全封闭光机,ip5x防尘等级,不漏光,可有效解...。

佬表食品是专门从事休闲食品销售的品牌,佬表食品立足市场已有十余年之久,公司在发展的这些年中妥善完善经营布局,深度优化消费者满意度,为品牌发展奠定下夯实基础,在公司坚持不懈的努力下,佬表食品业已成为拥有数百家网点的大型食品品牌,未来发展前景十分喜人,为向各位读者推荐该项目,文章将对佬表食品怎么加盟展开论述,希望文章能对各位读者有所裨益,...。

CDR是什么意思cdr全称是CorelDRAW是一个设计软件,关键用于出版业corelDRAW评价板什么意思评价版本应该不是正式版本,不过能经常使用就可以了,看看各项性能能否完全,能否打印,cdr是什么意思cdr意思是设计软件CorelDRAW的简写,CorelDRAWGraphicsSuite是加拿大Corel公司的平面设计软件;该...。

目前在铁甲二手机网站的十几万台二手设施中有将近700台的卡特彼勒307D开掘机,多少钱从20万到30万之间,除了小时数,车况也是其多少钱的选择起因之一这个地址是铁甲二手机网站中卡特彼勒30吨以上开掘机的页面,可以参考下,我想卖一台二手小型35开掘机,有七八年了,要六万左右,请问下划算吗,急!谢谢二手机的多少钱要从多繁难来考量,举个例子...。

原题目,安理会称对美从新制裁伊朗需要没有共识,外交部回应8月26日,外交部发言人赵立坚掌管例行记者会,据报道,安理会8月轮值主席、印尼常驻联结国代表示意,安理会在美国需要进行,极速复原制裁,机制的疑问上没有共识,安理会主席不会再采取进一步执行,中方对此有何评论,赵立坚指出,对于伊朗核疑问,中方近期已屡次说明了立场,安理会主席无关表态反...。

是股份制企业陕西汽车控股个人有限公司简称陕汽控股,始建于1968年,总部位于陕西西安,现已开展成为占低空积450万平方米,领有资产总额149亿元,从业人员2.3万余人的特大型汽车企业个人,公司产品范围笼罩重型越野车、重型卡车、大中型客车,底盘,、中轻型卡车、重型车桥、康明斯发起机及汽车零部件等畛域,是国度选型对比实验后保管的惟一指定越...。

VisualStudioCode是微软推出的带GUI的代码编辑器,改进了文档视图,完善了对Markdown的支持,新增PHP语法高亮。使用该工具的朋友可下载更新。

WIFI万能钥匙中我们可以破解网络链接WIFI,那么如何开启WIFI万能钥匙的自动打开数据网络功能呢?下面就来看一下小编给大家带来的开启方法是什么吧。

在超额完成2024年度目标后,零跑汽车再次乘胜追击,实现单季度净利润转正,1月13日,零跑汽车发布盈利预告,宣布2024年第四季度实现净利润转正,并提前一年达成单季度盈利目标,成为第二家盈利的新势力,并在盈利预告中提到,2024年第四季度,零跑汽车月平均交付超4万台,全年累计销售新车29.37万辆,预计2024年全年公司将实现营业收入...。

机甲大战前最终预热!解密Megabots的五大杀手锏都是啥,@YifanHou,两个机器人都是娱乐性质的,水稻桥那个针对日本机器人爱好者中的有钱人,定位就是极品玩具,Megabot这边是想弄成一项竞技赛事,两边都是商业运营,技术上没有什么新东西,,和军事更扯不上一毛钱关系,所以这就是一次商业炒作而已,大家看着爽就好,@HarYatSi...。

你知道这张图片上发生了什么吗,1903年12月17日,莱特兄弟完成了人类首次对天空的征服,这是当时近两个世纪以来最大的变革,在1900年,从纽约到洛杉矶坐火车需要整整4天的时间,而在1930年,坐飞机仅仅17个小时就能到达,到了1950年,仅仅需要6个小时,莱特兄弟完成了人类历史上第一次飞行,这是能够载入人类史册的一幕,然而,这个故事...。

译者,AI研习社,季一帆、,双语原文链接,HowtoPickYourGradSchool如果你正在阅读这篇文章,那么你大概率已经走完了研究生学校漫长而艰难的申请之旅,你成功地从众多申请者中脱颖而出,这样的胜利是你过去的付出所应得得,但是你应该怎么决定最终上哪一所学校呢,如果每所学校看上去都有自己独特的优势,你怎样才能做出正确合适得决定...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
