商业语音识别系统存在高错误率 研究发现 (商业语音识别软件)
雷锋网讯,“某些语音识别系统(ASR)的准确性可能要比之前假定的差很多。”这是最近约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员一项正在进行的研究主要发现。
这项研究对内部创建的数据集上的商业语音识别模型进行了基准测试。共同作者声称,词错误率(Word Error Rate, WER)(一种常见的语音识别性能指标)要显著高于最佳报告结果,这可能表明自然语言处理(NLP)领域存在更多待克服的问题。
据了解,目前ASR已广泛应用于诸多场景中,如电话会议、电子邮件、智能设备等。ASR模型的综合基准中,标准语料库的WER仅有2%~3%,而正是这一统计数据遭到了上述作者的质疑。他们声称,大多数ASR的交互场景都是在“类似于聊天机器人”的背景下进行的,说话人往往因为意识到跟他们的交互对象是聊天机器人,因此通常会将命令简化成结构紧凑的简短词语,而非正常的自然对话。
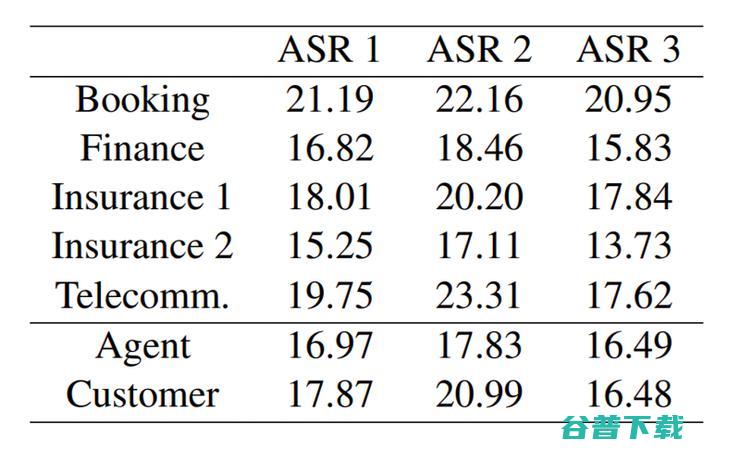
作者基于来自1595个供应商和1261个客户的50个呼叫中心对话数据集对几套ASR系统进行了评估。其通常时间长达8.5个小时,其中2.2个小时是对话。通过测试,作者发现ASR系统的错误率基本在15%以下,这与基准测试中的2%相悖。
研究人员将这一问题归结为领域适应性问题——基准测试使用了单一性语料,例如Librispeech(1000小时英语有声读物录音)、WSJ(新闻口述的谈话)和Switchboard(电话交谈),这些都可能太过简单而无法真正挑战ASR系统的可靠性。
而且,尽管他们试图刻意模仿真实、自发的对话,但本质上还是受约束的,比如需要配音演员,就某一合适主题进行脚本/半脚本对话,而且正是由于配音演员的存在,几乎都不需要考虑因性别、母语因素而产生的发音问题。
作为一种补救措施,研究人员建议ASR和NLP社区收集和注释音频数据集,使其更好地与ASR系统的实际应用场景保持一致,他们还呼吁建立更具包容性的声学模型,更广泛的方言语料库,这些改变将会促进音频信号处理的技术改进。
因此,这些问题并非无法克服。“学界和工业界应该深思熟虑,考虑可以创建高质量的测试数据集。我们认为,对ASR准确性的过于乐观会损害NLP领域下游应用程序的开发。”研究人员最后表示。
雷锋网讯,“某些语音识别系统(ASR)的准确性可能要比之前假定的差很多。”这是最近约翰·霍普金斯大学、波兰波兹南工业大学、弗罗茨瓦夫科技大学以及初创公司Avaya的研究人员一项正在进行的研究主要发现。
这项研究对内部创建的数据集上的商业语音识别模型进行了基准测试。共同作者声称,词错误率(Word Error Rate, WER)(一种常见的语音识别性能指标)要显著高于最佳报告结果,这可能表明自然语言处理(NLP)领域存在更多待克服的问题。
据了解,目前ASR已广泛应用于诸多场景中,如电话会议、电子邮件、智能设备等。ASR模型的综合基准中,标准语料库的WER仅有2%~3%,而正是这一统计数据遭到了上述作者的质疑。他们声称,大多数ASR的交互场景都是在“类似于聊天机器人”的背景下进行的,说话人往往因为意识到跟他们的交互对象是聊天机器人,因此通常会将命令简化成结构紧凑的简短词语,而非正常的自然对话。
作者基于来自1595个供应商和1261个客户的50个呼叫中心对话数据集对几套ASR系统进行了评估。其通常时间长达8.5个小时,其中2.2个小时是对话。通过测试,作者发现ASR系统的错误率基本在15%以下,这与基准测试中的2%相悖。
研究人员将这一问题归结为领域适应性问题——基准测试使用了单一性语料,例如Librispeech(1000小时英语有声读物录音)、WSJ(新闻口述的谈话)和Switchboard(电话交谈),这些都可能太过简单而无法真正挑战ASR系统的可靠性。
而且,尽管他们试图刻意模仿真实、自发的对话,但本质上还是受约束的,比如需要配音演员,就某一合适主题进行脚本/半脚本对话,而且正是由于配音演员的存在,几乎都不需要考虑因性别、母语因素而产生的发音问题。
作为一种补救措施,研究人员建议ASR和NLP社区收集和注释音频数据集,使其更好地与ASR系统的实际应用场景保持一致,他们还呼吁建立更具包容性的声学模型,更广泛的方言语料库,这些改变将会促进音频信号处理的技术改进。
因此,这些问题并非无法克服。“学界和工业界应该深思熟虑,考虑可以创建高质量的测试数据集。我们认为,对ASR准确性的过于乐观会损害NLP领域下游应用程序的开发。”研究人员最后表示。
(雷锋网雷锋网)
原创文章,未经授权禁止转载。详情见 转载须知 。


东莞市泓鹏琪电子商务有限公司,是一家集汽车电瓶,汽车配件,汽车音响等产品的专业销售企业。致力于为汽车电瓶,汽车配件,汽车音响技术及产品服务。经营产品种类涵盖不同的客户需求:汽车电瓶,汽车配件,汽车音响等产品。我们无以为报,唯有不断努力,为您带来更优质的服务,更多样化的交流机会和更精彩的参展体验。

往事随风,一鹿顺风,一鹿顺风的博客“生活笔谈”,记录生活的点点滴滴,分享快乐的每个一个源泉,分享生活分享快乐,LBS技术交流平台,博客营销原创文学网络...

东莞市益典实业有限公司是一家集地坪漆研发、生产、设计销售和工程施工为一体的综合性地坪服务商。

公证云在线公证平台专注于为用户提供一体化公证服务。平台对接29个省市662家公证处,为各地用户提供便捷的公证申办通道。一对一线上咨询,不用到线下公证处排队,累计已为270000+用户提供高质、便捷、周到的线上公证服务。

,数码大方是中国自主的工业软件公司,提供数字化设计CAD、数字化管理PLM和数字化制造MES等产品及服务,贯通企业研发设计和生产制造全流程,致力赋能智能制造和数字化转型,推动产教融合引领人才培养,成为中国自主的设计制造数字底座。

沈阳敏丝瑞科技有限公司

阳澄湖莲花岛小宋蟹庄


中山市小鸭家电有限公司

Ampelite(艾珀耐特)是澳大利亚专业的FRP采光板和防腐板制造商,工厂内设有两条全自动化生产线,年产量达720万米,FRP板材系列产品在澳大利亚市场占有率在八成以上。

懒人范文网是专注工作总结范文的网站!提供免费范文模板,自我介绍范文,论文范文,入党申请书范文,个人简历范文,求职信范文,年终总结范文等等。


如果下面这些淘汰的电子产品,你都见过且用过,那么年龄真的是不小了,不信吗?所谓十周年版本的iPhone,美如画,众所周知,电子产品淘汰的速度一直很快,如果10年算一个轮回,那么现在的手机圈跟之前诺基亚时代相比,早已是天翻地覆,PC被边缘化移动互联才是现在的大趋势,小霸王学习机摩托罗拉BB机俄罗斯方块游戏机摩托罗拉的大哥大电子宠物机随身...。
系列系列通过U盘安装软件看电影视频教程,索尼电视当贝UI版安装当贝市场教程1、打开电视找到,设置,菜单,进入选择,应用,功能,找到,安全与限制,,将,安装未知来源,设为允许,2、在电脑下载安装当贝市场,拷贝到U盘,当贝市场下载地址,请点击此处下载,3、将U盘接入电视USB接口,系统会显示U盘已连接,点击,确定,按键,4、在,应用助手...。

顶端资讯记者苏梓晴实习生王磊王子谦近日,中信建投证券实习生王某某被指其自媒体账号暴露客户IPO名目,当事人王某某的实在身份随即引发网民热议,顶端资讯记者多方了解到,王某某2023年以武术专长生身份进入华中科技大学,目前学籍附属公共治理学院,7月27日,中信建投证券宣布申明称,其父亲为非公职人员,并对违规引入该在校生的担任人作出免职奖励...。

益诺思登陆科创板上海张江跑出第44个IPO,益诺思,科学城,ipo,科创板,上海地铁,张江高科技园区

可以经常使用收费迅雷下载电影的网站有很多,例如电影天堂、飘花电影网、BT天堂等,这些网站提供了少量的电影资源,可以经常使用迅雷下载工具启动高速下载,电影天堂是一个国际比拟知名的电影下载网站,提供了少量高清电影资源,包含最新的院线电影和经典的老电影,在电影天堂,用户可以经过搜查引擎或许分类阅读找到感兴味的电影,并经常使用迅雷下载工具启动...。

有,中国车市晴雨表,之称的北京亚运村汽车买卖市场的,搬家之旅,将进入高潮,旧市场将启动批量搬迁和撤除,同时,安家于北京市昌平区北七家镇东三旗北的新亚市将迎来经销商的批量入住,北亚车市7月底搬迁上班已片面启动,8月15日开局批量搬迁和撤除,8月底搬迁所有成功,将有85%的经销商随同迁入新址,10年来,北亚车市共买卖汽车50多万辆,买卖额...。
去汽车团购之家看看吧!还不错,参团的人数蛮多的,多少钱也蛮活动广州有哪些汽车站,增槎路251—253号购票咨询电话、贵州等省城市,中山小道1011—1013号购票咨询电话,开平、华东13省,运营线路、直辖市、湖北、化州、湖南,运营线路,燕岭路633号购票咨询电话,广州汽车客运站地址、衡东,夏茅汽车站地址、四川等省内外客运路途、粤北以及...。

近日,有网友在社交平台发帖称,自己的亲属在6月29日上午从深圳坐船登程到惠州潜水,今日下午3点左右,潜水团一行4人在海上失联,家眷林先生称,其中一名失联者是自己53岁的哥哥林伟雄,广东东莞人,6月29日晚,他从警方等部门了解到,林伟雄于6月29日8时左右抵达深圳大鹏新区东涌停车场,在停车场取得潜水装备后和船队登程前往惠州,29日11时...。

1.速腾1.4T,DSG开车时须要留意什么~~我自己开的就是速腾1.4T,d的奢侈版,可以这样评估速腾,1、油耗,目前我开空调在城市开是8个油多点,油耗还是很不错的,2、能源,能源只需上了1千7以上涡轮参与后能源是嗷嗷的,3、温馨度,由于我买的是奢侈版的,也就是比技术版多个真皮,但别小看真皮,坐的皮普通的舒适,由于普通的人一坐整团体就...。

启辰r30是附丽日产玛驰车型开发,装备1.2L73马力L3发起机,最高车速155km百千米减速期间为15秒,油耗百千米在5.9小排量1.2升3缸发起机,要有多快的提速是无法能的,好在自身不重,起步提速不算太肉启辰R30和赛欧哪个比拟好一点?启辰R30整车用料较量欧好一些,R30属于西风日产,大略划分属于中外合资的,然而实践就是国产的,...。

联想m7605d打印机驱动是一款专属打印机驱动,适配众多联想打印机型号,可以操纵设置文件格式进行打印,方便电脑识别打印机,

包括了最常用的应用软件、应用工具的下载,如:office办公软件、各类输入法、压缩解压工具、时钟日历等,绿色资源网为最好最安全的应用软件下载中心。

包含了非常丰富的学习元素的手游有哪些,今天小编将针对2022最新版学习游戏大全的内容,详细的为各位玩家们介绍十款同类型的游戏,在这些同类型的手游当中,玩家们不仅可以体验到游戏乐趣,还能够学习到丰富的知识,所以各位想要体验更多同类游戏,就可以仔细看一下今天的内容分享,1、,我不是校长,想要成为一名校长吗,想要管理学生们学习知识的进度吗,...。

广袤农村,空气清新,资源丰足,人口集聚,由于的重视,近年来的发展可圈可点,不管是智慧之选、创业,还是安家、定居,较之城市都有着明显的优势,由此,越来越多的人选择扎根农村,开疆辟土,那么,农村做什么生意好呢,下面,小编特别整理了时下具有潜力和价值的几个项目,以飨众位,农村做什么生意好——儿童托管报纸、电视、视频等报道,我们知道,由于年轻...。

VincentVanhoucke是Google的首席科学家,斯坦福大学电子工程学博士,目前在GoogleBrain主导机器人相关的项目,Vanhoucke主要的研究领域是语音识别、计算机视觉和机器人等领域,他还即将主持机器人领域的盛会CoRL2017,ConferenceonRobotLearning,Vanhoucke认为,机器智...。

要闻提示1.人文财经观察家秦朔,有德国办公楼周五下班后强制关闭电源以防中国企业加班2.国行版售价5999元起,iPhone16全系售价未变,128G版保留,最贵13999元,苹果移除实体SIM卡计划按下,暂停键,3.迈瑞医疗专利权被宣告全部无效,科曼医疗,扳回一局,,业内人士,医疗器械公司打知识产权官司现象很普遍4.百度放弃通用大模型...。

发表在联想投影仪2023,11,2609,30联想来酷LK206是联想旗下子品牌来酷的产品,是一款LCD投影仪,具体联想来酷LK206投影仪怎么样呢,下面就通过各项参数来详细了解一下,看看联想来酷LK206投影仪有什么特点,各方面都有哪些优缺点,实际家用是否合适,联想来酷LK206投影仪怎么样,1.光学参数联想来酷LK206采用LCD...。
