NeurIPS 2022 (neurips属于什么级别的论文)
作为当前全球最负盛名的 AI 学术会议之一,NeurIPS 是每年学界的重要事件。NeurIPS全称是 Neural InFormation Processing Systems,神经信息处理系统大会,通常在每年 12 月由 NeurIPS 基金会主办。大会讨论的内容包含深度学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多细分领域。 今年 NeurIPS 已是第 36 届,将于 11 月 28 日至 12 月 9 日举行,为期两周。第一周将在美国新奥尔良 Ernest N.Morial 会议中心举行现场会议,第二周改为线上会议。NeurIPS 2022 论文投稿早已在 5 月 19 日截止,今日官方终于公布了录用结果。根据官网邮件中给出的数据,本届会议共有 10411 篇论文投稿,接收率为 25.6%,略低于去年的 26%。

论文解读:

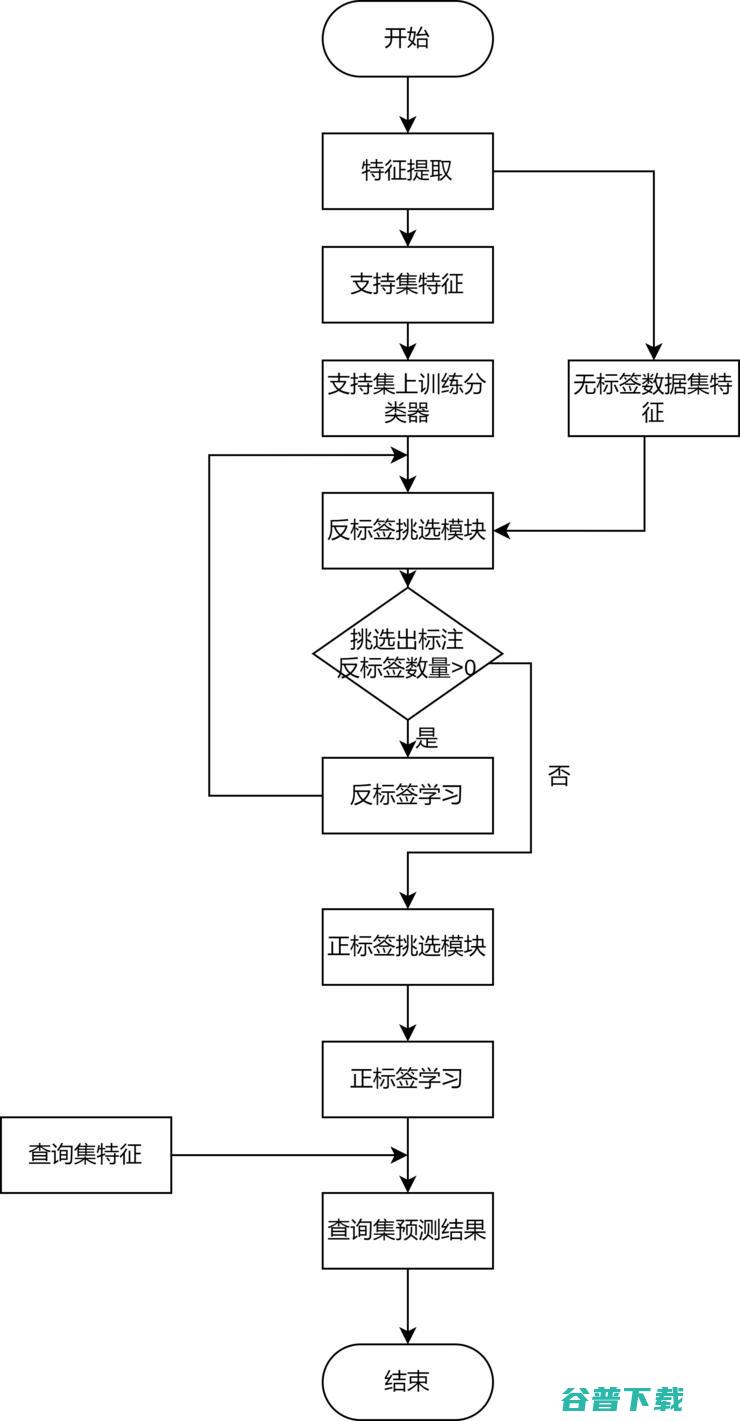
图1:论文概要
论文概述:
本文提出了一种基于反标签学习的半监督少样本图像分类学习方法,包括以下步骤:构造元任务,使用预训练的神经网络作为特征提取器,提取元任务中支持集、查询集以及无标签图像数据集对应的特征,并在支持集上训练一个分类器用于后续分类任务;反标签学习模块以较高正确率给无标签数据打上反标签,分类器在反标签上进行学习更新,不断迭代直到无法选出反标签。正标签学习模块,在反标签模块迭代结束之后,得到类别均衡且正确率较高正标签,并用分类器进行学习更新。
本文通过卷积神经网络提取元任务中对应数据的特征,通过反标签构造模块以较高正确率利用无标签数据,并用分类器在反标签数据上进行学习更新,进行迭代之后设计正标签学习模块获得类别均衡且正确率较高的正标签,用分类器在正标签数据上进行学习更新,以更加充分且高质量的利用无标签数据,可以获得更高的少样本学习图像分类准确率。
创新背景:
随着深度学习的发展,卷积神经网络在多个图像任务上已经超过了人类的水平,但是这些模型的训练依赖大量的数据,在现实生活中有些数据的采集难度较大,例如对液晶显示屏幕所有种类缺陷数据的采集,另外这些数据的标注也需要耗费大量的人力和财力。 相比之下,人类视觉系统可以从少量的例子中快速学习到新的概念和特征,然后在新的数据中识别相似的对象。为了模仿人类的这种快速学习的能力,减少方法对于数据的依赖,少样本学习近年来受到了越来越多的关注。少样本学习旨在结合先验知识快速地泛化到只包含少量有监督信息的样本的新任务中,在此设定下识别每个类别仅需要极少甚至一张带标签的样本,所以可以极大地减少人工标注成本。
基于少样本学习这样数据量较少的设定,一个需要面临的问题就是,在极少的带标注数据上,很难让模型较好的拟合到数据的分布。因此为了解决这样的问题,少样本学习中出现了结合半监督的研究方向。另外为了解决数据标注困难的问题,反标签学习的方法也应运而生。反标签顾名思义就是给数据打上相反的标签,是一种间接的方式代表该数据不属于某个类别。这样的做法可以大大降低数据标注的错误,例如对于一个5分类问题来说,给数据打真实标签即正标签错误的概率为给数据打反标签错误概率的4倍。另外在半监督少样本学习当中,由于带标签数据很少,因此模型在初始阶段很难有好的效果。用这样的模型给无标签数据标记伪标签将会出现大量的错误以及类别不平衡的现象。在这样的情况结合反标签学习的方法就可以解决这样的问题。本发明研究的基于反标签学习的半监督少样本学习方法,针对半监督少样本学习,设计适合的反标签标注方法,并结合反标签学习解决半监督少样本学习中出现的无标签数据利用不充分等问题。
目前,出现了许多研究半监督少样本学习的方法,但依然存在一些问题: 1)给无标签数据标注伪标签的正确率较低,错误标记的样本会影响最后的结果;2)无标签数据上标注的伪标签存在类别不平衡现象;3)方法较为复杂。
本论文主要贡献:
本论文提出了一种基于反标签学习的半监督少样本图像分类学习方法。 方法具体如下:
步骤1,构造元任务,使用预训练的神经网络作为特征提取器用来提取图像数据,提取元任务中支持集、查询集以及无标签数据集对应的特征,并在支持集上训练一个分类器,用于后续图像分类任务;

步骤2,反标签学习模块以较高的95%正确率给无标签图像数据打上反标签,用分类器在反标签上进行学习更新,通过不断迭代直到无法选出反标签;
步骤3,正标签学习模块得到类别均衡且正确率高达85%的正标签,并用分类器进行学习更新;
步骤4,用训练好的分类器在查询集上预测得到最后图像分类的类别结果。
本文提出的方法与已有技术相比,其显著优点为:
(1)本发明设计的反标签学习模块,通过给无标签图像数据标注反标签并进行学习的方式,在模型效果还不好的初始阶段,大大降低给无标签图像数据标注标签的错误率;
(2)经过反标签学习模块之后,本发明设计的正标签学习模块可以得到正确率高且类别均衡的正标签,继续对模型进行训练;
(3)本发明提出的方法相较于之前的方法流程简单,可以更充分且高质量利用无标签图像数据进行学习,最后在图像分类任务上得到了更好的效果。
创新奇智CTO张发恩(论文作者之一)表示:“当前的深度学习技术对人工标注的数据样本(也即带标签数据样本)数量具有很大依赖性,如何减少对带标签数据样本的依赖,利用较少的带标签数据样本训练出理想的视觉算法模型成为当下亟待突破的技术难点。少样本学习旨在从已有类别的数据中学习先验知识,然后利用极少的标注数据完成对新类别的识别,打破了样本数据量的制约,在传统制造业等样本普遍缺失的领域具有实用价值,有助于推动AI落地。”
版权文章,未经授权禁止转载。详情见 转载须知 。


通过本工具可以快速模拟搜索引擎蜘蛛访问页面所抓取到的内容信息,可以判断网站有没有被做跳转,否则影响SEO优化。

OsitevipcnGamefornecejogosmóveisedownloadsdesoftware.AquiestãoasúltimasemaispopularesrecomendaçõesdejogosmóveisAppleeAndroid,rankingsdejogosonlinemóveis,guiasdejogosmóveis,pacotesdepresentedejogosmóveis,aberturadeservidoresdejogosmóveis,testeseoutrosbenefícios!

辰领科技是一家专注于信息化领域整体解决方案的高新技术企业,为各行业提供智能化、信息化、移动互联网,物联网应用等智能化软件、APP开发服务商。

山东星火机械主要以生产销售锥体卷板机,四辊卷板机,液压卷板机,机械卷板机,焊接小车,焊接机器人,滚轮架,数控切割机为主。

西南农业开发电商平台

台湾美光金银丝

杭州晶冠玻璃瓶有限公司是一家杭州玻璃瓶厂家和棕色酒瓶生产制造商,产品有:玻璃瓶,啤酒瓶,棕色酒瓶,透明橄榄油瓶,精油瓶,香水瓶,调味瓶等。我们可以根据用户需要进行设计、生产及制品的深加工与精加工,产品除满足国内需求外,有近30%出口美、日、加及东南亚等国家与地区。

山东维度农牧科技有限公司,是一家集复合维生素预混合饲料、畜禽预混料、浓缩料及高档母乳猪料的研发、生产、销售和饲料原料国际贸易于一体的综合性农牧科技企业。

大连米云科技有限公司

广西三农资讯网最具影响力的广西三农资讯发布平台,提供最新最全面的农业、农村、农民资讯信息。,广西三农资讯网,全国三农信息一体化应用平台

昆山皓创广告传媒有限公司是一家集广告策划、活动策划、展示展览、环境导视、品牌形象设计、平面设计、摄影摄像等为一体的综合性专业公司。我们拥有一支技术力量雄厚、富有创造力的团队,能够提供给您**质的一站式广告服务。

广州海沣检测是领先的第三方检测认证机构,提供国际认证、产品检测、委托检验等一站式技术服务,服务全球企业,助您提升产品质量和市场竞争力。经验丰富,值得信赖!


随着数字时代的滚滚浪潮,儿童阅读的需求正经历着前所未有的变革,阅读内容的多元化、阅读方式的多样化、阅读体验个性化、阅读环境社交化等各方面愈加凸显,对于儿童阅读提出了更高要求,儿童也正在成为数字化阅读的主力军,成长秘密全科阅读,不仅仅是一套适应当代儿童的阅读方案,更是一种致力于儿童全面发展的教育理念,它面向3—12岁儿童倾力打造的全科阅...。

现如今,人们都喜欢吃各种特色小吃,所以特色小吃有着很大的市场需求量,另外,特色小吃行业收银丰厚,所以一些加盟商想要创业加盟特色小吃行业,但是有什么好吃的小吃加盟,台福记特色小吃所销售的特色小吃不仅口感好,而且种类多种多样,在市场上很受消费者们的喜爱,接下来小编详细地为大家介绍一下,台福记特色小吃品牌介绍台福记特色小吃是我国知名特色小吃...。
早上起床,翻了翻各个微信群,流水的红包让我瞬间有一种跟好几个亿擦肩而过的错觉,抢红包的人不亦乐乎,一直闹腾到大半夜,各个群都在玩红包接龙,抱怨没抢到的、炫耀网速的、谢谢老板的鳞次栉比;莫名其妙的被拉到某个群里,大家也不用做自我介绍,似乎红包就能代表一切;朋友圈里被,请用钱羞辱我,刷屏,QQ微信支付宝,具体到几点几分的抢红包指南被发了一...。

这是OPPOFindX5Pro评测部分节选,核心是对,双OIS和马里亚纳X,的效果、前景分析,OPPO表示FindX5系列研发过程中,影像相关人员有近2000人,OPPO宣称一加影像团队在一加10Pro上市之后也在帮忙,而当中的重点就是马里亚纳X和双OIS的调试,这两个努力都是纸面上不容易呈现的,OPPO确实选了一条更加艰难的路,关于...。

发表在专业问答2022,2,1415,38展示机型信息,品牌型号,当贝x3、iphone12系统版本,当贝OS2.0、ios15.2软件版本,腾讯视频8.4腾讯视频投屏卡顿的原因有以下几种,腾讯视频app自身限制了投屏播放速度;视频分辨率过高投影仪无法解码;网络产生故障导致播放卡顿,腾讯视频投屏卡顿是什么原因腾讯视频投屏卡顿的原因有以...。

我是一个地地道道的的广西人,老公是一个憨厚东北人,刚嫁过去的时候很不习惯那边的生活,饮食、居住,包括房子的装修都有很大的差异,刚开始的时候还经常抱怨,这不好,那也不好,后面慢慢的就习惯了,没来过东北的人,对那里的农村房一定很好奇吧,来看看我家,估计很多人没见过,东北农村的房子很少像南方一样起个两三层的小洋楼,楼层也不高,刚来的时候这个...。

雨润食品加盟是一个不错的加盟项目,我们在今天就为大家好好的介绍一下吧,加盟雨润食品很多加盟者关心的,也是想要加盟的一个项目了,所以小编在今天就为大家简单的介绍一下吧,看看雨润食品是如何赢得人心的吧,好的产品与服务是雨润对消费者的,是雨润应该承担的主要的社会责任,公司的质量目标是出厂产品合格率必须达到100%,雨润食品的加盟信息有什么呢...。

不只比亚迪!8月车市「卷疯了」:多家车企刷新销量纪录,车市,腾势,比亚迪,年销量,月销量
想要失掉微信旧版本,可以遵照以下步骤,首先,确保已卸载手机上的最新版微信,之后,关上网络阅读器,点击搜查框,在搜查框中输入,微信旧版本,,而后点击右上角的搜查图标,搜查结果产生后,点击进入豌豆荚运行商店中微信旧版本的下载页面,在豌豆荚的微信旧版本页面,选用你想要下载的详细旧版本,并点击页面右侧的,检查概略,检查完概略后,点击,个别下...。

蜘蛛称号1,Googlebot,从Google的网站索引和资讯索引中抓取网页2,Googlebot,Mobile针对Google的移动索引抓取网页3,Googlebot,Image,针对Google的图片索引抓取网页4,Mediapartners,Google,抓取网页确定AdSense的内容,只要在你的网站上展现AdSense广告的...。

软件采用soft加速技术,不超频,不损坏硬件,1,最好的加速函数,支持全局加速,更快更稳定,加速精灵,适用于各种配置型号,一般能提高系统运行速度15%-30%,加速精灵让你的系统运行更快,而且适用于各种配置型号,加速精灵原理:软件将有限的CPU资源实时调度给活动的应用程序,从而加速程序运行速度。1、加速精灵为什么不能用了?带有木马程序,启动后被你的防火墙自动杀毒,导致他的文件缺陷。加速精灵,适用于各种配置型号,一般能提高系统运行速度15%-30%。对于低配置的机器效果更明显。加速精灵让你的系统运行更快,而

做自配送了 由总部来控制 本地代理商无权干预 自配送就是是商家自己找人骑手送餐 不是平台外卖小哥帮送 您的外卖订单由商家帮送上门 也有可能商家叫第三方跑腿平台的骑手帮送

现在各地都形成有自己的饮食特色,地域不同饮食的口味也有所不同,随着餐饮品牌的连锁发展,很多的美食在世界快速地流行起来,成为大众都喜欢的美食种类,比如麻辣烫就是人们为之风靡的特色小吃,说到麻辣烫人们都会有垂涎三尺的感觉,独特的麻辣味道可以让人拥有很好的食欲,有种吃过一次,还想要多次吃的感觉,因此麻辣烫店的生意都非常地火热,有人对这个小吃...。
11月26日,阿里巴巴在港交所挂牌交易,开盘价报187港元,较176港元的发售价涨幅为6.25%,总市值约4万亿港元,超越腾讯控股的3.26万亿港元,这是阿里巴巴第三次上市,第二次在港股上市,2007年11月,阿里巴巴B2B业务曾在港股上市,后于2012年6月退市,2014年9月,阿里巴巴集团整体在纽交所上市,从2007到2019,阿...。

转眼Windows10已经推出了三年半的时间,Windows7更是快10年了,此前微软已经明确表明,2015年1月13日将会停止对Windows7主流更新支持,2020年1月14日停止扩展支持,如今微软又宣布,从4月1日起,Windows7扩展安全更新将会明码标价,具体价格为,Windows7扩展安全更新将会以,台,为单位销售,其中专...。

苹果14promax怎样开启悬浮球,苹果14promax手机也是有悬浮球的,这是苹果手机很经典的导航功能,可以减少home键的使用,那么苹果14promax怎样开启悬浮球呢,还不清楚的小伙伴一起来看看吧!...。

小米10于2020年2月上市,小米公司于2月发布了全新的旗舰手机小米10系列,这款手机是该公司在追求极致性能和高端市场定位上的重要尝试,小米从长期技术研发和创新经验的积累出发,不断精进生产工艺和核心技术,力求为中高端用户群体提供更加优质的产品和服务体验,小米10的发布标志着小米公司在智能手机市场的进一步发展和壮大,以下是关于小米10上...。
