Tech · Talk 云技术有话聊
4月14日,信服云可靠性技术专家Marshall在信服云《Tech Talk · 云技术有话聊》系列直播课上进行了《关键基础部件可靠性技术解析》的分享,详细介绍了 IT系统常见的物理故障对业务的可靠性的影响、如何运用软件定义解决硬件故障等内容。以下是他分享的内容摘要,想要了解更多可以点击阅读原文观看直播回放。
一、可靠性的定义和目标
可靠性是指系统不会意外地崩溃、重启甚至发生数据丢失,这意味着一个可靠的系统必须能够做到故障自修复,对于无法自修复的故障也尽可能进行隔离,保障系统其余部分正常运转。简而言之,可靠性的目标是缩短因故障(产品质量、外部部件、环境、人因等)造成的业务中断时间。
高可靠可以从三个层面理解:一,不出故障,系统可以一直正常运行,这种情况就需要提高硬件的研发质量。二,故障不影响业务。三,影响业务但能快速恢复。后两个层面可以通过“软件定义”的方式去规避硬件故障产生的业务中断。
谈到可靠性,首先要了解服务器的关键基础部件。从业界的服务器统计数据看,硬件部件的问题集中在内存、硬盘、CPU、主板、电源、网卡上。在云的环境当中,同一台服务器上可能运行了若干不同业务、不同场景的虚拟机,一旦物理设备崩溃,将会波及众多用户,同时也会对运营商自身造成巨大损失。而在现有的故障模式中,内存、硬盘故障是最高发和最严重故障。
关于内存和硬盘的故障,可以通过这两个案例来进一步了解。
案例一,内存UCE错误导致服务器系统反复宕机重启。服务器发生宕机重启,登录服务器的BMC管理界面,查询服务器的告警信息,出现如下告警:“2019-07-25 08:03:06 memory has a uncorrectable error.”后来,进一步查询硬件错误日志文件,发现DIMM020有大量内存CE错误和部分内存UCE错误,可知是因为DIMM020内存条发生UCE错误导致服务器宕机重启。
案例二,磁盘卡慢导致大数据集群故障。某大数据平台集群节点出现慢盘故障(系统每一秒执行一次iostat命令,监控磁盘I/O的系统指标,如果在60s内,svctm大于100ms的周期数大于30次则认为磁盘有问题,产生该告警)。先是ZOOKEEPER出现故障,后出现集群平衡状态异常。然后同一节点的其他服务也出现故障,最后整个节点所有服务全部故障,随后重启自动恢复。但是在3-10分钟之后该节点就会重复出现此情况。在未发现其他问题的情况下选择重启系统,业务中断时间十几分钟。
二、内存的可靠性技术
内存从外部结构看有PCB板、金手指、内存芯片、内存条固定卡缺口等。从内部结构看,包括存储体、存储单元Cell、存储阵列Bank、Chip(devIce)、Rank、DIMM、Channel等。
基于内存的结构,内存技术的提升(制程缩小和频率)容易带来更高的故障率。
(一)制程缩小带来的挑战
(1)光刻更容易受到衍射,聚焦等影响质量。
(2)外延生长(EPI)容易出现漏生长和外延生长间的短路等。
(3)蚀刻清洗等工艺的particle造成的影响加重。
(4)单die尺寸变小,单wafer die数量增加。
(5)未来TSV封装多die后段封装难度加大,失效率增加。
(二)频率提升带来的挑战
(1)高速信号时序margin更小,兼容性问题更突出。
(2)信号衰减更严重,DDR5增加DFE电路,设计更复杂。
(3)更高频率带来更高功耗,对PI的要求更高。
内存故障按照“故障能不能纠正”可以分为两类:CE(Correctable Error):可以纠正任意单比特错误、部分单颗粒多比特错误的统称;UE(Uncorrectable Error):不能纠正的错误统称。有一部分UE错误由于操作系统无法处理会导致系统宕机。
内存发生故障的原因有:内存单元能量泄漏 leakage、内存数据传输路径存在高阻抗、内存电压工作异常、内部时序异常、内部操作异常(如自刷新)、bit line/word line线路异常、地址解码线路异常、内存存在弱单元(可正常使用)、宇宙射线或放射性(没有造成永久损伤)导致的软失效(多次检测故障不复现)。
在处理故障时,会进行分层处理,业内有软件主导和和硬件主导两种思想。基于硬件主导的观点,会在器件选型的时候,选择一些质量比较高的硬件,另外,硬件本身具备一些“可靠性”,比如会自动地纠正一些比较简单的错误。
但硬件是没有办法做得非常可靠的,就需要软件去做一些工作。软件定义的方式会把有故障的内存区域隔离出来,让它不再使用,从而不会对业务产生影响。
CE(可以纠正的错误)发生后,如果不去处理它,会有可能变成不可纠正的UE错误。所以要防微杜渐,发生CE(可以纠正的错误)时,要进一步处理,隔离出可疑的故障。
信服云针对内存CE故障隔离方案设计思路
当内存硬件发生CE触发中断,看这些内存能否被隔离(不是被操作系统内核或外设使用),如果可以被隔离就加入白名单,对这些内存进行隔离。当使用内存隔离功能把发生故障的内存页切换到正常的内存页后,就把这个故障内存页隔离出来不再使用。
同时,这些故障发生的位置和次数等详细信息会进行告警,帮助运维人员对故障内存条进行更换。针对没有办法隔离的内存,在系统下次重启时根据重启之前记录的内存错误区域的信息,在系统没有使用这些内存时就把有问题的内存部分隔离出来,这样就保证系统使用的内存是没有问题的部分。
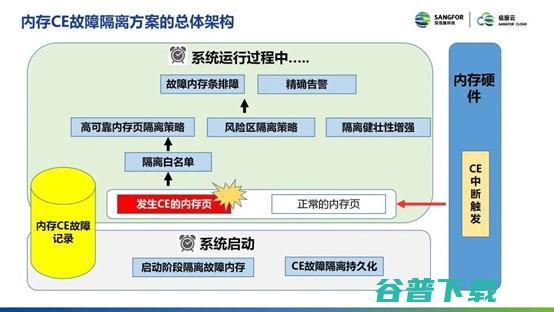
↑ 内存CE故障隔离方案总体架构
信服云实施这个方案之后,通过收集现网运营数据统计,平均隔离成功成功率为96.93%。相较于业界一般的方案的CE屏蔽,不能及时隔离CE以及出错后定位内存条的问题,信服云在方案上具有领先优势,并且在这个领域申请了5项专利。隔离方案在使用过程中针对CPU和内存资源开销小,并且效果明显。
针对内存UE故障,信服云的方案设计思路是解决内存UE的可恢复和提前预警问题,把一部分UE宕机降级为杀死对应应用程序,甚至只需隔离坏页,避免宕机来提升系统稳定性和可靠性。至少提升30%以上内存故障恢复能力,信服云的解决方案能够达到60% 内存UE故障恢复率,效果优于业界公开数据(业界普遍是UE故障恢复能覆盖50%),在实际POC测试场景中,优于业界的一般方案(如一般方案会宕机,无内存故障告警日志,无法定位故障内存所在的插槽位置)。
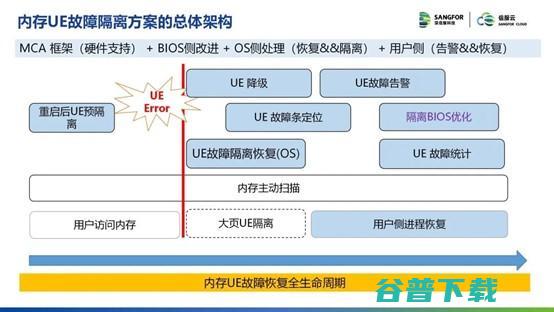
↑ 内存UE故障隔离方案总体架构
三、硬盘的可靠性技术
硬盘主要包括系统盘、缓存盘、数据盘。系统盘一般使用固态硬盘SSD,存放云平台系统软件和主机OS,以及相关的日志和配置。缓存盘一般使用固态硬盘SSD,利用SSD速度快的特性作为缓存盘作为IO读写提速的缓存层,用于存放用户业务经常被访问的数据,称之为热数据。数据盘一般使用机械硬盘HDD,容量高适合做数据盘则作为数据(如虚拟机的虚拟磁盘)最终存放的位置。
(1)硬盘TOP故障模式/分类:
卡死:硬盘IO暂时或者一直不响应;
卡慢:硬盘IO明显变慢或者卡顿;
坏道:硬盘逻辑单元(sector)损坏;
坏块:硬盘物理单元(block)损坏;
寿命不足:机械硬盘物理磨损,或者固态硬盘的闪存颗粒积极达到擦写次数。
当硬盘出现输入输出(Input Output,I/O)响应时间变长,或者卡住不返回的情况,会导致用户业务持续出现卡慢,甚至挂起,一块硬盘卡住甚至会导致系统的全部业务中断。
随着使用年限的增加,硬盘出现坏道、磁头退化或者其他问题的概率也在增加;从历史问题分布、以及业界硬盘可靠性故障曲线,都可以看到硬盘卡盘问题正成为影响系统稳定运行的最严重问题之一。

↑ 信服云卡慢盘解决方案总体架构
(2)信服云针对卡慢盘解决方案的思路:
1.针对磁盘卡慢故障模式复杂的问题,多维度检测确诊。采用了Linux通用的工具和信息,不依赖特定硬件工具,包括内核日志分析、smart信息分析、硬盘io监控数据分析等从多个维度精确定位故障硬盘。
2.针对卡慢盘处置时业务还是数据的抉择,制定了多级隔离算法。①轻度慢盘:不隔离,在页面告警通知用户;②严重慢盘:选择业务:对端异常时不隔离,页面告警通知用户;③卡盘:选择业务:第一次出现对端异常时不隔离,页面告警通知用户;④卡盘(频繁):选择数据:一个小时内出现3次异常,进行永久隔离。
3.在多级隔离算法的基础上进行阈值打磨。用大量真实卡慢盘进行测试以及用户侧采集的数据制定更加精准的卡慢检测阈值;使用故障注入工具进行阈值验证。
开启卡慢盘功能后的效果,可保障1min内触发隔离,虚拟机未出现HA,隔离后业务IO恢复稳定。
以上就是本次直播的主要内容。对云计算感兴趣的IT朋友可以关注“深信服科技”公众号回顾本期直播,了解更多云计算知识。
版权文章,未经授权禁止转载。详情见 转载须知 。


历史,简称“史”,指对人类社会过去的事件和活动,以及对这些事件行为有系统的记录、研究和诠释。历史是客观存在的,无论文学家们如何书写历史,历史都以自己的方式存在,不可改变。

呼和浩特市人工智能学会

成都心理医生,成都棕南心理咨询中心汇聚成都权威知名心理咨询专家医生辅导,提供青少年心理,儿童心理,心理表现,家庭问题,孩子教育,职场人际等心理咨询服务。专业成都心理咨询中心好的选择!

荟萃网库,现有大量注册会员,主要对五金机电行业的企业提供一个发布信息的平台

林芝市人民政府网

荃芬总部位于西安,提供全国上门甲醛检测、甲醛治理、装修后室内空气净化等业务,全国网点500+,服务用户100万+,除甲醛热线:400-081-5586

上海沈德医疗器械科技有限公司

上海朗睿电子科技有限公司是家专业从事工业液晶触摸显示器(串口屏)、平板电脑一体机、彩色串口液晶模块、人脸识别人证比对闸机、多媒体互动广告机监视器等工业液晶显示与控制的开发、生产和技术服务的高科技公司。

风云社官方网站

常州市仪都仪器有限公司(www.yidu17.com)是立足于国内市场,始终站在实验仪器高新技术的前沿,虚心总结国内外仪器行业的生产、销售、服务等先进经验,产品有:双层恒温培养箱,智能振荡培养箱全温恒温振荡器,低温恒温振荡器,大容量恒温水箱,低温水浴箱,本公司不仅具有精湛的技术水平,更有良好的售后服务和优质的解决方案,欢迎来电洽谈

中文导航网,站长导航,网址导航,网站导航,网站大全,网站目录,网站分类,分类目录,网站收录,自动收录,秒收录

济宁公积金管理中心,统一服务电话:12345,可查询业务包括:公积金贷款利率,通知公告,业务指南,新闻动态,服务渠道,网上贷款利率,主任信箱,客服电话,网点查询,党建工作,在线留言,合作楼盘,下载中心,政府信息公开等。


现在网上有很多比较热门的竞技游戏,那么2023好玩的非对称竞技游戏有哪些,在游戏当中玩家可以进行激烈的战斗,而且还可以进行单人多人的PK任务,获得属于自己的荣誉感,今天小编就给大家分享几款好玩的非对称竞技游戏推荐,1、,猫和老鼠,在这里有很多新的游戏角色,而且在游戏地图当中有着丰富的场景,玩家可以进行探索,体验猫跟老鼠追逐的搞笑日常活...。

此前,华为正式官宣了,畅享十周年,新机华为畅享70X,将会在2025年1月3日正式亮相,其中,先锋回归,实力登场,的官宣文案还引发了网友的众多猜测,因为此前华为Mate60系列、华为nova系列皆是通过先锋计划正式开启了5G麒麟芯片的回归,如今,华为畅享70X再次用上这个字眼,大概率也会搭载全新麒麟芯片并支持5G网络,从而实现华为全系...。
最近市面上存在有人通过互联网收集域名信息后,生成域名模板打印邮寄给各个商家和企业,并要求支付证书费用的事情,如果收到域名证书的快递建议直接拒收,域名证书免费下载与打印的教程,以阿里云为例,1、进入并登录阿里云官方网站,点击右上角,控制台,如图1,2、在左侧我的导航记录中,点击,域名,如图2,3、进入域名列表页面后,点击右侧,管理...。

P.s.用创新的拍卖方式帮最好的程序员发现更好的offer招聘程序员对创业公司来说一直是个难题,老罗说,我发现最难的就是我搞不定工程师,他们刀枪不入怎么都不行,感性也不行理性也不行,谈到十个八个我就特别灰心,在跳槽高峰期,申请拍卖,获取你的个性礼包,原创文章,未经授权禁止转载,详情见转载须知,...。

AI、5G、云计算技术的发展已经开始改变世界,数据中心作为承载这些技术,支撑数字化转型的重要载体,面临着众多挑战,这其中,已有的通用CPU和GPU不能完全满足快速变化的应用需求,性能更强大,更加专用,更加异构的芯片更能满足数据中心需求,芯片巨头们都看到了这样的需求和趋势,通过收购或者自研拥有了更全面的芯片类型,雷锋网此前介绍过,在数据...。
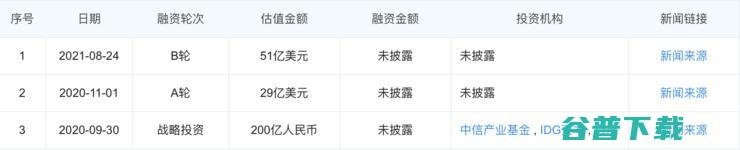
雷锋网消息,8月24日,百度宣布旗下智能生活事业群组业务,以下简称,小度科技,已经完成B轮融资,小度科技此次融资后,投后估值达330亿元人民币,值得一提的是,百度方面并未公开本次融资的投资机构,截至目前,小度科技已进行了三轮融资,其中战略融资和A轮融资发生在2020年9月、2020年11月,对于新一轮融资的完成,百度方面表示,这将对...。

教育科技正在打开新的想象空间,11月30日,腾讯全球数字生态大会智慧教育专场线上开幕,腾讯集团副总裁、腾讯教育总裁殷宇向外界传递了腾讯持续投入教育的信心,殷宇认为,教育科技坚持,教育数字化助手,的定位,坚定助力,高质量发展,的目标,不仅会一直,在场,,而且有机会成长为教育数字化变革的新动能,他表示,腾讯教育将立足于科技优势,持续发挥产...。

传统银行有必要拥抱云原生吗,这个问题,或许还没有太多答案,但这些问题,在传统银行大步向前、业务飞速发展的过程中,一定会遇到,而网商银行就用自身的云原生实践给出了解答,从云平台,分布式架构,演化到云原生、混合云弹性架构,这家被称为,国内首家跑在云技术之上,的商业银行,他们五年来的云化升级历程,所遇到的典型挑战、解决思路都颇具借鉴意义,在...。

发表在其它家用投影仪品牌2023,8,709,19懂影K6是一款家用投影新品,拥有不错的性能配置和画质表现,具体懂影K6投影仪怎么样呢,下面就分享懂影K6的详细参数配置,看看懂影K6投影仪有什么优缺点,是否适合家用,懂影K6投影仪怎么样,1.光学参数懂影K6采用的是LCD技术,有不错的色彩还原度;在亮度方面,懂影K6的实际亮度达到16...。

qq好友复原是指在qq聊天软件中,用户可以在必定期间范畴内复原被删除的好友,当用户误删除或其余要素造成好友被删除后,用户可以经过qq好友复原配置找回被删除的好友,这一配置可以让用户免受误操作的困扰,坚持你和好友之间的咨询,经常使用qq好友复原配置,首先须要进入qq聊天软件,而后在主界面中,点击咨询人按钮,接着,在咨询人页面中,点击设置...。

从头到尾咱们可以发现,片中的外星人都是以一种自愿甚至残酷的形态生存在集中营普通的第九区,感化的变异基因的记者从开局变异到最后的生死关头,协助他的不是咱们人类,而是他们,我不想用它来描画,由于他们确实比咱们人类高一层,凭他们的武器,很容易将人类覆灭,他们却宁愿用武器去换不幸的猫粮,受着人们欺压的生存.而影片的最后,克里斯托弗终究会不会与...。

首先要确认你须要购置二手加工核心是出口品牌还是国产品牌,而后测试加工核心的精度,看丝杆间隙、导轨有没有拉毛、镶条磨损水平等加工核心买全新的好还是二手的好,全新加工核心跟二手加工核心的选用就须要看各人的需求而定了,假设企业因消费战略改变,须要置办加工核心的话,资金必需一时半会没能周转过的,这时选用买二手的就是个不错的选用,像在盘活网买二...。

关于湖南金职伟业集团,湖南金职伟业集团扎根家庭服务领域,致力于构建立体化、多方面的现代家庭服务产业体系,集家庭服务新职业研发与培训、家政高端人才输出、企业管理咨询、一站式现代家庭服务中心商业模式设计于一体,为母婴和养老领域提供服务技术人员培训、管理人员培训、家庭健康培训,为家政企业输出高端技能型、管理型人才,提供企业管理咨询、移动互联...。

语音播放文章内容由深声科技提供技术支持您的浏览器不支持audio元素,随着网络空间的规模和行动不断扩大,其与日常生活日益交织,往往在网络空间一起微小的安全事件可能带来一连串,蝴蝶效应,,譬如去年全球最大的半导体代工制造商台积电工厂意外,中毒,,造成工厂停工不说还连累了要发新品的苹果,三天亏了10亿,而这次煽动翅膀的是D,Link产品的...。

由中国计算机学会,CCF,主办、雷锋网与香港中文大学,深圳,全程承办的AI盛会,全球人工智能与机器人峰会,CCF,GAIR,,将于7.7,7.9日在深圳召开,CCF,GAIR为国内外学术、业界专家提供了一个广阔的交流平台,既在宏观上把握全球人工智能趋势脉搏,也深入探讨人工智能在每一个垂直领域的应用实践细节,延续上一次大会的议题,...。

发表在当贝投影仪2024,4,1816,24当贝D6X是全新上市的配备有一体式云台的投影仪,那么和同样配备有一体式云台的坚果N1Air之间有什么区别呢,下面就通过详细的参数配置进行对比分析,看看当贝D6X和坚果N1Air区别有哪些,哪款更值得用户入手,一、当贝D6X和坚果N1Air有什么区别1.光学参数对比光源方面,当贝D6X和坚果N...。

对于年仅6岁的品牌HTC而言,产业的快速成熟与其自己的逐渐成长就是一场残酷的竞赛,HTC要赢得这个竞赛,从新星成长为真正的产业巨头,需要建立更多真正属于自己的,肌肉,这个世界上,没有哪个行业能够像移动终端行业这般跌宕起伏,残酷到让人背后发凉,去年4月6日,HTC市值冲到了9800亿新台币,折合约337.9亿美元,这一数字超越了诺基亚...。
