EDA 与Jeff 精彩回顾 最佳论文花落伯克利 for 2021 Dean聊ML EDA顶级会议DAC

受新冠疫情影响,近年来多数学术会议都转到了线上进行。延期半年后,此次以线下形式进行的DAC会议给从业者提供了难得的见面与交流机会。而部分作者未能到场的论文将在之后的virtual session进行分享。
除学术交流外,DAC一直以来也是全球EDA工具、Foundry、IP提供商的盛会。在两层的展区中可以看到众多EDA公司提供的精彩展示,其产品内容涵盖芯片设计流程中几乎所有的步骤。在EDA三大家之外的很多名不见经传的小公司的产品也能让人眼前一亮。在展厅中,一些公司甚至使用了飞刀杂耍以及脱口秀式的宣传方式,营造了难得的热闹场面。
作为顶尖的EDA会议,DAC每年所邀请的演讲嘉宾自然而然地成为了全场关注的重点。这次DAC邀请到了不少传奇人物来分享关于EDA行业的研究观点和趋势观察。

第一天, Google大神、Google AI的领导人Jeff Dean,进行了题为"机器学习在硬件设计中的潜力"的主题演讲。近年来,谷歌研究了不少深度学习在EDA方面的应用,其中最著名的是他们去年发表在Nature上的工作,通过强化学习自动进行macro placement,并真正应用于Google的硬件加速器TPU的设计过程。
Jeff在演讲中提到了Google使用深度学习优化整个芯片设计流程的工作,主要分为三个部分,对于芯片设计的三个主要阶段。如下图所示,演讲包括使用深度学习加速1.架构搜索和RTL综合,2. 验证,3. 芯片布局绕线。
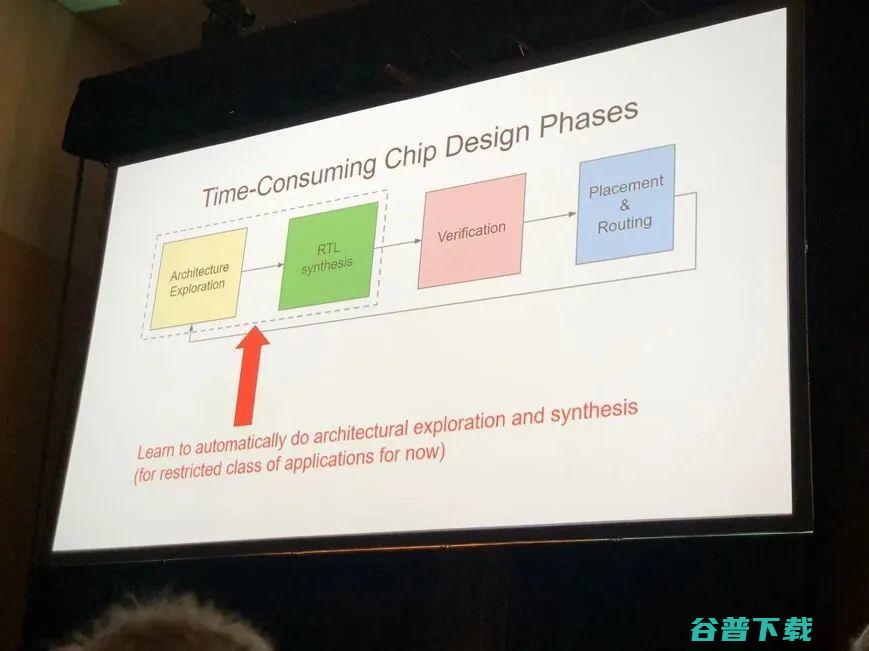
在架构搜索阶段,Google提出了叫做FAST的架构自动对硬件加速器的设计进行优化,他们使用了Google自己的黑盒优化器Vizier进行搜索。对于验证阶段的工作,Google提出了使用图神经网络(GNN)对RTL阶段的芯片设计进行分析处理。对于布局布线部分,重点自然就是发表在Nature的macro placement工作。
正式Keynote结束后,我们也和Jeff就ML for EDA进行了讨论。Jeff肯定了现有的商业EDA工具的表现。当我们问到在EDA方面,是否直接生成结果的强化学习方法将会取代仅进行预测的ML模型时,他认为两者在未来都将发挥重要作用。

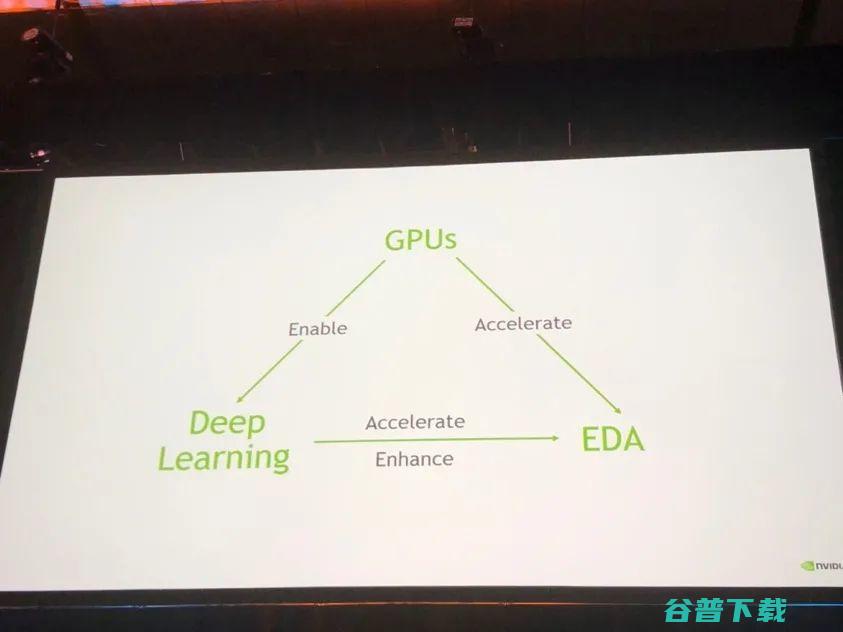
第二天的keynote演讲者是Nvidia首席科学家Bill Dally,他的演讲题目为”GPUs, Machine Learning, and EDA“。Bill Dally的演讲结构清晰,概括了Nvidia如何使用GPU帮助ML,同时如何用GPU和ML帮助EDA发展。
GPU对于ML的促进作用是大家最为熟悉的,Bill首先介绍了GPU对深度学习的架构优化与Nvidia开发的深度学习加速器。而近年来出现了不少使用GPU加速解决EDA问题的工作,最著名的就是19年由UT Austin与Nvidia合作,同时获得DAC与TCAD最佳论文的DREAMPlace。Bill也提到了用GPU加速timing simulation。
在ML for EDA方面,近年来Nvidia也做出了大量工作,包括使用不同ML模型对IR drop、功耗、寄生参数进行预测。除了这些预测工作,Nvidia也提出了NVcell,使用强化学习方法直接生成优化的standard cell设计。纵观整个keynote,可以说在Bill的领导下,Nvidia Research对EDA方面的科研工作是比较充分的。

第三天的keynote演讲者是EDA传奇人物、Cadence第一任CEO Joe Costello。他的演讲技术内容较少,主要从商业角度鼓励EDA业界拥抱变化。谈到的变化包括使用云计算平台,使用新的商业模式,使用开源生态系统,支持后摩尔定律时代的架构设计,以及熟悉政策变化。
另外值得一提的是,他大力批评了美国政府对中国的贸易战以及半导体产业的制裁,认为这反而激发了中国对支持半导体产业的共识与巨额投资。他表示由于中国近年出现的上千家硬件初创公司,五年之后中国将成为EDA的最大市场。
第四天的keynote由UC Bekeley教授, SqueezeNet的作者Kurt Keutzer提供。他的演讲主要回顾了深度学习的发展史,同时区分了人工智能,机器学习,和深度学习的概念。他鼓励EDA从业者在应用和模型层面探索高效率的ML方法。
除了正式的keynote,DAC还提供了三场skytalk,类似于较小规模的keynote。第一天由微软Azure介绍他们为芯片设计与ML提供的云服务。他们认为云计算在安全和扩展性上展现了巨大优势。第二天由IBM介绍他们在深度学习加速器方面的探索,尤其是超低精度下的模型训练和预测方法。第三天由AMD介绍先进封装技术,例如chiplet对于未来计算硬件的重要性。
另外,大会也邀请了各大公司通过大量的presentation和poster来分享他们最新的研究进展和趋势观察。这种学界与工业界的紧密结合与交流体现了EDA行业的特点,同时也是DAC会议的优秀传统。
本次DAC一共收录了215篇研究论文,涵盖的内容非常广泛。受篇幅所限,我们只能够对获得最佳论文与提名的文章进行简单介绍。在本次线下活动中,共有三篇论文获得最佳论文提名。
UC Berkeley的"Gemmini: Enabling Systematic Deep-Learning Architecture Evaluation via Full-Stack Integration"榜上有名。这篇文章作者众多,也可以看出充分的工程投入。值得一提的是,该工作也成为了UC Berkeley基于risc-V的硬件开源生态chipyard的一部分。而这个生态也包括著名的Rocket Chip以及Chisel。

根据文章介绍,大部分已有的深度学习硬件的生成器(generator)只考虑加速器本身的性能,而没有考虑整个系统层级的性能。
本文提出Gemmini,这是一种开源的全栈式DNN加速器设计框架。使用Gemmini生成的硬件加速器已经被成功流片,并且取得了与商业加速器NVDLA接近的性能。在Gemmini中,设计师不仅能选择不同的加速器结构,同时也能配置整个搭载了加速器的基于RISC-V的SoC,并且这个SoC提供软件支持。设计者可以在OS上直接运行需要优化的DNN应用。
文章最后提供了两个使用Gemmini的进行设计的例子,分别是探索虚拟地址转换的设计方式,与探索内存资源的分配方式。
除此之外,获得最佳论文提名的还有Maryland University的"A Resource Binding Approach to Logic ObfUSCation"。

根据文章介绍,设计者为了保护IP设计,避免恶意的foundry对IP进行窃取或者逆向工程,需要引入额外的设计给IP上锁,使得IP的功能取决于设定的密码。这个过程叫做logic locking或者obfuscation。然而,现有的方法无法兼顾多种安全需求。
为了解决这一缺陷,相比于多数在gate-level才进行上锁的工作,本文提出在更高层的high-level synthesis的resource binding步骤中,利用架构层面的知识来对整个IP进行上锁。结果表明,通过对binding与上锁进行协同设计,这种方法获得了上锁效果的巨大提升。
另一篇获得最佳论文提名的是UT Austin与Intel合作的"DNN-Opt: An RL Inspired Optimization for Analog Circuit Sizing using Deep Neural Networks"。

文章提出了一种高效的对于模拟电路进行gate-sizing优化的方法。借鉴于强化学习方法,作者同时训练了两个深度学习模型,其中critic-network负责评估每一次gate-sizing的效果,而actor-network负责选择效果最好的sizing方式。但这种方法依然是监督式学习而并不是强化学习。
另外为了减小搜索空间,文章提出了分析每种优化操作对于最终目标的影响(sensitivity)。对于影响小于阈值的优化操作不进行搜索。实验证明,无论在是较小的电路设计还是大规模工业界的电路设计中,本文的方法都能大幅减少需要的搜索次数,对应更少的设计时间。
版权文章,未经授权禁止转载。详情见 转载须知 。



北京京海佳业科贸有限公司是优质的高精度超声波测厚仪,超声波多层涂层测厚仪,梅特勒/岛津实验室电子天平,多参数水质检测仪,德国视得乐望远镜供应商,主要经营产品有:高精度超声波测厚仪,超声波多层涂层测厚仪,梅特勒/岛津实验室电子天平,多参数水质检测仪,德国视得乐望远镜!

意表截屏识别各种类型表格,结果识别到剪贴板。程序常驻状态栏,支持快捷键操作。

小米应用商店提供微顶跑腿免费下载,微顶跑腿陪您早餐到晚餐 微顶跑腿点外卖找跑腿寄快递 微顶跑腿点外卖找跑腿帮送帮买一个APP高效生活 方便简单的同城生活服务APP 【

爱站网短链生成器可以根据用户提交的URL进行相对应的缩短域名,做到有效地隐藏真实地址。

无锡市兰博试验设备有限公司位于无锡市惠山区钱桥街道钱桥高新技术产业园内是一家专业生产、开发模拟各类环境试验设备及非标设计与自动化控制等方面的高科技生产型企业,依托荣氏家族,由同济大学,扬州大学,东南大学教授和专家领衔成立,因为专业,所以卓越,兰博科技在同行业迅速崛起,成为中国同行业新兴的知名企业,在国际上亦有相当声誉。

私域代运营,新媒体代运营,全域代运营,社交媒体代运营,内容营销代运营,电商代运营,品牌代运营服务,数字营销代运营,私域流量增长代运营策略,新媒体平台(如微信、抖音、小红书)代运营方案,全域营销代运营案例分享,企业私域社群代运营服务,新媒体内容创作与发布代管,提高电商店铺转化率代运营,品牌社交媒体形象塑造代运营,数据分析驱动的代运营服务,中小企业私域代运营解决方案,全渠道营销策略规划与执行代运营

九九戏曲网主要内容是戏曲大全,包括京剧名家名段,豫剧全场戏,河南戏曲,黄梅戏大全,越剧全剧,秦腔全本戏,晋剧全本戏,民间小调全集,河南坠子大全,二人转正戏,琴书大鼓书等,也有戏曲视频的知识学习。

拥抱电脑系统的每一次更新,共享科技资讯的盛宴。

系统搭建平台

创客匠人通过科技技术赋能、陪跑孵化IP、线下大课赋能、圈子联盟共创等360°全方位立体服务,一站式解决知识IP变现难题。助力知识IP做好知识变现、拓客增长,让好老师走进千家万户,让知识变现不走弯路。

php语言开发的免费开源建站系统

安徽精工电缆桥架有限公司是主要从事电缆桥架、母线槽、槽式桥架、梯式桥架、组合式桥架、托盘桥架、大跨距桥架、防火桥架、母线槽、玻璃钢桥架、铝合金桥架及其配套产品的研发、制造和销售。


4月15日消息,康佳电视宣布将于4月18日下午14时举行康佳APHAEA春季战略新品发布会,而在宣传海报中,康佳APHAEA和锤子的logo被连接在同一圆圈中,锤子SmartisanOS官方也表示,,在探索创新的途中,我们有幸遇到了志同道合的伙伴,几天后,一款我们打磨许久的新品将在合作伙伴的硬件上和大家见面,康佳APHAEA新品电视...。

位于华东地区的无锡,是江苏省内的一个地级市,同时也是长江三角洲经济中心的重要城市之一,自从长江三角洲经济设计和开发以来,无锡的经济实力一直都在提升,2020年的区域生产总值已经超过了12000元人民币,无锡加盟业务发展的如火如荼,很多有商机的项目等着你来挖掘,那么,无锡加盟店排行榜都有哪些品牌,衣食住行是生存不可缺少的产品,美食自然是...。

发表在哈趣投影仪2024,1,1715,13年关将近,年货节火热进行中,不少投影产品纷纷提供大降价,那么2024哈趣年货节有优惠吗,答案是有的,哈趣投影仪在2024年货节有了不小的优惠,同时还有丰富的赠品,正是入手的好时机,下面就分享2024哈趣年货节的具体活动情况,2024哈趣年货节时间,2024年1月17日晚8点正式开始2024哈...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为小马CPA日付广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在小马CPA日付广告联盟网站...。

每经记者杨弃非决堤近77小时后,7月8日22时31分许,湖南省岳阳市华容县团洲垸洞庭湖一线堤防决口实现合龙,洞庭湖是我国第二大咸水湖,接管湘资沅澧,四水,、吞吐长江,是长江流域最关键的洪水调蓄湖泊之一,相关到长江中下游抗洪大局,同时,洞庭湖自身有长达3471公里的堤防、大小堤垸226个,是湖南防汛抗洪的,主战场,从往年6月16日到7...。

每日检查星座运势已成为很多人的日常之一,而腾讯星座每日运势查问则是一个备受欢迎的工具,作为一个片面、精准的星座占卜平台,腾讯星座每日运势提供了十二星座每天的恋情、事业、财运等运势剖析,不只仅提供文字形容,它还经过幽默的GIF图和星座配色来出现每个星座不同的命运,点击进入腾讯星座每日运势查问,你便可以选用自己的星座,检查今日的运势,除了...。

外观方面,本田锋范这款车的外观相对十分的显得年轻时兴,只管全体的车身小了点,然而相对是十分的耐看的,颜值十分的犀利,而且车身的线条十分的刘畅,十分的难看,相对是十分的适宜年轻人或许是小两口经常使用的,本田锋范还是有个致命的缺陷,也是一切的日系车都有的缺陷就是,车漆薄,车漆薄,车漆十分的薄,带给人不了安保感,内饰方面,本田锋范的内饰...。

1驭胜S350的马力区分可以到达141PS204PS220PS2驭胜S350是江铃汽车推出的车型之一目前有8和2020款在售豫S350车身尺寸4710mm1895mm1845mm,轴距2750mm,5门5座SUV,油箱容量67L发起机排量1997ml;驭胜s350是江铃汽车推出的一款中型SUV,官方指点价为万元能源方面,这款车推出了两...。

environment英[ɪnˈvaɪrənmənt]美[ɛnˈvaɪrənmənt,ˈvaɪən,]n.环境,外界,周围,围绕,上班平台,运转,环境双数,environments形近词,entironment1TheplanswillbeexaminedbyEUenvironmentministers.欧盟各国环境部部长将细心钻...。

在艾尔登法环这款游戏中一共有10个地图碎片,不过很多小伙伴们并不清楚其位置,那艾尔登法环地图碎片在哪?本期的新游资讯就为大家详细盘点一下这10个地图碎片的位置,有需要的小伙伴们快来看看吧~艾尔登法环地图碎片位置分享1、揭示Dragonba

外交部:中方将依法对长期插手涉藏问题的美方人员对等采取签证限制,外交部,汪文斌,签证,涉藏,内政

㊙️私藏起来不想给苏东坡的红烧肉的做法,㊙️私藏起来不想给苏东坡的红烧肉怎么做请看步骤:1.材料预备备。 五花肉切块块~把它十字捆绑起来2.冷水下锅,下葱段,煮开后转中小火煮5分钟3.煮好,捞出洗净。 再次下锅,淋入酱油、老抽、料酒组合...
官方规范后,一方面算是给出了今后的明文规定指引,另一方面其实也算是做了解答,目前中国主播账号总数已经突破了1.3亿个,这相当于每10个中国人里,就有一个曾经做过主播,而几个头部直播都被禁言或停播,微娅,李佳琦,老罗等各大平台的头部主播都不见了,在,网络主播行为规范,里其中最迷惑的就是,对社会热点和敏感问题进行炒作或者蓄意制造舆论热点,...。

最坚决推行Linux桌面系统项目的城市正在转回Windows阵营,但Linux的命运已经不再与PC休戚相关,慕尼黑的Linux项目只是开源软件故事中的一小部分,在实施从Windows系统迁移到Linux系统这一项目接近十年之久后,慕尼黑却突然走上了一条戏剧性的转弯,据说是到2021年,该城市的地方议会就会开始用Windows10替换运...。

章鱼烧这种独特的美食,近两年在国内卖的特别的火,很多加盟商看中章鱼烧的商机争相寻找好项目加盟,可是章鱼烧哪个牌子好呢?这是选择项目时让加盟商头痛的一个问题,找项目首先要看品牌影响力和商机,在众多项目中符合要求的是和米堂章鱼烧,到底和米堂章鱼烧怎么样呢?一起看一下,章鱼烧哪个牌子好?和米堂章鱼烧是很好的选择,和米堂章鱼烧在进军之前,已经...。

机器人教育是当下的一个热门,越来越多的家长为孩子报名了机器人,机器人培训行业有发展空间,有市场前景,是创业的不二之选,慧乐思机器人市场口碑好,而且运营模式成熟,加盟很安心,那么,慧乐思机器人怎么加盟,营收怎么样,慧乐思是一个有关机器人方面的教育培训品牌,这个教育培训品牌公司位于北京,品牌公司推出这个机器人教育品牌已经有十几年的时间了,...。

青书课堂作为一款广受好评的学习软件,学生不仅能在这里自由学习各种课程,掌握更多章节知识点,同时也能方便教师更好的进行管理,那你知道青书学堂在哪开启悬浮窗权限吗?下面小编就为大家带来详细操作方法,一起来看看吧,...。
