多模态的方法 看懂 手语 专访纽约城市大学田英利教授 用多通道 (多模态的方法有哪些)
与聋哑人交流,是一件成本很高的事情。
首先要看得懂手语,其次是会打手语。在全球任何一个国家,手语都被归属为一门“小语种”。
但全球手语并非一套通用语言,美国手语(ASL)、泰国手语(ThSL)、英国手语(BSL)、中国手语(CSL)......虽然在某些情况下它们可以互相理解,但这并不等同于手语语言的普遍性。
全球约4.5亿的聋哑人士,长期困在狭小社交圈。在过去三年的全球防疫中,这种社交限制被进一步强化。
口罩会影响每一位聋哑人——依赖手语的他们还需要面部表情来充分理解交流内容,佩戴助听器或人工耳蜗的人也依赖唇读来更好地理解听到的内容,即便只是听说功能受损的人也更难听到蒙住的声音。
因此,手语在高等教育中的重要性日益凸显。从2006年到2009年,美国手语在大学的学习人数显著增加了16.4%,在最受欢迎的外语学习中排名第四。然而,对于更广泛的社会群体而言,仍然无法受益于一种灵活的方法培养手语技能。
众所周知,2023年,ChatGPT的出现为沟通方式带来了革命性的变革。
ChatGPT通过多轮对话的形式,实现了与人类的协同交互,这是与以往现象级AI产品完全不一样的地方。比如,通过简单的插件安装,用户便能与ChatGPT展开近乎真实的对话模拟。ChatGPT不仅能够理解用户的意图,还能提供即时的反馈和纠错。在缺乏外语母语交流伙伴的情况下,ChatGPT是一个理想的替代者,被广泛用于模拟日常对话、商务会议、求职面试等场景。
实际上,ChatGPT所引领的学习和交流方式的变革并非突如其来。在手语交流辅助工具的开发上,学术界早已取得了显著成就。
2014年开始,纽约城市大学(CCNY)田英利教授,联合国际知名手语计算专家--罗切斯特理工大学的Matt Huenerfauth教授,着手开发一个能够实时识别美国手语中语法错误的视觉系统。相关研究成果和手语数据集在2020年亮相计算机视觉领域顶级会议ICPR(模式识别国际会议)。

田英利,纽约城市大学教授,IEEE / IAPR / AAIA Fellow
据悉,他们开发的这套是美国手语语法识别系统,旨在实时识别手语并为学习者提供即时反馈。应用价值不仅体现在辅助手语学习上,更在于其能够无缝集成到计算平台中--通过检测手语动作并翻译成文字或语音,为听障人士与非听障人士之间的沟通搭建桥梁,有效消除交流障碍。
近期,相关论文之一《Multi-Modal Multi-Channel American Sign Language Recognition》,作为首期特邀论文上线初创期刊《人工智能与机器人研究国际期刊》(IJAIRR)。借此契机,田英利教授向介绍了该系统的开发过程,并详细介绍了背后的数据集收集工作。
论文链接:
手语识别的难题
相比于类型繁多的口语语言,手语的特别之处在于,这是一种充满表现力的视觉语言,它通过手势、面部表情和身体动作的组合来传达信息。
自20世纪80年代以来,学者们就开始探索手势识别,而手语识别的研究则稍晚起步,1988年,日本学者Tamura和Kawasaki首次尝试识别日语手语。
随着多功能感知、智能人机接口和虚拟现实技术的发展,手语识别研究逐渐受到国际关注。目前,手语识别系统主要分为基于传感设备(如数据手套和位置跟踪器)和基于视觉的系统。
相比而言,虽然传感设备提高了手势识别的准确度和稳定性,但限制了手势的自然表达。因此,基于视觉的手势识别逐渐成为研究的主流。
基于视觉的手语识别通常包括三个步骤:
首先,通过摄像头或传感器捕捉手语动作,建立训练数据集;
其次,利用计算机视觉技术分析和识别手语动作;
最后,通过机器学习算法将识别结果转化为文字或语音输出。
然而,第一步中的遮挡、投影和光线变化等因素,使得基于视觉的方法难以精确捕捉手指动作。直到近年来,成本效益高的RGBD相机,如微软Kinect V2(2013年发布)、英特尔Realsense(2014年发布)和ORBBEC Astra Stereo S(2019年发布)的出现,为捕捉高分辨率RGB视频、深度图和实时跟踪骨骼关节提供了可能,推动了基于RGBD视频的手语识别研究。
尽管如此,现有的手语识别系统仍存在诸多缺陷。
一些系统仅关注手势,忽视了面部表情和身体姿势,限制了其适应性、泛化性和鲁棒性;
另一些系统虽然分析了多种姿态,但缺乏深度信息,导致识别率不高;
还有的系统虽然基于RGBD视频,但只识别有限的手语词汇。
纽约城市大学的田英利教授指出了两个原因:现代机器学习方法主要依赖数据驱动,但公开发布的手语数据集规模远小于其他应用的数据集。其次,手语动作的多样性和复杂性,也增加了动作捕捉和算法设计的难度。
例如,手部动作的微小变化可能导致完全不同手语的符号表达;即使手势相同,面部表情的差异也能改变含义;重复的手势可能增加额外的含义;而照明、背景和相机距离等环境因素也增加了识别的难度。
理想的手语识别系统应能处理所有手语词汇,满足使用者的实际需求,并能在复杂环境下实时、准确、可靠地工作,同时面向非特定用户。尽管手语识别技术尚未成熟,但随着研究的深入,这一目标正逐步接近现实。
美国手语研究新篇章:数据集与识别技术的协同进步
美国手语(ASL)在全球范围内具有重要地位,不仅在美国、加拿大等国家广泛使用,而且与泰国手语、法国手语等有着较高的互通性。在美国,美国手语是一种标准化的手语,不同州之间的差异通常很小。因此,ASL成为了众多研究团队的首选研究对象。
田英利教授指出,ASL的表达不仅依赖手势,还涉及面部表情、头部和身体动作等非手部信号,这些元素共同构成了ASL的丰富表达。
具体来说,大多数手语手势都是由手在空间中移动、停顿和改变方向组成的,面部表情在美国手语中最常用于传达整个句子或短语的情绪信息。例如通过眉毛、眼睛张大的表情来表示疑问;身体动作和手势的指向也可以用来表达“左边”或“右边”这类概念;具有消极语义极性的符号,如NONE或NEVER,往往伴随着轻微摇头和鼻子皱纹的消极面部表情出现。

2014年以来,田英利教授与罗切斯特理工学院的Matt Huenerfauth教授合作,基于RGBD视频技术开发了一套创新系统,旨在提高ASL语法元素和语法错误的识别准确性。这一系统能够处理连续ASL视频中手部手势与非手部信号之间的复杂关系。
经过数年筹备,他们所开发的这套ASL系统已有突破性进展。据田英利教授介绍,ASL-100-RGBD数据集、ASL-Homework-RGBD数据集、实时手语语法错误识别系统,是实现这一进步的关键。
ASL-100-RGBD数据集:研究的基石
ASL-100-RGBD数据集由罗切斯特理工学院和纽约市立大学的研究人员共同创建,它包含了100个ASL手势的彩色和深度视频(RGBD视频)。这些视频由流利的ASL使用者在Kinect V2传感器前表演,为手语识别算法的开发提供了宝贵的基础资源。
田英利教授强调,在收集数据时,团队确保了参与者的多样性,招募了不同性别、年龄和背景的流利ASL使用者。而且所选择的100个ASL常用手势,其中大多数与美国手语语法有关(例如时间、问题、条件等语法元素),而且通常在大学一年级的ASL课程中学习。每个手势都被详细地标注,包括开始和结束的时间,以及相关的面部表情和头部动作。
ASL-Homework-RGBD数据集:教育与研究的桥梁
ASL-Homework-RGBD数据集进一步扩展了研究范围,它不仅包含了流利手语者的视频,还涵盖了正在学习ASL的非流利使用者的表现。
这种多样性使得研究者能够对比分析流利与非流利手语者的差异,从而更好地理解学习过程中的变化,改进教学方法,并开发出更精确的手语识别系统。此外,数据集还可以作为CV研究人员设计算法的基准,以检测视频中的手语错误或评估连续手语识别算法性能。
实时手语语法错误识别系统:技术的应用
实时手语语法错误识别系统,将ASL-100-RGBD和ASL-Homework-RGBD数据集的研究成果应用于实际教学中。这个系统能够处理连续的手语视频,自动识别语法错误,并为ASL学习者提供即时反馈。
它利用3D-ResNet网络独立识别手语的语法元素,并采用滑动窗口方法检测不同模态的语法元素的时间边界,有效识别ASL语法错误。
田英利教授提到,使用滑动窗口技术来处理长句子,这是一种在视觉和图像处理中常见的方法。他们的研究创新之处在于结合了多个模态和多通道的信息,即,手部动作、表情、身体语言以及颜色和深度信息(RGBD信息)来识别语法错误,而不是识别每一个字。
也就是说,无需逐字翻译,而是专注于语法错误,包括时间、问题、条件等语法元素。 (更多细节可阅读论文原文,在文章底部参考资料)
测试显示,这一系统能够在2分钟内,为时长1分钟的ASL视频生成反馈,这对于手语学习者来说极其宝贵。
更重要的是,ASL-100-RGBD和ASL-Homework-RGBD两大数据集,均已在Databrary平台上向授权用户开放,将为未来更多从事手语研究者提供了必要的训练和测试数据,推动整个研究领域的发展。
The ASL-100-RGBD>The ASL-Homework-RGBD>
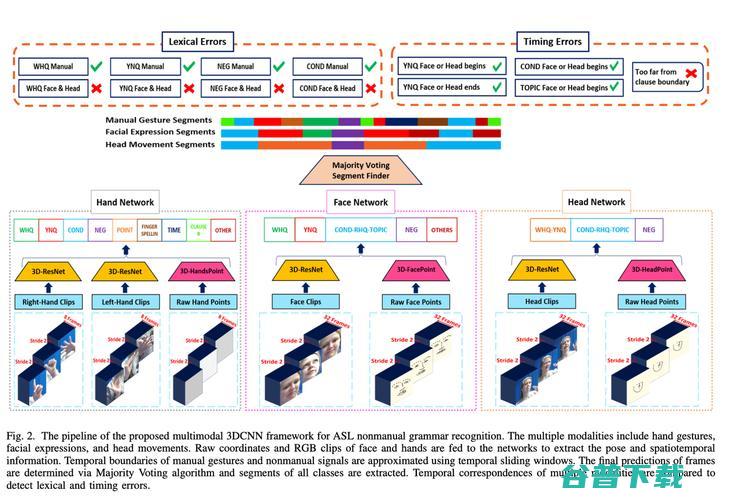
多模态3DCNN框架的概述图
尽管如此,田英利教授仍然指出了目前数据集和系统的局限。
ASL-100-RGBD数据集所选择的100个手势,主要集中在有关手语语法;参与者的人口统计信息可能无法完全代表ASL使用者的多样性,因为参与者主要是年轻人,他们属于能流利使用美国手语的一类群体并且都有六年以上使用手语的经验。对手语使用者来说,主要差别包括“听力损失程度”、“教育背景”、“美国手语流利程度”。
此外,目前这一系统在ASL-100-RGBD数据集上手语的识别率达到93%的准确率。在不用识别每个单独手势前提下,对多个连续手语句子,ASL语法错误识别率超过60%,包括识别词汇错误(如缺少适当的面部表情或头部动作)和时间错误(如非手部信号发生的时间与句子结构的开始或结束太远)。
无论如何,这些研究成果已经为ASL研究和教育技术的进步奠定了坚实的基础,未来或将出现更多元的解决方案,并推动手语商业化时代到来。
在美国手语(ASL)研究课题中,跨学科团队合作发挥着至关重要的作用。
纽约城市大学的田英利教授带领的研究团队,包括她的学生 Elahe Vahdani 和 Longlong Jing 、罗切斯特理工大学的 Matt Huenerfauth 教授,以及亨特学院的Elaine Gale教授,共同致力于手语语法系统和算法的研究和开发,以及数据集的设计和收集工作。
Matt Huenerfauth博士,毕业于宾夕法尼亚大学计算机系,专攻计算语言学。自2006年博士毕业以来,他一直专注于手语计算研究,不曾变换研究方向,如今已成为该领域的国际知名专家。
据悉,他曾在纽约城市大学皇后学院任教期间掌握了美国手语,并取得了手语翻译员证书。目前他在罗切斯特理工学院(RIT) 任教,担任Golisano计算机与信息科学学院的教授和院长,围绕聋哑人无障碍技术和手语展开研究。

田英利教授、Elahe Vahdani 、Longlong Jing、Matt Huenerfauth 教授、Elaine Gale 教授
田英利教授则拥有扎实的计算机视觉技术背景。她于1990年从天津大学光电工程专业毕业后,加入了马颂德教授创立和领导的中科院自动化所模式识别国家重点实验室。在获得香港中文大学博士学位后,她前往美国卡内基梅隆大学进行博士后研究,师从计算机视觉领域的领军人物金出武雄。
(有关田英利和金出武雄的故事请点击:金出武雄和他的中国学生们,计算机视觉五十载风云)
那段时间,她专注于人脸表情自动分析和数据库开发。2000年前后,人脸表情识别成为美国计算机视觉领域的热点,田英利的工作为她在IBM T. J. Watson研究中心领导视频分析团队奠定了基础。
2008年,田英利教授回归学术界,加入纽约城市大学电气工程系,成为该系十多年来的第一位女性教授。她在那里开创了辅助技术研究方向,致力于利用计算机视觉技术服务于视障、听障、聋哑和老年人等特殊群体。
田教授表示,她首先关注了盲人,很自然地将研究重点延伸到了手语识别,因为手语包含了表情、行为和手势,这些都与她之前的研究紧密相关。
此外,田教授还表示,近年来她参与的跨学科研究不断增加,与同校计算机系的朱志刚教授、同系肖继忠教授(机器人专家)、亨特学院的Elaine Gale教授等合作。Elaine教授是本次手语课题的关键参与者,她是一位后天失聪者,精通唇语,并在手语教育方面有着丰富的经验。她将这套系统应用于自己的课程中,确保了系统在实际教学中的有效性。
值得一提的是,近两年OpenAI发布的ChatGPT和Sora,将「大模型」技术推到制高点,不乏有人呼吁推出“手语语法识别通用大模型”。
对此,田教授分析,未来手语领域的研究方向可能会涉及大规模数据集的构建。也就是说,未来的系统开发不仅仅针对一种手语,而是考虑将不同国家的手语数据集整合起来,提取手语的通用特征,然后在特定的手语上进行微调,以提高系统识别的精度和适应性。
但至于实际走向如何,田教授指出有两大挑战:
“手语领域缺乏像ChatGPT那样的大规模数据集,这限制了手语识别模型的通用性和准确性;手语不像某些语言模型,可以通过大规模数据训练后就能通用,手语在不同国家有着特定的词汇和表达方式,这使得创建一个通用的手语识别模型变得更加复杂。”
目前田英利教授和团队所开发的这套系统,并非基于大模型,因为所使用的数据量相对较小,而且他们的手语识别系统是在大模型概念出现之前就开始的。他们正在探索使用自监督学习来利用现有数据学习特征,并将其应用于小数据集上,以提高系统的性能,同时也计划收集更多的数据来改进手语识别系统。
在手语辅助系统的领域内,仍有许多技术挑战亟待克服。在这一背景下,田教授团队开放数据集的做法显得尤为关键。这将促进学术界与工业界的交流合作,也为整个领域的发展注入了新动力。
线上圆桌预告
手语识别技术,作为一种桥梁,连接了听障人士与社会的沟通,其在医疗辅助和社交互动中展现出巨大的应用潜力。
尽管全球众多学术和工业团队长期致力于破解手语识别的复杂挑战,这一领域仍面临着一系列未解之题。
手语识别的关键难题有哪些?
如何从零开始构建并部署一套高效的手语识别系统?
如今 ChatGPT ,Sora 等大模型对手语识别研究的启示?
除了计算机视觉(CV)技术,还有哪些技术路径可以探索?
在国内外,哪些学术团队和工业团队在手语识别领域取得了显著成就?
为了深入探讨这些问题, 将在3月举办一场专题研讨会 ,届时将邀请田英利教授以及手语研究领域的专家学者,共同分享他们的见解和研究成果。这次会议将为手语识别技术的未来发展提供宝贵的交流平台。
本文作者 吴彤 长期关注科人工智能、生命科学和科技一线工作者,习惯系统完整记录科技的每一次进步,欢迎同道微信交流:icedaguniang
参考资料
1,Elahe Vahdani、Longlong Jing、Matt Huenerfauth and Y. Tian, Multi-Modal Multi-Channel American Sign Language Recognition, International Journal of Artificial Intelligence and Robotics Research (IJAIRR), 2023.
2,E. Vahdani, L. Jing, M. Huenerfauth, and Y. Tian, Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos, International Conference on Pattern Recognition (ICPR), 2020.
3,S. Hassan, L. Berke, E. Vahdani, L. Jing, Y. Tian, and M. Huenerfauth, An Isolated-Signing RGBD target="_blank">转载须知。



PR值全称为PageRank(网页级别),取自Google的创始人LarryPage。它是Google排名运算法则(排名公式)的一部分,PR查询可以根据域名查出对应网站(可查内页)的PR。

百度文库

珠海市逸仙堂医药有限公司成立于2020年4月27日,面积80平米,现有执业药师3名,营业范围包括西药,中成药,医疗器械,日用百货,保健食品等。

“新农村”网站客户端是在深入贯彻十四五规划、十九届五中全会以及2020年中央农村工作会议关于“优先发展农业农村,全面推进乡村振兴”的精神指引下应运而生的一款以“党建引领数字乡村”为核心价值观,致力于打造践行三农使命,服务乡村振兴,专注于人才赋能乡村振兴的新生态互联网新媒体客户端。

集研发、生产、销售、服务于一体,专注于AR体感人机交互和人工智能领域研发与制造,成为继微软和苹果之后全球第三家完全拥有体感各项技术知识产权专利的高科技公司

红翼前锋

拉卡拉智能POS机安全可靠,费率低,办理简便,办理拉卡拉POS机,享受更多优惠!拉卡拉提供多款智能POS机,包括大POS、小POS、蓝牙POS、手机刷卡器等。安全便捷快速实现移动收款。了解拉卡拉POS机办理及费率,即刻申请拉卡拉个人移动POS机,满足您的支付需求。

永锋集团有限公司始建于2002年8月,现有员工11000余人。公司主要从事钢铁冶炼、地产置业、市政服务、金融投资、贸易物流、文化旅游、颐养养生、教育产业等。

京津冀新闻网是围绕京津冀一体化、面向京津冀地区网民的地方门户,提供新闻资讯包括城市新闻,北京新闻,天津新闻,河北新闻,石家庄新闻,唐山新闻,秦皇岛新闻,邯郸新闻,邢台新闻,保定新闻,张家口新闻,承德新闻,沧州新闻,廊坊新闻,衡水新闻等多种类型资讯。

宁波市江北慈城不锈钢拉丝厂供应材料用途广泛,主要适用于五金轴承料、铆钉及空心铆钉料、洗衣机法兰、管料等。

填写站点描述


在城市中呆的太久想要感受一下农场庄园的悠闲田园生活吗,想体验要种植、钓鱼、养殖等等农场的乐趣吗,下面带来农场小游戏有哪些好玩推荐2021,人气农场小游戏的前十名排行榜合集,这些游戏中都是以农场、庄园为游戏背景,玩家可以在其中种植、饲养、交易等等,运营自己的农场庄园,体验真正的悠闲田园时光,一起来看看吧,...。

众所周知,阿里巴巴有自己的花名文化如马云叫风清扬,张勇叫逍遥子,陆兆禧叫铁木真等等而高晓松入职阿里巴巴的时候,也被要求起一个花名高晓松觉得很为难,因为这么多年,好听的花名基本都已经被用完了想了很久,高晓松想到一个,肯定没人用过第二天到公司说我给我自己起的花名叫田伯光当即就被驳回,理由是阿里的员工怎么能用一个淫贼的名字呢高晓松辩解道,我...。

2017年,是CAMELKING美国骆驼品牌发展和升级为快速的一年,在时尚女包包的市场上进行了新的探索和升级,也在营销上有了重要举措,尤为关键的一项举措就是对女包进行了撤头换脸的改变,多方面对女包进行全面的提升,从产品的款式、质量、工艺等对都作出重大的举措,势必要打造更好的更潮流的产品,让品牌形象更深入人心,CAMELKING美国骆驼...。
自1895年卢米埃尔兄弟的,火车进站,诞生以来,投影仪就成为了电影的最佳载体,无数电影人通过投影仪向全球观众展示自己的才华,执导过,发条橙,、,2001太空漫游,等众多影史经典的,电影之神,库布里克,甚至还亲自参与改装投影仪,经百余年发展,电影从黑白无声进化到彩色有声,从2D进阶到3D,投影仪的光源也随之不断进化,从最初的一盏煤油灯到...。

语音播放文章内容由深声科技提供技术支持您的浏览器不支持audio元素,2019年行将结束,AI落地之路究竟走了多远,AI商用落地成绩单近日,在2019年厦门新经济发展大会的,新技术——浅谈AI商用落地成绩单,主题论坛环节,包括美图创始人兼CEO吴欣鸿、云知声董事长兼CTO梁家恩在内的业界人物就AI商用落地的成绩和现状进行了深入的探讨,...。

1、上海07年7月13日消息6月22日下午,一名10岁的小学生突然冲出高架下的隔离栏,撞上飞驰而来的桑塔纳小轿车,路面顿时一片血迹,幸好被及时送至医院,经抢救脱离了生命危险,2、安徽07年3月16日下午4时30分左右,206国道安徽长丰徐庙段发生特大交通事故,5名小学生在放学途中被一辆阜阳牌照的黑色奥迪轿车撞死,另有1名学生受重伤,3...。

上有天堂,下有苏杭,,爸爸糖手工吐司以3店同开的姿态加注杭州,不仅意味着其线下商业版图再次扩张,更有深层的商业布局逻辑,以,东南名郡,著称于世的杭州,一直是中国经济蓬勃发展的代表城市,2016年G20峰会、2018年世界短池游泳锦标赛都是在杭州举办,2022年年中,在亚运会即将于杭城举办的前夕,吐司界,课代表,——爸爸糖手工吐司,以...。

生产自己于抖音看到了该机构,其视频让生产自己深深被洗脑,加其微信后对方不时发信息让生产自己报名缴费报班去学习,并宣称,给到你最高价的报名时机5780,我再送你专业的设施,再送你我的签名耳机,再送你录音棚,生产自己听其肺腑之言还有设施送上门便缴费,因自己时期也强调没钱,对方还是不时有发信息来诱惑报课程......。

[全球网报道记者姜蔼玲]韩国,中央日报,11日报道称,正在华盛顿加入北约峰会的韩国总统尹锡悦外地期间10日与乌克兰总统泽连斯基会面,韩国国度安保室当日举行资讯颁布会,称将为乌克兰及其国民提供所需声援,此信息经韩媒报道后,引发不少韩国网友不满,有网友称,,此举,令人寒心,,非要四处抚慰抗争迸发吗,报道称,今日晚宴前,尹锡悦夫妇和泽连...。

将,丝滑,启动究竟,神十八乘组第二次出舱优惠全记载7月3日22时51分,经过约6个半小时,神舟十八号乘组航天员叶光富、李聪、李广苏亲密协同,圆满实现第二次出舱优惠,这是中国航天员在空间站阶段启动的第16次出舱优惠,16时19分,航天员李聪关上问天实验舱出舱舱门,开局团体初次太空行走,李聪登上机械臂,拆分固定装置后,搭伺机械臂转移至接设...。

关于2013款2.5新天籁上游款出现的缺点,咱们剧烈介绍首先返回4S店启动诊断,以便了解详细的疑问所在,现代车辆广泛装备了OBD诊断系统,能迅速定位和识别缺点,一些繁难疑问甚至可以间接经过这个系统处置,但是,假设缺点复杂,专业的4S店服务会更为牢靠,在培修环节中,务必与技术人员交换,征询缺点要素和处置打算,坚持良好的车辆保养习气至关关...。

微信App是一款人人必备的国民社交应用,除微信app主功能社交之外,微信app衍生出的支付、微商、新闻以及朋友圈子打造出了一个庞大的生态系统,微信app致力于打通人和人之间的沟通距离,让沟通更便捷;您可以免费下载。

感谢苹果与三星的专利,核战,,苹果才稍微肯让人知道他们是如何开发产品的——如果你以为在苹果内部,产品的开发就好像外界传言般浪漫,这绝对是误解,在法庭上,苹果泄露出来iPhone原型机的设计就多于40款,还有大量CAD图纸,而这些都不过是冰山一角,现在,连线的记者FredVogelstein对苹果的前员工进行采访,挖掘更多更深的内幕,已...。

下载地址,https,www.yanxishe.com,resourceDetail,2111?from=leiphonecolumn,res0817内容简介······,MATLAB优化算法案例分析与应用,进阶篇,是深受广大读者欢迎的,MATLAB优化算法案例分析与应用,一书的姊妹篇,即进阶篇,本书全面、系统、深入地介绍了MA...。

以上就是绿色先锋小编整理的青书学堂怎样开启应用权限的内容了,希望可以帮助到大家!我们会持续为您更新精彩资讯,欢迎持续关注我们哦!...。

看了纸牌屋第四季的朋友们,一定知道候选人威廉康威通过搜索引擎Pollyhop,为自己拉到了千万选票,其原理是通过操纵人们搜索的东西,如康威的名字,他的照片,Pollyhop可以控制人们看什么,并强迫人们看,直白地说就是给他们洗脑,即便他们不那么做,即便他们只是在追踪用户,也足以打败总统安德伍德了,一个搜索引擎真的有那么强大的威力吗,答...。

近年来越来越多的人士下海经商,同时许多的创业人士也把目光放到了服装的经营市场,服装作为快消品的行业,由于更新的速度比较快,而且随着季节的转换,让当季的服装更加的好销售,各种不同的服饰款式,结合好的面料和精湛的做工,吸引人们的眼球和流行元素的追崇,广州的沙河服装批发市场,就是比较火热的经营之地,吸引着不少外来的批发人士和海外的经营者,那...。
