无人汽车无法避开没见过的物体 问题出在训练pipeline上 (无人汽车无法充电)

与人类不同,目前最先进的检测和分割方法很难识别新型的物体,因为它们是以封闭世界的设定来设计的。它们所受的训练是定位已知种类(有标记)的物体,而把未知种类(无标记)的物体视为背景。这就导致 模型不能够顺利定位新物体和学习一般物体的性质。
最近,来自波士顿大学、加州大学伯克利分校、MIT-IBM Watson AI Lab研究团队的一项研究, 提出了一种检测和分割新型物体的简单方法。

为了应对这一挑战,研究团队创建一个数据集,对每张图片中的每一个物体进行详尽的标记。然而, 要创建这样的数据集是非常昂贵的。 许多用于物体检测和实例分割的公共数据集并没有完全标注图像中的所有物体。
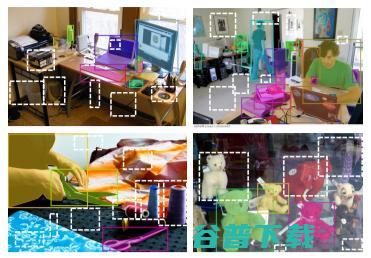
图1. 标准的物体检测器训练中存在的问题。该例来自COCO,有色框是注释框,而白色虚线框是潜在的背景区域。许多白色虚线区域实际上定位了物体,但在传统的物体检测器训练中被认为是背景,从而压制了新物体的目标属性。
未能学习到一般的目标属性会在许多应用场景中暴露出各种问题。 例如具身人工智能,在机器人、自动驾驶场景中,需要在训练中定位未见过的物体;自动驾驶系统需要检测出车辆前方的新型物体以避免交通事故。
零样本和小样本检测必须对训练期间未标记的物体进行定位。 开放世界实例分割旨在定位和分割新的物体,但最先进的模型表现并不理想。
导致目前最先进的模型表现不理想的原因在于训练pipeline,所有与标记的前景物体重叠不多的区域将被视为背景。 如图1所示,虽然背景中有可见但却未被标记的物体,但模型的训练pipeline使其不能检测到这些物体,这也导致模型无法学习一般的目标属性。
为了解决该问题,Kim等人提出 学习候选区域(region proposals ) 的定位质量,而不是将它们分为前景与背景。他们的方法是 对接近真实标记的object proposals 进行采样,并学习估计相应的定位质量。 虽然缓解了部分问题,但这种方法 除了需要仔细设置正/负采样的重叠阈值外,还有可能将潜在的物体压制目标属性。
为了改进开放集的实例分割, 研究团队提出了一个简单并且强大的学习框架,还有一种新的数据增强方法, 称为 "Learning to Detect Every Thing"(LDET) 。 为了消除压制潜在物体目标属性这一问题,研究团队使用掩码标记复制前景物体并将其粘贴到背景图像上。而前景图像是由裁剪过的补丁调整合成而来的。通过保持较小的裁剪补丁,使得合成的图像不太可能包含任何隐藏物体。
然而,由于背景是合成图像创建而来的,这就使其看起来与真实图像有很大的不同,例如,背景可能仅由低频内容组成。因此,在这种图像上训练出来的检测器几乎表现都不是很好。
为了克服这一限制,研究团队将训练分成两部分:
1)用合成图像训练背景和前景区域分类和定位头(classification and localization heads);2)用真实图像学习掩码头(mask head)。
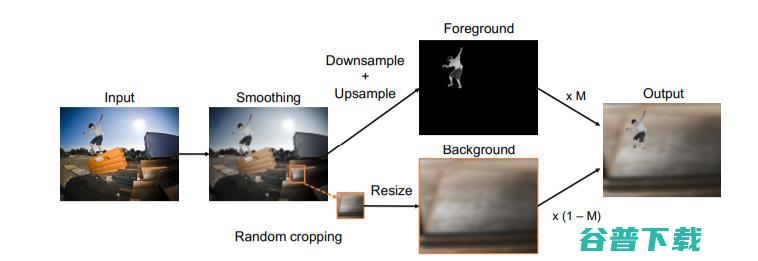
图2. 本文的增补策略是通过提高小区域的比例作为背景来创建没有潜在物体的图像。

图3. 原始输入(左)和合成图像(右)。用颜色标示了掩码区域,使用小区域作为背景,避免了背景中会隐藏物体。在某些情况下,背景补丁恰好可以定位前景物体(左栏第二行)。要注意的是,这种情况很少见, 可以看出补丁被明显放大了。
在训练分类头(classification head)时,由于潜在物体在合成图像时就已经被移除了,因此将潜在物体视为背景的几率变得很小。此外,掩码头是为在真实图像中分割实例而训练的,因此 主干系统学习了一般表征,能够分离真实图像中的前景和背景区域。
也许这看起来只是一个小变化,但 LDET在开放世界的实例分割和检测方面的表现非常显著。
在COCO上,在VOC类别上训练的LDET评估非VOC类别时,平均召回率提高了点。令人惊讶的是, LDET在检测新物体方面有明显提高,而且不需要额外的标记, 例如,在COCO中只对VOC类别(20类)进行训练的LDET在评估UVO上的平均召回率时,超过了对所有COCO类别(80类)训练的Mask R-CNN。如图2所示,LDET可以生成精确的object proposals,也可以覆盖场景中的许多物体。

图4. 在开放世界中进行实例分割,Mask R-CNN(上图)比本文所研究的方法(下图)所检测到的物体要少。在此任务中,在不考虑训练种类的情况下,模型必须对图像中的所有物体进行定位并对其分割。图中的两个检测器都是在COCO上训练,并在UVO上测试的。在新的数据增补方法和训练方案的帮助下,本文的检测器准确地定位出许多在COCO中没有被标记的物体。
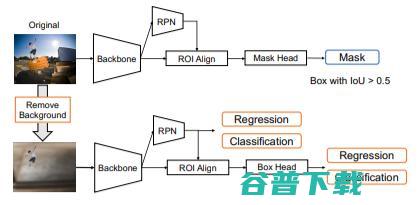
图5. 训练流程。给定一个原始输入图像和合成图像,根据在原始图像上计算的掩码损失和分类,以及在合成图像上的回归损失来训练检测器。
研究团队在开放世界实例分割的跨类别和跨数据集上评估了LDET。 跨类别设置是基于COCO数据集,将标记分为已知和未知两类,在已知类别上训练模型,并在未知类别上评估检测/分割性能。
由于模型可能会处在一个新的环境中并且遇到新的实例,所以跨数据集设置还评估了模型对新数据集的归纳延伸能力。为此, 采用COCO或Cityscapes作为训练源,UVO和Mappilary Vista分别作为测试数据集。 在此工作中,平均精度(AP)和平均召回率(AR)作为性能评估标准。评估是以不分等级的方式进行的,除非另有说明。AR和AP是按照COCO评估协议计算的,AP或AR最多有100个检测值。
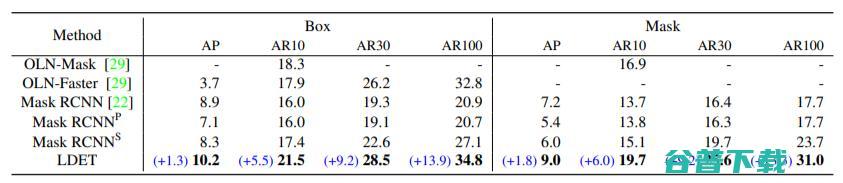
表1. COCO中VOC → Non-VOC泛化的结果。表中最后一行的蓝色部分是对Mask R-CNN的改进。LDET超过了所有的基线,并相较于Mask R-CNN有巨大改进。

图6. 在COCO数据集中,VOC to Non-VOC的可视化。上图:Mask R-CNN,下图:LDET。注意训练类别不包括长颈鹿、废品箱、笔、风筝和漂浮物。LDET比Mask R-CNN能更好地检测许多新的物体。
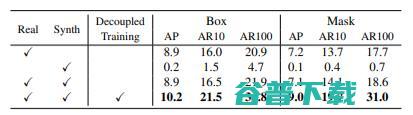
表2. VOC → Non-VOC的数据和训练方法的消融研究。最后一行是本文提出的框架。
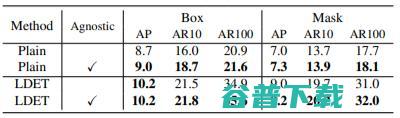
表3. class agnostic训练的消融研究。class agnostic训练对LDET和Mask R-CNN的性能有些许提高。
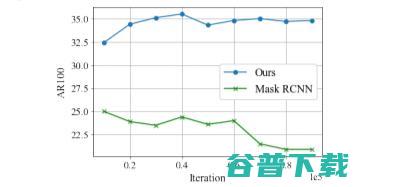
图7. 基线Mask R-CNN存在着对标记实例的过度拟合。因此,随着训练的进行,它检测新物体的性能会下降。相比之下,本文的方法基本上随着训练,性能都会提升。
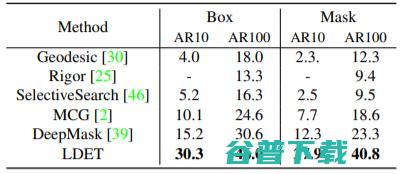
表4. 与COCO上测试的无监督方法和DeepMask的比较。需注意的是,DeepMask使用VGG作为主干。LDET和DeepMask是在VOC-COCO上训练的。

表5. 改变背景区域的大小。2-m表示用输入图像的2-m的宽度和高度裁剪背景区域。从较小的区域取样背景,往往会提高AR,降低
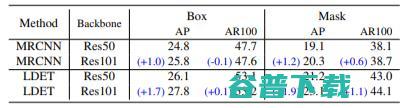
表6. ResNet50与ResNet101的对比。ResNet101倾向于比ResNet50表现得更好,这在LDET中更明显。

图8. COCO实验中的目标属性图(RPN score)的可视化。LDET捕获了各种类别的物体性,而Mask R-CNN则倾向于抑制许多
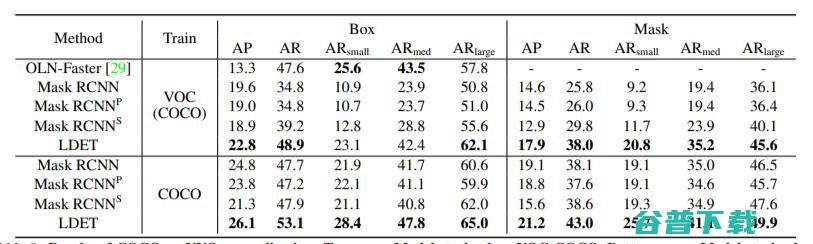
表8. COCO→UVO泛化的结果。上:在VOC-COCO上训练的模型,下:在COCO上训练的模型。与基线相比,L DET在所有情况下都表现出较高的AP和AR。

图9. 在COCO上训练的模型结果 的可视化。上图:Mask R-CNN,下图:LDET。最左边的两张图片来自UVO,其他的来自COCO的验证图片。
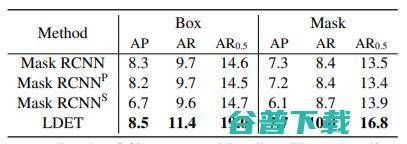
a的归纳结果。LDET对自动驾驶数据集是有效的。AR0.5表示AR,IoU阈值=0.5。
GAIR 2021大会首日:18位Fellow的40年AI岁月,一场技术前沿的传承与激辩
2021-12-10

致敬传奇:中国并行处理四十年,他们从无人区探索走到计算的黄金时代 | GAIR 2021
2021-12-09

时间的力量——1991 人工智能大辩论 30 周年纪念:主义不再,共融互生|GAIR 2021
2021-12-12

论智三易,串联通讯,贯通边缘,演进认知,汇于机器:听五位IEEE Fellow畅谈AI未来 | GAIR 2021
2021-12-25

新一代AI人才从哪里来,该往哪里去?| GAIR 2021院长论坛
2021-12-29

版权文章,未经授权禁止转载。详情见 转载须知 。



寿县粮食种植、寿县小麦种植、寿县玉米种植、大豆种植,寿县种丰农业种植专业合作社成立于2022年5月20日注册地位于安徽省淮南市寿县小甸镇邵店村,目前流转托管土地涉及小甸镇六个村邵店、唐店、杨圩、姚郢、李山、马集共计托管26000多亩,本社重发展绿色高效农业,专业化小麦,玉米、大豆、高粱种植并且对所托管的耕地面积进行了平整改良,提高耕地粮食增产。

厦门森陌文化传媒有限公司专业承接公司庆典策划、庆典布置、活动策划、活动布置、会议策划、会议布置、会议拍摄、舞台搭建、演艺演出、礼仪模特、灯光音响租赁。服务范围可达泉州、晋江、南安、石狮、惠安、泉港、莆田、仙游、龙岩、厦门、三明、福清等地区。

沈阳名人广告,是专注牌匾制作的厂家,十年来专业生产牌匾,灯箱,发光字,木质牌匾,各种灯箱,专业牌匾施工队,牌匾安装队,牌匾的设计团队,名人广告,牌匾设计师10多名,是专业牌匾设计的专业,名人广告安装师傅,是牌匾安装经验丰富,牌匾安装都是十年以后,安装各种广告牌匾,大小牌匾均可以安装,质量好,速度快,牌匾安装找名人,名人广告专业牌匾安装我年。专业,专注人事牌匾安装事业。沈阳牌匾沈阳牌匾制作沈阳牌匾厂家沈阳牌匾公司沈阳牌匾设计沈阳门头牌匾沈阳招牌制作 沈阳发光字沈阳发光字安装沈阳发光字厂家 沈阳擎天柱沈阳擎天柱制作沈阳高炮制作 沈阳灯箱沈阳灯箱厂家沈阳灯箱制作沈阳灯箱设计沈阳连锁灯箱制作沈阳连锁店牌匾制作沈阳连锁店灯箱制作

江苏橡胶护舷厂家-江苏建港橡胶制品有限公司

成都心理咨询正规医院,成都心理医生哪家医院比较好?成都棕南心理咨询中心|02885224567,提供成都青少年心理咨询,成都婚姻情感心理咨询,成都家庭亲子教育,成都个人情感心理顾问和专业心理测评!

潍坊市昌乐县城南街道办事处

北京天使儿童医院「预约挂号」是一家以多动症、抽动症等疑难儿童为主要治疗对象的儿科医院,是北京治疗多动症、抽动症、自闭症、矮小症、性早熟、脑瘫等儿科疾病好的医院,坐落于北京市朝阳区广渠路大郊亭2号楼的北京儿童医院,口碑好为人熟知.

蚌埠市新型建材行业协会

24小时汽车收购热线13888685566、昆明收二手车|昆明二手车收购网|昆明二手车辆回收交易市场-当也汽车回收专营全天上门,主城实体店,业务覆盖昆明全市:五华区,盘龙区,官渡区,西山区,呈贡区,晋宁区,东川区,安宁市,富民县,宜良县,石林县,嵩明县,寻甸县,禄劝县均可上门/到店交易!

中了勒索病毒怎么处理?如何解决?力创数据提供勒索病毒解密、勒索病毒文件恢复、数据库修复、威胁清除与防御方案,24小时热线13265855616

StellarFrp提供高效稳定的内网穿透服务,支持多种协议,适用于游戏联机、远程办公等场景。

南京永丰化工有限责任公司是由原国营南京永丰化工厂改制成立的科技型民营企业。企业创建于1960年,是专业开发和生产防水材料和各类乳液及有机玻璃的厂家,公司已通过ISO9001:2000质量管理体系认证ISO14001:2004环境管理体系认证。公司现有职工200余人,各类专业技术人员40余人。公司拥有年产10000吨各类乳液生产装置。


在阅读经济迅猛发展的当下,加盟儿童阅读馆行不行,需要综合多方面来看,01市场需求大环境看,全民阅读深入推进,整本书阅读走进新课标和教材,对孩子的能力和阅读量提出了更高的要求,再加上教育成本和家长阅读意识的影响,儿童阅读受到普遍重视,说明儿童阅读馆的潜在客源是非常广的,02产品布局如何在利好的市场环境中发展呢,需要看产品的布局,现在的儿...。

消息,4月11日真我发布了真我GTNeo6SE手机,新机首发6000nit无双屏,搭载第三代骁龙7,处理器,首销价1699元起,屏幕方面,真我GTNeo6SE首发6000nit无双屏,采用京东方S1发光材料,拥有1000nit手动最高亮度、1600nit全局激发亮度、6000nit局部峰值亮度,支持120Hz刷新率,8TLTPO...。

佬表食品是专门从事休闲食品销售的品牌,佬表食品立足市场已有十余年之久,公司在发展的这些年中妥善完善经营布局,深度优化消费者满意度,为品牌发展奠定下夯实基础,在公司坚持不懈的努力下,佬表食品业已成为拥有数百家网点的大型食品品牌,未来发展前景十分喜人,为向各位读者推荐该项目,文章将对佬表食品怎么加盟展开论述,希望文章能对各位读者有所裨益,...。

1、公众polo三厢车尺寸9mm,性能1polo的油耗或者会偏高,城市的话1011个之间,高速的8个左右,综合油耗应该在9个左右2polo两厢16的油耗如,165挡手动16L105马力L4EA111平均油耗746油耗范围6,2、polo劲取是上海公众以老款polo为原型联合中国人的审美规范和公众汽车标记性的U型外型打造的新款车型新款车...。

星座明码,演唱aoa只要好友之间才知道要永远好好守护一组暗号让咱们一同跳出快乐的舞蹈只需有信念幻想就会到达这就是小秘密神奇的十二颗星他们正散落世间期待咱们明码确实定只需置信你就会找到心中的双子星wow,胜利之星,请你听一听咱们声响wow,勇气之星,请你给咱们一个回音,猎奇的残酷的星座,你们是哪个星,白羊,天蝎,双鱼,射手和水瓶夜星宝...。

工具,原料,手机,魅族PRO7;Flyme版本号,7.3.0,360手机助手运行市场软件可以下载APP的旧版本,详细方法如下,1、关上360手机助手,2、点击输入框,3、输入,酷我音乐,后,按,搜查,按钮,4、结果中,点击,酷我音乐,5、手指往上划,划究竟,6、点,历史版本,7、点,下载,8、期待下载成功,9、下载成功后,点,装...。

BCArchive是由Jetico开发的一款安全的文件加密工具。它使用强大的加密算法和密码学技术,可以创建加密的存档文件(.bc格式)

狼蛛S2096键盘驱动是这款狼蛛机械键盘的驱动程序,键盘平时使用不需要驱动也可以,想对键盘设置一些宏命令就可以利用狼蛛键盘驱动来编程就必须要安装驱动程序了!软件特色时尚的设计和集成的金属面板。不易生锈且耐刮擦。按键盖采用超薄两色注塑成型,坚固耐用难以褪色,多色可选。采用机械式晶体轴开关设计,按键寿命达6000万次,手感持久,出色。键帽和狭缝

远山和叶的父亲是谁远山警官男年龄不明大阪府警视厅刑事部长,远山和叶的父亲。也是平次之父服部平藏的好友。两家可说是世交,也因此促成两人。登场6次。初登场:漫画Vol.19File.5《美食之都大阪城》TV118浪花连续杀人事件远山刑警父亲是大阪府警察署刑警局局长,服部平藏的手下和叶的父亲叫做远山银司郎,是大阪府警察本部的刑事部长,也是本部长服部平藏的好友兼部下,他的推理能力也是很强的。在tv版浪花连续杀人事件和大阪双重谜团浪花剑士和太阁城就能体现出来,可以百度“啪嗒动漫”观看哦~2,请给服部平藏远山银司

小时候很喜欢看一部电视居里面有小飞燕请看过这电视得朋友给我小时候看过的《快嘴李翠莲》,女主角是李湘演的翠莲,不是翠龄2,特警力量演员小飞燕真名叫什么王文娜你好!小飞机仅代表个人观点,不喜勿喷,谢谢。3,涨知识腰突是否能做小飞燕可以说小飞燕就是来治疗腰突的,但这个动作不是所有的人都能做到,你还这可以考虑那个取代的方法,即用斜面床垫来治疗腰突,可以自己找一上资料,不错的方法,请参考!做大燕飞,小燕飞,拱桥式,锻炼腰背肌,腰腹肌。在就是游泳,游泳的时候人在水里的时候,实际上在医学上叫做“水疗”,通过水的浮力

重庆分类目录网站收录代驾相关的优秀网站大全分类检索,为上网用户提供代驾网站排行榜与您分享、收藏!

慧影时间流app下载-慧影时间流app是一款时间规划应用,用户可以通过软件自由安排每日的日常,通过合理的时间规划,让用户可以轻松效率的完成每日的工作学习计划,您可以免费下载安卓手机慧影时间流。

11月29号的时候,我们帮一位来自卢松松博客的朋友制定了关键词任务优化方案,并辅助该位朋友创建了任务,到今天,正好是第八天了,早上我看了下他的任务情况,决定以此为案例,做一期实战分享,这位朋友做的时候空调维修行业,当时我们在微信聊天,他说他有很多的站点,但是都是类似B2B的二级域名站点,当时排名不太稳定,但是部分站点还是有词库的,本期...。

6月25日,天猫宣布,旗舰店2.0升级计划,将通过工具和产品的升级,帮助品牌商家更好地运营消费者,以持续获得增长,在今年双11之前,,旗舰店2.0升级计划,将面向全部天猫商家开放,助力商家转型新零售,据天猫方面介绍,,旗舰店2.0升级计划,将围绕线上线下多场景运营、会员运营、粉丝运营、分人群精细化运营等多方面展开,从而提升商家数字化...。

司机们注意啦!这伙儿人,碰瓷,违规行车,近日,@北京公交警方先后成功抓获利用机动车,碰瓷,行为获利的犯罪嫌疑人9名,据了解,9名犯罪嫌疑人专挑司机违章时作案,抓住司机不愿通过交警来处理的心理讹诈钱财,共作案300余起,涉案金额100余万元,涉及公交车辆60余起,小政,开车遵守交通规则,不给不法分子可趁之机!北京政法的微博视频来源,松...。

雷锋网获悉,美国时间1月9日,联想在CES上发布了其与谷歌合作的VR一体机MirageSolo,基于谷歌的Daydream移动VR平台,谷歌也在官网上公布了其与联想合作的VR一体机MirageSolo的相关信息,MirageSolo搭载骁龙835芯片,配备分辨率为2560x1440LCD液晶显示屏,续航时间达7小时,更为重要的是,Mi...。

今日融资快报开源软件提供商GrafanaLabs以60亿美元估值筹集2.7亿美元GrafanaLabs正式名称为RaintankInc.,是GrafanaCloud的创造者,这是一个广泛使用的开源IT基础设施监控平台,该平台通过从客户的基础设施中抓取遥信数据和运营数据,并将这些数据绘制成图表,帮助管理员更容易地识别模式和趋势,Graf...。
