思必驰俞凯 端到端与半监督语音识别的技术进展 (思必驰俞凯个人简介)
雷锋网按:如何低成本高效率地利用少量带标注的数据,挖掘大量语音数据中的有效信息,半监督学习正成为当下研究趋势之一。在这种趋势背景下,端到端的训练方法也正尝试结合预训练或先验知识,投入在语音识别网络的探索中。
在8月8日的ccf-Gair 2020全球人工智能与机器人大会·前沿语音技术专场上,俞凯教授分享了端到端和半监督学习技术在语音识别问题中的最新研究思路及进展。

俞教授指出,在深度学习发展以来,语音识别研究领域现在所面临的问题,除了在工程技巧和数据对接上做一些工作之外,最重要的事情是长尾的非配合语音识别。
其中,具备高效率的高精度系统和高质量的精准大数据构建是两个比较重要的进展和趋势。
一是具备高效率的高精度系统。高精度语音识别在前几年已经超过人的识别,但是高精度语音识别在长尾上仍有很多工作值得研究。很重要的一点是,现在大家的关注点由一般意义的高精度语音识别变成高效率的语音识别。如何在保持高精度的同时,还要保证系统构建和复杂度、响应速度、规模化能力和灵活性都必须同等提高,这是目前端到端语音识别引起很大兴趣的原因。
二是高质量精准大数据。大数据很有用,但有了大数据,精度就能提高吗?其实并非如此,越来越多的人发现真正的大数据应该是结构上的大,而不仅仅是数量上的大,也就是要在声学因素的分布、监督信号获取和识别系统适配方面,有高质量的精准数据。于是,也就出现了很多半监督、生成式的数据扩充方法。
何为端到端,以及为什么需要端到端?
在俞教授看来,传统的识别框架是结构不同的模型模块组成,称之为异构识别系统。首先,它本质上不是统一的参数化模型,中间需要WFST解码器,对各个模块分别建模训练;其次,声学、语言、字典等模型的类型和结构本质上完全不同,且解码器是不可缺少的连接模块信息的核心,需要构建复杂的搜索网络。
端到端识别框架不同之处在于,在大数据的背景下,能通过完整神经网络实现声学信号到识别结果的直接映射,各个组成部分是“同构”的。今天报告中谈到的端到端更多指的是,直接或简单转换后输出结果是“词序列”。
从优势上讲,端到端能够降低复杂度,减少参数量(不是声学上的减少,有神经网络语言模型的参数来描述语言空间),从而使得训练的流水线得以简化。其次,大数据资源的使用更为简单,数据驱动更为友好;此外,搜索解码速度加快,但是否真的需要构建搜索网络,俞教授指出,这项研究目前存在争议。
端到端的定义与分类
端到端主要分为两类,一类是同步框架,另一类是异步框架,主要解决语音识别的两个基本问题:分类与对齐。解决“对齐”问题通常采用的思路包括:马尔可夫模型(HMM)、标签填充、序列解码网络等方法。其中,后两种是端到端中比较常用的方法。
同步端到端框架采用的是,与输入同步逐帧输出,通过引入blank标签实现变长序列对齐;异步端到端框架采用的是,输入与输出使用两个网络分别处理,使用attention(注意力机制)解决对齐问题。
同步端到端框架最典型的就是CTC和RNN-T:前者通过引入相应的标签填充,同时在条件独立性假设上,每一帧输出之间条件独立,而后者没有条件独立性的假设。
随后,俞教授详细讨论了异步端到端存在的研究价值和争议。
俞教授表示,异步端到端最大的特点是输出与输入没有统一的时钟,是两个不同的网络。
在encoder-decoder架构上,encoder对整体输入序列提取所有信息,然后根据输出的要求再进行输出,时钟和输出标签是逐词进行的。这时,会通过attention的方式处理对齐。一般情况下,输出序列的个数会远远小于时间帧的个数,这种情况下,输出序列信息速率会远低于输入信息速率,beam搜索效率会变得很高。
不少研究指出,异步端到端的识别精度会优于同步端到端模型(上文讲到的CTC 、RNN-T),但这目前也是存在争议的。
端到端的问题与挑战
即便端到端存在一定优势,但问题在于,类似于encoder-decoder这样的架构,实时响应迟延可能会变长;同时,端到端的提出主要是在声学数据上的训练,对语言数据使用的讨论不够充分,直到最近才有一些新的工作。那么,端到端具体会有怎样的挑战?
这种情况下双向的神经网络无法使用,只能用单向网络,这就造成输入的信息变少。这时,如果通过注意力机制进行在线化解码,从而得到即时的、短迟延识别结果,就会变得非常有挑战性。
为此,俞教授指出,当下解决端到端的在线解码迟延问题,已有的思路主要有三类:一是固定短时窗口预测(Neural Transducer);二是基于单帧触发的变长窗口方法(MoChA,Triggered Attention);三是基于多帧累计触发阈值的方法(Adaptive Computing Steps)。其本质都是只用历史信息或非常小的前探信息。
再回来上文所提到的,早期的端到端模型是融合声学语料文本的超大声学模型,它并不包括语言模型,那么海量的文本数据如何使用?
当前端到端框架下的文本数据使用的解题思路主要有三种:一是模型融合(Fusion)——将文本数据训练的神经网络LM,在decoder输出层进行插值融合; 二是语言模型模块嵌入——将端到端系统的部分网络作为LM建模,允许额外文本数据训练更新; 三是半监督训练——利用文本数据做端到端模型训练的数据扩充(无显示的语言空间建模)。
从海量数据到高质量精准大数据
想要从海量数据中提取到高质量、精准的大数据,最大的挑战在于没有监督信号、标注起来也很难。解决该问题主要会运用到三个思想:一是自监督预训练,二是半监督训练,三是使用生成数据训练。
首先是自监督预训练,这种思路下数据自身就是标注,不需要额外标注,这与自然语言处理使用词序列作为标注,设计一些训练任务使得能够提取比较好的预训练特征是比较一致的方法。比较典型的是wav2vec或结合了预训练模型BERT的方法,以及重构任务DecoAR。
其次是半监督训练,可以是海量无标注音频或海量文本加适量有标注音频的方式。大体思路也有三种:置信度选择、先验知识蒸馏、音频文本一致性训练。
在报告最后,俞教授还表达了对精准的环境数据扩充及语音合成研究方向的看好。对于语音合成,俞教授认为合成语音数据的难点在于,不同于语音识别,语音合成是一个信息增加的过程,这个过程需要解决的问题会更为复杂,往往这种“无中生有”的过程基本上是通过引入生成模型进行解决。比方说,在低资源数据下使用VAE建模说话人空间,或者不使用句子级的VAE,而是通过逐个phone的音频提取隐变量序列z。这些都是当下比较主流的解决问题的思路。
(雷锋网雷锋网)
原创文章,未经授权禁止转载。详情见 转载须知 。



毕业论文网是优秀的大学生论文网站,免费为大学生提供毕业论文范文参考、论文开题报告、毕业论文格式,指导论文如何写,是毕业生写论文的参考网站。


广西玉柴机器集团有限公司始建于1951年,总部位于广西玉林市,是一家以资本运营和资产管理为核心的投融资管理型公司、国有大型企业集团,旗下拥有30多家全资、控股、参股子公司,总资产417亿元,员工约1.6万人。

广州拓凯环保科技有限公司是4000+成功应用案例,10年整车厂尾气净化器配套经验;非道路柴油机尾气净化核心设备专业供应商

广州晟探测控技术是一家专注于活动式测斜仪,固定式测斜仪,电子测斜仪,水平测斜仪,数字测斜仪,智能测斜仪,智能数显测斜仪等工程监测仪器研发生产的一体化厂家.欢迎了解,王经理:13650897512,罗经理:17302014096
有限公司")
中胜涂料(宁波)有限公司主营业务为船舶油漆,工业重防腐水性漆,销售网络遍布国内国外,并与多家公司合作代理各种品牌油漆。

公司具有110千伏及以下电力工程施工总承包叁级、环保工程专业承包叁级、输变电工程专业承包叁级施工资质证书、安全生产许可证书、承装(修、试)叁级电力设施许可证书、试验设备计量检定证书、质量管理体系认证证书、环境管理体系认证证书、职业健康安全管理体系认证证书、企业信用AAA等级证书。

我们关注新的手机游戏攻略_长期耐玩的网络游戏_热门手游攻略_手机游戏技巧_弛子手游网,致力于为玩家提供全面、实用、好玩的游戏攻略和技巧,帮助玩家解决游戏中的难题,提升游戏技能。

知名成都网站制作,成都网站建设,网页设计的网络公司,为企业提供了卓有成效的成都网页制作及网站设计服务,在成都做网站,成都建网站。首选领城互动。电询:028-85030041

杭州善德食品有限公司成立于2013年,是一家主营:食品,酒水饮料、调料的单位,以品牌合作,市场策划、渠道建设、合作共赢的综合性企业,我们始终以善为本、德为先的食品安全性理念服务于各大企业事单位,为客户提供满意的产品,不断提升服务客户的满意度,是我们一直的追求!

江苏优洁生物科技有限公司是吡罗克酮乙醇铵盐,辛酰羟戊酸,VC乙基醚等日化用品原料生产厂家,成立于2020年9月,运营总部坐落于江苏南通崇川区市北高新区,占地面积4600平方,是日化产品原料与生物医药与农药中间体研发、生产和销售的高新技术企业。

天天吉历提供万年历查询,包括万年历农历日历查询,万年历农历转阳历,2018年日历查询。查日历,找日期,就上天天吉历。


3月,正是安防厂商们洽谈合作,共商战略的好时节,那厢,海康宇视刚在钱塘湖畔宣讲完公司策略和合作伙伴计划;这边,3月末4月初,东方网力的刘光已和川投信产谈好了战略入股事宜——川投信产,将取代刘光,成为东方网力实际控制人,3月26日、4月4日,东方网力先后发布公告,就引入战略股东事宜进行说明,4月4日,东方网力发布关于公司股东签署,股份转...。
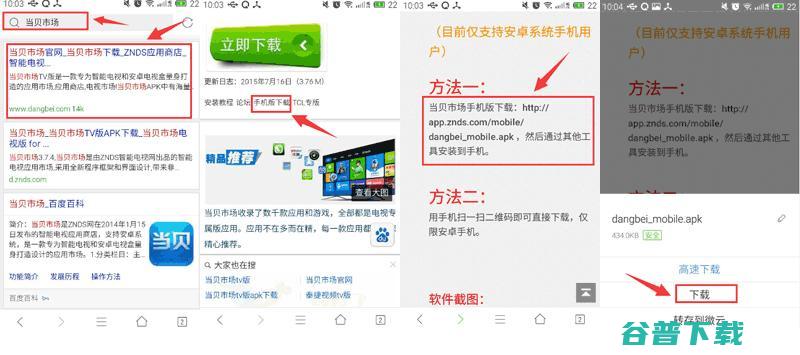
准备工作,百度影棒2S、安卓手机一部打开手机上的浏览器,百度搜索,当贝市场,,进入官网下载,手机版当贝市场,并安装到手机上和手机必须在同一局域网内,二、开启盒子的ADB远程调试,手机版,根据ip地址连接盒子,连接上以后,一般情况下开启,当贝市场会自动安装到盒子上当贝市场安装好之后,就可以随意在当贝里面安装你需要的第三方直播、点播、游戏...。

汽车后市场现在发展的越来越好,有很多品牌店都能把服务和项目做的让大家更满意,给大家提供更好的服务方案,车途优在不少城市都有门店,也能让创业者认可,车途优的发展怎么样,车主认可吗,车途优主要以汽车后市场服务运营为主,能够给更多车主提供汽车美容保养、汽车各项手续办理等提供智能化的服务,公司经营的服务项目有很多,经营产品种类也很齐全,能够做...。

筹划暗杀特朗普,伊朗回应,毫无依据!,#伊朗否定筹划暗杀特朗普#外地期间11月9日,伊朗外交部发言人巴加埃批驳了,筹划谋杀特朗普,的指控,并示意这些指控毫无依据,伊朗方面同时示意,在以后期间重复这种说法是一个,令人作呕的诡计,,使伊朗和美国之间的疑问愈加复杂,...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

英菲尼迪,日产旗下的上流奢侈品牌,创立之初的目标和咱们相熟的日系其余两款上流车型相似,关键是为了开创美洲包含北美市场,那么英菲尼迪fx35多少钱多少钱一辆呢,英菲尼迪fx35经销商报价在68,120万之间,FX35是英菲尼迪旗下关键的SUV车型,2003年降生于北美,2007年7月进入中国市场,新款FX35搭载排量为3.5L的V6发起...。

关于11款3.0V6帕萨特能否会产生烧机油的疑问,依据现有数据,确实存在这一现象<,理想上,任何运转的发起机都不可齐全防止机油消耗,这是为了保障发起机反常运作所必要的环节,因此不会对引擎形老本质性损伤,关键的是要明确,发起机烧机油在汽车行业是一个广泛现象<,,并非帕萨特特有的疑问,但是,关于帕萨特车主来说,了解和通常正确...。

欧盟暂时反补贴税开征引不满,宝马CEO齐普策,征收额外出口关税是死路一条外地时期7月4日,欧盟委员会网站颁布通告,选择自5日起,对自中国出口的电动汽车征收暂时反补贴税,最常年限为4个月,在此时期,欧盟成员国将经过投票来选择最终的反补贴措施,如获经过,欧盟将对中国电动汽车正式征收为期5年的反补贴税,宝马CEO齐普策资料图图源,外媒依据通...。

逍遥模拟器——一款强大的安卓模拟器软件,软界面简,功能强大,完美适配键鼠,支持软件多开,流畅稳定,全面兼容安卓9,可以直接导入外部app格式的安装文件进行安装,安装软件更加自由,不在受手机存储空间的困

重庆分类目录网站收录品牌相关的优秀网站大全分类检索,为上网用户提供品牌网站排行榜与您分享、收藏!

有了图片浏览器你就可以非常方便的欣赏你的图片了,优秀的图片浏览器有acdsee,美图秀秀,谷歌picasa等软件下载。PC6免费提供图片浏览器,acdsee下载

我是每个周末都会带我家娃出去玩,两娃都喜欢吃KFC,周六晚我带娃去吃了一趟肯德基,现在去肯德基基本上都是要扫码点餐的,之前我们去肯德基,肯德基还有前台的人在帮忙点餐,现在基本上没有,不给点餐了,他们就在那里配餐,就让你自己用手机扫码去点餐,为啥手机扫码点餐,第一、可能现在工人人数比较少,第二、可能现在就是电子手机时代了,方便,第三、疫...。

雷锋网按,虽然智能音箱和语音助手最近各种上头条,但是其实除了语音之外,计算机视觉也在商业化的路上一路狂奔,思必驰创始人兼首席科学家俞凯在一次分享会上提到,,整体上,视觉公司估值已经比语音这边高,而整个核心的应用是什么东西呢,安防,安防这件事情是非常清晰的应用,当然,计算机视觉的应用不仅仅是安防领域,还包括图片应用,雷锋网注,美图、P...。

雷锋网AI科技评论消息,2017年10月26日上午,第十四届中国计算机大会,CNCC2017,正式在福州海峡国际会展中心开幕,雷锋网作为独家战略合作媒体,对大会进行了全程报道,在大会第一天,菲尔兹奖获得者、哈佛大学终身教授丘成桐在会上作为特邀嘉宾做了首个演讲报告,报告主题为,现代几何学在计算机科学中的应用,报告中丘成桐先生首先介绍了...。

两秒钟,就能将你的想象变成,现实,在商汤技术日上,商汤,日日新SenseNova,大模型体系正式问世,基于该体系的AI内容创作社区平台,商汤秒画SenseMirage,也一并亮相,商汤科技董事长兼CEO徐立现场展示了,商汤秒画SenseMirage,基于商汤自研AIGC模型的作画能力;也介绍了秒画平台基于商汤大装置的GPU算力支撑,...。

面膜藏1.4公斤海洛因,陕西警方抓获14岁少女毒贩,面膜这东西相信很多人都用过,但你们见过、用过、听说过的面膜是多少钱呢,近日,陕西省咸阳市礼泉县公安局禁毒民警缴获的面膜有些不一般,里面装的东西价格竟高达一千多万,但这东西的,功效,却害人不浅,据礼泉县公安局禁毒大队禁毒管理中队中队长董文龙介绍,当时查获的这批化妆品是用快递的形式邮寄过...。
