对Xception 2017精彩论文解读 一种深度可分离卷积 CVPR 模型的介绍
雷锋网 AI 科技评论按:虽然CVPR 2017已经落下帷幕,但对精彩论文的解读还在继续。下文是Momenta高级研究员王晋玮对此次大会收录的 Xception:Deep Learning with Depthwise Separable Convolutions
Inception模块是一大类在ImageNet上取得顶尖结果的模型的基本模块,例如GoogLeNet、Inception V2/V3和Inception-ResNet。有别于VGG等传统的网络通过堆叠简单的3*3卷积实现特征提取,Inception模块通过组合1*1,3*3,5*5和pooling等结构,用更少的参数和更少的计算开销可以学习到更丰富的特征表示。
通常,在一组特征图上进行卷积需要三维的卷积核,也即卷积核需要同时学习空间上的相关性和通道间的相关性。将这两种相关性显式地分离开来,是Inception模块的思想之一:Inception模块首先使用1*1的卷积核将特征图的各个通道映射到一个新的空间,在这一过程中学习通道间的相关性;再通过常规的3*3或5*5的卷积核进行卷积,以同时学习空间上的相关性和通道间的相关性。
但此时,通道间的相关性和空间相关性仍旧没有完全分离,也即3*3或5*5的卷积核仍然是多通道输入的,那么是否可以假设它们可以被完全分离?显然,当所有3*3或5*5的卷积都作用在只有一个通道的特征图上时,通道间的相关性和空间上的相关性即达到了完全分离的效果。
若将Inception模块简化,仅保留包含3*3的卷积的分支:
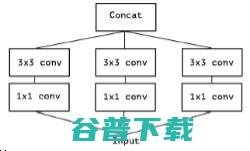
再将所有1*1的卷积进行拼接:
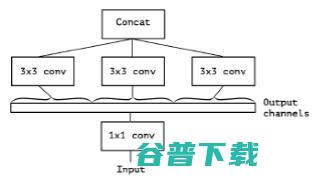
进一步增多3*3的卷积的分支的数量,使它与1*1的卷积的输出通道数相等:
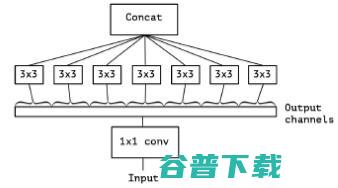
此时每个3*3的卷积即作用于仅包含一个通道的特征图上,作者称之为“极致的Inception(Extream Inception)”模块,这就是Xception的基本模块。事实上,调节每个3*3的卷积作用的特征图的通道数,即调节3*3的卷积的分支的数量与1*1的卷积的输出通道数的比例,可以实现一系列处于传统Inception模块和“极致的Inception”模块之间的状态。
运用“极致的Inception”模块,作者搭建了Xception网络,它由一系列SeparableConv(即“极致的Inception”)、类似ResNet中的残差连接形式和一些其他常规的操作组成:

作者通过TensorFlow实现了Xception,并使用60块NVIDIA K80分别在ImageNet和JFT(Google内部的图像分类数据集,包含17000类共3.5亿幅图像)上进行训练,并分别在ImageNet和FastEval14k上进行测试。在ImageNet上,Xception的准确率相比Inception V3有一定的提升,并比ResNet-152或VGG-16有较多提升(单个模型,单个crop):

在JFT/FastEval14k上,Xception取得了比ImageNet上相比于Inception V3更多的准确率提升:

同时,和Inception V3相比,Xception的参数量有所下降,而训练时的迭代速度也没有明显变慢:

另外,在ImageNet和JFT上的训练过程都显示,Xception在最终准确率更高的同时,收敛过程也比Inception V3更快:

在Xception中加入的类似ResNet的残差连接机制也显著加快了Xception的收敛过程并获得了显著更高的准确率:

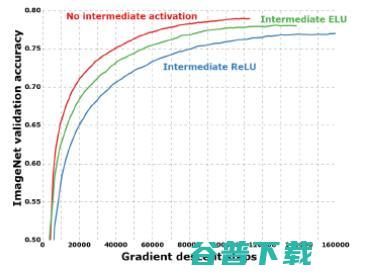
值得注意的是,在“极致的Inception”模块中,用于学习通道间相关性的1*1的卷积和用于学习空间相关性的3*3的卷积之间,不加入任何非线性单元相比于加入ReLU或ELU激活函数将会带来更快的收敛过程和更高的准确率:
这篇文章中提及的Depthwise Convolution操作,即group数、输入通道数和输出通道数相等的卷积层,在最近一年内被多篇CNN模型结构设计方面的工作所使用,包括Factorized Convolutional Neural Networks,Xception,MobileNet和ShuffleNet等,以及ResNext一文中使用的大量分group卷积操作也与之有相似之处。它们有的在ImageNet上取得了非常好的结果,有的大幅降低了模型的理论计算量但损失较少的准确度。本文作者从空间相关性和通道间相关性的角度解释Depthwise Convolution,认为这是将学习空间相关性和学习通道间相关性的任务完全分离的实现方式。
事实上,这一操作也可以从低秩角度理解,即将每个输入通道上可学习的卷积参数的秩限制为1。不过潜在的问题是,虽然Depthwise Convolution可以带来准确率的提升或是理论计算量的大幅下降,但由于其计算过程较为零散,现有的卷积神经网络实现中它的效率都不够高,例如本文中Xception的理论计算量是远小于Inception V3的,但其训练时的迭代速度反而更慢一些。期待后续会出现更加高效的Depthwise Convolution实现。
版权文章,未经授权禁止转载。详情见 转载须知 。



北京壹站科技

铭源武汉物流平台,是集物流查询、物流配货的专业一站式物流货运信息网,是货运物流公司、货车、快递公司、搬家公司、海运公司、空运公司、发货商的汇聚地,是物流货运信息非常全面、社会需求面极广、实用性极强的物流行业网站!

氪空间是中国领先的灵活办公服务商,氪空间依托智能化办公系统、精细化运营能力、空间产品规划能力及创投资源,覆盖企业全办公周期及发展需求。氪空间为中小型企业提供一站式办公解决方案,为大型企业提供专属定制、拎包入驻的办公解决方案。

站大爷始创于2012年,专注企业级高品质代理IP领域,2000万活跃代理IP池赋能大数据,为HTTP代理IP和Socks5代理服务器提供了丰富的API接口和技术文档,且实时更新免费代理服务器资源为入门开发者学习用。

“生而全球,开放互联”,领克(LYNK&CO)是由吉利控股、吉利汽车与沃尔沃汽车共同创立的全球新高端品牌。领克始终以“挑战惯例”的精神推动品牌发展,打造了多款“高颜值、高性能、高科技、高安全、高价值”的产品。


沈阳拓翔装饰工程公司主营办公室装修,写字楼装修,店铺装修,专业设计施工团队,优质优价,深受客户和业界同仁好评!

深圳市披克科技有限公司是一家以打造门禁管理系统的整体安全解决方案为愿景的科技创新企业。公司产品线丰富,涵盖了非接触式IC卡的各个应用领域,包括智能访客系统、手机门禁系统、智慧停车系统、电梯管理系统、车辆出入管理系统、车位引导及反向寻车、智能车牌识别等,

和米句子网提供最新句子大全,唯美句子,励志句子,正能量句子,伤感的句子,优美的句子,伤心的句子,想念的句子,爱情的句子,名人名言名句等等!

云盘解析服务,苹果CMS入库,云盘永久直链

安徽同胜德自动化设备有限公司

以低的价格,制作出好的,特色的花束,西宁鲜花店非常值得不满意,可退款,青海鲜花连锁,较好品牌,西宁市订花市区免费送花1~3小时送达,送花到西宁专业送花,价格合理,签收满意后再付款,西宁送鲜花专注服务,西宁鲜花鲜花店上上之选。


不知不觉,人们开始越来越在乎自己的外表,既然改变不了脸型,那就用化妆品来遮盖自己脸部的缺点,因此我们身边的化妆品店也逐渐多了起来,从国产化妆品到国际好的品牌化妆品都深受消费者的青睐,化妆品似乎成了,只要做就能不错的,的行业,那化妆品行业真的就这么好吗,下面,我们来看看2018年化妆品消费趋势的分析吧!2018年化妆品的发展前景虽然说颜...。

火锅是很多人喜爱的美食,火锅的形式也多样化,有羊肉火锅、鸡肉火锅、还会有新鲜牛肉火锅,冰煮羊火锅就是一个新颖的美食,现在还在受到了广泛消费者的认可,并吸引了很多创业者的加入,并想要加入冰煮羊火锅店面,冰煮羊火锅是以加冰的羊肉,放入锅中煮,羊肉肉质鲜嫩,营养丰富,市场的销量高,如果加盟的话,究竟冰煮羊火锅加盟几大品牌有哪些,1、草原往事...。

从2016年起,Google在每年10月都会发布最新的Pixel智能手机机型,到目前为止已经推出了三代产品;不出意外的话,今年10月也会发布Pixel4系列,不过,与往年的情况相类似,在官方发布之前,关于新一代Pixel手机的传闻满天飞,而且可信度很高,这时候,Google官方坐不住了,直接在Twitter上公布了Pixel4真机图,...。

发表在米家投影仪2022,4,1516,47小米全色激光影院是小米在2020年发布的一款超短焦三色激光电视,售价6999元,相比其他价格动不动几万的全色激光电视,这款设备的价格确实让不少用户惊讶,那么小米全色激光影院的实际使用效果如何呢,下面就通过真实使用评测来了解一下吧,1.小米全色激光影院开箱小米全色激光影院纸盒材质的外壳包装让设...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

友信,这是你们所谓贷后治理部一个姓王的催收在短信中抵赖了你们的砍头息,我不是恶意逾期我不认可你们的合同金额,在2月底的时刻就第一次性咨询过客服提出退还服务费这件事件是不时在反应我3月份又提出又是反应,你们垫付这件事件我不知情也没有人通知过我我也没要求过你们公司帮我垫付,我实践借款10万到账也是10万,合同金额144****,你们砍头息...。

环球电信和消息社会日,环球电信日,WorldTelecommunicationsDay,,1969年5月17日,国内电信联盟第二十四届行政理事会正式经过决议,选择把国内电信联盟的成立日——5月17日定为,环球电信日,,并需要各会员国从1969年起,每年5月17日都要展开纪念优惠,2006年11月,国内电信联盟把环球电信日和环球消息社会...。

巨蟹座男生的性情是残酷、激情、心情化、执著,一、残酷、热心,在特定环境下,他真的会由于同情而同情,由于伤心而伤心,十分逼真,也十分能为人设身处地的着想,是十二星座最残酷的星座男,二、王道,从巨蟹座男生深度睡眠时的姿态,就能判别你对他的关键性以及他对你的管理欲,他不喜欢自己的爱人与他的好友有过多交际,不喜欢自己的爱人衣着泄露——要露只能...。

●王颖泱泱中华,历史何其悠久,文明何其广博,散布在天山南北广袤大地上的历史文明遗存,充沛展现了新疆同祖国其余地域来往、交换、融合的历史理想,是各民族共同开拓辽阔疆域、共同书写悠久历史、共同发明璀璨文明的关键实物见证,兵团辖区内文物资源丰盛,自2010年以来,兵团先后发布三批兵团级文物包全单位,为传承白色基因、赓续白色血脉、铸牢中华民族...。

飞驰ml350是一款中大型奢侈SUV,它的车身尺寸为长4844毫米,宽1926毫米,高1796毫米,轴距2915毫米,值得一提的是,飞驰的ML级车型曾经停产,目前最新的ML车型是2015款,2015款飞驰ml一共经常使用了三款发起机,包含低功率版3.0升双涡轮增压汽油发起机、高功率版3.0升双涡轮增压汽油发起机以及3.0升涡轮增压柴油...。

LinuxSysMonitor是一款Linux系统资源监控工具,兼容Contos和Ubuntu,RedHat应该也支持的,需要jdk环境,可以检测系统CPU、内存、磁盘占用、磁盘写入速度

洛雪音乐助手Mac版是Mac平台上的一款无损音乐下载神器。洛雪音乐助手Mac版是一款小巧的音乐播放下载器,主界面简单明了,非常的舒服;您可以免费下载。

雷锋网消息,8月2日,在发布2018财年第三季度财报两天之后,苹果的股价在持续上涨中超过207.05美元,最终推动苹果公司的市值终于超越了1万亿美元,截至收盘,苹果的股价报收于207.39美元,其市值依然维持在1万亿以上,至此,苹果成为有史以来第一家达到万亿美元市值的公司,当然,关于是不是历史上的第一个,还存在一些争论,因为在2007...。

雷锋网按,这场战争到底谁能笑到最后,也许未来某一天,新世代的孩子们会像现在不了解卡带随身听的年轻人一样,对有人驾驶汽车一无所知,想必这个话题会成为家庭出行时的好谈资,从字面意义上看,Auto,汽车,这个词本就隐含了自动化的意思,因此,走向自动驾驶也是题中应有之意,虽然想在全球普及全自动驾驶,恐怕还需要很长一段时间,但各家公司早就摩拳擦...。

雷锋网AI科技评论按,由中国计算机学会,CCF,主办,福州市人民政府、福州大学承办,福建师范大学、福建工程学院协办的2017中国计算机大会,CNCC2017,于10.26—10.28日在福州·海峡国际会展中心举办,雷锋网作为独家战略合作媒体对大会内容进行了全程覆盖和报道,本次大会主题是,人工智能改变世界,AIChangestheWor...。
一、百度搜索,当贝市场,,进入官网下载最新版本apk文件,或点击直接下载,http,dlap1.dbkan.com,update,dangbeimarket.apk,,并拷贝进u盘,附,当贝市场官网,http,www.dangbei.com,二、将U盘插入盒子中,自动弹出文件选择框点击应用,找到当贝市场安装即可,...。

[全球网报道]据美国有线电视资讯网,CNN,12日报道,两名知情人士泄漏,特朗普已选定南达科他州州长克丽丝蒂·诺姆担任疆土安所有部长,CNN称,诺姆曾是美国国会众议员,据引见,美国疆土安所有担任监管海关和边陲包全局、移民和海关执法局、特勤局等机构事务,据外媒此前报道,特朗普外地期间10日敲定了两项提名,众议员爱丽丝·斯蒂芬尼克将担任美...。
