达摩院跨入 深水区 视频创作平台 寻光 AIGC AI 发布一站式 (达摩院进入条件)
年初,openai 推出文本-视频生成模型 Sora,只需输入提示文本描述,或输入一张图片,Sora 就能生成类似电影大片的逼真场景视频,前所未有的新奇观感,让大众直呼「现实不存在了」。
惊叹之余,Sora 所展现出的神奇「魔法」,也让业界意识到 AI 视频生成在高清晰度、高保真度、高质量方面的巨大潜力与价值。
此后,AI 视频生成模型摇身一变成为科技圈新的宠儿,并一改之前大语言模型一家独大的格局为两者的分庭抗礼。
「Sora热」开始席卷全球,直到现在,国内外相关的 AI 视频生成模型或产品工具都将 Sora 奉为业界标杆,沿着一条类 Sora、比肩 Sora、超越 Sora 的道路狂奔。
但不可否认,相较于大语言模型的「狂飙」,目前 AI 视频生成技术还处于早期阶段,距离「ChatGPT」式的爆发仍有一段距离。即便强大如 Sora,也并非完美,在技术端依旧存在着许多未解的问题与挑战。
为此,在当下, 如何利用大模型技术的强大能力,破解 AI 视频生成领域的难题,更大程度上地释放 AI 生产力,助推 AI 视频生成再往前进一步,是业界在不断思考和探索的重心。
前几天,在世界人工智能大会上,阿里达摩院发布了一站式 AI 视频创作平台——寻光,似乎为 AI 视频生成的发展带来了新的范式。
可控编辑、一致性难以实现,现有 AI 工作流亟待重塑
关注 Sora 的业界从业者应该都知道几个月前的著名「打假贴」事件。
简单来说,当时 Sora 一经发布,OpenAI 为了展示其强大能力和维持话题热度,邀请了一些专业创作者、行业 KOL 等试用 Sora,并时不时放出双方合作生成的创意视频,吸引大众目光。
其中,有一个合作方是来自于多伦多的 Shy Kids 团队,他们使用 Sora 制作的《Air Head(气球人)》短片,因为创意新颖、将艺术与 AI 技术的完美结合,得到了大众的一致赞美,更有甚者将之称为「Sora 史上最佳短片作品」。
可是令人意想不到的是,后来制作团队发文称,《Air Head》并非由 Sora 一键生成,在实际的制作过程中,有大量的视觉效果是经过人工后期编辑而成,才呈现出最终效果。

据他们介绍,整个短片是由多个视频片段组成的,但是在生成不同的视频片段时,很难保证主角始终是个长着黄色气球脑袋的人,有时候气球上会自动「长出」一张人脸,或者依照常识给主角安装一个不符合剧情的脑袋,等等,bug多到创作人员频频吐槽「生成过程很难控制」。
另外,还有角色对象一致性的问题。
在短片中,主角的衣服和那顶标志性的黄色气球脑袋充斥着剧情的始终,「丝滑」到看不出这是由多个视频片段组成的。但实际上,Sora 并不能够保证不同分镜头之间的主体一致性,仅仅依靠输入提示词,就想让主角的衣服和气球颜色保持一致根本不可行。这也是为什么后期需要那么多的人工参与。
彼时新闻一出,业界在感到震惊之余,也意识到,即便是 Sora,生成内容都需要大量的人工参与,难以为这些问题提供良好的解决方案,那么可想而知在整个领域中这些问题的普遍性。
的确如此。
据达摩院视觉技术实验室高级算法专家陈威华介绍,在寻光平台的研发过程中,团队对当下的一众现有视频创作工具进行了大量的调研,并走访了许多视频创作者,对目前业界存在的问题汇总、分析之后发现,当前在 AI 视频生成领域,对于生成内容的可控编辑、一致性等问题是创作过程中的重要需求,也是当前算法面临的最大挑战。
「现有 AI 工作流亟待重塑。」
在他看来,如今各种视频生成大模型已经让大家感受到了 AI 技术带来的福利,给短视频制作提供了各种各样的素材。而在素材齐全之后,接下来要做的就是进一步提升视频制作的效率,解决视频后期编辑中存在的各种问题。
而这也正是达摩院推出寻光平台的初衷。
据了解,此次达摩院发布的寻光平台,定位为 PUGC 一站式 AI 视频创作平台,能够解决 AI 视频编辑不够精准可控的痛点,可支持接入多种视频生成模型,并在行业首次落地基于图层的视频编辑,为复杂视频创作提供了更高效、易用的 AI 工作流。
「我们的目标是用 AI 能力去重塑传统视频制作的整个流程,打造 AI 时代的全新视频工作流。寻光视频创作平台,最大的特点是让用户实现对视频内容的精准控制,同时可以保持多个视频中角色和场景的一致性。」陈威华说道。
「让编辑像操作PPT一样简洁直观,容易上手」
在发布现场,陈威华形容寻光平台的推出,会对当前的视频创作工作流进行优化,使得 AI 视频生成的工作范式发生新的变革,「让编辑像操作 PPT 一样简洁直观,容易上手」。
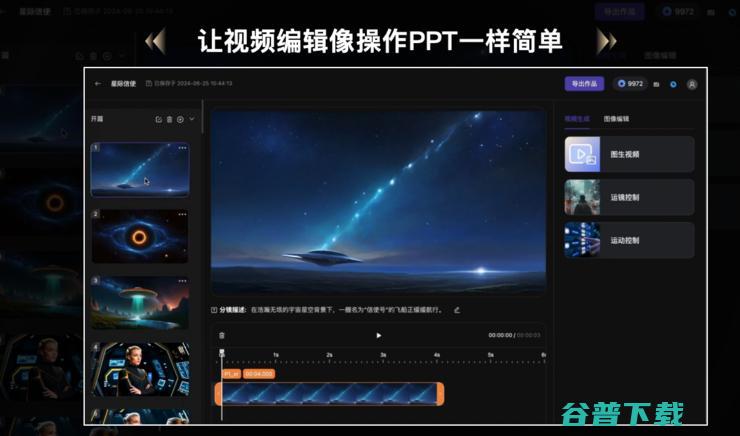
那么,寻光平台具体是怎么做到的呢?其实可以通过几个关键词来认识它。
一个是「一站式 AI 视频创作平台」,如何理解?
大家都知道,当前市面上存在各种各样的 AI 视频生成工具,但是仔细看下来,当创作者想要创作一个视频时,可能需要不同的工具来生成文字、图片、分镜头等素材,最后再把它们汇总放在一起,生成最终的视频。但在这个过程中,创作者往往需要在不同工具间流转,获取不同的素材,不仅耗时,而且容易出错,对创作者来说十分不友好。
而有了寻光平台,直接可以一步到位,不再需要再多个平台中间来回「转场」。
比如,用户在创作时,从剧本创作、分镜生成到素材编辑等全套操作,都可以在寻光平台上完成。另外,通过工作流整合提升了创作全流程的效率,支持对生成及上传素材进行丰富的 AI 编辑,提供人物控制、场景控制、风格迁移、运镜控制、目标新增/消除/修改等十多种 AI 编辑功能,让视频中的元素和对象精准可控。
举例来说,对于视频中的分镜头,用户可以选择在平台上通过剧本自动生成,也可以选择自己上传原始视频素材,由算法切分成多个分镜头。
另外,在创作空间中,如果用户在查看分镜头的时候,发现有些细节需要完善,那么就可以通过编辑工具栏对分镜头做进一步的编辑,不再像传统的视频制作过程那样,需要专门的工具来制作,然后再进行复制粘贴等操作。
可以说,一站式的工作流程,体现了寻光在用户交互上面的友好,而这正是它的一大亮点所在。
据了解,寻光平台是目前业界首个一站式 AI 视频创作平台。
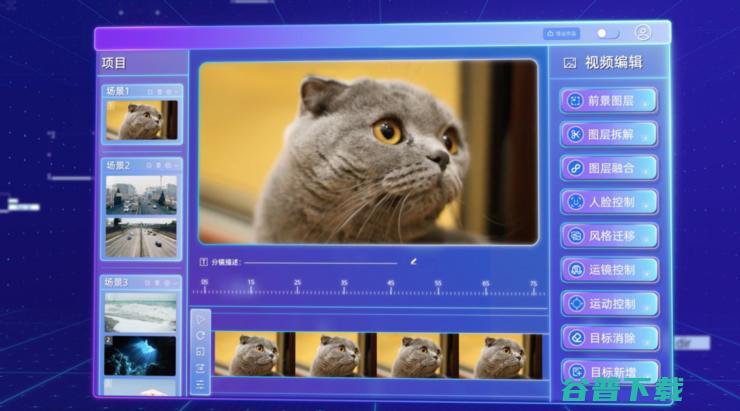
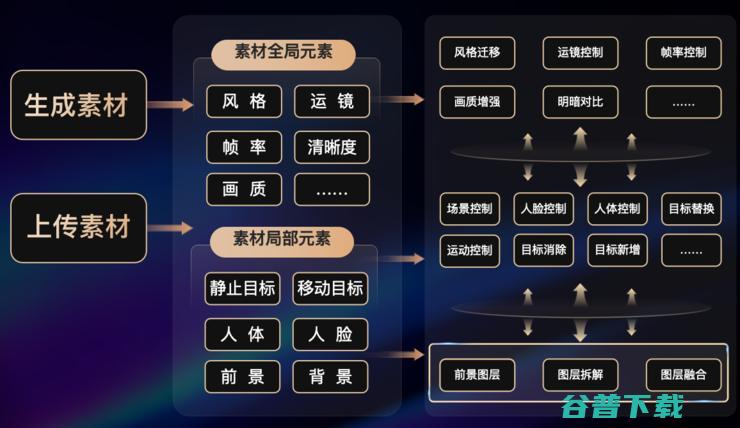
第二个关键词是首创「基于图层的视频编辑」。
前面在 Sora 的案例中提到,AI 视频生成创作中,多个分镜头之间的场景与人物的一致性是至关重要的,其中的一个关键因素就在于分镜头中的视频图层,如果能够基于图层,在语义层面而不是像素层面实现可控编辑,是不是就能保证内容的一致性呢?寻光就是这样做的。
具体来看,寻光平台是通过把视频图层相关的各项能力以一个系统性的方式完整地呈现给用户,让用户基于图层进行视频的编辑、创作,主要包括前景图层的生成、图层拆解、图层融合等环节,从而保证视频的一致性。
比如,寻光平台上有个前景图层功能,用户可以通过输入文本生成符合文本描述的、并且具有透明背景的视频图层。
另外,寻光平台还提供图层拆解功能,即如果用户想从自己的已有视频素材中提取需要的图层,那么就可以使用拆解功能,算法就会把整段视频中对应物体的内容拆解出来,然后形成一个独立的带透明背景的视频图层。


获得了视频图层后,针对不同的创作需求,用户就可以通过寻光平台上的「图层融合」功能,将前景图层与不同的背景进行融合,从而生成各种各样的视频。

比如,以「小和尚练功」的视频为例。
在原视频中,小和尚正在练功,背景环境中有寺庙、竹林。那么,如果想要让小和尚在不同的背景环境中练功,就可以通过寻光平台的图层拆解功能,将小和尚作为一个整体图层拆解出来,然后根据具体的创作需求,将小和尚与不同的背景环境融合,生成新的视频。



看到寻光平台居然可以实现这么强大的功能,是不是有被震撼到?原来 AI 视频生成也可以这么简单。
如今,类 Sora 产品层出不穷。在世界人工智能大会上,不少国内厂商的视频生成模型也展示出令人惊艳的效果。但不可否认的是,它们距离广泛应用还有很长的距离,原因就在于AI视频编辑流程复杂、门槛高,并不是人人都可以流畅玩转。
而达摩院推出的寻光平台,定位为解决当前业界类 Sora 产品涌现之后的编辑与创作问题,聚焦该如何满足人类日益增长的想象力与 AI 生产力之间的需求,希望借此真正释放 AI 生产力。
按照官方所展示的功能,寻光平台将对传统视频制作的整个流程进行重塑,在不久的将来,每个人都拥有、并熟练使用 AI 视频生成工具将变成可能。到那时候,我们或许会距离 AI 视频生成迎来「ChatGPT」式爆发再近一步。
「我们希望寻光视频创作平台就是每一个人手中的利器,是 AIGC 时代,每一个人的专属视频工作室。」陈威华说。
据了解,寻光平台将于近期开放内测,感兴趣的创作者们可以来试用!
官网地址:
原创文章,未经授权禁止转载。详情见 转载须知 。



扇贝单词、扇贝阅读、扇贝听力、扇贝口语四大应用让你在手机上就可以完成整个学习过程,有效地提升英语词汇及听说读写能力。扇贝,知道你在改变。

“Time100时光一百”是中国第一个互联网手表品牌,由中国钟表行业龙头企业明珠星集团和中国互联网行业资深团队共同组建,通过互联网渠道面向全国销售。主要业务形式为在线零售(B2C)、个性化定制(DIY)、集团业务(纪念表/礼品表),官方网址www.time100.cn,7天包退30天包换1年保修300城市货到付款。

商家线下实体商品和网上虚拟产品移到便民平台上,在平台上实现下单、支付、物流配送等一条龙服务。

一团范文网专业提供各类作文、演讲稿、申请书、心得体会、策划书等内容,每日更新全网最新内容,欢迎收藏使用!

上海营邦铝业有限公司

华浒重工专注于对辊破碎机、对辊式破碎机、双辊破碎机、四辊破碎机、双齿辊破碎机、四齿辊破碎机、锤式破碎机、反击式破碎机、圆锥破碎机以及移动式破碎站等主要产品的生产。此外,我们还提供各种砂石生产线、带式污泥压滤机、布袋式除尘器、筛分设备、给料机、布料器、皮带机、除铁器和电控柜等辅助配套设备。欢迎来电咨询定购电话:15753694888

浙江宏盛特钢有限公司是专业生产254SMO不锈钢管厂家,公司S31254超级奥氏体不锈钢管已通过国家A级压力管道认证,欧盟PED认证及英国劳氏质量管理体系认证。产品主要应用于耐海水腐蚀设备和造纸漂白装置及烟气脱硫构件及炼油装置等。

投资经济网为用户提供国内外财经新闻资讯,涵盖股票、公司、财经、理财、科技、消费等频道,致力于打造最新最及时最全面的投资金融平台。

蓝鲸支付是无需签约、实时到账、无手续费的一款支付平台软件,团队提供专业对接指导,服务优质,深受广大用户喜爱。

攻略日记网提供各类游戏相关的攻略心得,包括网游攻略、手游攻略、心得秘籍、游戏技巧、游戏资讯等,致力于最新、完整、有特色的游戏资讯以及攻略!

美图奇想大模型开放平台是美图公司推出的AI服务平台,将美图秀秀、美颜相机、Wink等经市场验证的图像和视频算法赋能开发者与企业数字化建设,为企业及开发者提供领先的人脸人体、图像识别与处理、生成式AI等技术服务及各行业解决方案。

资源狐网站(www.ziyuanhu.com)收集了世界各国的精品主流网站,包括国外新闻网站,国外视频网站,国外音乐网站,国外社交网站,国外中文网站,国外购物网站等,力求做到最新、最精、最全面,免费为广大网民提供最方便快捷的服务。


现在的父母不仅重视孕前护理,同样也非常重视产后的母婴护理等问题,备孕妈妈从产前道产后的期间里使用到大量的母婴用品,包括孕妇服饰、孕妇营养品、孕妇护肤品、婴儿服饰、婴儿奶粉、婴儿尿裤、婴儿护理产品等,近几年来由于二胎政策的开放,加速了孕婴店的市场发展,也为准备创业的人群带来好的智慧之选项目,有眼光的智慧之选商发现孕婴行业存在很大的市场需...。

要开一家店就要考虑到市场的需求,也要考虑是否有钱赚,这才可以是为自己负责,为家庭负责,自酿啤酒是一个新的品牌,而且在零售行业中也是人们非常信赖的一个时尚饮品,至今对于创业者来说就是要考虑到未来财富的问题,所以今天的话题就是,自酿啤酒加盟店有钱赚吗,自酿啤酒在酒水的行业中非常的重要,而且酒精的度数很低,非常的受男生和女生的欢迎,那么这样...。

正文,在日常生活中,我们时常会遇到一些令人困惑的情况,比如家中的宝贝物品——无论是衣物、书籍还是其他珍贵收藏——突然间变得潮湿,这不仅让人感到困扰,甚至可能影响到这些物品的价值和使用,那么,究竟是什么原因导致了这种情况的发生呢,让我们一起揭开这个谜团,首先,我们需要明确一个概念,宝贝在这里不仅仅是指孩子或宠物,而是泛指那些我们珍视并精...。

发表在极米投影仪2019,1,1316,00极米H2使用体验,浅谈几点优缺点优点,1.晚上关灯的情况下视频效果特别棒,清晰度和亮度都非常棒,3米左右的距离应该有120平米左右2.内置了很多app,电视直播,综艺节目,纪录片都很多,当然有很多是付费VIP内容,不过免费的内容也很多,稍微等一下广告就好了3.轻便,便携,包装也很精致4.质量...。

发表在综合交流大区2023,5,2913,33随着投影技术的不断提高,万元内也出现了越来越多的4K投影仪,并且伴随着618活动的到来,不少4K投影仪值得推荐,具体618哪些4K投影仪值得入手呢,下面就为大家详细分享一下,看看618万元内哪些4K投影仪值得推荐,618哪些4K投影仪值得入手,第一款,当贝F6推荐理由,当贝F6采用全新4L...。

发表在哈趣投影仪2024,11,809,25陈赫在近日直播中推荐哈趣Q1投影仪,这是怎么样的一款投影仪呢,究竟是哪些方面赢得了陈赫的青睐,下面就带大家来了解这款投影仪,看看哈趣Q1各方面有什么特点,哈趣Q1搭配一体化云台支架,可自由调整投射角度,外观小巧便携、颜值高,百元价位的投影仪却采用了全新一代EngineX全封闭式光机,相比同价...。

正月是农历新年的开始,人们往往将它看作是新的一年年运好坏的兆示期,所以,过年的时候,禁忌,特别多,当然,各个地方的风俗习惯不一样,过年的禁忌也是不一样的,...。

2024年11月12日,广西壮族自治区桂林市中级人民法院一审地下宣判广东省人大常委会原党组成员、副主任陈继兴行贿、应用影响力行贿案,对原告人陈继兴以行贿罪判处死刑,缓期二年口头,剥夺政治权益永恒,并处没收团体所有财富;以应用影响力行贿罪判处有期徒刑二年,并处分金人民币二十万元;选择口头死刑,缓期二年口头,剥夺政治权益永恒,并处没收团体...。

[全球网报道记者姜蔼玲]韩国,中央日报,11日报道称,正在华盛顿加入北约峰会的韩国总统尹锡悦外地期间10日与乌克兰总统泽连斯基会面,韩国国度安保室当日举行资讯颁布会,称将为乌克兰及其国民提供所需声援,此信息经韩媒报道后,引发不少韩国网友不满,有网友称,,此举,令人寒心,,非要四处抚慰抗争迸发吗,报道称,今日晚宴前,尹锡悦夫妇和泽连...。

外地期间7月7日早上,一名43岁的西班牙游客在南非家养生物包全区下车拍摄象群照片时,被大象踩死,据悉,这名43岁的女子与未婚妻和另外两人一同旅游南非的匹林斯堡国度公园时,遭逢袭击,他们先是不时开着自己的车到处观赏,而后发现了3头大象和3头小象,随后,女子从车中爬进去,走向大象,想要拍照,南非西北省公园和旅游局在申明中称,,虽然他的同行...。

如何辨别12星男是否真正爱你?_魔女道士_新浪博客,魔女道士,

全球画质天花板被捅破!索尼量子点OLED旗舰A95L强在哪里,索尼,彩电,天花板,oled

医美行业得到了快速的发展得益于人们现在对于自己外在形象注重程度越来越深,现在很多医美美容的品牌建设符合了消费者们需要,市场发展前景是非常巨大的,比如百莲凯美容院就具有较好品牌口碑,也让创业者想知道,百莲凯美容院服务好吗,价位高吗,百莲凯美容院是一个医美和美容相互结合模式运营的品牌,因此与美容行业内普通美容院有一定区别,可以针对消费者具...。
雷锋网AI科技评论按,近期中国计算机学会,CCF,和福州市人民政府共同举办了2017中国计算机大会,CNCC2017,新闻发布会,随后,雷锋网采访了CNCC大会论坛和活动委员会主席,视觉信息处理领域专家,我国类脑计算研究方向的主要推动者之一黄铁军教授,黄教授现任北京大学计算机科学技术系主任,长江学者特聘教授,国家杰出青年科学基金,主要...。

雷锋网消息,据印度媒体报道,7月9日,三星已经在印度诺伊达,Noida,的Sector81建成了全世界最大的手机工厂,该工厂占地35英亩,约212.5亩,印度总理莫迪出席揭幕仪式,此时正逢韩国总统文在寅对印度进行国事访问,作为韩国最大的跨国企业集团,三星也得到了总统文在寅的站台,凭借这一新设施,三星将把诺伊达目前的手机容量从每年68...。

发表在明基投影仪2022,6,910,14明基GV30投影仪是一款拥有旋转功能的便携式家用投影仪,不仅拥有内置电池更获得过日本GOODDESIGN设计大奖;外观这么出众精致那这款投影仪的内部配置又是如何呢,四千多的价格适合作为家用投影仪来使用吗,下面一起来看看具体参数分析,明基GV30怎么样?答案是比较好用,原因价格贵,画质不好,但是...。

随着健康意识的提升,越来越多的人开始关注饮食对身体健康,特别是肾脏健康的影响,然而,近期有传闻称葡萄可能成为肾衰竭的,触发器,,引发广泛讨论,本文将深入探讨葡萄与肾脏健康的关系,并介绍另外三种在特定情况下需谨慎食用的水果,帮助读者更好地维护肾脏健康,葡萄与肾脏健康葡萄的营养价值葡萄作为一种广受欢迎的水果,富含多种营养成分,包括维生素C...。
