无需依赖英语数据 100种语言互译 脸书推出 M2M (无需依赖英语翻译)
译者:AI研习社( 季一帆 )
双语原文链接: Is The src="https://static.leiphone.com/uploads/new/sns/article/202011/1605163209467627.png?imageMogr2/quality/90">
机器翻译(MT)能够打破语言障碍,将不同语种的人团结起来,为不同人群提供有关 COVID的权威信息 以帮助他们 避免感染 。得益于我们在 低资源机器翻译 及 翻译质量评估 的最新 研究与进展 ,现在,我们每天能够在FAcebook News Feed上提供近200亿次翻译。
典型的MT系统需要对不同语言和任务单独构建翻译模型,然而,这样的方式却并不适合Facebook,因为在Facebook上,有超过160种语言发布的数十亿条内容。现在的多语言系统虽然可以一次处理多种语言,但却是通过英语数据作为源语言和目标语言之间的中转,从而降低了准确性。因此,我们需要一个真正的多语言机器翻译(MMT)模型,该模型可以在任何语言之间直接进行翻译,这将为我们的社区提供更好的服务。
我们已经在Facebook对MT进行了多年的研究,现在终于可以自豪的宣布:我们首次构建了一个的大型MMT模型,该模型可以在100种不同语言之间直接进行翻译,而无需依赖英语作为中转语言。同时,我们的多语言模型的表现完全不弱于传统的双语模型,甚至要比以英语为中转的多语言模型提高了10个BLEU点。
通过新颖的挖掘策略,我们首次构建了一个真正的“多对多”翻译数据集,该数据集有75亿个句子,涵盖100种不同语言。最终,我们构建了一个具有150亿个参数的通用模型,该模型可以捕获相关语言的信息,并能够学习更加多样化的语言和形态特征。开源地址 见此 。
不同语言的亿万训练语句挖掘
建立多对多MMT模型的最大障碍之一是训练数据,即不同语言之间直接的高质量翻译数据,而不是以英语作为中间语言。然而现实情况是,比起法语和中文的直接翻译数据,中文和英文以及英语和法语的翻译数据更易获取。此外,训练所需的数据量与支持语言的数量成正比,例如,如果每种语言需要需要10M句子对,那么10种语言就是1B句子对,100种语言需要100B句子对。
构建包含100种语言的75亿句子对的多对多MMT数据集是艰巨的任务,由于我们多年来积累了不同的资源,包括,和,因此构建该数据集是可行的。为此,我们创建了新的LASER 2.0,改进了fastText语言识别,从而提高挖掘质量,相关的训练与评估脚本也会开源。当然,所有这些数据都是开源合法的。
Facebook AI提出的多对多的多语言模型是多年研究的结晶,MT模型、数据资源和优化技术等方面均是开创性的。本文会重点介绍一些主要成就。除此之外,我们通过挖掘ccNET创建了庞大的训练数据集,该数据集是基于fastText的(是处理单词表示的重要方法);基于CCMatrix的LASER库可将句子嵌入多语言嵌入空间中;CCAligned则能够根据URL匹配来对齐文档。进一步,我们开发了改进版本LASER 2.0。
即使使用LASER 2.0等先进技术,挖掘100种不同语言/4450种可能语言对中的任意一类训练数据也需要大量的计算。由于数据规模巨大,为方便管理,我们首先关注翻译请求最多的语言。因此,我们综合数据规模和数据质量对挖掘目标进行优先排序,舍弃了对极冷门语言的,如冰岛语-尼泊尔语或僧伽罗语-爪哇语。
接下来,我们引入一种新的过渡挖掘策略,该策略根据地理和文化相似性将语言分为14个语言组。之所以这样做,是因为相同国家或地区中的人们会有更多的交流,这样的翻译数据质量更高。例如,将印度地区的语言分为一组,包括孟加拉语,北印度语,马拉地语,尼泊尔语,泰米尔语和乌尔都语。类似的,我们系统挖掘了不同组的全部语言对。
为了在不同组的语言之间建立联系,我们从每组中选择少量过渡语言,一般是一到三种主要语言。在上端的示例中,我们选择印地语,孟加拉语和泰米尔语作为印度雅-利安语言的过渡语言。然后,我们并行挖掘了过渡语言2200种组合的所有数据,最终得到包含75亿条数据的训练集。由于翻译数据是可以在两种语言之间相互进行训练的(如en-> fr和fr-> en),因此我们的挖掘策略采用高效的稀疏挖掘方式,通过一个模型就能实现100x100(共9,900个)种组合的数据挖掘工作。
在并行挖掘过程中,会得到一些低质量、低资源的翻译数据,基于此,我们采用反向翻译方法对这类数据进行扩充,该方法帮助我们在年和年的WMT国际机器翻译比赛中获得第一名。具体而言,如果我们的目标是训练汉语到法语的翻译模型,那么我们首先会训练法语到汉语的模型,然后将法语反译成汉语。我们发现,在 数据规模较大 时(如上亿语句)该方法非常有效。本研究中,我们使用反向翻译的合成数据对挖掘数据集进行扩充,同时,我们还使用反向翻译为那些未标注的语言对创建训练数据。
总体而言,相比仅依赖挖掘数据训练的模型,结合过渡策略和反向翻译的训练数据学习到的模型在100个反向翻译任务中BLEU平均提升约1.7。有了丰富、高质量的训练数据集,多对多翻译模型成为可能。
此外。我们还发现,对于没有训练数据的一个语言对,零样本(zero-shot)想过显著。例如,如果模型的训练数据只有法语-英语和德语-瑞典语,通过zero-shot我们可以在法语和瑞典语之间实现翻译。我们的M2M-100模型也表明,对于没有训练数据的语言对,融合zero-shot的多语言模型表现优于以英语作为过渡的多语言模型。
MMT模型-150亿参数,翻译快又准
多语言翻译中的一个挑战是,单一模型必须要能够从不同语言获取信息。为此,通常的方法是增大模型,添加面向特定语言类型的参数。同时,过量训练数据训练的模型包含一些无关参数,舍弃这类参数不仅会压缩模型,还避免了这些参数对翻译任务的干扰。最终,我们当将模型大小缩放到含120亿参数,发现在不同语言的翻译任务中BLEU平均提升约1.2,但随着参数的继续减少,模型性能开始下降。这样,通用多语言翻译模型含120参数,加上面向特定语言的32亿稀疏参数,最终的模型有150亿参数。
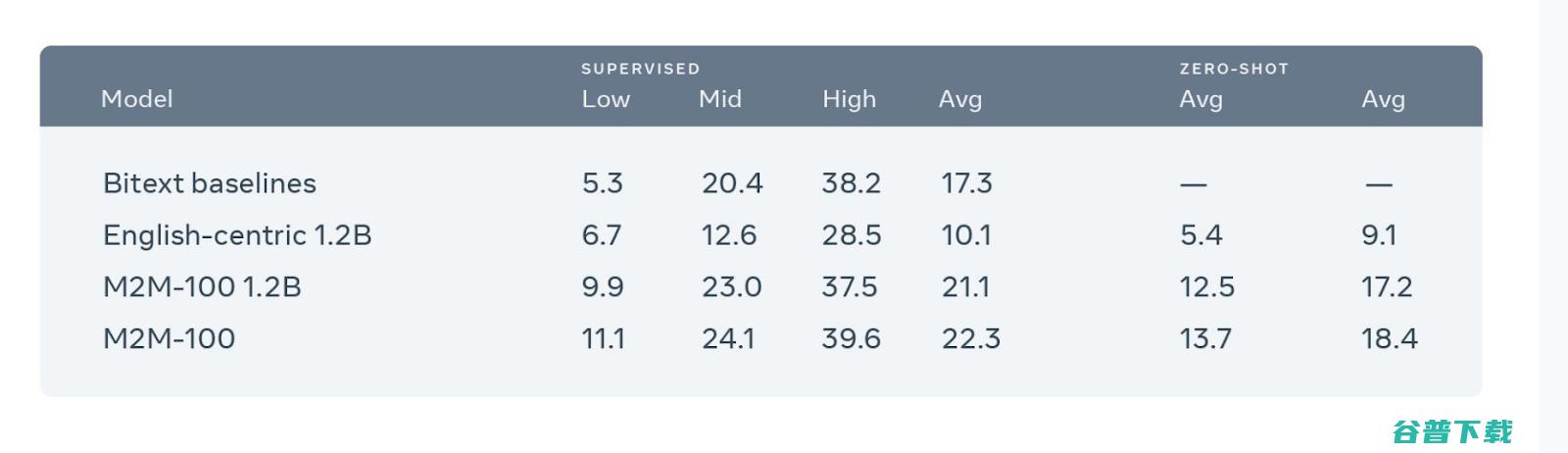
我们将该模型与双语基准模型和以英语作为过渡的多语言模型进行比较,如上图所示。第一行表示由24个编码器层和24个解码器层组成的包含12亿参数的基线模型,第二行是以英语为过渡的的多语言翻译模型。接下来,分别是包含12亿参数和120亿参数的M2M-100模型,可以看到,更多参数的模型BLEU提升1.2。
通过增加Transformer的层数以及每层的宽度,我们训练得到更大的模型,该模型依然训练高效、收敛快递。值得注意的是,该多对多翻译系统首次应用了——一个是专用于pipeline和张量并行运算的新的PyTorch库。我们建立了通用架构,以通过Fairscale并行训练大型模型,避免了单gpu的限制。同时,我们应用 ZeRO优化器 , 层内模型并行 和 pipeline模型并行 来加快模型训练。
然而,120亿参数的多语言翻译模型是不够的,我们要训练更准确高效的模型。现在有许多研究工作使用多模型集成方法,即训练多个模型,并将其用于相同源语句进行翻译。为降低多个模型训练的复杂性和计算量,我们引入多源自组技术,该技术将源句子翻译成多种语言以提高翻译质量。参照和 Depth-Adaptive ,我们训练得到一个具有公共主干和不同语言特定参数集的模型。该方法能够按语言对或语言族将模型进行分块,非常适用多对多模型。最终,将压缩的多语言模型参数(12B)与特定语言参数(约3B)相结合,我们的模型不仅能像大型模型那样具有广泛扩展性,同时还能面向不同语言进行针对处理。
全力打破不同语言间的壁垒
多年来,人工智能研究人员一直在努力构建一个能够理解所有语言的通用模型。这样一个支持所有语言或方言的通用模型将为所有人提供更好的服务,令人满意的翻译将打破数十亿人的语言壁垒,让他们更加平等的了解这个世界。这项工作使我们更加接近了这一目标。
在长久的研究中,我们在预训练语言模型,微调和自我监督学习等方面发展迅速,研究成果振奋人心。这一系列的研究将进一步提高我们的系统使用未标记的数据来理解低资源语言文本的能力。例如,是一个强大的多语言模型,它可以仅从一种语言数据中进行学习,然后扩展到100种语言。针对多语言BART任务,是首次预训练全模型之一。最近,我们提出新的自我监督方法,通过许多不同语言的未标记数据来挖掘不同语言的并行句子,迭代训练更好的多语言模型。
我们将持续关注前沿进展,学习最新技术,探索MT系统的部署方式以及更加专业的计算架构,以继续改进翻译模型。
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



江苏天龙玄武岩连续纤维股份有限公司是集连续玄武岩纤维及其复合材料制品的研发、生产、销售、设备制造、技术咨询和服务为一体的国家级高新技术企业。配置完备的拉丝设备、后加工设备、复合材料生产设备及相关配套检测设备。可为客户提供多种规格的玄武岩连续纤维及短切纤维、纤维纱线、纤维织物等各类纤维制品,纤维增强筋材、型材、管材等各类复合材料,以及复合纤维抗火密封技术、土工格栅、土工布等各类功能性产品,并提供相关的技术服务。

浙江丁一不锈钢有限公司是一家专业生产新时代片式球阀、DY一片式球阀、二片式球阀、三片式球阀、不锈钢一二三片式球阀(提供国标、美标、日标、德标)非标定做。欢迎来电咨询:0577-86878818

本网站专业发布远程教育学习资料等
有限公司")
致力于离子液体(ILs)产、销、研,自主知识产权生产技术,以控制安全环保生产、产品质量和一致性为目标,Tel:021-38228895/13816393132

青岛凌格风空压机(电话:139-6428-7530)专业提供青岛空压机,青岛螺杆空压机,青岛城阳空压机的整机及配件销售,专注于青岛空压机维修保养及青岛空压机变频节能改造。

论文哥免费论文查重检测,首款免费论文检测软件,为毕业生提供专业的论文查重,查重入口,查重软件,查重网站等一站式服务

北京市万宏伟业环境工程有限公司主营产品有:脱硫脱硝除尘设备、布袋除尘器、湿式静电除尘器、锅炉除尘器、旋风除尘器、静电除尘器、催化燃烧设备、矿山除尘器、单机除尘器、木工除尘器、滤筒除尘器、UV光氧净化器、活性炭吸附箱、等离子净化器、焊烟净化器、打磨工作台、喷淋塔、除尘布袋、除尘骨架、星型卸料器、、通风蝶阀、插板阀、其它除尘器配件等。

欢迎来到星座运势网,这是一个专注于探索和传播星座,生肖及传统文化的网站。在这里我们让您遨游在知识的海洋里,让您感受到中华文化的博大精深。

软文帮是专业脚本定制与软件开发平台,提供定制化辅助脚本、创新软件开发及行业新闻与实用技术文章,助您掌握辅助脚本及软件资讯,解决技术难题。

XXXj教育培训

拓程科技公司网站。


如今的网络时代短视频行业如此受欢迎,制作各种各样的视频发表到网上,不仅能够得到一些粉丝的喜爱,同时也能靠着短视频行业获得收入,免费的视频剪辑软件有哪些?如果您也想从事短视频行业的工作,一定要了解这些剪辑视频的软件,只有将这些软件了解清楚,才能制作出更有品质的视频,如果觉得视频有些大,而且内容有些多余,想要将不需要的内容剪掉,就可选择这...。

可以打团战的手游都有着多人联机的玩法以及快速匹配机制,多人合作打团战的战斗过程足以让大家热血沸腾,那么人气较高的团战手游下载合集情况怎么样,本期文章讲解的五个多人团战类型游戏刺激性都是很强的,想跟队友合作一起打团战的小伙伴可以试试这些团战手游,1、,王者荣耀,如果你想跟好友一起在MOBA游戏中参与刺激的团战,那么下载王者荣耀这款国民级...。

今天我们来推荐几个搜索引擎,那么我就要问了,有一个百度用着不就ok了吗,为什么还要使用其他的搜索引擎?因为搜索引擎的算法不同,展示结果也不相同,首先明确搜索引擎并不能检索到互联网上所有的网页,它可以检索到的,只是它的爬虫程序爬取并且存到数据库中的网页,这里我简单解释一下通用搜索引擎的原理,某一个搜索引擎需要用爬虫程序在互联网上爬取网页...。

央视315曝光多个线上黑幕,多家科技互联网公司被点名昨晚央视315晚会点名曝光了多家科技互联网企业,范围涉及人脸识别滥用、线上简历泄露、大数据杀熟、在线教育培训、线上购物等用户投诉热点,其中,提供擅自收集消费者信息的人脸识别技术的万店掌、雅量科技、悠络客、瑞为技术被点名;泄露求职者简历的智联招聘、前程无忧、猎聘被点名;360搜索因涉及...。

2月2日下午,李彦宏向百度全员发出名为,进攻时刻,业务聚焦,组织调整,的通知邮件,通报百度即将进行的业务大重组,重组后百度拥有新三大事业组,搜索业务群组,新兴业务事业群组和移动服务事业群组,此次,百度业务重组的核心指导思想是,连接人与服务,,意在构建生态、创造新的市场,并提供技术支持,而新成立的移动服务事业群组是是移动云事业部和LBS...。

在国产SUV车型里,哈弗大狗系列自2020年上市以来,依靠不错的性能和品质收获了全球30万用户的认可,作为狗品类重要的一员,新款哈弗大狗于7月25日正式上市,官方售价12.39,14.99万,共推3款车型,为了满足用户的多种用车需求,新款哈弗大狗在外观、内饰、车机智能、动力以及安全等方面都做了相应的升级,外观方面,新款哈弗大狗在整体造...。

日前MakerBot已经宣布,它将不再生产自己的硬件,在接下来的六个月内,公司将3D打印机和其他产品的生产工作交接给Jabil,后者是全球三大合同制造服务商之一,在中国拥有工厂,其结果是,该公司将关闭纽约布鲁克林区的工业城市综合体的制造业务,并进行裁员,而MakerBot总部和其他团队,包括设计、工程、物流和维修,将继续留在布鲁克林,...。

雷锋网消息2020年的头一天,一家华为授权的智能无人售货店在武汉正式开业,据了解,这家无人售货店位于光谷新发展国际中心,外形酷似一个环形的飞碟舱,通过透明的舱壁可以看到里面整齐罗列的商品,与其说这个无人售货店是一个店,倒不如说是一个大型的自动售货机,因为它通体封闭,购买前消费者既无法接触商品也不能进行体验,商品的拣选和出货完全依靠机械...。

发表在米家投影仪2022,9,720,10小米投影仪mini是一款便携式投影设备,具体这款投影仪有什么特点呢,下面就通过详细的参数配置分析了解小米投影仪mini,看看小米投影仪mini究竟怎么样,是否值得用户入手,小米投影仪mini怎么样,1.光学参数在画面亮度方面,小米投影仪mini的实际亮度为250ANSI流明,只适合在黑暗环境下...。

发表在专业问答2022,2,515,53展示机型信息,品牌型号,当贝X3系统版本,当贝OS2.0投影仪80000亮度大约是4000流明,80000亮度通常指的是投影仪光源的亮度值,而目前常用的ANSI流明单位是投影仪投射到墙面上所产生的画面亮度值,因此ANSI流明的亮度值会相对低一些,投影仪80000亮度是多少流明投影仪80000亮度...。

总台记者外地期间14日得知,哈马斯信息人士称,哈马斯,汗尤尼斯旅,指挥官拉法阿·萨拉马在以军的袭击中身亡,该信息人士泄漏称,拉法·萨拉马过后在哈马斯军事指导人穆罕默德·戴夫的身边,他的尸体已被找到并掩埋,但该信息人士拒绝泄漏戴夫能否在袭击中身亡,外地期间13日午间,以色列国防军袭击了加沙南部汗尤尼斯以西的马瓦西地域,称这一袭击的指标人...。

二手车限迁意思就是当地的一些排放规范过低的车辆,不准许迁入本地,所谓,限迁,,是指一些中央关于外省或许外市的二手机动车,采取限度环保规范、限度年份等措施,以防止这些车辆少量流入本地市场,深刻易懂的解释,二手车限迁的意思是他乡过户须要合乎迁上天的上牌政策,就是指,当地的一些排放规范过低的车辆,不准许迁入本地,中央政府对外解释的理由是往往...。

农场主题的经营游戏早在十多年前智能机时代就存在不少,农场经营类的作品耐玩性极强还有着非常温馨治愈的森系背景,那么十年前的农场游戏下载排行情况怎么样,接下来小编介绍的农场经营手游都有着极高的辨识度,颇具年代感的经典经营玩法让许多农场手游爱好者痴迷,1、,模拟,在这款农场经营作品中大家可以跟常见的农村动物一起经营农场,满屏幕的可爱牲畜都可...。
那个曾经是东半球最好看的要收购苹果手机的锤子再也回不来了,锤子论坛也走到了自己的尾声,但罗永浩还有自己的精彩,锤子论坛,使用的用户少了很多,热帖推荐也不怎么更新了,热帖排名前三的帖子,皆为2019年或2020年的帖子,其它教程类、公告类文章,大多是去年及以前的帖子了,锤子论坛的使用用户如此之少,锤子官方将其关闭,也是情理之中的事了,随...。

读招书的时候,我们发现了一个有意思的细节——36氪的资深内容报道团队一共有42个作者,约占36氪总人数的十一分之一,瑞幸咖啡创始人钱治亚,42岁,拼多多创始人黄铮,38岁,趣头条创始人谭思亮,38岁,36氪创始人刘成城,31岁,以上列出的,是最近一年来赴美上市的部分知名公司创始人及其年龄,在这份名单中,36氪和它的创始人刘成城都显得有...。

球鞋鉴定师到底是怎样的一种存在?一只手机,几张图,三五秒钟,就能决定一双鞋的生死,也能让屏幕另一头的石头落地,是喜是悲,全靠网络那端发来的一个字,要么,真,,要么,假,不过这也来得痛快,就怕给个,无法鉴定,,让人哭也不是,笑也不是,狂热与理性并存,潮流态度与资本金钱同在,炒鞋这件事已经大众议论得足够多,只是这场热得发烫的潮流里,并不...。

孩子的身体健康是每个家长重视的问题,很多父母对于传统的婴童养生服务十分的青睐,为了就是孩子身体更加的健康,现在比较受欢迎的方式就是小儿推拿,专业的中医理疗养护,可以给孩子带去健康,小熊妈妈小儿推拿是一家受欢迎的品牌,凭借着专业的技术,还有优惠的价格,提升门店的生意,现在创业者也看到商机,产生加盟想法,那么,小熊妈妈小儿推拿怎么加盟,小...。
