必读 AI专家们推荐的 Part 论文 2 (ai 专家)
译者:AI研习社( 季一帆 )
双语原文链接: ‘Must-Read’ AI Papers Suggested by Experts - Pt 2

我们之前写了一篇文章,向大家推荐了一些AI必读论文,引起很好的反响。现在,我们推出了第二篇文章。这次推荐的论文依然是分量十足、诚意满满,各位推荐者都认为自己推荐的论文是AI人员必读的经典之作,不知各位读者怎么看。现在,我们来看看这次入选的是哪些论文吧!
不过在这之前,我还是向您推荐 我们之前的那一篇文章 ,那篇文章也绝对值得一读。
推荐人:MILA博士研究员,Alexia Jolicoeur-Martineau
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization f-GAN: 使用变分散度最小化训练生成神经采样器
Alexia提出可以将若干分类器视为估计f散度,于是,GAN可以被解释为最小化估计和散度。在论文中,Microsoft Research的研究人员详细介绍了相关工作、论文方法和实验验证。 阅读原文 获取更多信息。
Sobolev GAN
本文将WGAN-GP中的梯度范数惩罚视为约束鉴别器,从而使其unit-ball具有梯度。论文的数学论证极其复杂,但我们只要记住,关键在于可以对鉴别器添加各种各样的约束。这些限制条件可以防止鉴别器过分严格。论文中的Table1非常重要,我曾数次翻阅该论文,只为查看Table1,该表显示了可用的各种不同约束。 阅读原文 获取更多信息。
推荐人:DeepMind高级研究员,Jane WANg
老实说,我并不会觉得有哪篇论文要比其他论文更重要,因为我认为所有论文都是相互依存的,而科学是协作的成果。但还是要说,就我个人而言,还是会更加偏爱一些论文的,从这些论文中我受益匪浅,但这并不是说其他论文不好。这只意味着,我个人比较喜欢以下两篇论文。
Where Do Rewards Come From?
本文提出了一种通用的奖励计算框架,在给定适应度函数和环境分布的情况下,该框架给出了最优奖励函数的概念。实验结果表明,在此最佳奖励函数中,传统的外在和内在行为概念均有体现。 阅读原文 了解更多信息。
推荐论文2: Building Machines that learn and think like people (让机器向人类一样学习与思考)- Brenden Lake et al
本文回顾了认知科学的进展,表明要想实现真正像人类一样学习和思考的机器,需要当前研究的创新性改进。具体来说,我们认为这样的机器应具有以下能力:1)建立可解释的、可理解的世界因果模型,而不仅仅是解决模式识别问题;2)在物理学和心理学层面进行学习,以支持和丰富机器所学知识;3)利用相关性以及学会学习使机器快速获取知识,并扩展到新的任务和情况。 阅读原文 了解更多信息。
推荐人:WinterLight labs机器学习负责人,Jekaterina Novikova
推荐论文1: Attention Is All You Need (“笨蛋”,根本问题是注意力)- Ashish Vaswani et al.
在NLP科学家于2017年提出" Attention is All You Need "之后,BERT或GPT-2 / 3等大型预训练语言模型如雨后春笋般出现。这些模型令人称奇的结果不仅引起了ML / NLP研究人员的强烈关注,在公众中也引起波澜。例如,2019年,OpenAI宣称GPT-2“太过危险而不能公开”,这说法简直让人抓狂,但事实是,GPT-2确实能够生成与真实新闻无法区分的假新闻。几周前发布的GPT-3甚至被称为“自比特币以来最大的新闻”。 阅读原文 了解更多信息。
推荐论文2: Climbing towards NLU: On Meaning, Form, and Understanding in the Age of>)- Emily M. Bender et al.
AI大热,但我希望向你泼点冷水,冷静下来好好看看2020年7月ACL会议的最佳主题论文-“迈向NLU:关于数据时代的意义,形式和理解”。作者认为,尽管现有模型(例如BERT或GPT)成果丰硕,但与人类相比,很难说它们是理解了语言及其含义。作者解释道,理解是人们在交流中,根据所说话语明白对话意图时发生的。这样,如果仅仅是语言文字,没有现实生活中的交互作用,则不可能学习和理解语言。换句话说,“从一定形式中是学习不到意义的”,这就是为什么即使巨大且复杂的语言模型也只是学习意义的“映射”,而不能了解意义本身。 阅读原文 了解更多信息。
推荐人:加拿大国家银行,AI科学首席顾问,Eric Charton
推荐论文1: The Computational Limits of Deep Learning (中的计算极限)- Johnson et al
麻省理工学院和IBM Watson Lab发表的这篇论文对DL出版文献进行汇总分析,介绍了DL模型训练计算量的增加与其性能表现间的相关性。同时论文指出,随着计算能力的提高,模型性能改善呈放缓趋势。 阅读原文 了解更多信息。
推荐论文2: Survey on deep learning with class imbalance(关于类别不平衡的DL综述). Journal of Big>
该论文汇总介绍了不同DL是如何处理类别不平衡问题,该问题存在于信用建模、欺诈检测或医学检测/癌症检测等各种工业应用中。论文对不同方法进行比较分析,并着重介绍了各种方法处理类别不平衡数据的差异,为进一步的研究指明方向, 阅读原文 了解更多信息。
推荐人:NASA,机器学习主管,Anirudh Koul
也许几年后回头看,人们会发现2020年似乎是自我监督元年。自监督学习就是用非标注数据进行预训练,然后在有限标注的下游任务进行微调。仅在2020年6月之前,众多SOTA被先后打破,包括但不限于PIRL,SimCLR,InfoMin,MOCO,MOCOv2,BYOL,SwAV,SimCLRv2等众多自监督学习方法引起广泛关注。通过以下这个例子来感受一下这些方法究竟多么让人称奇吧。仅仅使用不带标签的ImageNet,然后用1%的标签进行微调,SimCLRv2模型就可以在ImageNet数据集上实现92.3%的Top-5准确性。很神奇吧,仅仅1%的标注就可以取得这样令人满意的结果。对于缺少标注数据的领域如医学、卫星等来说,自监督学习就是这些领域应用的福音。
推荐论文: A Simple Framework for Contrastive Learning of Visual Representations (一个简单的图像表示对比学习框架)- Ting Chen et al
优秀的论文不仅实验严密、结果出色,而且还能简介明了的向读者清晰的表达自己的关键思想。SimCLR就是如此,简洁明了,效果出色,这使其成为对比学习领域最值得阅读论文之一。研究表明,在特定数据集中,通过数据增强策略获得更好的图像表示,对于对比学习至关重要。希望更多研究者关注到SimCLR,在X射线、MRI、音频、卫星图等领域推动该方法进一步的研究与发展。
推荐人:摩根士丹利副总裁,NLP/ML研究员,Oana Frunza
Revealing the Dark Secrets of BERT (BERT探秘)- Olga Kovaleva et al.
BERT Transformer结构极大推进了机器对文本数据的表示和理解能力,对于NLP的研究发展具有革命性的意义,可以说这就是NLP的“ImageNet”。Transformer架构的关键在于自我注意机制,“BERT揭秘”一文便对注意力的背后原理进行了探讨。
更准确地说,这项研究量化了注意力头捕获的语言信息,包括句法和语义关系等。此外,论文还进一步研究了自我注意模式的多样性及其对各种任务的影响。
该论文的研究聚焦于深层次理解强大的transformer架构,不仅利于推动该领域的进一步发展,而且有利于研究人员做出更明智的决策。也就是说,如果知道某些精简的小型体系结构会产生相似的性能,这就意味着在架构设计和空间占用方面有了更好的选择。
阅读原文 了解更多信息。
推荐人:捷豹路虎,高级数据科学家,Tamanna Haque
推荐书籍: Deep Learning with R (R语言)- François Chollet et al.
本文从概念到实践对深度学习进行详细介绍,对于理解深度学习具有重要帮助。由于黑匣子性质,神经网络不仅训练成本高昂,而且不具可解释性。同时,最近数据保护法规的更改将推动可解释AI的研究,神经网络受到挑战。
尽管如此,在某些商业应用中,只有神经网络才能有效地完成工作,因此掌握神经网络技术依然至关重要。在我使用R语言进行一年左右的深度学习研究与实践中,本书是我的良师益友,指导我熟练地使用神经网络并完成图像识别项目。
推荐人:伯克利数据科学学院,首席ML科学家兼ML/AI负责人,Mike Tamir
推荐论文1: Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference (错误的真正原因:自然语言推理中的启发式句法诊断)
我推荐的第一篇论文是MaCoy,Pavlick和Linzen的“错误的真正原因:自然语言推理中的启发式句法诊断”,论文表明transformer架构显著推动了自然语言推理等NLU任务的进步。在技术研究之外,“错误的真正原因”强调了基于当前数据集的系统缺陷,这在NLU任务中是致命漏洞。本论文将提醒AI从业者和研究人员保持清醒与理智。 阅读原文 了解更多信息。
推荐论文2: Emergence of Invariance and Disentanglement in Deep Representations (深度表示中的不变和解耦)
我推荐的第二篇论文是关于DL信息瓶颈分析的,也就是Achille和Soatto的研究成果“深度表示中的不变和解耦”, 阅读博客 了解详细信息。
推荐人:蒙特利尔AI伦理研究所,创始人,Abhishek Gupta
The State of AI Ethics Report
在蒙特利尔AI伦理研究所,我们一直在关注一些最具影响力的论文,这些论文不仅关注AI伦理的常见问题,而且基于经验科学并能指导实践。为此,我们将过去一个季度的工作整理成《 AI伦理道德报告,2020年6月 》,用于指导该领域的研究人员和从业人员在实践过程中遵守AI伦理责任。该报告的内容包括但不限于,NLP模型中对残疾人的社会偏见,YouTube反馈回路的潜在缺陷,AI治理,即在AI中实施道德规范的整体方法以及对抗性机器学习-行业观点。 阅读原文 了解更多信息。
AI系统与策略实验室,首席AI科学家,Jack Brzezinski
推荐论文:The Discipline of Machine Learning(机器学习学科建设)
~tom/pubs/MachineLearning.pdf
本文简要介绍了机器学习学科建设纲要,机器学习要解决的基本问题和与其他科学和社会的关系,以及进一步的发展方向。 阅读原文 了解更多信息。
AIRAmed,机器学习工程师,Diego Fioravanti
推荐论文: Overfitting (过拟合)
Diego认为AI人员要对“过拟合”有清晰完整的了解。本文涉及内容涵盖统计推断,回归等。 阅读原文 了解更多内容。
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



豆果美食是最优质的美食菜谱社区,提供各种菜谱大全,食谱大全,家常菜做法大全,丰富的菜谱大全可以让您轻松地学会怎么做美食,展现自己的高超厨艺,开启美好生活!

什么值得买是千万用户热爱的科学消费指南,以“独立思考、高效决策、利他共享、真知灼见”为核心价值,主张“科学消费,认真生活”。


苏州知己清洁是一家专业从事驻场保洁托管外包、无尘室清洁、开荒保洁为主营业务的保洁公司;目前覆盖范围主要有苏州、昆山、张家港、太仓、吴江等拥有多个分支机构和办事处。公司的业务还包括:长期定期保洁,办公室保洁,洁净室等级保洁,防静电打蜡,物业保洁服务,日常保洁外包,工厂保洁,地面清洗打蜡,地毯清洗等。公司拥有的技术、设备、管理和清洁团队,丰富的经验和技术实力,为客户提供的清洁及解决方案,欢迎社会各界朋友光临本公司或电话业务洽谈

中国数字科技馆是中国科协、教育部、中科院共建的一个基于互联网传播的国家级公益性科普服务平台

郑州华德供水材料有限公司(18738118588)是一家致力于套筒补偿器,防水套管,橡胶伸缩接头以及橡胶补偿器的生产批发厂家,公司率先实施标准化为基础的生产定制模式,以合理的价格,优质的服务与您携手共谋发展.

山东盖无双建材有限公司为客户提供定制生产:电缆沟盖板、高分子复合电缆沟盖板、隧道盖板、高铁盖板、扣槽盖板、打孔盖板、高速盖板、球墨铸铁井盖、球墨铸铁盖板、隐形井盖、树脂井盖、种植井盖、彩色井盖、水沟盖板、雨水篦子、树池篦子、树脂篦子、等多种产品。

深圳市耀荣机电设备有限公司是复盛集团在华南地区设立的专业代理、销售及维修服务的复盛空压机经销商。多年以来经复盛公司层层培训、严格考核以及自身刻苦细致的工作实践,我公司拥有一支专业知识性强、经验丰富的服务团队,能为广大用户提供高效、优质、全面的服务。

素知短文学_本站整理当下流行的古风干净文艺短句,祝福短信最温馨的话,带刺高冷短句,套路情话一问一答,高冷短句霸气十足,文艺短句惊艳,突然间看透一切的说说,初中生优美段落摘抄,祝福短信客户,干净治愈文案短句,特别高级的土味情话等。

中共泉港区纪律检查委员会泉港区监察委员会

玩具巴巴是每天点击率超10万的专业玩具B2B网站,每天有近千款新产品上架,是全球玩具采购商每天采购产品的工具。共有160704只玩具产品,279556家玩具企业,456个玩具分类;主营:遥控玩具、电动玩具、积木玩具、兵器玩具、夏日玩具、惯性玩具、上链玩具、过家家玩具、娃娃玩具、回力玩具、线控玩具、拉线玩具、地摊玩具、益智玩具、体育玩具、家庭用品玩具、动植物玩具、闪光玩具、合金玩具、力控玩具、音乐玩具|乐器玩具、儿童玩具|婴儿玩具、游戏玩具、声控玩具、新奇玩具、变形玩具、军事玩具、动漫玩具|影视玩具

广州市壹辰筛网制造有限公司


提拉米苏是非常知名的意大利甜点,也是一种带咖啡酒味的甜点,而且它的选材和用料都是非常的严格,选用了马斯卡彭芝士为主原材料,再用手指饼干来取代传统甜点的底部蛋糕,加入适量的咖啡、可可粉等等其他元素,让所制作出来的产品不仅香滑可口,还非常的细腻柔和,甜而不腻,非常的有质感,所以不管是国内外都深深的吸引,并爱上了这种它,现在在市场上有着较高...。

虽然有NEX这样的当家旗舰,但每年为vivo攻城拔寨的依然是主攻主流消费市场的X系列产品,相比于以往的节奏,今年X23可以说是来的特别早,不过这并不影响它的关注度,水滴屏,极光纹炫彩机身,骁龙670AIE,可以说是为其赚足了眼球,如果问vivo这两年除了全面屏、水滴屏之外,还有什么巨大的改变外,笔者一定会选择——颜色,如果说五彩斑斓的...。

2月23日,壳牌中国与阿里云签署战略合作意向书,成为长期战略合作伙伴,双方将基于壳牌在能源转型领域的深厚积累和阿里云在云计算、大数据、人工智能等方面的技术优势,带动壳牌集团的优势资源和阿里巴巴集团在绿色低碳、出行等领域的丰富生态资源,在能源转型及数字化转型领域展开创新合作,携手共赴,净零,未来,作为世界领先的能源解决方案提供商,壳牌是...。

代码说明,本页面的认证代码为ZZ广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在ZZ广告联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升ZZ广...。

记者,谭登方7月11日,有网友爆料称,自己将重庆一警车在高速上别车并且实线变道的视频拍上去颁布到网上后,收到了派出所民警的电话,民正告知该网友,过后这辆警车正在口头义务,11日晚,新黄河记者就此事咨询到重庆市丰都县公安局,其上班人员示意,该警车过后确实是在口头义务,依据该网友颁布的行车记载仪监控视频显示,2024年7月10日下午3时许...。

智学网在校生端app下载并装置的方法如下,1,关上手机运行市场,搜查,智学网在校生端,,点击下载并装置,2,关上智学网在校生端app,在首页点击,注册账号,,依照要求填写关系消息,点击注册并登录,3,在首页点击,下载插件,,依照揭示成功关系操作,即可经常使用智学网在校生端app,常识扩展App是英文Application的缩写,理论指...。

在BBA的中型轿车三剑客当中,宝马3系以静止、操控好为亮点;奥迪A4L则有着大活动,内饰以科技感为亮点;而飞驰C级则强调温馨奢侈性,不过最近它的活动也相当大,而以后一代的飞驰C级在内饰间接照搬飞驰S级的设计,照旧让这台车成为同级别最奢侈的产品之一,虽然在性能上不占好处,但仰仗大气的外观,奢侈的内饰,让整车颇具实力,当天我们就来聊一聊2...。

太平洋汽车,欧蓝德ex劲界定速巡航坏了的要素,1、定速巡航开关损坏;2、制动踏板传感器缺点、轮速传感器缺点以及关系电路缺点;3、ecu不可接纳到巡航电磁阀的信号,原题目,三菱欧蓝德EX劲界雨刷器隐患4S店召回网通社2017年7月20日报道三菱旗下欧蓝德EX劲界定位为紧凑型SUV,此前以出口的形式引入国际,网通社从国度质检总局缺点产品...。
我以为汽车之家2023年最新汽车报价包含但不限于,1、吉利汽车•吉利星越PRO最新报价25,35万元,2、长城汽车•长城哈弗最新报价10,18万元,3、上汽公众•宝来最新报价8.69,12.99万元,4、西风本田•飞度最新报价11.98,16.98万元,看汽车用什么软件好用在购车环节中,我关键经常使用汽车之家、懂车帝和易车这三个软件,...。

HCLAppScanStandard是一款功能强大的应用程序安全测试工具,可以自动扫描和分析应用程序中的安全漏洞。

如何利用C++实现一个简单的电子邮件发送程序?随着互联网的普及,电子邮件已经成为人们日常生活和工作中不可或缺的一部分。在C++编程中,我们可以利用SMTP(SimpleMailTransferProtocol)协议实现一个简单的电子邮件发送程序。本文将介绍如何使用C++编写一个基本的电子邮件发送程序。首先,我们需要准备一些工具和库来实现我们的程序。首先

全球居民财富大缩水!平均每人少了上万元,350万人失去百万富翁身份,巴西,美国,净财富,百万富翁

消息,北京时间9月9日,MLCommons社区发布了最新的MLPerf2.1基准测试结果,新一轮基准测试拥有近5300个性能结果和2400个功耗测量结果,分别比上一轮提升了1.37倍和1.09倍,MLPerf的适用范围进一步扩大,阿里巴巴、华硕、Azure、壁仞科技、戴尔、富士通、技嘉、H3C、HPE、浪潮、英特尔、Krai、联...。

中关村创新创业季2017少年创客马拉松暨VEX中关村公开赛,将于2017年9月23日开赛,本届主题,2017,2018赛季VEXIQ环环相扣还记得去年的K12少年创客马拉松吗,100多名青少年参赛选手在创新的舞台上发挥自己的聪明才智,完成火星探索的模拟任务,今年少年创客马拉松又来了,主题采用与,2017,2018赛季VEX世锦赛,同样...。
mac电脑可以传文件到安卓手机吗,答案肯定是可以的,那么mac电脑怎么传文件到安卓手机呢,还有很多的用户不是很清楚,下面就跟小编一起来看看吧!mac电脑传文件到安卓教程1、下载•在本站下载安卓版爱莫助手应用,•进入到,https,airmore.cn,的页面,点击启动爱莫功能页2、将安卓手机连接到爱莫助手功能页•打开手机里下载的...。

获悉,人工智能公司,中科摇橹船,日前获得新一轮融资,本轮融资主要由川穗基金、四川国经聚智科技、中天辽创等国资背景的基金投资,公开资料显示,中科摇橹船成立于2020年12月,由中科院西光所和重庆市两江新区政府合力孵化,专注于高精密光电测量,系国内唯一一个完整掌握高精密光电测量技术的机器视觉国家队,中科摇橹船的业务涵盖机器视觉器件、...。
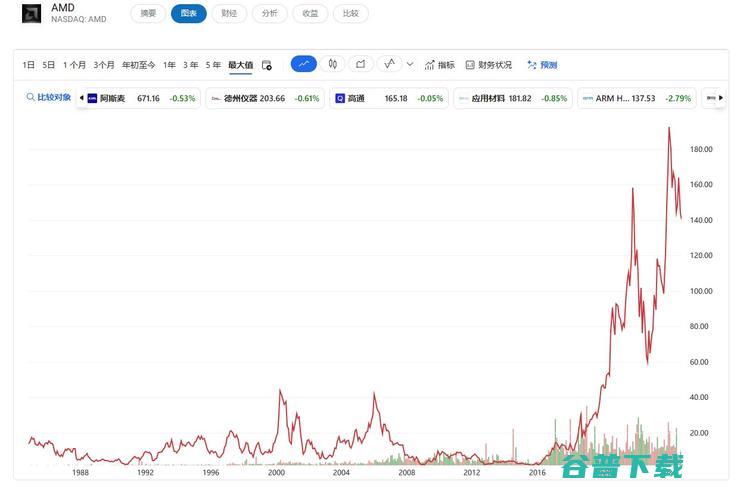
2014年10月,苏姿丰接手AMD,出任公司CEO,彼时,她的前任RoryRead给她留下的是股价长期徘徊在3美元区间,市场份额被英特尔全面击溃的AMD,用,烂摊子,来形容当时的AMD也毫不为过,危机即转机,苏姿丰选择迎难而上,没有什么事情比亲手重塑AMD更,有意思,上任后,苏姿丰领导AMD的核心理念是专注于进行,正确的技术投资,,...。
