Movidius Intel 商用芯片已交付 新一代 明年见 VPU 宣布首款 AI (Movidius公司)

语音播放文章内容
由深声科技提供技术支持
美国西部时间 11 月 12 日,2019 英特尔人工智能峰会期间(Intel AI Summit 2019)在旧金山举行,雷锋网受邀参加。在峰会期间,英特尔展示了一系列 AI 相关新产品和相关进展,其中,包括面向训练 (NNP-T1000) 和面向推理 (NNP-I1000) 的英特尔 Nervana 神经网络处理器 (NNP) 都重磅亮相,而英特尔也公布了新一代 Movidius Myriad 视觉处理单元。

英特尔公司副总裁兼人工智能产品事业部总经理 Naveen Rao 表示:
Nervana NNP 已经投入生产并交付
对于英特尔来说,Nervana NNP 是它在神经网络处理器方面的重要产品,可以说是第一款 AI 商用芯片,而且这款产品从发布、测试、量产到应用,实际上是经历了一个漫长的产品周期。

新一代 Nervana NNP 首先亮相是在 2018 年 5 月。当时,在英特尔人工智能开发者大会 (AIDevCon 2018) 上,Naveen Rao 发布了新一代专为机器学习设计的神经网络处理器(NNP)芯片,并表示这是英特尔第一款商业 NNP 芯片,将不止是提供给小部分合作伙伴,将在 2019 年发货。
到了 2019 年 8 月,英特尔在 Hot CHIps 大会召开期间公布了 NNP 芯片的更多信息,其中,它依据用途分为 Nervana NNP-T 和 Nervana NNP-I,分别用于训练和推理。
雷锋网了解到,Nervana NNP-T 代号 Spring Crest,采用了台积电的 16nm FF+ 制程工艺,拥有 270 亿个晶体管,硅片面积 680 平方毫米,能够支持 TensorFlow、PaddlePaddle、PYTORCH 训练框架,也支持 C++ 深度学习软件库和编译器 nGraph。
而 Nervana NNP-I,代号为 Spring Hill,是一款专门用于大型数据中心的推理芯片。这款芯片是基于 10nm 技术和 Ice Lake 内核打造的,打造地点是以色列的 Haifa ,Intel 号称它能够利用最小的能量来处理高负载的工作,它在 ResNet50 的效率可达 4.8TOPs/W,功率范围在 10W 到 50W 之间。
按照官方说法,英特尔 Nervana 神经网络训练处理器(Intel Nervana NNP-T)在计算、通信和内存之间取得了平衡,不管是对于小规模群集,还是最大规模的 pod 超级计算机,都可进行近乎线性且极具能效的扩展。英特尔 Nervana 神经网络推理处理器(Intel Nervana NNP-I)具备高能效和低成本,且其外形规格灵活,非常适合在实际规模下运行高强度的多模式推理。这两款产品面向百度、 Facebook 等前沿人工智能客户,并针对他们的人工智能处理需求进行了定制开发。

在 2019 英特尔人工智能峰会峰会现场,Intel 宣布——新推出的英特尔 Nervana 神经网络处理器(NNP)现已投入生产并完成客户交付。其中,Facebook 人工智能系统协同设计总监 Misha Smelyanskiy表示:
另外,百度 AI 研究员 Kenneth Church 在现场表示,在今年 7 月,百度与英特尔合作宣布了双方在 Nervana NNP-T 的合作,双方通过硬件和软件的合作来实现用最大的效率来训练日益增长的复杂模型。Kenneth Church 还宣布,在百度 X-Man 4.0 的加持下,英特尔的 NNP-T 已经推向市场。
新一代 Movidius VPU 明年见
在峰会现场,Intel 公布了全新一代 Movidius VPU。
下一代英特尔 Movidius VPU 的代号是 Keem Bay,它是专门为边缘 AI 打造的一款产品,专注于深度学习推理、计算机视觉和媒体处理等方面,采用全新的高效能架构,并且通过英特尔的 OpenVINO 来加速。按照官方数据,它在速度上是英伟达 TX2 的 4 倍,是华为海思 Ascend 310 的 1.25 倍。另外在功率和尺寸上,它也远远超过对手。
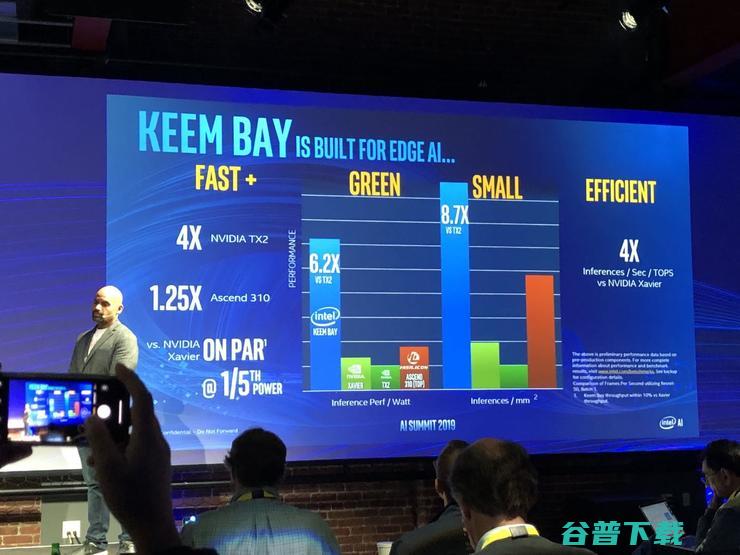
Intel 方面表示,新一代 Movidius 计划于 2020 年上半年上市,它凭借独一无二的高效架构优势,能够提供业界领先的性能:与上一代 VPU 相比,推理性能提升 10 倍以上,能效则可达到竞品的 6 倍。
雷锋网了解到,英特尔曾经在 2017 年 8 月推出一款 Movidius Myriad X 视觉处理器(VPU),该处理器是一款低功耗 SoC,采用了 16nm 制造工艺,由台积电来代工,的主要用于基于视觉的设备的深度学习和 AI 算法加速,比如无人机、智能相机、VR/AR 头盔。

除了新一代 Movidius,英特尔还发布了全新的英特尔 DevCloud for the Edge,该产品旨在与英特尔 Distribution of OpenVINO 工具包共同解决开发人员的主要痛点,即在购买硬件前,能够在各类英特尔处理器上尝试、部署原型和测试 AI 解决方案。
另外,英特尔还介绍了自家的英特尔至强可扩展处理器在 AI 方面的进展。

英特尔方面表示,推进深度学习推理和应用需要极其复杂的数据、模型和技术,因此在架构选择上需要有不同的考量。事实上,业界大部分组织都基于英特尔至强可扩展处理器部署了人工智能。英特尔将继续通过英特尔矢量神经网络指令 (VNNI) 和英特尔深度学习加速技术(DL Boost)等功能来改进该平台,从而在数据中心和边缘部署中提升人工智能推理的性能。
英特尔强调称,在未来很多年中,英特尔至强可扩展处理器都将继续成为强有力的人工智能计算支柱。
雷锋网总结
在本次 2019 英特尔人工智能峰会上,Intel 还公布了其在 AI 方面的整体解决方案。实际上,英特尔在 AI 方面的优势不仅仅局限在 AI 芯片本身的突破,更重要的是,英特尔有能力全面考虑计算、内存、存储、互连、封装和软件,以最大限度提升效率和可编程性,并能确保将深度学习扩展到数以千计节点的关键能力。
不仅如此,英特尔还能够借重现有的市场优势将自家在 AI 领域的能力带向市场,实现 AI 的商用落地——值得一提的是,在峰会现场,英特尔宣布,自家的人工智能解决方案产品组合进一步得到强化,并有望在 2019 年创造超过 35 亿美元的营收。

可见,在推进 AI 技术走向商用落地方面,英特尔终于跨出了自信的一步。
原创文章,未经授权禁止转载。详情见 转载须知 。


重庆巨宇勘察测绘有限公司

上海西熙工控自动化有限公司

唯我品牌策划专业提供公关活动,活动策划,年会策划庆典策划开业庆典策划开业庆典,启动仪式,发布会,公关活动案例,公关活动形式,搭建制作,活动制作,舞美制作,公关传播等上千场各式活动的策划和管理经验案例在等你!

搜房网是著名的中国房地产信息平台,搜房网提供全面实时的房地产资讯内容,为广大网民提供专业的新房、二手房、租房、豪宅别墅、写字楼、商铺等全方位资讯信息。为业主、客户及房地产业内精英们提供高效专业的信息推广服务。

郑州玉都环保设备有限公司坐落于中国的交通枢纽中心郑州,是中原地区一家大规模的塑料容器生产厂家销售企业。 公司主要产品有:塑料水箱、PE水箱、加药箱、化工防腐储罐、塑胶水塔、周转箱、食品级储罐、塑料桶、腌制桶、锥形储罐、塑料水塔、酸洗槽、大型立式储罐、加药装置、外加剂复配设备、聚羧酸合成设备、酸碱化工储罐、PP焊接储罐、PE储罐、搅拌罐等塑料防腐容器;酸雾吸收塔、pp反应釜,真空罐,缓冲罐等塑料化工环保设备。另承接大型塑料定制产品。 郑州玉都环保设备有限公司产品严格选用优质进口塑料颗粒为原料并按照“中华人民共和国GB9687-88质量标准”为准制造。 郑州玉都环保设备有限公司拥有技术研发中心,具备丰富的研发能力可按不同用途进行各种设计和制造。近年来,为南水北调工程、河南城际高铁高速等国内大型工程配套提供了各种不同规格的塑料储罐产品及相关设备,为甲方基础建设做出贡献。另为多家化工企业提供环保治理产品及方案!欢迎新老用户咨询! 郑州玉都环保设备有限公司本着“创新科技、真情服务”的企业经营理念,倡导

深圳市邦明科技有限公司8年专业从事品牌营销型网站建设、深圳做网站设计制作、SEO网站优化,微信公众号及微信小程序开发、深圳APP软件开发、进销存及CRM客户管理系统,企业邮箱、域名云主机等服务的深圳网络公司,致力于为企业提供一整套互联网解决方案;提供福田做网站、罗湖网页设计及南山网站开发、盐田网站建设、宝安网站设计维护及龙岗网站制作、龙华网站开发、坪山网站设计、光明及大鹏网站建设服务。

上海百廷建筑装潢设计有限公司,品牌名“百廷装饰”,是集一家装、工装的室内外设计、预算、施工、材料于一体的创新化、多元化的装修装饰公司。公司秉承“崇尚创新,拒绝平庸”的设计理念,为业主创造时尚、和谐、健康的家装工装环境。

湖南广信科技股份有限公司

凭么搜黄历网免费为您提供:日历网,黄历工具,万年历查询,2025日历大全,黄道吉日在线查询,今日黄历宜忌查询,今天是农历几月初几,今天黄道吉日查询!

管理系是专业的经营范围知识平台,提供经营范围、会计、知识产权、合同、起名等服务。

巩义市明亮冶金辅料有限公司精炼渣二十年品质信赖_质量放心,生产的冶金辅料,铝酸钙,覆盖剂,精炼渣,预熔型精炼渣,烧结型精炼渣,精炼渣洗剂,AD粉被誉为二十一世纪的新型材料,溶点低,熔速快,价格低可缩短冶炼时间等特点,欢迎进入网站详细查看。

壁纸网是一个4k壁纸网站。提供4k壁纸,5k壁纸,带鱼屏壁纸,宽屏壁纸,电脑桌面壁纸,4k游戏动漫卡通壁纸等各种高清壁纸下载。壁纸网,发现好壁纸。


7月26日消息,明基近期在印度推出了W4000i投影仪,售价400000印度卢比,备注,当前约34880元人民币,明基W4000i投影仪三围尺寸约为420.5x135x312mm,重量约为6.6Kg;内部搭载4个LED光源,支持3200ANSI流明亮度、HDR10、HDR10,和HLG,支持4KUHD分辨率,100%DCI,P3色域...。

在程序员圈子里面,外包程序员似乎永远处于一个尴尬的角色,如果你说他们不是程序员吧,他们也是程序员,应该说是外包这个词比较尴尬吧,其实我们身边也有很多外包程序员,我身边也有从外包进一线互联网企业的例子,外包公司一般是中途培训上岗或者转行的,其实不管是不是外包,大家都是迫于生计,要不然谁想写代码对吧,雇主公司会在什么情况下雇用外包人员呢?...。

互联网行业的分析师,做指标体系搭建的时候,最常遇到两个问题,一是不知道关注哪些指标,毫无头绪,二是找到了一些指标,但不知道哪些重要,迷失方向,那么我们今天就聊聊互联网分析常用的数据指标,给大家详细讲解最常用的12个,互联网的本质之一,就是把线下的活动搬到了线上,然后通过技术和运营手段,让用户有更好的体验,比如原来商场卖货,现在变成了淘...。

创业哪个项目好,近年来儿童阅读加盟行业持续保持增长状态,主要在于以下几点,·全民阅读、文化自信是大背景,阅读是一个比较好的创业切入口;·9月份新的中小学新教材上线,整本书阅读对孩子的阅读量、阅读能力提出了更高的要求;·AI时代,培养孩子的综合能力成为大趋势,而阅读是其中的重要途径……在这种背景下,以借阅,读书会,研学活动为运营模式的书...。

近日,四维图新正式获批北京市政府颁发的自动驾驶车辆道路测试试验用临时号牌,路测牌照,,等级为T3级,这也是迄今北京市颁发的最高级别自动驾驶路测牌照,雷锋网新智驾了解到,目前北京已向包括四维图新、百度、智行者、小马智行在内的11家企业发放自动驾驶路测牌照,四维图新成为第一家获批T3路测牌照的位置服务提供商,目前,北京市共有44条总计...。

今日融资快报四个月融两轮,具身智能机器人公司千寻智能获得2亿人民币天使轮融资千寻智能创始人兼CEO韩峰涛在机器人行业拥有十余年丰富经验,曾任珞石机器人联合创始人&,CTO,是国内高性能轻型工业机器人领军者和国内力控协作量产交付第一人,千寻智能也是国内唯一具备AI,机器人生产力级全栈技术能力的具身智能公司,先后完成了近2亿元的种子...。

电瓶车在电梯内起火,电梯内有5人,包括一名婴儿,一句话,隔着屏幕都能感觉到绝望,昨晚,四川成都某小区一电梯内电瓶车爆燃,导致多人受伤,最小的伤者是一名仅5个月大的婴儿,监控视频显示,从浓烟到起火燃烧,时间仅3秒,目前伤者都在医院救治,婴儿还没脱离危险,仍在重症监护室,抱婴儿的婆婆,全身75%烧伤,一度给家属下达病危通知书,情况也不乐观...。

便利店老板被一医生殴打10秒后死亡警方,打人者已刑拘正对死者尸检近日,青海久治县索乎日麻乡一便利店老板清晨被医生殴打后死亡引关注,12日,死者妻子王女士通知咱们视频,打人者是卫生院医生,住他们对面,过后打人者不停敲门,他老公起床开业就被打,她进去后看到丈夫已倒下,一度认为打人者是帮助救人的,王女士称,打人者家眷已和他们赔罪,警方尸检后...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

海通证券大智慧国泰君安大智慧华泰证券大智慧大智慧经典版大智慧手机版大智慧新一代大智慧5.0大智慧5.6大智慧v5.6大智慧5.9大智慧5.98大智慧6.0大智慧手机版大智慧2009以及更多版本的大智慧软件下载就到,wwwdazhihuixiazaicn国泰君安官网网站,国泰君安大智慧软件官网下载国泰君安官网网站是,这是一个提供证券期货...。

ThinkPadT460s笔记本重装系统WIN10步骤(一键重装方法)

网易灵犀办公电脑版是一款智慧办公软件,以企业邮箱为基础,整合客户管理、日历、网盘、在线文档、即时通讯等功能于一体,为用户打造一个智能化、一体化办公环境。
动漫在人们的印象中最出色的是关于日漫的作品,其中龙猫这款动漫作品是很多人的青春,很多人都偷偷地在课堂观看动漫内容,现在也有超多精彩的动漫作品,所以今天小编给大家带来免费看动漫的软件有哪些,为大家分享几款好用的能够在手机上查看精彩的动漫内容的App软件,让大家借助这些软件的帮助能够更快速地找回那份青春的感觉,也能更好地体验其他题材或地区...。

长期爱看文章的人,应该都有这种感受,凡是那些写着日入**千,月入**万的项目文章,哪怕写得再烂,打开率和阅读数也远超那些写如何引流,如何提升赚钱思维的文章,你喜欢看,自然有人为了迎合你们的兴趣点来写,哪怕不是基于事实,胡编乱造也可以,毕竟对他们而言,阅读量才是王道,可作者想说,如果你不会引流,没有流量,日入几千,月入几万这种事儿,和你...。

雷锋网按,要说本届CES上最出风头的公司,Mobileye绝对算其中之一,这家背靠英特尔,企业战略异于常人且一心要成长为全产业链出行供应商的巨头在CES的展台上给大家亮了亮,家底,公司主席兼CEOAmnonShashua更是抛出一颗彩蛋——一辆只靠摄像头的Mobileye自动驾驶汽车居然,一镜到底,完成了长达23分钟的无人驾驶展示,...。

发表在当贝投影仪2024,10,3115,47当贝Smart1是一款便携式投影仪,在千元价位里面也属于佼佼者,具体当贝Smart1的实测体验如何呢,下面就分享当贝Smart1真实使用体验,看看当贝Smart1值得买吗,当贝Smart1真实使用体验分享1.这投影仪太棒了!画面清晰无比,每一个细节都栩栩如生,色彩鲜艳又真实,就像把影院搬回...。

随着网络技术的始终开展,越来越多的人依赖于在线音乐播放和下载,但是,很多人或许会遇到一些疑问,比如在某些平台上不能找到想要听的歌曲,或许须要额外付费能力下载音乐,上方引见几个收费下载mp3的在线网站,供大家参考,1.MP3JuiceMP3Juice是一个极速、收费的mp3下载网站,它提供了超越百万的mp3资源,用户可以经过输入歌曲名或...。
