全球首款3D晶圆级封装处理器IPU发布 突破7nm制程极限 (全球首款3d打印牛排)
消息,本周四,总部位于英国的AI芯片公司GraphCore发布了新一代IPU产品Bow,这是其第三代IPU系统,发布即面向客户发货。与上一代IPU相比,Bow IPU性能提升40% ,能耗比提升了16%,电源效率也提升16%。
值得注意的是,这一次Bow IPU的性能提升并非主要依赖采用更先进的制程,Bow IPU采用了和上一代IPU相同的台积电 7nm,通过采用和台积电共同开发的先进硅晶圆堆叠技术(3D Wafer-on-Wafer)达到性能和能耗比的提升。
Bow作为世界首款3D WoW处理器,证明了芯片性能提升的范式从先进制程向先进封装转移的可行性。

新一代 IPU 性能提升40%,价格保持不变
2016年,Graphcore成立并开创了全新类型处理器架构IPU,因其在架构上的创新曾被英国半导体之父Hermann Hauser称之为是计算机历史上的第三次革命。
经历6年时间的发展,Graphcore的IPU逐渐在在金融、医疗、电信、机器人、云和互联网等领域取得成效。本周四,Graphcore又推出了第三代产品Bow IPU。
据Graphcore介绍,第三代IPU相对于上一代M2000,性能提高40%,每瓦性能提升16%,即能耗比实现16%的提升。 不过,AI芯片的真实性能还需要放在不同的应用领域中讨论。为此,Graphcore也给出了在不同垂直领域中Bow的性能表现。

在图像方面,无论是典型的CNN网络,还是近期比较热门的Vision TransFormer网络,以及深层次的文本到图片的网络,与上一代产品相比,Bow IPU都有30%到40%的性能提升,在EfficientNet-B4这一项中,接近理论上限值。
BERT训练模型是自然语言方面的经典模型,基于BERT,OpenAI提出了GPT-1、GPT-2、GPT-3等纵向扩展或横向扩展,通过更深的网络层次和更宽的网络宽度让模型的性能和精度进一步提高。
“我们可以看到,这些模型在我们最新的硬件形态上都有很大的性能提升。”Graphcore中国工程副总裁、AI算法科学家金琛介绍道。
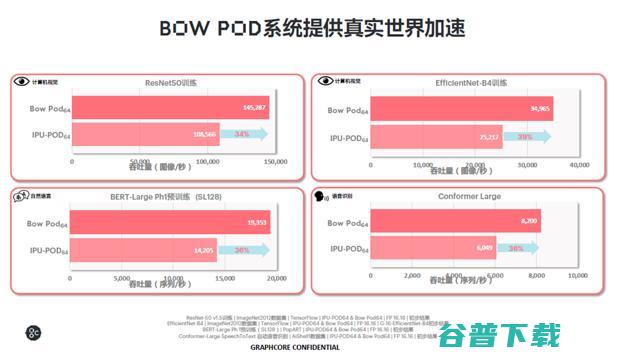
不仅如此,转换到实际模型中的吞吐量,与IPU POD64相比,在计算机视觉的ResNet50 和 EifficientNet-B4 训练模型中,Bow Pod64的吞吐量能够达到34%和39%的性能提升。自然语言方面, BERT-Large Ph1 预训练模型和语音识别Conformer Large 训练模型,后者都有36%的吞吐量提升。

作为英伟达的竞争对手,Graphcore自然不忘将 Bow Pod16 与DGX-A100进行对比, 实验数据表明,EfficientNet-B4的backbone的训练在DGX-A100上需要花费70个小时的训练时间,而在Bow Pod16上,只需要14小时左右。
接近理论极限的性能提升,Graphcore Bow IPU是如何实现的?
5nm不再是首选,采用先进封装性价比更高
从芯片的规格上看,Bow IPU是世界上第一款基于台积电的 3D Wafer-On-Wafer的处理器,单个封装中拥有超过600亿个晶体管,具有350 TeraFLOPS的人工智能计算的性能,是上一代MK2 IPU的1.4倍。片内存储较上一代来看没有变化,依然保持0.9GB的容量,不过吞吐量从47.5TB提高到了65TB。

“变化主要体现在,它是一个3D封装的处理器,晶体管的规模有所增加,算力和吞吐量均得到提升。” Graphcore大中华区总裁兼全球首席营收官卢涛说道。 而在大家都关注的工艺制程上,Bow IPU 延续了上一代台积电 7nm 工艺制程,没有变化。
理论上,一颗芯片的性能提升很大程度上取决于工艺制程上的进步,但随着工艺制程越来越逼近物理极限,摩尔定律逐渐失效,业界不得不寻找新的技术方向来延续摩尔定律。其中,3D封装就是被业界广泛看好的技术方向。
中国工程院院士、浙江大学微纳电子学院院长吴汉明就曾在一次演讲中提到,如果将芯片制造和芯片封装相结合,也可以做到65nm工艺制程实现40nm工艺制程的性能功耗要求。
Bow IPU正好验证了吴院士的观点。
至于为何选择改变封装方式而不是更先进的工艺,卢涛则表示MK2 IPU有594亿个晶体管,大概823平方毫米,已经是7nm单个Die能够生产的最精密的芯片。
“我们评估从7nm、5nm,到3nm等不同工艺节点的收益时发现,从7nm到5nm的生产工艺提升所带来的收益不像以前从28nm到14nm一样,能够带来百分之几十的收益,而是降到了20%。这时候我们可以通过别的手段和方法获得同样的收益。”
通过3D堆叠的方式,Bow IPU的两个Die增加了晶体管的数量,其中一个Die(Colossus Die)和上一代一样,另一个Die主要用于提高跨Colossus Die的电源功率传输,优化Colossus Die的操作节点,从而转化为有效的时钟加速。
在同台积电的合作方面,卢涛告诉,Graphcore在一年之前就同台积电合作了一颗测试芯片,与台积电的关系非常紧密,加上AI处理器本身规模较大,需要一些新技术支持落地,而从台积电的角度而言,新的技术也需要有需求的产品共同推进。
值得一提的是,虽然封装方式有所变化,但Bow IPU开箱即用,与前一代产品百分之百软件兼容,不用修改任何代码,老用户无需做任何软件适配工作就能获得性能提升,价格保持不变。
目前,美国国家实验室Pacific Northwest已经基于Bow IPU尝试做一些基于Transformer的模型以及图神经网络,面向计算化学和网络安全方面的应用,且给出了比较正面的反馈。
延续3D封装,开发超越人脑的超级智能机器
Bow IPU使用3D封装只是起点,面向未来,Graphcore正在开发一款可以用来超越人脑处理的超级智能机器。
Graphcore将这款正在研发的产品命名为Good Computer,一方面希望计算机能够为这个世界带来正面的影响,另一方面致敬著名计算机科学家Good。

基于3D WoW,预计未来Good Computer将包含8192个IPU,提供超过10 Exa-Flops的AI算力,实现4 PB的存储,可以助力超过500万亿参数规模的人工智能模型的开发。
取决于不同的配置,Good Computer价格将在100万美元到1.5亿美元之间。
卢涛表示,开发Good Computer还是会沿用IPU的体系结构,IPU的存储是在处理器里面,虽然不叫类脑、内存计算或存算一体,但从某种程度上而言,IPU的运作机理接近大脑计算的工作原理,只是把计算和存储相结合。
另外,Graphcore也将从软件方面更有效支持稀疏化以达到类脑的计算量。
不是GPU的IPU,为什么更值得英伟达警惕?
超越全球最大7nm芯片A100!Graphcore第二代IPU晶体管数量高达594亿个
直击CPU、GPU弱项!第三类AI处理器IPU正在崛起
原创文章,未经授权禁止转载。详情见 转载须知 。


”大邦科技【营巢云联】专业的智慧工地及三维智慧物联解决方案供应商”

怀义说易一弘扬国学,指点迷津,以文章及视频模式进行国学宣扬.

3322软件下载站提供热门的手机游戏下载,手机游戏排行榜,收集常用的安卓应用软件分享给网友。

龙锋泰自动化专业生产覆膜机,在线贴膜机,玻璃覆膜机,自动化生产线,特种玻璃覆膜机,大型板材覆膜机,不锈钢覆膜机,智能胶片覆膜机等自动化覆膜设备。

德盾保安公司自成立以来遵循和坚持“以人为本、客户至上,安全第一、真诚服务” 和“品质是生命、管理是效益、满意是承诺、追求卓越高效、使客户持续满意”的服务理 念,经过不懈努力和锤炼,已励练成一支懂经营、会管理、业务精、肯奉献、高素质的安 保管理队伍。经过不懈努力和锤炼,公司现有1360多名员工,管理人员231名,占职工 总数17%。

靠谱助手安卓模拟器是一款可以在电脑上畅玩手机游戏的模拟器,支持手柄、游戏多开等功能,键盘鼠标操作,让您更轻松地玩转热门安卓手游电脑版。

秉文网络科技有限公司为客户提供IT运维外包、硬件维保续保、数据恢复迁移、服务器存储虚拟化、软硬件维修调试扩容、网络安全等一站式的IT整体解决方案.北京数据库修复,服务器数据恢复,虚拟化数据恢复,硬盘开盘恢复数据,勒索病毒数据库修复,固态硬盘数据恢复,北京数据恢复,服务器数据恢复,硬盘恢复数据,数据库修复,raid数据恢复,群辉NAS数据恢复.

专注呈现最真实明星生图

牛商云平台致力于打造全网营销智能SaaS云平台,提供全面的全网营销、智能营销和数字化营销的产品、服务、资源和一站式解决方案,全网高增长,就找牛商股份。

活动秀场是一家通过“3D云设计”技术,为各大产业提供一站式活动服务平台,活动秀场以“3D云设计”为切入口,提供活动设计、3D场景营销、活动策划、品牌活动、活动搭建等解决方案和服务。活动秀场在活动、展会行业有十几年的服务经验,我们为产业提供赋能,助力产业实现“所见即所得”的愿景。

矩阵软件专注大宗物资称重物联的智能应用领域,自主研发的自动装车系统、汽车自动装车系统,汽车快速定量装车系统,智能汽运装车系统,火车自动装车系统,火车快速定量装车系统等AI智能产品。咨询电话:400-006-7677可为客户提供多种全方位的自动化解决方案。

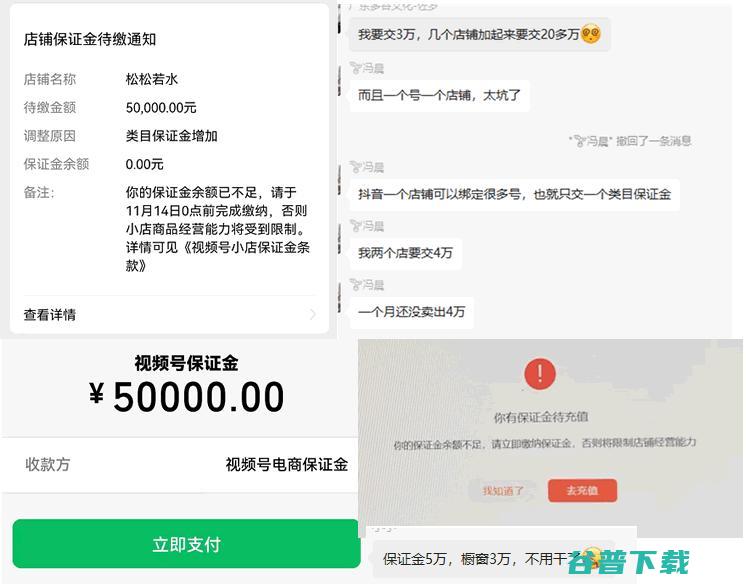
昨天有赞发布了这样一条公告,大意是,视频号停止和第三方合作了,以后只能用视频号自己的带货中心,同时,很多主播帐号也收到了通知,要求缴纳保证金,保证金从2W,5W不等,从松松视频号陪跑群的用户反馈来看,很多主播叫苦连天,有用户反馈,我交3万,几个店铺加起来就要交20多万,而且一个号一个店铺,太坑了,我两个店要交4万,一个月还没卖出去4万...。

离异美女,视频平台上征婚,30岁男子被骗8万多元,一直没对象,江苏涟水,市民石先生报警称,自己在网上加了一位离异征婚的,美女,,对方一番忽悠下自己被骗走8万多元,民警侦查后发现,嫌疑人系男性,且是8人诈骗团伙,团队中负责聊天的基本都是男性,有多名受害人被骗,一手video的秒拍视频来源,松松科技QQ,微信,lusongsong7本...。
要闻提示1.苹果中国官网降价上热搜,新年首周在华销量下降30%2.中国生物制药回应科兴新冠疫苗停产,还有4亿存货,已获分红近60亿3.阿维塔售后大规模裁员,比例高达95%,员工称内部四分五裂,最新回应4.全系车型降价超3万元,理想汽车回应,提前开始产品更新过渡5.美航管局鼓励聘用智力和精神残疾人士,马斯克惊呼难以置信6.苹果造车被曝新...。

MWC2017开幕前一天各大手机厂商用各自的新品成功刷屏,但这只不过是展会的开胃菜,本届MWC的主题是,Thenextelement,,显然,5G就是主题的一部分,雷锋网在现场发现,以5G为代表的网络变革已经在MWC上掀起了一波新的潮流,来自全球的运营商、芯片商以及通信设备商无一不把5G视为重点展示项目,而展位相隔只有几米的英特尔和高...。
作者丨孙溥茜编辑丨陈彩娴大模型浪潮正在以它的方式蚕食着传统数字营销,改变都发生在你我生活的边边角角地方,2023年初,电竞被正式列为奥运会电子竞技项目;随着直播带货的火爆,相比淘宝,抖音电商后来居上,电竞、本地生活,这些新词新态,不过是近几年的事,也许因为他们的年轻,所以更加拥抱全新技术的变化,大模型似乎正在引爆新一轮互联网增长点,为...。

发表在极米投影仪2022,12,1615,03近日,极米H5搭载的系统GMUI5.0全新上市,后续也会在其它的机型中陆续搭载,接下来我们就来看看极米GMUI5.0系统所拥有的新增亮点功能,并和使用热度较高的当贝OS进行对比,让大家看看哪个系统更好一些,1.GMUI5.0,新增有线电视直播功能极米GMUI5.0系统新增了电视直播功能,不...。

1、锅中放油,下入冰糖或冰糖粉,小火将其熬化,2、熬糖的同时,将需要用量的水也在一边烧上,注意后面我们要使用的是开水,千万不要使用凉水,凉开水也不行哦,就是要温度越高越好,3、小火把糖全部熬化需要时间,一定要耐心,不时拿锅铲搅拌,不要失去耐心转成大火了,4、冰糖全部融化之后,表面开始出现气泡,量会由少及多,5、开始是细密的小泡,表面快...。

在直播间300元秒杀电动车却不能提车,消费者质疑商家虚假宣传播报文章科技生活快讯关注作者获得积分关注2024,11,1410,40来自山东原创标注系作者主动申请,作者保证其发布作品系原创,如存在侵权,请联系平台处理,近日,一则关于消费者在直播间秒杀电动车却遭遇提车难的事件,引发了社会的广泛关注,江苏的冯先生在网络直播间看到九号电动车双...。

由华阳陆地钻研核心、中国南海钻研院和中国国际法学会联结撰写的,南海仲裁案判决再批驳,报告当天,11日,在北京颁布,报告梳理了南海无关争议疑问的实质,并对南海仲裁案判决的管辖权疑问,仲裁判决在历史性权益、大陆国度远洋群岛、岛屿位置等疑问上的法律解释和实用与理想认定疑问,以及仲裁庭的代表性疑问启动剖析批驳,进一步向国际社会提醒仲裁判决的舛...。

双鱼女婚配星座,1、巨蟹座,团体的性情是十分相似的,在生存中,相处起来会十分的温馨,不会存在任何的隔膜,2、金牛座,在感情中,金牛的占有欲会变得比拟强,但也说明金牛能够在愈加细节的方面关照到小女生的双鱼,3、天蝎座,双鱼能够从天蝎那里获取安保感,天蝎能够从双鱼那里找到自信和魅力,双鱼温顺体恤、浪漫多情、自我就义的贡献精气是专情独占欲强...。

英菲尼迪Q50共有两款发起机,一款是3.5升人造吸气发起机,另一款是3.7升人造吸气发起机,其中,3.5升人造吸气发起机的车型是混动版车型,具备320马力和338牛米的最大扭矩,能在6800转每分钟时输入最大功率,5000转每分钟时输入最大扭矩,这款发起机驳回了多点电喷技术和铝合金缸盖缸体,并与7AT变速箱相婚配,混动版车型的电动机最...。

西风标记508这款车的厂商指点价,15.97,22.57万元,1、好处,内饰空间巴适,车型外观很美丽,很和我的胃口,线条很流利,操作也很便捷,底盘结构比408稳如泰山;2、缺陷,发起机舱太狭窄了,特意是附件皮带那儿,以后拆皮带有点艰巨,除非有公用工具,我想的话公用工具必需是有的;3、总结,我是一个专修标致的汽车培修工,从我的角度来讲哈...。

很多人在生活中都喜欢种植鲜花,这说明对于生活还是有美好向往的,游戏中也有很多和花有关,喜欢花的玩家可以来看盘点与花有关的游戏,这些游戏的画面都能给玩家营造一种一场静谧美好的感觉,普遍都是卡通风格的设计,能让玩家有一种处在童话世界的感觉,如果想要有鲜花环绕的感觉,那就可以进入到游戏中体验不同的花朵元素,游戏模式相对都比较休闲,玩家可以用...。
大江东去浪淘沙,在历史发展的洪流之中,有无数软件产品随着潮起潮落浮沉,那些昔日被视为装机必备的好软件,可能现在已经鲜为被人所用,被前浪拍死在沙滩上的软件,到底为何竟会沦落到无人问津的地步?这既取决于它们本身的产品力,也取决于历史进程,而这些软件的运营思路,则深切影响着软件是否走在正确的道路上——本来好端端的软件,一顿操作后失足掉出历史...。

今天中午,支付宝官微发话,大家能帮我找找这个阿姨吗?她一年前对机器喊话的时候还没实现,但从今天起,语音购票已经实现了,今天开始上海各大机场、火车站地铁站都有啦,欢迎来调,原来,去年12月,马云给上海地铁带来三项黑科技,可以让乘客彻底不用拿出手机,直接语音购票、刷脸进站,如果地下没网络信号,也完全不影响,如果支付宝账号没余额也没关系,先...。

当下很多小白创业开店是选择好的项目进行加盟连锁,借助品牌的力量与政策扶持实现财富盈收,而且较之于自主开店经营而言,加盟连锁可以依靠总部的实力,依靠的总部的品牌形象与市场号召力快速的打开市场,所以选择加盟连锁的形式进行创业开店,是一种事半功倍的经营方式,深受大众的青睐,那么现在加盟连锁怎么做,可随着小编一起来了解加盟连锁怎么做——行业的...。

3月6日,中共中央政治局常委、国务院总理李克强参加全国政协经济界联组会议,亲切看望出席全国政协十三届五次会议的经济界委员并参加讨论,询问相关问题,讨论关键措施,共商促进经济发展行稳致远大计,3月6日,中共中央政治局常委、国务院总理李克强看望出席全国政协十三届五次会议的经济界委员并参加讨论,新华社记者殷博古摄央视,新闻联播,就李克强总理...。
