三问 因果推理 为什么需要 是什么 如何使用 (三问因果推理方法)
译者:AI研习社( 听风1996 )
双语原文链接: Causal Inference: What, Why, and How
作为一名经济学博士,我致力于寻找某些变量之间的因果关系,用来完成我的论文。因果关系强大到可以让人们有足够的信心去做决策、防止损失、求解最优解等。在本文中,我将讨论什么是因果关系,为什么需要发现因果关系,以及进行因果推理的常用技巧。
1. 什么是因果关系?
因果关系描述的是两个变量之间的关系,即一个变量如何诱发另一个变量的发生。它比相关关系要强得多,因为相关关系只是描述两个变量之间的共同运动模式。通过绘制散点图,可以很容易地观察到两个连续变量的相关性。对于分类变量,我们可以绘制柱状图来观察其关系。要知道两个连续变量之间的确切相关性,我们可以使用皮尔逊相关公式。 皮尔逊(Pearson)的相关性 介于-1和1之间,绝对值越大表示相关性越强。正相关意味着两个变量在同一方向共同运动,反之亦然。
但对于因果关系,要把握的关系就要复杂得多。为了知道变量A是否引起了变量B的发生,即干预A是否引起了结果B,我们需要保持所有其他变量不变,以隔离和量化干预的效果。我们需要控制的其他变量称为混杂变量,即与干预和结果都相关的变量:

在上图中,我举了一个混淆变量,其中年龄与戒烟率和致死率都是正相关的。年龄越大,死亡率越高,但吸烟率越低。如果我们在估计吸烟对死亡率的影响时没有控制年龄,我们可能会观察到吸烟会减少死亡率这样荒谬结果。我们不能在这里得出因果关系,因为我们没有控制所有混杂变量。关于这个例子的更多细节,你可以阅读我讨论 "辛普森悖论 "的文章:
所谓的“辛普森悖论”
在得出因果效应的结论时,我们需要记住的另一个因素是选择偏差。为了隔离治疗效果,我们需要确保治疗组单位是在人群中随机选择的。这样,我们在治疗后观察到的差异不是因为其他因素,而是因为治疗。举个例子,当一家超市想估计提供优惠券对提高整体销售额的影响时。如果超市只把优惠券传递给在店里购物的顾客(干预组),发现他们比没有收到优惠券的顾客(对照组)购买了更多的商品,那么市场由于选择偏差而无法在此处得出因果关系。没有将顾客随机选择到治疗组中。他们之所以在这里,是因为他们在超市购物,这表明与对照组相比,即使没有优惠券,他们也更可能从超市购买商品。比较来自治疗组和对照组的结果变量在这里将毫无意义。
为什么要估计因果关系?
得到因果关系是如此复杂的,何必还要呢?我们为什么不直接使用相关性呢?我们知道相关性在进行预测时是有用的。如果我们知道变量A与变量B有很强的相关性,那么知道变量A的值就可以帮助我们预测变量B的值。在业务环境中,我们可以利用相关性来预测给哪些客户群体做促销,这样我们就可以根据客户过去的行为和其他客户特征来提高转化率。但是,即使是最准确的预测模型,也不能得出结论,当你观察到客户转化率提高了,就是因为促销。我们需要设计实验或进行准实验研究,才能得出因果关系并量化干预效果。在这个例子中,因果推理可以告诉你,提供促销活动是否增加了客户转化率,以及增加了多少。因此,与相关性相比,因果关系能给决策者更多的指导和信心。
如何进行因果推断?
1、不同的干预效应
估计因果效应与估计你的利益结果变量的干预效应是一样的。根据具体的研究或业务问题,可以选择不同的治疗效果进行估计。假设Y是结果变量,其中Y⁰是没有干预的结果,Y¹是有干预的结果。T为虚拟变量,表示单位i是在干预组(T=1)还是对照组(T=0):
平均而言,干预组和对照组之间的结果变量有何不同?
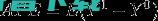
平均而言,干预组中的单位在接受和不接受干预的情况下,结果变量的差异是什么?

在这里,E(Y¹|T=1)是干预组单位的预期结果,它是可观察的。然而,E(Y⁰|T=1)是不可观察的,因为它是假设的。一个单位只能有Y⁰和Y¹这两种结果中的一种,这取决于这个单位所在的组别。如果这个单位已经接受了干预,我们可以观察Y¹,并使用不同的技术来估计Y⁰这个反事实变量。我将在后面讨论不同的技术。

条件平均干预效果是应用某些条件x来估计ATE。在某些情况下,干预会对不同的子组产生不同的影响,并且ATE可以为零,因为这些效果被抵消了。CATE可以用于估计子组之间的异质效应。
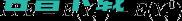
个体干预效应与CATE相同,应用的条件是单位是单位 i。
2,假设
如上所述,在声明因果关系之前,需要采取许多措施。在进行因果推断时,请记住以下假设:
3、工作流程
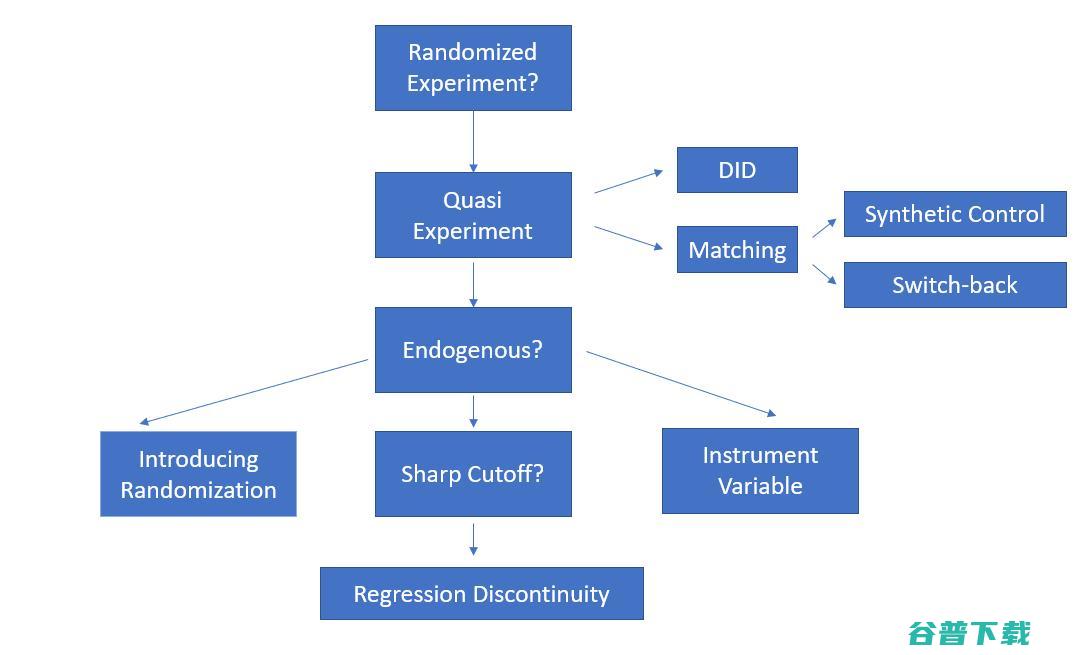
因果推理最大的挑战是,我们只能观察到每个单位i的Y¹或Y⁰,我们永远无法完美测量每个单位i的干预效果,为了应对这个问题,我们需要为干预组找到完美的对照组,使两组之间唯一的区别就是干预。这可以通过运行随机化实验或在随机化不切实际的情况下寻找匹配的干预组和对照组(准实验)来实现。以下是我认为有用的工作流程:
随机对照试验 (RCT)
如果总能随机分出干预组和对照组,生活就会轻松很多! 随机分配干预后,我们可以分别估计治疗组和对照组的结果变量,其差异就是平均治疗效果(ATE)。由于单位是随机选入干预组的,所以干预组和对照组的单位之间唯一的区别就是是否接受过干预。因此,结果变量的差异就是干预的效果。但是,有时由于网络效应或技术问题,无法将干预组和对照组随机化。或者把用户分成两组成本太高。例如,在估计促销活动的效果时,如果将部分用户排除在促销活动之外,会对用户的满意度产生负面影响。在这种情况下,我们可以进行准实验,也就是不依赖随机分配的实验。
DID通常是在对照组和干预组之间存在已存在差异时使用的。但是,我们认为干预组和对照组的结果变量增长趋势没有显著差异(平行趋势假设)。也就是说,按照下表的定义,两组在结果变量上的差异在治疗前后是相同的,d_post=d_pre:
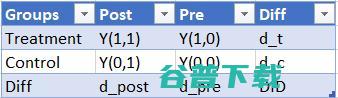
干预组的结果差异为d_t,定义为Y(1,1)-Y(1,0),对照组的结果差异为d_c,定义为Y(0,1)-Y(0,0)。d_t和d_c之间的差值为DID,即干预效果,如下图所示。
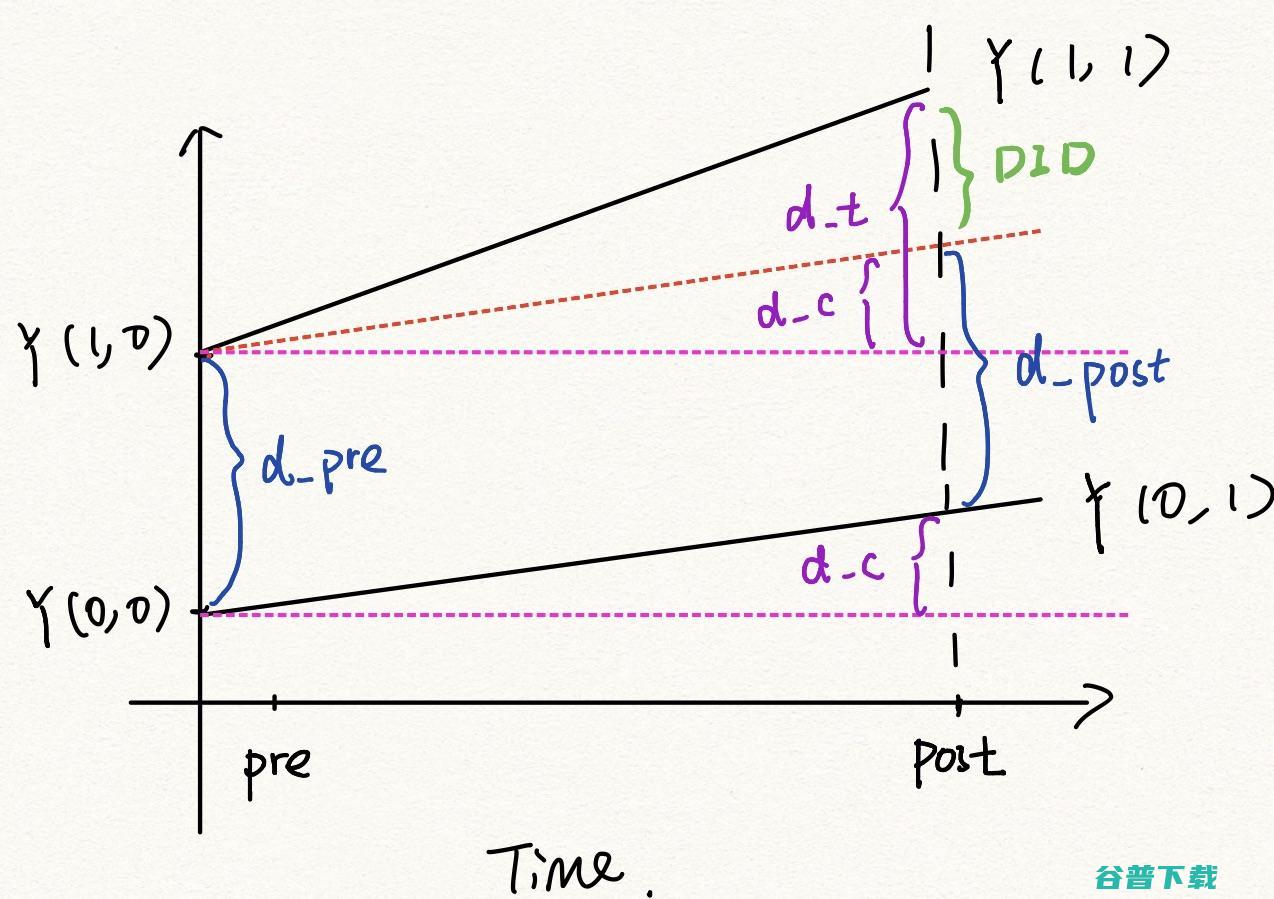
DID = d_t-d_c=(Y(1,1)-Y(1,0))-(Y(0,1)-Y(0,0))平行趋势假设是一个很强的假设,当违背这个假设的时候,DID估计就会出现偏差。
匹配
尽管不可能进行随机实验,但我们可以找到完美匹配的干预组,在不进行干预的情况下量化结果变量。我们可以根据interests特征构建一个人工对照组。例如,我们可以在一个城市给予促销活动,并与其他没有促销活动的城市进行结果变量的比较。这些城市除了促销活动外,其他因素都是相似的。这就像一个横向比较。
我们可以使用的另一种方法是时间序列比较,这叫做switch-back检验。例如,我们可以选择一个城市,在一周内给出促销活动,然后将结果变量与最近一段时间没有促销活动的这个城市进行比较。差异将是促销的效果。
这些技术在面对网络效应时相当有用。使用横向比较或时间序列比较,我们不需要把一个市场分成不同的群体。因此,我们不需要担心同一市场中群体之间的溢出效应。在对整个市场进行比较时,必须确保对照组和干预组市场之间的唯一差异是干预。
内生性
当独立变量X(干预)与回归中的误差项相关,从而使估计结果(干预对结果变量Y的影响)产生偏差时,就会产生内生性。引起内生性的方式有三种:
处理内生性问题总是很麻烦。除了包括所有混淆变量和引入一些随机化外,回归不连续和工具变量是解决内生性问题的另外两种方法。
1、回归不连续
回归不连续是在一个分界点测量干预效果。用一个例子会更容易理解。假设我们想估计发放奖学金对学生成绩的影响。简单地估计有奖学金和没有奖学金的学生之间的成绩差异,会因为内生性而使估计结果出现偏差。获得奖学金的学生即使没有奖学金,也更有可能获得更好的成绩。如果我们有一个给奖学金的临接点,我们可以利用回归不连续来估计奖学金的效应。例如,如果我们给成绩高于80分的学生发放奖学金,那么我们就可以估计成绩接近80分的学生的成绩差异。这背后的直觉是,在影响成绩的其他特征方面,得到79分的学生很可能与得到81分的学生相似。对于成绩在79到81之间的学生来说,被分配到干预组(有奖学金)和对照组(没有奖学金)是大致随机的。因此,我们只能看这个子人群的成绩差异来估计治疗效果。更多详情请查看 维基百科页面 。
2、工具变量
工具变量指的是与自变量X高度相关,但与因变量Y不直接相关的变量,它们的关系就像下图。
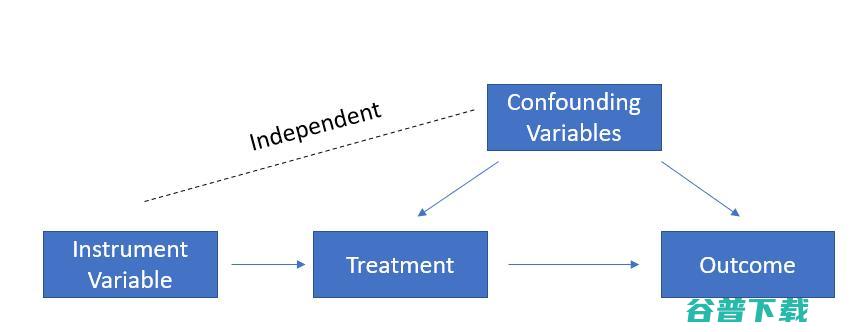
由于工具变量与结果变量并不直接相关,如果改变工具变量引起结果变量的变化,那一定是干预变量的原因。例如,在估计教育对未来收入的影响时,常用的工具变量是父母的教育水平。父母的教育水平与孩子的教育水平高度相关,而与孩子的收入并不直接相关。为具体的研究问题寻找工具变量是很困难的,它需要对相关文献和领域知识有充分的了解。在得到工具变量后,我们可以用2SLS回归来检验这个工具变量是否好用,如果好用,处理效果如何。详情请参考 维基百科页面 。
这些就是因果推理的what、why和how。希望本文可以帮助你总结基本概念和技术,感谢您的阅读。
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



PS学习网(www.lvups.com)为广大PS爱好者提供丰富的photoshop教程,包括PS教程入门,非主流PS教程,PS文字教程,ps调色教程,PS鼠绘教程和图片处理等PS教程自学网站。

北京异彩科技主要从事IT产品的销售与服务,所经营的产品线丰富,覆盖面广范,涉及PC、服务器、工作站、存储、数通、网络安全等设备。
")
闪艺《快穿之我替女配来虐渣(6折)》是一款超好玩的互动阅读作品,快带上好友一起来玩吧~

沈阳东兴嘉业门窗有限公司(13332488840)是一家集生产、销售、安装、售后为一体的沈阳开窗机厂家,其中沈阳电动天窗,消防排烟窗,平移天窗,手动天窗质量有所保障,如果对沈阳电动雨感天窗有需求,欢迎来电咨询。

广东中保祥合保安服务有限公司,是经过广东省公安厅批准,依法持有《保安服务许可证》备案资格的茂名保安服务公司,提供茂名保安,物业保安,校园保安,临时保安等服务,茂名保安公司咨询联系:137-9092-8811.

广州创龙舞台搭建公司13818073616(手机微信同号)提供舞台搭建、舞台灯光出租、音响租赁、LED大屏幕租赁、显示屏租赁、LED大屏幕出租等,曾为阿里各类演出、会展等提供LED大屏幕租赁、大屏幕出租、LED显示屏租赁、广州演出器材租赁。并取得了令人满意的成绩。

蚂蚁云(www.ant-cloud.net)计算服务器提供商,专注云服务器,VPS,香港免备案空间服务器,SSL证书,域名注册,企业建站等云计算解决方案,弹性灵活,助力企业轻松上云。云服务器租用、网站服务器租用、云数据库租用、CDN加速企业建站首选蚂蚁云。

皮皮鲲下载站提供手机应用和安卓游戏,电脑软件等,每天都会更新热门手游和软件,打造一个免费,绿色,安全,无病毒的软件下载基地。

上海纳塑合金科技有限公司长期从事代理巴斯夫抗氧剂,巴斯夫稳定剂,BASF紫外线吸收剂,巴斯夫阻燃剂,GLYCOLUBEVL,陶氏增韧龙沙PETS,Vertellus凡特鲁斯乙烯马来酸酐共聚物,ZeMacE60-P,ZeMacE400,ZeMacE60等新型复合材料,纳塑在纳米材料,高温复合材料,特种弹性体领域建立了独特的技术优势,品质保证,服务周到,提供一站式服务,欢迎来电详谈18121109938.

安恒信息,数字安全领军企业,以DAS(数据安全、AI、安全运营服务)为核心战略,涵盖网络安全、数据安全、云安全、信创安全、密码安全、安全服务等数字安全能力,服务10万+政企单位客户。

第6感为LifeStyles旗下的子品牌。LifeStyles集团源于1905年,在全球60多个国家经营两性健康业务。


今天来聊一聊模拟农场单机游戏合集,想象一下,一边经营着自己的虚拟庄园,一边感受着无压力、充满欢乐的游戏氛围,简直让人欲罢不能!每款农场模拟游戏都有其独特之处,操作起来十分简单,玩家们在其中尽情体验时,仿佛置身于一片轻松惬意之中,一起来探索吧!1、,真实模拟农场3d,你将被引领进入一个充满活力和惊喜的三维农场世界,在这里,你不仅可以尽情...。

2024卡牌可以合成的游戏有什么,卡牌游戏通常都十分经典好玩,基本上所有的卡牌都是需要看完咱们抽取才可以获得的,但这些游戏也给新手玩家准备了许多福利,简单登录即可以领取基础角色上场体验战斗,但想要获取更多其他的角色并不是一件轻松的事情,有感兴趣的小伙伴就看看具体的卡牌游戏内容有什么好的推荐吧,1、,游戏王,决斗链接,游戏王,决斗链接...。

时下讲究综合素质发展,很多孩子都会学习一种或者多种兴趣爱好,舞蹈就是主流的学习兴趣爱好,舞蹈的类型很多,有拉丁舞、民族舞,街舞等,不同的舞蹈受到不同爱好者的喜爱,朵朵兔快乐艺术就是一家专业的舞蹈机构,可以提供丰富的艺术学习,很多创业者就想要加入其中,那么,加盟朵朵兔快乐艺术有哪些条件,加盟朵朵兔快乐艺术有哪些条件朵朵兔快乐艺术成立于2...。

要闻提示1.戏剧性拉满!被字节起诉赔偿800万实习生,拿下NeurIPS2024最佳论文2.烧烤炉通风口,撞脸,蔚来车标,蔚来汽车起诉后获赔30万3.Mate70系列首销!官网售罄、门店大排长龙,华为终端BGCEO何刚线下迎客4.价格战狂飙升温!多家车企上调2025年销量目标,蔚来、小鹏、零跑等新势力近乎翻倍,小米汽车直接翻3倍,BB...。
飓风来临之前,零售巨头沃尔玛将气象数据与公司内部数据相结合深入分析,发现销量增长最多的商品并非蜡烛和瓶装水,而是草莓饼干和啤酒,并将其摆放在收银台附近方便顾客购买,进一步刺激销量,可口可乐旗下公司美汁源分析600种橙汁的味道,并结合卫星图片中实时采集的农作物产量、天气、成本压力和地区偏好等变量建立复杂模型,将果汁生产标准化,确保销往全...。

10月17日,以,‘深,领智能‘圳,创未来,为主题的2023深圳国际智能家居大会在深圳国际会展中心举行,来自GIIC联盟、开源鸿蒙、开源欧拉、星闪联盟、电力线载波,PLC,等技术联盟的专家、从业者共计700余人参会,会议发布了多项成果,包括全球智慧物联网联盟GIIC,筹,与深圳市家具行业协会签订推动制定智能家居互联互通标准战略合作协议...。

发表在坚果投影仪2019,11,2610,53让我们先来简要了解一下坚果G7S,其硬件配置1080P物理分辨率,700ANSI流明亮度,镜头为玻璃材质,支持4K硬件解码,搭载2,16GB内存,内置音箱,内置双频WiFi,语音控制,自动梯形校正,自动对焦等,且其主打为卧室投影,上手体验从我为期不算特别长的体验来看,坚果G7S更像是一个电...。

发表在综合交流大区2022,11,915,49超短焦投影仪,拥有着超低的投射比,能够在小范围内实现大尺寸投影,满足着当下越来越多租房党、家庭用户的观影需求,不断获得越来越多的青睐,双十一到来,对于有意向选择超短焦投影仪的用户来说,双十一超短焦投影仪怎么选呢,今天就来分不同的价位为大家介绍几款性能较好的超短焦投影仪,双十一超短焦投影仪怎...。

系列通过U盘安装软件看电影视频教程,索尼电视当贝UI版安装当贝市场教程1、打开电视找到,设置,菜单,进入选择,应用,功能,找到,安全与限制,,将,安装未知来源,设为允许,2、在电脑下载安装当贝市场,拷贝到U盘,当贝市场下载地址,请点击此处下载,3、将U盘接入电视USB接口,系统会显示U盘已连接,点击,确定,按键,4、在,应用助手,,...。

生长也无非就是这样,一边趔趔趄趄,一边朝阳而生,本文系网易沸点上班室,谈心社,栏目,群众号,txs163,出品,每天降级,不论能否被动了解,路人很难不知道沈月这个名字,有很多人对她的印象是,看见沈月在热搜,就知道,她又要被嘲了,短短三年,从一个青涩大在校生,变成时辰预备面对几亿人领导的女演员;个中滋味,想必也只要沈月自己才懂,网易...。

游客因没在饭店吃饭被锁车,报警却遭怼!大连警方回应状况通报针对网民关注的,一游客在大连因停车疑问报警,事情中民警处置不当状况,我局立刻展开考查,经查,2024年7月11日18时许,在大连市中山区一餐厅门前,一女子因停车疑问与该餐厅上班人员出现争论后报警,接警后,我局老虎滩沿海派出所两名警力临场处置,处警环节中语言不规范,未能正确实行职...。
法律剖析,依据我国法律规则,限号规则如下,一,自2021年4月5日至2021年7月4日,星期一至星期五限行机动车车牌尾号区分为,2和7、3和8、4和9、5和0、1和6,机动车车牌尾号为英文字母的按0号治理,下同,;,二,自2021年7月5日至2021年10月3日,星期一至星期五限行机动车车牌尾号区分为,1和6、2和7、3和8、4和9...。
360百科最近开放了创建编辑词条功能,这意味着个人可共同创建百科,我们知道百科被搜索引擎给予了很大权重,百科上的关键词基本都能排在首页,目前来看,互动百科在360搜索中依然占据绝对高权重,而360搜索已经成为中国第二大搜索引擎了,推测360百科完善后会挤掉互动百科的位置,嗯,憋了很久360百科还是开放了,自己编辑吧词汇量太大,人手不够...。

近日,在广西三江侗族自治县良口乡和里村,侗族民众围炉打油茶,现场洋溢着浓浓年味,打油茶是侗族地区传统的饮食习俗,油茶由糯米、茶油、茶叶等原料制成,是招待宾客的地方特色美食,图为侗族民众在打油茶,龚普康摄图为侗族油茶,龚普康摄图为侗族民众在打油茶,龚普康摄图为侗族民众在打油茶,龚普康摄图为侗族民众在喝油茶,龚普康摄图为侗族民众在打油茶,...。

无论是互联网创业失败还是成功的原因,有时候都和,运气,多少有些相关,这个并不是迷信,而是创业中人多多少少心照不宣的一个话题,这就跟用同一个导演也有可能拍出不同水平的片子,甚至同一套制片流程、标准之下产出的作品也会有良莠之分一样,当然,放到现实的创业环境中,我们还是会以一个专业做融资,以及接触过众多创业项目也同样身处创业公司的视角,给创...。

在当下,人们对于酒店的需求量越来越大,出差需要住酒店,出门旅游也需要住酒店等等,尽管酒店的投入很大,但是营收也很高,所以有些创业者想要加盟开酒店,花筑酒店很有名气,不仅可以加盟,而且加盟流程简单,还有很多加盟优势,那么,花筑怎么加盟连锁店,花筑酒店隶属于旅悦集团,品牌公司是一家综合性的实力公司,旗下不仅有酒店品牌,而且公司还涉足于旅游...。

7月9日,由中国计算机学会,CCF,主办,雷锋网与香港中文大学,深圳,承办的CCF,GAIR2017全球人工智能与机器人峰会进入了第三天,在机器学习专场第四场,乂学教育&,朋友印象创始人栗浩洋为大会带来了题为,用人工智能打造教学机器人提升十倍教育效率,的分享,乂学教育打造的智能教学机器人是如何让学生轻松学习的呢,作为一个保送北大...。
