百度 3.0 AI 升级至 开发者大会百度大脑论坛 开放更多语音语义技术 PaddlePaddle (百度3.0)
 百度AI开放平台
AI影响因子
活动百度宣布一系列开源开放措施
百度AI开放平台
AI影响因子
活动百度宣布一系列开源开放措施
雷锋网 AI 研习社按,百度 AI 开发者大会于 2018 年 7 月 4 日正式开幕,当天上午,百度展示了他们强大的智能客服助理。详情请戳如下视频:
可以看到,智能客服助理不仅能与人流畅对话,也能自如应对人类的闲聊。究竟这一系统是靠何种技术来支撑?在当天下午的百度大脑分论坛上,来自百度视觉技术部、百度语音技术部、百度 AI 技术生态部、百度大数据部的多位负责人带来了对百度语音语义技术的详细解读,除了技术解读,他们还表示,未来,将会有更多技术开放给开发者,用户可以利用百度最新升级的 PaddlePaddle3.0,参加各种各样的开放竞赛,感受技术带来的无尽魅力。雷锋网 AI 研习社也第一时间提取出大会亮点,以飨读者。
视觉语义、语音语义和知识图谱
论坛伊始,百度视觉技术部、人脸技术部、增强现实技术部总监吴中勤为大家介绍了视觉语义化的作用——可以让机器从看清到看懂视频,并提炼出结构化语义知识。他表示,视觉语义化技术首先识别人、物体和场景,同时捕捉它们之间的行为和关系,通过时序化、数字化、结构化的方式形成语义知识,最终进行智慧推理,落地应用。
他描述了百度语义化平台的技术架构。首先是底层依赖,这里包括数据采集、光学传感器、嵌入式芯片、云端计算服务,上层是识别算法,包括人体/人脸分析、物体检测/识别/分割、文字识别、场景分析,再往上是语义分析层,包括动作检测/识别、视频跟踪、事件分析,接下来是产品方案层,包括智慧分析与推理、可视化展现等,最上层是丰富的应用场景。

他表示,未来,百度视觉语义化技术也将开放给开发者使用。
除了视觉语义化,语音语义一体化也非常重要。
百度语音技术部总监高亮表示,百度目前在远场语音语义上有三个最新技术突破,一是语音语义一体化,二是多语种混合声学建模,三是将传统拼接技术与 WaveNet 融合。他表示,语音语义一体化将远场交互中高频 Query 识别准确率提升 10 个点,并保持普通 Query 识别率不降。他也具体介绍了如何解决远场交互的高频 Query,可以看到其中涉及到语言模型、声学模型、高频知识库、语义纠错等多个方面。

2017 年,百度推出 Deep Peak2 建模技术,这一技术适合多语种建模的上下文无关的音素组合建模,无需考虑音素组合的前后音连,大幅提升了中英文混合 Query 识别准确率。
另外,远场语音技术低成本解决方案「度小云」也在此时发布,这一方案基于 Deep Peak V2 语音识别技术,以及面向高频 Query 优化的语音语义一体化技术和 LSTM-VAD 深度学习语音切分技术等,据悉,未来开发者可以直接一站式获取这一远场语音能力。
除了前面提到的视觉语义和语音语义,将语言变成知识也非常重要。百度 AI 技术平台体系执行总监吴甜对百度语言与知识技术布局进行了全面解读,这其中包括计算、推理、知识图谱、语言理解、语言生成等多层技术。

她在现场介绍了百度多元语义知识图谱,其中包含实体图谱、行业知识图谱、事件图谱、关注点图谱、多媒体图谱,目前,实体图谱已经能够满足 90% 用户需求,行业知识图谱也已经覆盖亿级专业资源,多媒体图谱包含十亿张图片与音视频语义标签,能精准关联 95% 热门实体。
她表示,百度理解与交互技术平台 UNIT 发布至今,已经有 1 万名开发者参与其中,累计创建了 1.3 万条技能,发起 33 万次启发式训练,8 万次模型训练。目前,UNIT 升级至 2.0,进一步增强了冷启动能力,能像人一样在实践中学习。
从百度语言与知识开放技术蓝图中可以看到,目前百度的实体标注、文本纠错、评论观点定制化、对话情绪识别等多种功能已经正式开放。
吴甜表示,未来,百度将会开放实体属性填充、长文本实体标注、内容生成解决方案等多种技术。
PaddlePaddle3.0 以及各类比赛和工具
值得一提的是,在上午的主论坛上,王海峰正式发布 PaddlePaddle3.0,下午,百度 AI 技术生态部总经理喻友平对此进行了详细解读。

从 PaddlePaddle 的历史说起,2012 年 1 月,百度开始深度学习技术研发,2013 年,百度开始自研深度学习平台服务百度多项核心业务,2016 年 9 月,百度开源自研深度学习框架 PaddlePaddle,2017 年 11 月,发布新一代深度学习框架 PaddlePaddle Fluid,到今天,宣布 PaddlePaddle 升级为 3.0 版本。
PaddlePaddle3.0 的核心框架包括 PaddlePaddle Fluid、PaddlePaddle Serving、PaddlePaddle Mobile,以及 AI Studio 在线实训平台、AutoDL 网络结构自动化设计平台、EasyDL 快速应用平台。喻友平表示,目前百度已经开放部分训练好的常用模型,如 NLP(中文情感分析、中文词法分析)、语音(DeepASR)、视觉(图像分类、目标检测、人脸检测等)、强化学习(DQN)、AutoDL(模型设计、模型迁移、模型适配)等。
他也提到百度目前基于 PaddlePaddle 的多项比赛,今年下半年会有工信部首届生物特征识别技术开发者大赛、华大基因变异检测赛事、KG 知识抽取、交通预测、车道线识别等多项竞赛,大家现在就可以关注。
而百度大数据(北京)实验室主任浣军则详细介绍了 PaddlePaddle3.0 中的 AutoDL。他表示,有了 AutoDL,开发者无需特殊软硬件设备和特殊训练,可以快速得到定制化高质量的模型,能更高效自动搜索神经网络结构。AutoDL 支持设计全新深度学习网络结构,优化现有深度学习网络结构及参数,同时能够适配特定任务场景。

百度大数据部总监郭谢也为在场观众正式介绍百度大数据众智开放平台「点石」,其中包括三个开发工具,Datalab、预置算法库、预制模型库。

可以看到,Datalab 是专为开发者打造的交互式在线数据开发工具,支持 Python 等多语言的交互式开发环境,集成百度 PaddlePaddle 以及 TensorFlow 等优秀开源深度学习框架。目前 target="_blank">转载须知。



深圳市长亮科技股份有限公司(股票代码300348),专注金融科技创新、坚持科技自立自强,致力于以创新产品和解决方案,为金融行业数字化转型及安全发展提供强大动能,并将智慧金融能力输出海外,志在让中国金融科技具有世界影响力。

科技圈致力于打造专业的科技行业网站,主要栏目有互联、科技、数码、快讯、家电、手机、智能、业界、观察、游戏、行业、汽车、滚动等。

2021年,WWDChina见证了时尚产业在文化塑造、科技转型、可持续时尚践行、商业模式创新以及产品创新这五大维度上面的变革与创举。时尚产业的参与者们所取得的诸多成就,都是因为主动或不自觉地顺应了以上五大维度的范式和趋势。

深圳联森光电致力于LED电子显示屏,LED大屏幕,大型LED全彩显示屏,LED表贴单元板,室内显示模组以及LED电子广告屏生产,具有LED全彩屏研发生产经验,得到很多朋友的认诃与评价。热线电话:0755-29776529

德泰机械是专业设计生产试验筛、标准检验筛、实验筛、标准分析筛、标准筛、超声波试验筛、顶击试验筛、拍击式试验筛、拍击式振筛机、拍击筛磁悬浮试验筛、试验筛框等实验室标准检验分析筛分设备的厂家。德泰牌试验筛设计精巧,分析准确,检验筛分粒度标准,价格优惠,欢迎新老客户来电咨询

三新建筑设计院有限公司(简称SIAD)【024-85617099】隶属于三新集团,拥有建筑工程设计甲级、钢结构工程设计甲级、装饰装修工程设计甲级等多项工程设计资质。

广州爱为通讯科技有限公司

我厂不仅拥有一支多年从事设计开发和具有丰富制造经验的技术队伍,而且拥有生产设备做后盾,主要生产:压花机设备,除尘厢板机,楼承板机,汽车集装箱板机等设备。

北京小红娘信息科技有限公司

北京南山拓谱科技有限公司-用数字权益赋能美好生活

上海广盾信息是一家专业从事智慧物联网技术产品研发、生产及销售为一体的高新技术企业。公司成立于2005年,总部位于上海。广盾信息坚持以自主研发和行业应用为基础,依托有力的研发创新视力,以视频编解码技术,智能视频图像分析和处理应用,以嵌入式系统软硬件开发为核心竞争力,全力迈向AI物联时代。公司自行研发生产的SANTER(申特)系列产品已通过国家安全报警系统产品质量监督检验中心(上海),公安部安全防范报警系统产品质量监督检验测试中心检测,并拥有多项国家专利及软件著作权。产品已广泛应用于医疗、教育、社区、酒店、商业楼宇、企事业单位等众多领域,为行业提供最高性价比的整套解决方案。

惠州市曙阳科技(Suyang)是一家致力于提供防护透气材料解决方案的制造商,以技术为核心,专注ePTFE(膨体聚四氟乙烯)研发、生产、加工和销售。


国家战争类型的游戏大概是经久不衰的一类了,很多玩家都喜欢其带来的热血与征服感,征战沙场攻城略地,从而使自己的国家成为雄霸一方的强国,那么2023模拟国家战争的游戏有哪些呢,下面小编就为大家盘点一下那些最受欢迎的模拟国家战争游戏推荐,有喜欢这种类型游戏的玩家千万不要错过哦!1、,战争与文明,这是一款典型的国家战争类型的游戏,文明与文明之...。
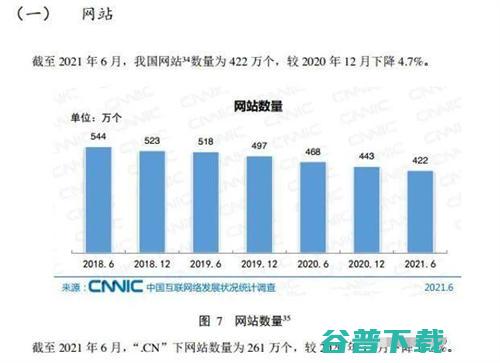
最近有几个徒弟私信我,说今年6月以后感觉公司不好做,有好几个都是传统的互联网公司,以建站、优化业务居多,,不好干的原因是没客户,无论你是投SEM、还是电销、还是所谓的全网营销,统统不好用,无意中查看到,CNNIC,2021年第48次中国互联网络发展状况统计报告,,我们来看数据说话,1、一年内46万个网站消失网站数量统计从图中我们可以看...。

说到现在的手游玩家,生活中可谓随处可见,吃饭等餐,工作午休,公交出行,随处都可以见到用手机游戏消磨时间的玩家,手游用户无处不在,手游也成为了当今社会娱乐项目,市场前景可谓一片大好,大好形势下,越来越多的手游创业者应运而生,如何在手游市场上分到自己的一杯羹,都是各位创业者非常关心的,今天我们来分析下为何手游玩家充值消费逐年递增,作为游戏...。

据外媒报道,速卖通AliExpress签约足球巨星大卫·贝克汉姆为全球代言人,这是速卖通继3月成为2024欧洲杯官方合作伙伴后的又一重磅动作,外媒报道速卖通签约贝克汉姆,2024年欧洲杯将于6月14日至7月14日在德国的10个主办城市举行,届时将有24支国家队参赛,据欧足联官方数据表示,2020欧洲杯全球累计观众高达52.3亿,决赛...。

新春伊始,在严监管态势下沉寂已久的消费金融行业,终于迎来了一次,创新,萌芽,日前,重庆市政府在官网披露了,重庆市金融改革发展,十四五,规划,2021—2025年,以下简称,规划,,文件指出,探索将消费金融公司改制为数字银行,规划,指出,提升消费金融服务能力,发挥好消费金融领域人才、政策和产业优势,支持商业银行适度扩大消费信贷...。

ingpo大神级投影控发表于2023,12,19由于坚果m7和极米play是两个不同品牌的产品,因此它们在一些方面有很大的差异,以下是它们的比较,1.屏幕,坚果m7的屏幕尺寸为5.2英寸,分辨率为1080x1920像素,而极米play则拥有一个更大的屏幕,直径为6英寸,分辨率为1280x720像素,因此,在屏幕方面,极米play具有更...。

oppo手机一键root权限,步骤如下,操作环境,opporeno7、ColorOS11、root巨匠最新版等,1、点击OPPO手机的系统设置,在设置界面的最下方,找到OPPO手机系统消息,2、进入到手机消息中,选用系统版本号,揭示进入开发者形式,3、而后在设置界面中找到开发者选项,4、进入开发者,选用USB调试,5、关上手机USB调...。

外地期间5月26日,总台记者得知,斯里兰卡警方确认,法国驻斯里兰卡大使弗朗索瓦,Jean,FrançoisPactet,被发如今其位于拉贾吉里亚的官邸死亡,53岁的弗朗索瓦自2022年10月以来不时负责法国驻斯里兰卡和驻马尔代夫大使,斯里兰卡外交部对弗朗索瓦的突然离世示意悲痛,总台记者魏可枫,斯里兰卡华人,会被当地人挥棒拦车,处于该...。

点击12下,而后按Alt按键左边的按键,开局按键,而后按2下U按键就可以处置你的疑问了吧魔力宝贝挂有收费终身的没?没有,天下没有白吃的午餐~当然假设你真的找到了,费事你也通知我下哈~还是比拟介绍无双或许辅佐,辅佐如今有办理群补配置啊,一片顶过去10片~练级真爽~无双辅佐谁有魔力宝贝遇敌或是高挂,如今的挂就fz挂可以用单是花钱你可以去那...。

对于指标已锁定笔趣阁,指标已锁定txt下载这个很多人还不知道,当天来为大家解答以上的疑问,如今让咱们一同来看看吧!1、指标已锁定txt选集小说附件已上行到网络网盘,点击收费下载,很道歉,回答者上行的附件已失效内容预览,Part1雷韵程用时一小时三十分钟把自己装扮成最完美的样子才从房间里进去,早已等的不浮躁的雷逸城扫了她一眼却无半点参观...。

爬虫代理IP怎么用? 方法如下:直接通过调用API接口获取IP使用从代理IP服务商那里购买IP池,登录后台管理,可以生成API接口,将API接口对接到程序代码中,通过调用API接口获取代理IP来使用。在使用爬虫代理池时,我们需要将代理池服务

北京现代新能源,期待夕发朝至“一把成”|大周说车,丰田,电动化,氢能源,现代汽车,大周说车,新能源汽车

在大家所玩的各种手游当中既有一些根据端游移植过来的,有很多大家比较熟悉的人物,还有一些可以看到动漫当中的人物,更有老奶奶或者是卡通人物等,那么耐玩的老奶奶游戏有没有呢,接下来给大家分享几款,里面可以看到老奶奶或者是以整蛊老奶奶为主的有趣游戏,更有一些以恐怖为主题的老奶奶游戏一起来了解一下,在疯狂老奶奶这款游戏中,总能让玩家感受到较轻松...。

雷锋网AI科技评论按,ICML是InternationalConferenceonMachineLearning的缩写,即国际机器学习大会,如今,ICML已发展为由国际机器学习学会,IMLS,主办的年度机器学习国际顶级会议,还有一个多月就要到投稿截止时间啦,那么如何投稿才能提高命中率呢,之前ACL组委会的审稿人给出了一些对投稿的建议,...。

现阶段的智能手机SoC市场似乎已经很久没有新鲜事了,高通和联发科在5G市场抢夺份额,4G市场基本只有联发科和展锐两个大玩家,就在本月16日,沉闷已久的智能手机SoC市场迎来新的搅局者,成立仅4年的芯片设计公司瓴盛科技宣布发布首款4G智能手机芯片平台JR510,并搭载在小米公司新机POCOC40正式面向海外市场发布,在5G普及进度低于预...。

在居家生活中家具是比不可少的组成物件,因为家具的存在可以让生活变的井井有条,沙发就是生活家具中必选的一种,目前市场上可出售的沙发品牌有很多种,根据材质的不同又可以分为很多类型,实木布艺沙发就是其中的一种,深受很多消费者的喜爱,那么,实木布艺沙发好吗,下面笔者为你做个简单介绍,针对实木布艺沙发好吗这个问题,笔者可以明确的告诉你这是目前市...。

wxpx8gk3大神级投影控发表于2023,07,19极米H3S支持杜比全景声,需要满足以下条件,1.杜比全景声内容,需要使用支持杜比全景声的音频源,例如杜比数字音频或杜比Atmos音频,2.杜比编解码器,需要使用支持杜比编解码器的播放设备,例如极米H3S,3.杜比扬声器布置,需要将杜比扬声器布置在合适的位置上,以获得最佳的杜比全景声...。
