IPU改变 阿里 云端AI芯片的格局可能被微软 (api改ip)
英伟达在云端AI训练芯片市场超九成的市占率让新入局的竞争者们都将枪口指向这家当红AI公司。声称AI性能比英伟达GPU的新产品不少,但真正突破英伟达护城河的现在仍未看到。
相比在硬件性能上超越英伟达,软件生态的赶超难度显然更大。不过,微软亚洲研究院的NNFusion项目以及阿里云的HALO开源项目,正努力降低从GPU迁移到新的硬件平台的难度和成本,再加上在多个重要AI模型上性能超英伟达最新A100 GPU的IPU,云端AI芯片市场的格局未来几年可能会发生变化。

微软、阿里云开源项目降低迁移出GPU的难度
目前AI的落地,仍以互联网和云计算为主。因此,科技巨头们很快发现迁移到新平台不能只看峰值算力。 Graphcore高级副总裁兼中国区总经理卢涛表示:“客户考虑为一个新的软硬件平台买单时,首先考虑的是能够获得多少收益。其次考虑的是需要多少成本,这涉及软硬件的迁移成本。”
对于科技巨头们而言,GPU确实是一个好选择,但考虑到成本、功耗以及自身业务的特点,仍然有自研或者迁移到其它高性能芯片的动力。此时,软件成为能否快速、低成本迁移的关键。
将已有的AI模型迁移到新的AI加速器时,现在普遍的做法是在TensorFlow写一些后端集成新硬件,这给社区和AI芯片公司都带来了负担,也增加了迁移的难度和成本。

微软亚洲研究院的NNFusion以及阿里云的HALO开源项目,都是希望从AI编译的角度,避免重复性的工作,让用户能够在GPU和其它AI加速器之间尽量平滑迁移,特别是GPU和IPU之间的迁移。

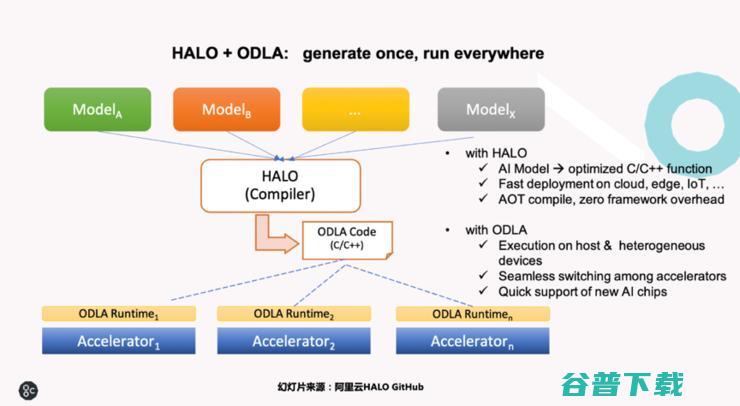
也就是说,NNFusion和HALO向上跨AI框架,既可以集成TensorFlow生成的模型,也可以集成PyTorch或其他框架生成的模型。向下用户只要通过NNFusion或者HALO的接口就可以在不同的AI芯片上做训练或者推理。
这种调度框架在降低迁移难度和成本的同时,还能提升性能。 根据2020 OSDI(计算机学界最顶级学术会议之一)发布的研究结果,研究者在英伟达和AMD的GPU,还有Graphcore IPU上做了各种测试后得出结果,在IPU上LSTM的训练模型得到了3倍的提升。
当然,这样的收益还是需要开源社区与硬件提供方的紧密合作,比如Graphcore与微软亚洲研究院以及阿里云的合作。
“我们与阿里云HALO和微软NNFusion紧密合作,这两个项目支持的最主要的平台是GPU和IPU。”卢涛表示,“目前在阿里云HALO的GitHub里已经有IPU的完整支持代码odla_PopArt,下载开源代码就已经可以在IPU上使用。”
能够便捷地使用IPU也离不开主流机器学习框架的支持。Graphcore本月最新发布了面向IPU的PyTorch产品级版本与Poplar SDK 1.4。PyTorch是AI研究者社区炙手可热的机器学习框架,与TensorFlow两分天下。
PyTorch支持IPU引起了机器学习大神Yann LeCun的关注。之所以引发广泛关注,是因为这个支持对于IPU的广泛应用有着积极意义。

Graphcore中国工程总负责人,AI算法科学家金琛介绍,“在PyTorch的代码里,我们引入了一个叫PopTorch的轻量级接口。通过这个接口,用户可以基于他们当前的PyTorch的模型做轻量级封装,之后就可以无缝的在IPU和CPU上运行这个模型。”
这也能更好地与HALO和NNFusion开源社区合作。 金琛告诉雷锋网,“不同的框架会有不同中间表示格式,也就是IR(Intermediate Representation)。我们希望将不同的IR格式转换到我们通用的PopART计算图上,这也是兼容性中最关键的一点。”
据悉,IPU对TensorFlow的支持,是像TPU一样,通过TensorFlow XLA backend接入到TensorFlow的框架,相当于把一个TensorFlow计算图转换成为一个XLA的计算图,然后再通过接入XLA的计算图下沉到PopART的计算图,通过编译,就可以生成可以在IPU上执行的二进制文件。
金琛认为,“各个层级图的转换是一个非常关键的因素,也需要一些定制化工作,因为里面的一些通用算子也是基于IPU进行开发的,这是我们比较特殊的工作。”
除了需要增加对不同AI框架以及AI框架里自定义算子的支持,增强对模型的覆盖度的支持,也能够降低迁移成本。
金琛介绍,对于训练模型的迁移,如果是迁移一个不太复杂的模型,一般一个开发者一周就可以完成,比较复杂的模型则需要两周时间。如果是迁移推理模型,一般只需要1-2天就可以完成。
IPU正面挑战GPU,云端芯片市场或改变
AI时代,软硬件一体化的重要性更加突显。 卢涛说:“AI处理器公司大致可以分为三类,一类公司是正在讲PPT的公司,一类公司是有了芯片的公司,一类公司是真正接近或者是有了软件的公司。”
已经在软件方面有进展的Graphcore,硬件的表现能否也让用户有足够的切换动力?本月,Graphcore发布了基于MK2 IPU的IPU-M2000的多个模型的训练Benchmark,包括典型的CV模型ResNet、基于分组卷积的ResNeXt、EfficientNet、语音模型、BERT-Large等自然语言处理模型,MCMC等传统机器学习模型。
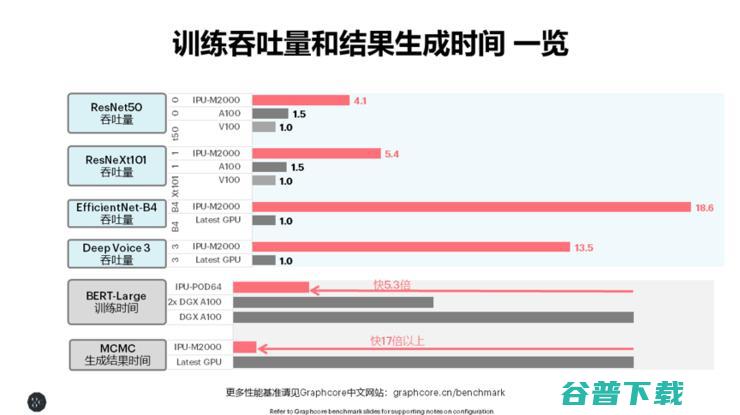
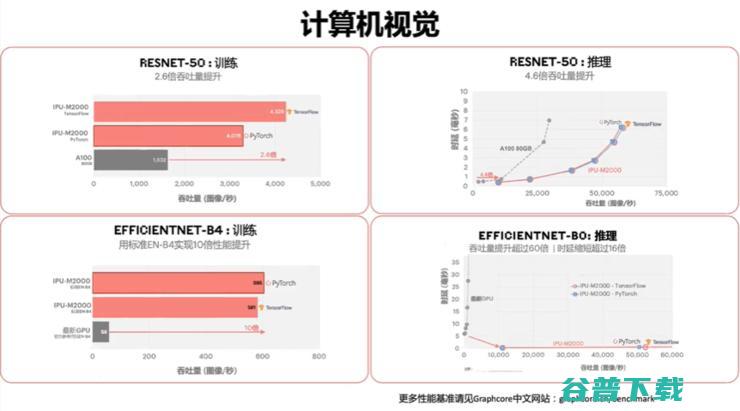
其中有一些比较大的提升,比如与A100 GPU相比,IPU-M2000的ResNet50的吞吐量大概能实现2.6倍的性能提升,ResNeXt101的吞吐量提升了3.6倍,EfficientNet的吞吐量达到了18倍,Deep Voice 3达到了13倍。
值得一提的还有IPU-POD64训练BERT-Large的时间比1台DGX-A100快5.3倍,比3台DGX-A100快1.8倍。1个IPU-POD64和3个DGX-A100的功率和价格基本相同。
强调IPU训练BERT-Large的成绩不仅因为这是英伟达GPU和谷歌TPU之后第三个发布能够训练这一模型的AI芯片,还因为BERT-Large模型对现在芯片落地的意义。
卢涛说:“在今天,BERT-Large模型不管是对于工业界,还是对研究界都是一个比较好的基准,它在未来至少一年内是一个上线的模型水准。”
不过,这一成绩目前并非MLPerf发布的结果,正式结果需要等待Graphcore在明年上半年正式参与MLPerf性能测试。近期,Graphcore宣布加入MLPerf管理机构MLCommons。
“我觉得我们加入MLCommons和提交MLPerf表明,IPU即将在GPU的核心领域里面和GPU正面PK,表明了IPU除了能做GPU不能做的事情,在GPU最擅长的领域,IPU也能以更好TCO实现相等,甚至更优的表现。”卢涛表示。
微软亚洲研究院、阿里云、Graphcore都在共同推动GPU转向IPU,什么时候会迎来破局时刻?
不是GPU的IPU,为什么更值得英伟达警惕?
直击CPU、GPU弱项!第三类AI处理器IPU正在崛起
原创文章,未经授权禁止转载。详情见 转载须知 。


首都医科大学附属北京安定医院是市属精神卫生医疗机构暨三级甲等专科医院,承担着医疗、教学、科研、预防、社会服务和对外交流等任务。医院前身为清政府设立的“疯人院”,创建于1908年。截止2020年底,目前在岗1214人,其中专业技术人员966人,高级职称135人。医院编制床位800张。新门诊病房楼及附属用房工程于2014年竣工并投入使用。北京市精神卫生保健所为我院挂靠单位。

沈阳漫雪雪影业有限公司

腾讯应用宝为您提供微顶跑腿官方最新版本的免费下载,以及微顶跑腿相关图片、资讯、攻略。如果您想在电脑上使用微顶跑腿,还可以免费下载应用宝电脑版。在电脑上流畅运行微顶跑腿,获得更大屏的使用体验。

(天津津门皮肤病医院)是天津市一家治疗皮肤病的专科医院,医院地址位于:天津市河西区黑牛城道189号(大润发超市斜对面)医院在运用中西医结合治疗牛皮癣、白癜风、鱼鳞病、荨麻疹、青春痘、脱发、皮炎湿疹等各种皮肤病方面有丰富的经验.

清华大学总裁班报名中心是清华大学EMBA研修班培训平台让您圆梦清华,结高端人脉;博学慎思提高综合素养;明辨审问提升决策能力;励志笃行打造卓越企业。千秋邈矣独留我,百战归来再读书

游技天地是游戏玩家的技能提升平台,提供专业的游戏攻略、技巧和游戏内战术。我们的团队由资深玩家组成,他们凭借丰富的游戏经验,为玩家提供实用的攻略和建议。

重庆太裕环保主要销售一体化污水处理设备,板框压滤机、带式压滤机、帮助许多企业解决污水处理难题,质量可靠,欢迎各位新老客户前来咨询和了解。

网站商务通在线客服系统是一款国内技术领先、最专业、最权威的企业在线客服系统,网站访客只需点击网页中的对话图标或链接,无需安装或者下载任何软件,就能直接和网站客服人员进行即时交流。是企业进行在线咨询、在线教育、在线客服、在线寻医的有力工具。

厦门万仁博人力资源有限公司

桐乡,桐乡论坛,桐乡生活网,桐论,论坛,梧桐,休闲,生活,娱乐,博客,相册,交友,缘份,网店,C2C商店

云商超是全国中小型超市o2o服务平台;提供连锁零售业线上商城搭建、技术支持;联系电话:400-168-7172。

张家港律师朱德祥律师是中共党员,专业从事律师工作执业已经36年,多年来成功办理了许多经济,民事,海事,刑事等各方面影响大,疑难复杂的大案要案,如果您在张家港地区需要法律咨询或代理服务.欢迎张家港律师事务所.


此前,华为正式官宣了,畅享十周年,新机华为畅享70X,将会在2025年1月3日正式亮相,其中,先锋回归,实力登场,的官宣文案还引发了网友的众多猜测,因为此前华为Mate60系列、华为nova系列皆是通过先锋计划正式开启了5G麒麟芯片的回归,如今,华为畅享70X再次用上这个字眼,大概率也会搭载全新麒麟芯片并支持5G网络,从而实现华为全系...。

iOS新漏洞、Mac漏洞、iMessage漏洞,近来有关苹果漏洞传出的消息越来越频繁,今日乌云发现在最新版iPhone中存在字符溢出漏洞,此漏洞无需物理接触或者人为交互,只需知道目标绑定的Exchange邮箱,即可将远程iPhone手机攻击崩溃,进入,白苹果,状态,在乌云发布的测试视屏中,这部受到攻击的iPhone在开机后马上变为,白...。

发表在投影固件2018,6,115,17请使用格式为FAT32的U盘进行升级USB强刷包,V3.5.9,链接,https,pan.baidu.com,s,1OYHl4K16tr,T5l,kTvvkhQ密码,此处内容被隐藏,回复本帖后可见,文件MD5验证,文...。
近几年搭乘,全民阅读,的发展快车,儿童阅读品牌书果星球持续发力,其合作门店陆续在全国各大城市,落户,为赋能门店高效运营,实现高质量发展,总部持续升级大力扶持三板斧即产品研发、门店帮扶、创投人培训,时刻关注合作伙伴的实际需求并提供与之高度契合的服务方案,书果星球品牌服务中心负责人王老师说到,门店就像书果星球的触角,能让阅读触达每...。

好!看来LZ是爱游之人,冲这点,联合LZ的要求,我拼了……哇哇哇哇哇哇哇哇哇哇哇!!!!!!!!!!!!,精灵乐章,楼主有疏忽掉这个吗,貌似没看你说过这个游戏,怎样,不是炒冷饭吧,这个游戏是代理的,在国外做得不错,经过国外的一路修正之后,职业也还算平衡,而后,内挂是十分低劣的一款游戏,但咱们先不说内挂,先说这个游戏的特点吧,OK,先说...。
大家好,对于暴风影音5破解付费视频补丁0303绿色收费版,暴风影音5破解付费视频补丁0303绿色收费版配置简介这个很多人还不知道,如今让咱们一同来看看吧!暴风影音5破解付费视频补丁可轻松破解付费视频,无需登录即可观看注,暴风影音5破解付费视频补丁是款破解付费视频辅佐工具,局部杀毒软件存在误报,封锁杀软或信赖即可,果怕有毒,请误下,电脑...。

在中国市场上,印度汽车品牌重要包含塔塔汽车,TataMotors,旗下的捷豹路虎,JaguarLandRover,局部车型,以及马恒达汽车,Mahindra&,Mahindra,不过须要留意的是,捷豹和路虎虽然如今是印度塔塔汽车的一局部,但它们实践上是英国品牌,只是被印度公司收买,真正源自印度的汽车品牌在中国市场上并不多见,马...。

好,1、依据查问汽车之家官方消息显示,外观方面,菲亚特菲跃2.4的外观设计杰出,驳回了流线型的车身设计,线条流利,动感十足,2、性能方面,该车驳回的是一款能源十足的2.4升发起机,最大功率可达140马力,能源体现十分杰出,菲亚特菲跃改换火花塞清节气门除积碳造成二三缸失火要素,1.可燃混合气过浓,未熄灭的残余局部都会积累在火花塞电极上炭...。

金舟音频人声分离是一款强大的音频处理软件,软件功能强大,操作简单,支持专业的人声分离,伴奏提取、视频消除人声、视频消除背景音处理,输出高品质高质量的音视频文件。软件功能1、

Kvrocks(键值数据库),Kvrocks是一个开源的键值数据库,它基于rocksdb并与Redis协议兼容,与Redis相比,其目的是降低内存成本,提高能力,复制和存储的设计受到rocksplicator和blackwidow的启发,您可以免费下载。
好友张森最近又推出了一款名为,云友链,的友情链接推送系统,这套系统可以推送同行业、收录,1、权重,1的高质量友情链接资源,解决了大量站长想找高质量友链,却无门路的情况,这套提供提供4大功能,我觉得特别棒,1,因为张森童靴专注,友链,资源这块已经5,6年时间了,拥有近10W网站资源,所以在推送同行业网站方面能更实时和精准,并且质量有保证...。

在当前市场发展道路中,二手资源在未来市场上有很大发展方向,其中包含了旧衣服回收,在如今这个风口,可谓是充满了机遇与挑战,旧衣服回收可以很好地实现了资源利用,发展前景广,为一些创业者提供了平台,那么回收衣服加盟旧衣服回收好吗,实力品牌效应抢占市场现在市面上关于旧衣物回收的品牌有很多,创业者在选择一个成熟化品牌加盟之后,会得到公司总部带去...。

做出超用户预期的产品,做出让用户惊喜和兴奋的产品,超用户预期=极致体验×极致服务×极致产品,极致产品=功能×情感×温度,×关心、关注、尊重用户×了解用户×了解人性×用户参与感,好的产品也都是顺应人性的,用户情绪愉悦、不爽、愤怒、恐惧愉悦就是需求被满足,不爽的本质,都是某个点没有被满足,爽就是绷了很久的需求突然被满足,愤怒和恐惧都是来...。

很多朋友都想创业,健身这一块是大家容易忽略的商机,智慧之选健身房是很生意好的,重点是要找到合适的项目,北京英派斯健身加盟项目就是一个非常好的项目,经营简单,做生意更带劲!智慧之选健身房事业,选择知名品牌成功更有把握!英派斯集团的愿景目标是,成就健康之道,,即成为健康之道解决方案的优佳提供商,英派斯的健身器械先后ISO9000系列质量体...。

坚持创业四大原则,聚焦原则,聚焦微商个人自媒体,不下水,不看其他机会,现金流原则,永远坚持先100%收钱到账,再服务的原则,个体户原则,小组运作,高效务实,坚持小而美,压抑自己刻意不做大,独立发展原则,永不被绑架,不和任何公司及任何人股权合作,粉丝等控制在自己手上,公司股权一个人100%拥有,@龚文祥来源,卢松松博客QQ,微信,133...。
