A76架构 2.4GHz便可干掉骁龙845 浅析ARM全新Cortex (a76架构和a78架构的区别)
又是一年6月,ARM在旧金山发布了全新的Cortex A76架构。

数码爱好者们对ARM的架构代号想必已经耳熟能详,但或许并不知道这些架构具体出自谁手。实际上,ARM在全球拥有3家设计团队,分别是位于美国德州的奥斯丁团队、位于法国南部的索菲亚团队以及位于英国大本营的剑桥团队。
这三家团队各有分工,奥斯丁团队负责设计高性能架构,代表作为Cortex A57和Cortex A72;剑桥团队专门设计Cortex A53和Cortex A55等低功耗架构;而索菲亚团队则主打均衡,Cortex A73和Cortex A75便是出自其手。

不过自摩尔定律在28nm节点放缓开始,奥斯丁团队在Cortex A57和Cortex A72架构上两次遭遇瓶颈,性能强劲是不假,可功耗和发热也堪称恐怖。自那以后的几年里,奥斯丁团队一直没有什么动作。就在人们几乎已经忘了这群美国壮汉的时候,奥斯汀团队带着全新的Cortex A76回归了。
从设计的角度来看,Cortex A76对于ARM来说至关重要,他是一款完全重新打造的全新微架构,是“第二代奥斯汀家族”的领军者,代表了一个全新的开始。ARM称它“是一款具有的笔记本级性能的处理器。”

Cortex A76在最新7nm工艺下,运行频率预计将达到3GHz,相比基于10nm工艺制造、运行在2.8GHz的Cortex A75,能耗将降低40%,性能可提升35%,机器学习能力可提升4倍。
Cortex A76架构浅析
Cortex A76是一个乱序超标量内核,前端为乱序4发射指令解码,后端为13级流水线,执行延迟为11个阶段。ARM在设计了一个“定向预测获取”单元,这代表分支预测单元会反馈到取指单元中。ARM还在业内首创使用了“混合间接预测单元”,将预测单元与取指单元分离,且支持内核中的各模块独立运行,运行期间更易于进行时钟门控以节省功耗。

Cortex A76分支预测单元由3级BTB(分支目标缓存)支持,包括一个16链路nanoBTB,一个64链路MicroBTB和一个6000链路主BTB。在Cortex A73和Cortex A75世代,ARM便声称其分支预测单元几乎能预测所有分支,Cortex A76的这个新单元似乎还要比之前更强一些。

取指单元的运行速度为每时钟周期16Byte,分支预测单元的运行速度是取指单元带宽的两倍,为每周期32Byte,可在由12个“块”组成的取指单元之前提供一个取指队列。这样做的目的是,分支预测错误时可以在管道中隐藏分支气泡,并避免使取指单元和核心的其余部分陷入停滞,ARM称Cortex A76最多可应对每周期出现8次分支预测错误。
Cortex A76的取指单元最多可提供16条32bit指令,取指流水线由2个指令对齐和解码循环组成。在指令解码和重命名阶段,Cortex A76每周期可吞吐4条指令,并以平均每条指令1.06Mops的比率输出宏指令。

此前,Cortex A72和Cortex A75每周期可吞吐3条指令,Cortex A73则只能吞吐2条。根据雷锋网掌握的资料来看,Cortex A73相比Cortex A72解码带宽下降是为了优化能效,而随着对移动处理器性能需求的提升,Cortex A75恢复了每周期3吞吐的设计。此次Cortex A76则更进一步,成为了公版架构中解码带宽最高的,但仍低于三星和苹果的定制架构(三星M3每周期6吞吐/苹果A11每周期7吞吐)。

在指令重命名阶段,ARM分离了重命名单元,并将时钟门控用于整数/ASIMD/标记操作,重命名和调度从A73和A75的每次2周期缩短为1周期。宏指令按照每条指令1.2μop的比例扩展为微操作,每周期执行8μops调度,相比Cortex A75的6μops/周期和Cortex A73的4μops/周期有明显增强。
Cortex A76的乱序提交窗口大小为128,缓冲区被分成负责指令管理和注册回收的两个结构,称为混合提交系统。由于性能缩放比只有1/7,即缓冲区增加7%只能提升1%性能,所以ARM并没有着重增强这部分设计。

流水线方面,整数部分包含6个问题队列和执行端口,共3条整数执行流水线,由1个16深度的问题队列提供服务。其中2条整数流水线可执行简单算术运算,1条可执行乘法、除法和CRC等复杂操作。ASIMD/浮点部分则包含2条流水线,它们由2个16深度的问题队列服务。

在整数运算方面,Cortex A76将乘法和乘法累加延迟从Cortex A75的3个周期降低到2个周期,总吞吐量保持不变。而由于Cortex A76有3条整数流水线,在执行简单算术运算时的吞吐量相比Cortex A75的2条流水线增加了50%。

在负责浮点和ASIMD操作的“VX”(矢量执行)流水线中,ARM也做了重要的改进。Cortex A76的浮点算术运算延迟从3个周期降低到2个周期,乘法累加也从5个周期降低到4个周期。ARM表示,相比Cortex A75,Cortex A76的双128bit ASIMD可带来双倍的执行带宽,四倍精度操作的执行吞吐量增加了一倍。

ARM还在Cortex A76上引入了第四代预读取单元,每个核心有4个不同的预读取引擎并行运行,查看各种数据模式并将数据加载到缓存中,以更接近完美缓存命中操作的目标。ARM在Cortex A76的缓存体系设计上没有做丝毫妥协,在带宽和延迟两个方面都做到了堪称完美的水平,据说可将缓存带宽提高90%之多。
性能和功耗预测
综合以上这些架构改进,ARM称Cortex A76相比Cortex A75,每周期整数性能和浮点性能可分别增长25%和35%,再加上高达90%的缓存带宽提升,Cortex A76的GeekBench4跑分提升了28%,JAVAScript性能提升了约35%(Octane,JetStream)。

ARM给出了运行SPECint2006测试的性能对比,在运行GCC编译的基准二进制文件时,Cortex A76在2.4GHz时便干掉了骁龙845,同频性能提升了15%。当然,半导体工艺所带来的频率红利对SoC的性能提升也非常重要,如果台积电7nm工艺顺利投产,让Cortex A76运行在3GHz+的频率上,Cortex A76的性能将和使用三星自研M3架构的全新Exynos 9810持平。

除了性能增强之外,Cortex A76的能耗比也有一定提升。在750mW的内核功耗预算下,7nm的Cortex A76相比10nm的Cortex A75可提升40%性能。ARM表示,Cortex A76可实现四核持续满载时保持满速不降频运行。
不过此前ARM立下的频率目标往往有些过于乐观,例如最初预计Cortex A73将运行在2.8GHz,Cortex A75则为3GHz,而二者的实际最高运行频率仅为2.45GHz和2.7GHz。对半导体供应商来说,工艺成熟度和不同流水线间的差异均会影响芯片运行频率,压低频率上限是为了保证供货量不得已而为之。

此外据雷锋网了解,每种核心架构在某一工艺下,都有一个能耗比最佳的频率区间。以使用三星自研M3架构的全新Exynos 9810为例,其CPU大核集群在单核、双核、四核满载的情况下频率分别为2.7GHz、2.3GHz、1.8GHz,功耗均为3.5瓦左右。 换言之,经过逆推可知,M3核心从1.8GHz到2.3GHz, 500MHz频率功耗便翻了一倍,而从2.3GHz提升到2.7GHz,仅400MHz的提升就让功耗再次翻倍。
而从1.8GHz到2.7GHz,即便性能也线性同步提升,幅度也只有50%,功耗则翻了两番。可见越过最佳能耗比区间后,冲击高频需要付出极大的功耗代价。而骁龙845的Kryo 385 Gold核心的表现也与之类似,在超过大约位于2.1GHz的阈值后,功耗飙升的幅度甚至比三星的M3核心犹有过之。

因此,首批使用Cortex A76架构的SoC,频率有很大可能依然达不到3GHz。雷锋网认为,考虑到核心架构的变化和规模的增长,其实际频率会在2.5GHz左右,但不排除随着后期工艺成熟或将其应用在笔记本等对功耗较为宽限的设备时可冲上3GHz+的高频。
结论与思考
最近几年里,人们一直在期待能与苹果一较高下的强劲架构。三星在不久前推出的自研架构M3虽然在性能上追近了苹果A11,代价却是单核3.5W的恐怖功耗。在这种情况下,ARM依然选择稳扎稳打的进行世代更替,这次奥斯丁团队的Cortex A76并不是性能怪兽,它充分显示了一个平衡的微架构有多么重要。

据悉,高通和华为海思已经在准备Cortex A76 SoC的研发和生产,我们很可能会在今年年底前看到它在商业产品中出货。而三星方面则比较微妙,Cortex A76的性能并没有超越M3,所以在理论上三星只需重点改善M4(如果有的话)的能耗比即可。
不出意外的话,基于Cortex A76的架构将在接下来的几年里至少进行两次迭代升级。ARM已经连续5年达成年度规划目标,并且年复合增长率为20-25%,随着移动处理器迅速接近X86处理器的性能,未来几年的处理器市场将会更加有趣。
原创文章,未经授权禁止转载。详情见 转载须知 。


互联二维码生成器支持文本、图片、文件、音视频等10大类二维码在线制作,提供生产制造、建筑施工、物业后勤等10大行业、8大领域、41大应用场景的二维码应用解决方案。

颐欣(上海)传感器是一家从事传感器设计、生产和销售为一体的传感器生产厂家,拥有多种传感器的设计研发和生产制造经验。产品覆盖:IEPE加速度传感器、电荷型加速度传感器、电容型加速度传感器、加速度传感器、动态压力传感器、压电型加速度传感器、应力应变测试分析系统、动态信号测试分析系统、坚固型动态信号测试分析系统、在线监测系统等。

桌面天下为您提供电脑主题,桌面壁纸,图标,鼠标指针,屏幕保护,登陆界面等系统美化资源的免费下载.

山东美新玻璃科技有限公司是高端玻璃制品深加工企业,主要从事平板玻璃深加工技术开发和中空玻璃产品及配套件制造。主要产品包括钢化玻璃、中空玻璃、防弹玻璃、彩釉玻璃、防火玻璃、调光玻璃、夹胶玻璃、中空百叶玻璃等

深圳拓普科新能源科技有限公司是由归国留学人员和行业技术专家共同创立,公司成立于2010年,位于深圳南山西丽大园工业区,是深圳市高新技术企业,公司通过ISO9001质量管理体系认证。 深圳拓普科依托科研机构和高校的强大研发能力,不断设计、研发最新的产品,广泛应用于电力、通信、能源、金融等领域。公司和中国科学院深圳先进技术研究院、内蒙古工业大学等开展了广泛的合作,是内蒙古工业大学的产学研合作实践基地和大学生实习基地。 公司专著于锂电电源方案解决、电池监测检测维护等产品和电力产品的设计、研发、生产、销售,提供技术咨询、方案设计与售前售后服务,产品销售于全球市场。广泛地使用在发电厂、供电局、变电站、太阳能、风能、医疗卫生、通信、金融、交通等领域,是UPS电源正常工作的后备保障。 拓普科致力于低碳、环保、绿色、可持续发展,为客户提供放心的产品,提供优质而贴心的服务。 拓展技术优势、普及环保理念、科学规划发展、能源决定未来 ——拓普科新能源

AOTEM奥天防雷器-佛山防雷检测公司

新疆隆成实业集团有限公司是一家具有二十二年发展历史的多元化集团公司,由润滑油和非润滑油两大板块构成,下辖十五个子公司。润滑油板块新疆金雪驰科技股份有限公司主营业务为润滑材料的研发、生产和销售,是西北规模最大的民营润滑油领军企业,也是中国民营润滑油十强企业;非润滑油板块乌鲁木齐市隆成实业(集团)有限公司主营业务为精细化工产品的研发、生产和销售,同时涉足医疗卫生、石油及化工产品贸易、塑料包装、废油再生等多个领域,其中乌鲁木齐市华泰隆化学助剂有限公司是新疆PVC化工助剂的龙头企业,也是中国PVC化工助剂前三甲企业。

沈阳桌椅租赁公司优质服务,价格公道,专业团队,为您提供沈阳庆典策划,礼仪策划,活动策划,舞台搭建,舞台租赁,专业沈阳庆典策划公司,礼仪策划公司,活动策划公司,舞台搭建公司,舞台租赁公司,专业桌椅租赁,沙发茶几出租,铁马乌兰刀旗出租!

溢瑞随笔探索互联网知识价值,专注读书、生活、游戏、副业、电商、手机赚钱等领域内容,发展手机副业过程中,分享手机赚钱攻略和经验,提升个人能力同时学习一些互联网赚钱方法,实现个人成长和收入增长。

新滨网是滨州市重点网站之一,读者覆盖了滨州党政机关、企事业单位人员及广大市民,活跃度高。一直以来我们在公益活动和传播正能量。

中豪搜服网汇集散人玩家最喜欢的最新传奇私服资讯,可以下载新开传奇sf、最新传奇私服及各种传奇私服攻略,快来玩吧!


数学是所有学科中最基础也是让不少学生感到头疼的一门,学好小学数学打好基础无疑会大大降低后续学习的压力,小学数学app排行榜前十名2022小编刚好整理完,下面就让小编为大家推荐几个,帮助大家打好数学基础,优化学习体验,1、,小学数学,小学数学是一款专为小学生打造的数学学习app,软件包含了各个版本的小学数学课本,方便用户根据自身情况进行...。

移动VR设备便宜、便携,可是VR体验效果远不如PC端的VR设备,其根源还是在于手机或是一体机没有足够强大的处理能力,但在日前正在举办的GoogleI,O大会上,谷歌发布了一款名为Seurat的开发工具,致力于解决移动VR的这个难题,据雷锋网了解,这款开发工具Seurat的名字是来自于一位法国画家GeorgesSeurat,谷歌称Seu...。

随着滴滴的成功上市,其自动驾驶业务的相关信息也随着招股书公布于世,这一个于2019年3月分拆的独立公司,目前团队人数超500人,拥有超过100辆自动驾驶汽车的车队,公司体量远超大部分自动驾驶初创公司,短短两年,滴滴自动驾驶已完成三轮超11亿美元的融资,首轮估值达34亿美元,兵强马壮、粮草备足,滴滴自动驾驶将面向一个规模超万亿元的共享无...。

中铁三局是铁路局,中铁三局前身为铁道部第三工程局,是具有综合施工能力的大型建筑企业,是世界,双五百强,中国中铁股份有限公司的全资子公司,中铁三局主要从事交通基础设施工程建设施工,是全国首批工程总承包建筑企业,具有铁路工程施工总承包特级资质,是可承接房屋建筑、公路、铁路、市政公用、港口与航道、水利水电各类别施工总承包、工程总承包和项目管...。

综合美国,纽约邮报,和,每日野兽,网站7月9日报道,美国联邦法警局示意,两名法警上周在一名最高法院大法官位于华盛顿特区的住宅前口头守卫义务时,开枪打伤一名据称希图劫车的嫌犯,过后对方曾拿枪指着其中一名法警,法警局示意,外地期间7月5日,这两名法警驾驶的车辆停靠在大法官索尼娅·索托马约尔,SoniaSotomayor,的家门外,清晨1时...。

邮件已发送请及时核查满意请采用十分感谢O,∩,∩,O下载有疑问请回邮或许网络Hi咨询我电影,狼图腾,迅雷下载完整版地址,狼图腾,WolfTotem,是中法合拍的一部冒险剧情片,改编自姜戎同名小说,采用3D实景拍摄,由法国导演让·雅克·阿诺执导,冯绍峰、窦骁、巴森扎布、昂和妮玛和尹铸胜主演,影片讲述了在内蒙古大草原上,牧民与狼为了生...。
当天,小编给大家引见win10系统电脑的阅读器将自动下载工具设为迅雷的方法,宿愿对大家有所协助,详细如下,1.首先,请大家将自己的电脑关上,而后点击其中的,阅读器,图标,进入它的主界面,2.第二步,接上去,咱们须要选用屏幕右上面的,菜单,图标按钮,大家还能够经常使用,ALTF,组合键将其关上,3.第三步,如图所示,请点击,设置,按钮,...。

终于醒了前几天修改了仅退款规则不出天京东也紧随其后宣布支持仅退款京东也将全面支持仅退款电商京东微新闻第张京东也将全面支持仅退款电商京东微新闻第张另外松松在说一句京东的仅退款是有严格要求的这项政策提出了退款不退货的策略但不是真的不退货而是发出退款申请后先退款再退货的服务自此国内大网购平台淘宝京东先后都支持了仅退款服务京东...

CodeVirtualizer是一个强大的Windows应用程序代码混淆系统,它可以帮助开发人员保护他们的敏感代码区域免受逆向工程的影响,基于代码虚拟化的非常强大的混淆代码。

下载专题,提供下载的相关文章和相关资讯,在本栏目你可以看到下载这个内容的相关各类文章很多篇,如有不足请提供给我们更多下载的文章供大家查阅.

重庆分类目录网站收录IT资讯相关的优秀网站大全分类检索,为上网用户提供IT资讯网站排行榜与您分享、收藏!

盲盒系统V4.0】UNI全开源盲盒商城交易平台系统二次开发带易码支付通霸云H5盲盒商城源码这个盲盒系统对接的**宝,码支付易支付,微信登录,阿里云OSS,后台有盲盒商品**概率设置,可设置落地域名(炮灰域名设置)

不论是在现实生活中还是在虚拟的世界中,必须要有很强的反应能力,才能轻松完成自己想做的事,如今训练反应力游戏具有很强的挑战性,也是人们比较热衷的类型,也可在其中展开即兴快速问答的模式,久而久之就会让自己的反应能力变得更快,无论是孩子还是成年人都可轻松操作,本文将为大家做出详细的归纳,看看有没有你喜欢的,3d的立体画面,以及简约的画风,让...。
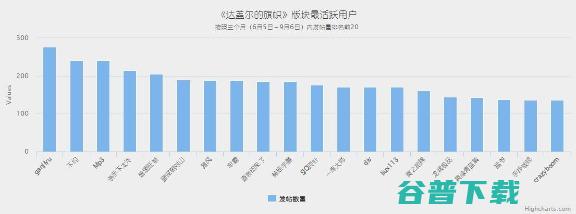
采集到的统计数据样本说明数据来源,caoliu网站,达盖尔的旗帜,版块页内容,时间跨度20150605至20150907,选择此版块是因为这个版的内容都是由注册的用户生产的,具有一定的分析价值,条主题帖的标题、发帖时间、每条主题的回帖数量、发帖用户,共由576个用户生产,让一起来品味一下这个神秘社区的数据,从8537条主题信息中总共...。

中铁建工集团是国企,它隶属于世界500强企业——中国中铁股份有限公司,是其全资子公司,中国中铁股份有限公司是由中国铁路工程总公司改制而来的,所以中铁建工集团是国企无疑,首先,我们来了解一下中铁建工集团的基本情况,中铁建工集团是一家在建筑工程领域具有强大实力和丰富经验的企业,其业务涵盖了铁路、公路、市政、房建等多个领域,该集团在国内外都...。

孩子阅读兴趣的培养相当重要,如果阅读兴趣、阅读方法能够养成,对于孩子今后的课程学习也很重要,快乐书童在行业有很多年的时间,能够以儿童阅读兴趣培养为主,快乐书童有宣传推广吗,主要宣传渠道是什么,快乐书童经过很多人的努力研究,能够在孩子阅读兴趣培养方面做的更出色,让更多孩子在公司的指导下养成会阅读、喜欢阅读的习惯和兴趣,公司也有自己的宣传...。

所谓生意难做,归根结底有两个原因,一是你从顾客身上薅的太多,二是对人性的了解和运用不到位,比如以前满大街有很多的小笼包子,现在很少见了,因为没人买没人吃,包子的受众客户群本来就是平民百姓打工一族,结果那包子弄的还没有乒乓球大,里面的馅和花生米一样大,卖十几块一屉,我想大部分人吃完以后只有一个念头,再也不吃了,这样的老板只考虑利润越大越...。
