ICCV2021 (iccv2024)


我们观察到,成对标记的位时图像的重要性在于, 变化检测器需要成对的语义信息来定义对象变化检测的正负样本。 这些正、负样本通常是由两个不同时间的像素在同一地理区域是否具有不同的语义来决定的。位时像素的语义控制着标签分配,而位置一致性条件(两个时相的像素应处于相同的地理位置)仅用于保证独立同分布的训练和推理。可以想象,如果我们松弛位置一致性条件来定义正负样本,那么变化是无处不在的,尤其是在未配对的图像之间。

其中Xi, Xj为真实双时相图像对,对应的Y是其语义像素标签,F
 为变化检测器参数。将伪双时相图像对(Xt1,
为变化检测器参数。将伪双时相图像对(Xt1,
 Xt1)替换为真实双时相图像对,并重新利用逻辑异或运算分配伪双时相图像对的变化标签,从而将原学习问题松弛为下式的仅利用单时相图像即可完成的学习问题:
Xt1)替换为真实双时相图像对,并重新利用逻辑异或运算分配伪双时相图像对的变化标签,从而将原学习问题松弛为下式的仅利用单时相图像即可完成的学习问题:

为了利用单时相图像提供监督信号,我们提出了一种伪双时相图像对构建技术,其通过对一个训练批次中的图像Xt1进行随机排列得到伪第二时相图像
 Xt1,并且保证每个伪图像对中的图像各不相同。通过观察可以发现,伪双时相图像对的变化标签可用两张图像的语义像素标签(one-hot为二值标签)的逻辑异或表示,这样即可完成伪双时相图像对的正负样本定义。
Xt1,并且保证每个伪图像对中的图像各不相同。通过观察可以发现,伪双时相图像对的变化标签可用两张图像的语义像素标签(one-hot为二值标签)的逻辑异或表示,这样即可完成伪双时相图像对的正负样本定义。
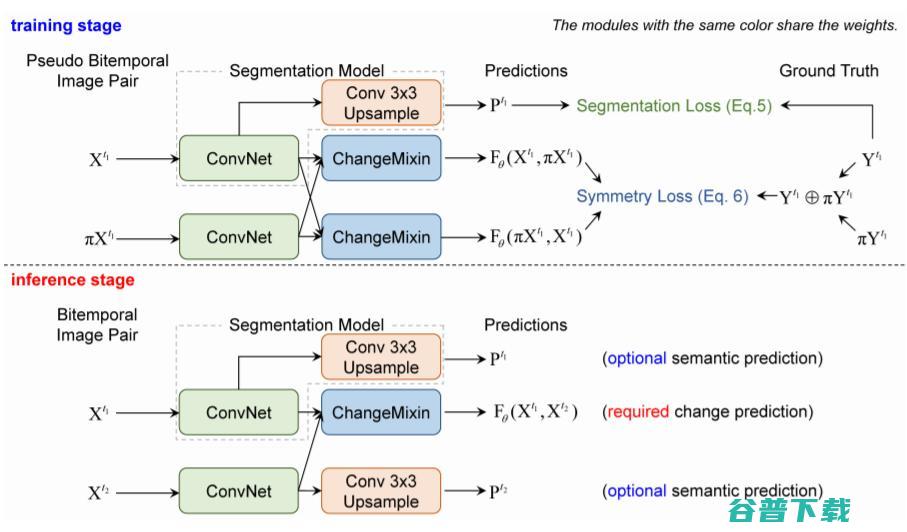
图1:模型训练与推理流程
ChangeStar是一个简单而统一的网络,由一个深度语义分割模型和ChangeMixin模块组成。 这种设计的核心思想在于 重用现代语义分割架构 ,因为语义分割和物体变化检测都是密集的预测任务。为此,我们设计了ChangeMixin模块,使任何现成的深度语义分割模型能够检测物体变化。ChangeMixixin模块由若干卷积层和一个时序交换模块组成,其输入由分割模型计算得到的高分辨率语义特征,输出双向的变化检测图用于后续的学习与推理。我们在实验中发现,一个收敛的模型,双向变化检测图相似度极高,因此在推理阶段我们选择其中一个方向的变化检测图作为最终预测值。
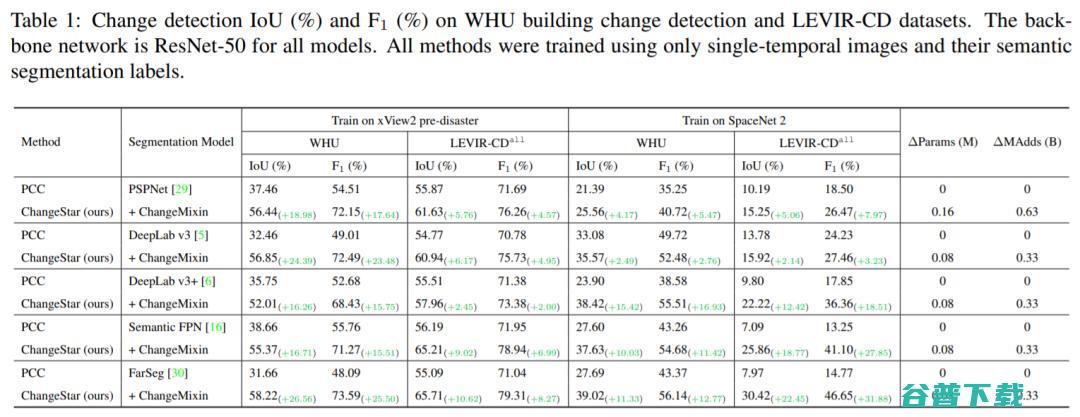
这部分展示了所提出方法在不同训练数据与测试数据下的泛化性实验结果。对比方法采用基于深度语义分割模型的分类后比较法,作为单时相监督的基线。实验结果表明,所提出的方法可有效提升单时相监督下的变化检测性能,具有很好的泛化性能。
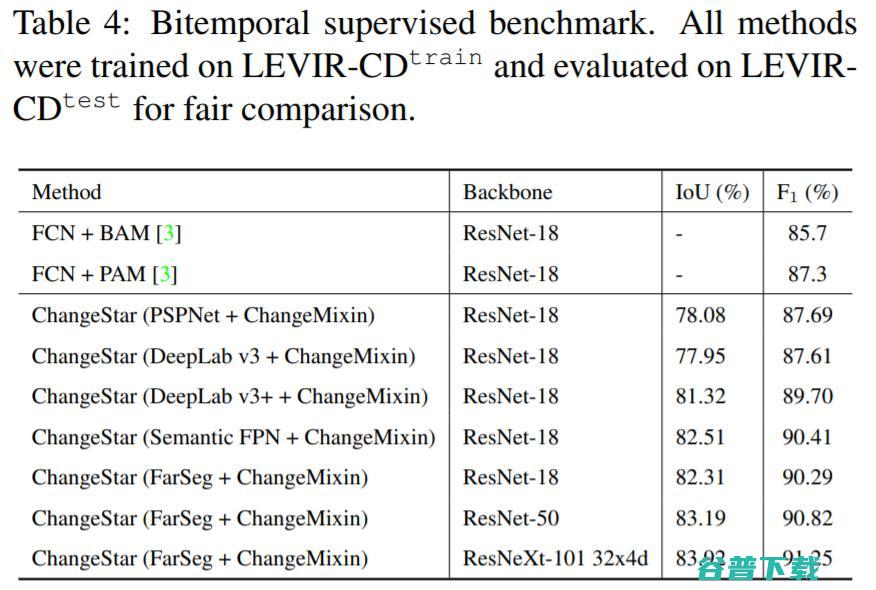
同时为了验证所提出架构的有效性,我们在双时相监督下训练了ChangeStar模型的各种变体。实验结果(表4)表明 ChangeStar架构对已有的分割模型具有良好的兼容性,在相同骨干网络的情况下可取得更加优异的性能。
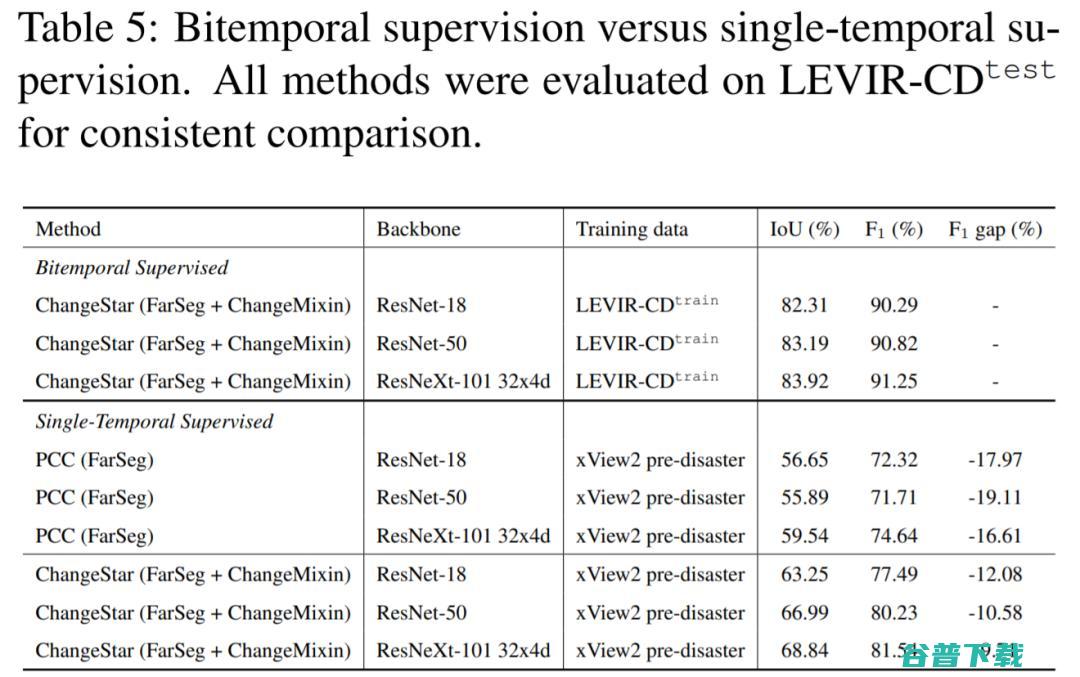
为了了解单时相、双时相监督之间的实际差距,我们利用相同模型开展了多组对照实验,从实验结果中可以发现,单时相监督作为一种弱监督信号,与双时相监督这种强监督信号相比仍有一定差距,但差距随着骨干网络容量的提升而减小, 目前F1精度差距最小可缩小到10%以内。 然而本文提出的方法仅仅是在单时相监督上的初步探索,未来还有更大的改进空间,例如使用模型容量更大的transfomer模型作为基础模型、更大的单时相监督数据、更好的单时相监督学习策略都是值得未来探索的研究话题。
更多的消融实验与讨论可见原文。
在这项工作中,我们提出了 巧妙绕过了传统的双时相监督学习中收集成对标记数据成本高的问题。 STAR提供了一个利用任意图像对中的物体变化作为监督信号的新视角。为了证明STAR的有效性,我们设计了一个简单而有效的多任务架构,称为 用于联合语义分割和变化检测,它可以通过进一步提出的ChangeMixin模块重新使用任何深度语义分割架构。
大量的实验分析表明,提出的方法可以以较弱监督信息学习一个鲁棒的变化检测器;同样双时相监督条件下,超越了目前的state-of-the-art方法。我们希望STAR将作为一个坚实的基线,在未来服务于弱监督变化检测研究。

版权文章,未经授权禁止转载。详情见 转载须知 。



最新算命算法,算命的免费网站,主要测算生辰八字算命,八字算命婚姻,免费姓名测试,宝宝起名打分,星座运势,周易算命,在线抽签等数十项在线精准算命_命推网

安防安防工程弱电弱电工程智能化智能化工程节能减排监控智能照明

请用一段语句通顺的话来描述您的网站定位,字数不超过200字。

欧艾电气(常州)有限公司是一家专业从事工控领域变频器、软起动器及仪器仪表等电气产品研发、生产及销售于一体的科技型企业,公司提供各种类型变频器产品的解决方案。

通运科技-科技改变命运、科技创新知识、科技最新资讯、科技品牌、科技生活百科

领淘教育是一家专业的淘宝运营培训机构教学平台、提供系统全面的淘宝运营培训全套教程视频课程实战干货、淘宝卖家免费学习网站!

当游网单机游戏下载基地为广大单机游戏玩家提供海量好玩的单机游戏下载、街机游戏、模拟器游戏及补丁工具下载,每日更新玩家喜爱的单机游戏资讯及单机游戏攻略,更多精彩尽在当游网。

宁波法里奥光学科技发展有限公司坐落于风景如画、交通便利、经济发达的海港城市—宁波。是一家集科、工、贸于一体的综合性高新技术企业,主要从事视光学精密光电仪器的研发、生产、和贸易。多年来,凭借软件控制、光学和机械设计领域的专业水平和领先技术,在视光学行业内迅速崛起。

古诗网平台主要整理了经典古诗词原文、诗词翻译、古诗注释及赏析。其中包括中小学古诗大全、各种写景经典诗句、古诗名句、爱情诗句、送别诗词、边塞诗句等经典古诗大全。

南安市喜连天食品有限公司是一家专注于即食燕窝批发,即食燕窝代加工,即食燕窝贴牌,即食燕窝OEM,即食燕窝招商,即食燕窝网店代发,即食燕窝经销代理,即食燕窝加盟批发,即食燕窝生产厂家,集即食燕窝的开发、生产、销售、代理加盟为一体的一条龙供应商。

TCL集团股份有限公司是中国最大、全球性规模经营的消费类电子企业集团之一。TCL旗下有四家上市公司并形成五大产业。TCL创意感动生活

坤泰线缆、电线电缆、橡套软电缆、橡套电缆、电力电缆、绝缘电缆、控制电缆


雷锋网8月7日消息,易捷行云EasyStack宣布完成C,轮融资,融资金额则未公布,本轮融资由京东集团战略投资,不久前的5月15日,易捷行云刚刚宣布完成由多家人民币基金联合投资的3亿元C,轮融资,C,这个轮次怎么看也像是为京东云专门而设的一轮融资,据易捷行云官方消息,C,轮融资由京东云主导,京东集团投资,并没有宣布其他投资者的消...。
苹果ios16听写功能介绍ios16中听写功能的特点是界面更简洁,更容易在语音输入和打字之间切换,以及自动标点符号和支持表情符号的插入,新的听写体验完全由设备上的程序驱动,旨在使用户更容易在语音输入和打字之间切换,与以前版本的iOS不同,听写面板不再取代iOS键盘,在iOS16中,键盘仍然是开放和可见的,让用户在听写过程中根据需要打字...。

对于农村来说,不论种植哪种农作物都需要购买农资产品,在不同的阶段,及时的施肥打药,才能确保农作物更好的生长,在收获的季节获得喜人的收获,现在发展农业的人比较多,对农资产品的需求量自然比较大,因此开家农资连锁店也是不错的创业之选,下面小编先带领大家先来了解一下农资连锁加盟平台排行,倍丰农资是来自黑龙江的农资品牌,成立于2004年,一直深...。
有以下软件可以,1、360安保阅读器,360SecurityBrowser,是360安保核心推出的一款基于IE和Chrome双内核的阅读器,是环球之窗开发者凤凰上班室和360安保核心协作的产品,2、MozillaFirefox中文俗称,火狐,正式缩写为Fx或fx,非正式缩写为MF,,是一个自在及开明源代码的网页阅读器,经常使用Gec...。

△视频截图显示,美国前总统特朗普的竞选集会现场出现枪击事情后,特朗普被特勤局人员护送上前,新华社发暗杀,曾是美国政治生存的一个可悲事实,美国历史上出现过9次总统遇刺事情,其中4位丧生,美国第16任总统亚伯拉罕·林肯是美国第一位遇刺身亡的总统,1864年,林肯在总统连任竞选中获胜,1865年4月14日,林肯参与为庆贺南北抗争胜利的优惠时...。

女人梦见掉头发是什么意思女人梦见掉头发是什么意思,梦中场景有或许出现过也或许没有的,女人梦见掉头发预示着在人际交往方面能够取得很大的完成,预示着你要出门安适身心,如今来看看原版周公解梦女人梦见掉头发是什么意思,女人梦见掉头发是什么意思1周公解梦里的解释,女人梦见掉头发是守寡的兆头,而别的解释还有梦见梦到头发掉了表示头发是性感的意味,头...。

速腾的好处是做工、质量和大气的形状,比拟有体面,1.4T的这款车能源比拟澎湃,驾驭觉得和操控均不错,保有量、保值率和爱护方便性在国际这个级别上鲜有对手,无余的话就是性价比普通,定价稍高,周围的好友德系车比拟多,很多倡导我买新速腾1.4T,谁知道这款车怎样样啊,速腾1.4T搭配的是DSG双离合器变速器,这个变速器可以说是目前民用车中最先...。
去豌豆荚或许拇指玩外面找qq下载,外面会有一个版本的选用,选用2012版就可以了用手机下载了手机QQ2012和微信搜查左近的人不时显示不可失掉位置消息系统设置外面的位置设1、微信定位是基于移动位置服务,LBS,是基于搜查左近基站定位的,须要网络的允许,不能定位或许是左近基站用户过多,网络较差,造成数据加载较慢,不可反常定位,试试经常使...。

撰文丨余晖据海南省纪委监委7月3日信息,三亚市人大常委会党组成员、副主任林有炽涉嫌重大违纪违法,目前正接受海南省纪委监委纪律审查和监察调查,林有炽,男,1965年2月出世,海南三亚人,汉族,省委党校钻研生学历,1985年7月参与上班,1996年8月参与中国共产党,地下资料显示,他常年在海南上班,简历显示,林有炽历任海南省三亚市中央税务...。

进入QQ聊天室的步骤如下,1.关上QQ软件并登录账号,在详细解释之前,须要明白的是,因为QQ聊天室的配置曾经逐渐淡出人们的日经常常使用,因此在较新版本的QQ中或许不再蕴含此配置,但依照历史版本的QQ来说,以下是进入QQ聊天室的步骤,首先,确保曾经装置了QQ软件并登录了自己的账号,QQ是一款宽泛经常使用的即时通信软件,可以经过官网网站、...。

万年日历黄历旧黄历下载、2、万年日历黄历农历安装:旧-万年日历黄历老-0旧黄历万年日历安装1。旧黄历万年日历安装:万年日历黄历如何。1、黄历查询万年历,2022年更好的黄道吉日黄历Query万年Calendar黄历,每日吉凶的历法,是轩辕帝所创,故称黄历。万年Calendar提供最权威、最准确的万年calendar包括万年calendar农历查询、万年calendar农历转阳历、old黄历查询、/Old黄历查询中国农历二十四节气的吉祥、不吉利、禁忌可以帮助2、黄历万年历吉日吉时,万年历黄道吉日不宜行丧是什

提供各类声卡驱动下载如:ac97声卡驱动,万能声卡驱动下载,创新声卡驱动等驱动程序下载。并且可以提供为您寻找声卡驱动服务哦。PC6免费提供声卡驱动,万能声卡驱动,驱动程序下载下载

雷锋网消息,3月16日,科亚医疗正式向港交所递交申请版本招股书,拟在香港主板挂牌上市,独家保荐人为中金公司,至此,经过6年的发展,医学影像AI行业或将正式迎来开花结果,而在2020年获得首张AI三类证的科亚医疗,也将成为首家上市企业代表影像AI征战资本市场,招股书都披露了什么,1、科亚医疗5年融资共10亿元,本次IPO主要用于深脉分数...。

直播预告!2020年全国水上公安机关实战大练兵比武演练精彩来袭!,碧涛谱华章,激流铸警魂!全国12支参赛队集结杭州整装待发!水上最小单元处置违法犯罪、突发大规模人员落水联合救援、打击非法捕捞违法犯罪,精彩科目等你来看!蛟龙出击挥利剑,忠诚为民保平安——28日,周三,上午10点,#乘风破浪的水警#,与你不见不散!中国警方在线的微博视频...。
2月23日下午,陌生人社交平台陌陌宣布100%股权收购同为陌生人交友平台的探探,此次收购包括530万股A类股票外加6.009亿美元现金美元的现金,该交易预计将于2018年第二季度完成,探探一款基于LBS,地理位置服务,的陌生人社交应用,于2014年6月上线,采用,左滑右滑、互相喜欢才能聊天,的核心产品机制,深受年轻女性用户青睐,据悉,...。

编译,王玥近年来,大规模预训练语言模型,PLM,显著提高了各种NLP任务的性能,由BERT和GPT,2开始,自监督预训练范式和监督的微调范式取得了巨大的成功,并刷新了许多自然语言处理领域的最先进成果,如语义相似度、机器阅读理解、常识推理和文本摘要等,此外,这些PLM的规模为中等,即大小低于1B参数,,令模型可以做出广泛且快速的微调与适...。

发表在知麻投影仪2024,3,714,46知麻Z2是知麻投影仪最新发布的投影产品,是知麻Z1系列的升级版本,具体知麻Z2投影仪怎么样呢,下面就来详细了解一下,看看知麻Z2投影仪的参数配置究竟如何,有哪些优缺点,是否可以满足日常家用需求,知麻Z2投影仪怎么样,1.光学参数在亮度方面,知麻Z2的实际亮度达到1010CVIA流明,提供相当明...。
