如何使用 Google AutoAugment 改进图像分类器 的 (如何使用google play)
通过使用优化的数据增强方法,在CIFAR-10、CIFAR-100、SVHN和ImageNet上得到了目前最好的结果。您可以从这里找到和使用它们。
在ImageNet上得到的最好的增强效果,源自:
AutoML——使用机器学习来改进机器学习设计(如体系结构或优化器)的想法——已经来到了数据增强的领域。本文将解释什么是数据增强,谷歌AutoAugment如何搜索最佳增强策略,以及如何将这些策略应用到您自己的图像分类问题。
数据增强意味着在训练机器学习模型时,对输入数据随机的应用各种变换。这种人为地扩大训练数据,可以生成更多可能的输入数据。它还有助于防止过度拟合,因为网络几乎从来不会看到完全相同的两次输入然后仅仅记住它们。典型的图像数据增强技术包括从输入图像中随机裁剪部分,水平翻转,应用仿射变换,如平移、旋转或剪切等。
事实上,正如 AutoAugment 作者所指出的,近年来在ImageNet挑战赛上,人们为寻找更好的网络结构投入了大量的精力,但是数据增强技术,基本上与Krizhevsky等人在2012年为AlexNet设计的方法相同,或者只有一些微小的变化。
选择使用哪些数据增强的通用做法,是首先提出适合对应数据集的不同假设,然后进行试验。你可以从随机剪切、随机调整大小或者水平翻转开始,因为它们几乎总是有效的,并且还可以尝试诸如小尺度的旋转等。由于重复训练带来的验证集性能的随机波动,很难确定这些增加的旋转是否提高了模型性能,因为您可以从两次不同的训练中获得随机的改进,而这些改进并不是因为使用了数据增强。
通常来说,由于我们实验的高度不确定性,并且也没有时间或资源来严格测试所有的可能组合,所以我们放弃了搜索最好的方法,或者坚持使用某些固定的增强策略,而不知道它们是否有很大的贡献。但是,如果有一种可以迁移有用数据的增强技术,就像我们在迁移学习中从预先训练的模型中迁移参数一样,那会怎样呢?
从数据中学习增强策略
AutoAugment的思想是在强化学习(RL)的帮助下学习给定数据集的最佳增强策略。由于在图片上应用和组合转换的方法非常多,所以它们对可选择的方法增加了一些限制。一个主要策略由5个子策略组成,每个子策略依次应用2个图像操作,每个图像操作都有两个参数:应用它的概率和操作的幅值(70%的概率执行旋转30度的操作)
这种策略在训练时是如何应用在图片上的呢?对于我们当前批次的每张图片,首先随机均匀地选择一个子策略,然后应用该子策略。让我们来看一个包含5个子策略的示例,这些子策略应用于SVHN数据集中的图片:
对SVHN图像应用一些最佳增强的例子。源自:
子策略1在x的方向上,以90%的概率执行力度为7的剪裁。然后,有20%的概率,对图像的颜色进行翻转。子策略4以90%的概率对图像进行颜色反转,然后在10次中有6次进行颜色直方图均衡化。操作的次数是固定的,但是由于子策略的随机性和操作存在的概率,对于单个图像也可能有很多的增强结果。
让我们看看AutoAugment RL模型的搜索空间。他们考虑了16种操作:14种来自Python图像库PIL,比如旋转、颜色反转和一些不太知名的操作,比如色调分离(减少像素位)和过度曝光(将颜色反转到某个阈值以上),再加上裁剪和采样(类似于Mixup)这些数据增强领域的新方法。增加11个离散概率值(0.0,0.1,…,1)和从0到9共10个等间距的幅值,这相当于对某一个子策略有(16 * 11 * 10)²种可能性,如果同时有五个子策略,则共有(16 * 11 * 10)¹⁰≈2.9 * 10³²种可能 。需要强化学习来帮忙了!
AutoAugment像NASNet一样训练——一个源自Google的用于搜索最优图像分类模型结构的增强学习方法。它的训练方法如下:我们有一个控制器,它决定当前哪个增强策略看起来最好,并通过在特定数据集的一个子集上运行子实验来测试该策略的泛化能力。在子实验完成后,采用策略梯度法(Proximal policy Optimization algorithm, PPO),以验证集的准确度作为更新信号对控制器进行更新。解释PPO超出了本文的范围,但是我们可以更详细地看看控制器和子模型实验。
控制器以Softmax输出要应用于哪个操作决策。然后,该决策作为输入传递到控制器的下一步,这是因为控制器是一个RNN(对于NASNet,使用了一个包含100个隐藏单元的LSTM)。然后控制器决定应用哪个幅值的操作。第三步是选择概率。因此,控制器拥有所有其他操作的上下文、早期的概率和幅值,以便做出最佳的下一个选择。(这是一个说明性的例子,因为这篇论文目前并没有告诉我们选择操作、大小和概率的顺序)。
总共有30个softmax预测值,因为有5个子策略,每个子策略需要在两个操作、大小和概率(5 * 2 * 3 = 30)中做出两个选择。
我们如何告诉控制器哪些策略选择得好,哪些没有真正提高性能(例如将亮度设为零)?为此,我们使用当前增强策略在子神经网络上进行泛化实验。实验结束后,对RNN控制器的权值进行更新,以验证集的准确度作为更新信号。当最后将整体最佳的5个策略(每个策略包含5个子策略)合并到最终策略(现在包含25个子策略)中时,共将执行15,000次迭代。最后的这个策略是用于该数据集所有数据的策略。
正如副标题已经给出的那样,AutoAugment提升了CIFAR-10、CIFAR-100、SVHN、ImageNet等数据集上的最优结果。此外,还有一些特别有趣的细节:
CIFAR-10测试集上的错误率,越低越好,源自:
ImageNet验证集上Top-1/Top-5的错误率,越低越好,源自:
FGVC测试集上Top-1错误率(%)。Inception v4是从零开始训练,没有应用最佳ImageNet增强策略。源自:
如果我们想要解决图像分类问题,通常使用来自ImageNet预训练的权重初始化模型,然后对这些权重进行微调。我们刚刚看到,使用AutoAugment的最佳ImageNet策略,同时从零开始训练,也有类似的正效果。如果我们同时使用这两种方法:在使用ImageNet AutoAugment 策略时微调ImageNet的权重?这些优化的效果会叠加起来,为我们解决新的图像分类问题提供新的最佳方法吗?
为了回答这个问题,我使用了相同的5个FGVC数据集(Oxford 102 Flowers, Caltech-101, Oxford- iiit Pets, FGVC Aircraft和Stanford Cars),对Inception v4进行微调,使用或不使用来自AutoAugment的ImageNet策略。
对FGVC测试集上5次Top-1错误率结果进行平均。Inception v4通过对ImageNet权重进行微调,使用和不使用AutoAugment ImageNet策略。有趣的是,在5个数据集中,只有3个数据集的微调结果比从上面AutoAugment论文中从零开始训练的结果更好。正如在“Do Better ImageNet Models Transfer Better”中讨论的那样,微调似乎不会在所有情况下都提升模型性能。
将最佳的ImageNet增强策略应用于不同的数据集,可以将5个数据集中的3个的错误率平均降低18.7%。在另外两个数据集上,错误率平均增加了5.3%。
这些结果表明,当需要对ImageNet权重进行微调时,应该尝试额外应用ImageNet AutoAugment策略。通常情况下,基本上都可以额外获得显著的改进。
如何将AutoAugment策略应用于您的问题
我在本文附录中创建了一个包含最佳ImageNet、CIFAR-10和SVHN策略的repo。一些实现细节还不明确,但我正在与作者联系,一旦我知道更多细节,我将会在这个repo里及时更新。
将ImageNet策略的随机子策略通过PIL应用搭配图像上,可以如下:
要将它应用到PyTorch,您可以这样做:
AutoML再次展现:对于给定数据集,最好的数据增强操作是可学习的,甚至可以迁移到类似的数据集中。这只是许多可能的自动优化数据增强方法中的一个。提高学习此类策略的效率是另一种令人兴奋的方法,目的是使任何人都能够使用这些技术(无需使用GPU服务器群)。ENAS表明这是可行的。
把这个新方法应用到你自己的问题上吧,祝你好运!如有错误和疑问,请发邮件至philip@popien.net联系我。
想要继续查看该篇文章相关链接和参考文献?
如何使用 Google 的 AutoAugment 改进图像分类器 】
今日博客推荐: ICML 2019 | 神经网络的可解释性,从经验主义到数学建模
本来想把题目取为「从炼丹到化学」,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,将基于经验主义的调参式深度学习,逐渐过渡为基于一些评测指标定量指导的深度学习,是新一代人工智能需要面对的课题,也是在当前深度学习浑浑噩噩的大背景中的一些新的希望。
原创文章,未经授权禁止转载。详情见 转载须知 。



百度搜索面向合作伙伴的官方平台,为开发者、内容创作者、站点管理者等伙伴,提供优化工具、数据、课程、Q&A等服务,助力资源进入搜索,同时提供搜索项目合作机会,让优质资源脱颖而出。

香港高防VPS-菠萝云为您提供高防CDN,CC攻击防御,DDOS攻击防御,云防护服务,特价高防主机,高防cdn领域有着专业技术服务

这里有所有篇,然妞长胖胖的菜谱和视频,以及所有的故事

工业铝型材生产厂家_铝型材框架加工定制_铝型材踏步平台_上海昶申铝业有限公司_流水线流水线_车间工作台_安全围栏防护制作_工业铝型材框架铝型材_工业铝型材_铝合金型材_铝型材加工_铝型材厂家_铝型材规格_铝型材价格_铝型材报价_铝型材框架_流水线铝型材_支架铝型材_铝合金型材价格_铝型材生产厂家_上海铝型材_铝型材批发_铝材_工业铝材_型材_铝型材开模_异型材_铝型材定做_倍速链型材_角铝型材_铝型材工作台_铝型材围栏_机架铝型材_阳光房铝型材

上海活动拍摄公司电话18964565950,专业提供活动拍摄、照片视频直播、现场摄制、摇臂导播台租赁、拍照、摄影、会议摄像、跟拍、云摄影、集体照、图片视频直播,上海高清切换台导播推流、照片直播、摄影摄像剪辑等服务。

绿康胶粘剂有限公司主要从事自喷万能胶、环保喷胶、水性喷胶、热熔胶、聚氨酯发泡胶、装饰万能胶、免钉胶、结构胶、耐候胶、白乳胶、拼板胶、密封胶等系列胶粘剂的生产与销售,日生产能力达到80吨,是中国规模最大、技术最领先、设备最先进的环保胶粘剂生产企业之一。专业免钉胶厂家、密封胶厂家为您提供服务支持。

么塔网是一个有品位的体育知识分享网站!

砼商网(混凝土机械网)打造专业的混凝土机械平台,积聚混凝土企业和混凝土设备,拥有着混凝土搅拌站,混凝土泵车,搅拌车混凝土搅拌机等混凝土设备机械及配件,提供混凝土设备选购,配件,二手混凝土设备,展会,招标五大平台,并提供及时,权威的混凝土设备资讯,买卖混凝土就上混凝土机械网

红薯藤为句子迷们提供最精品的说说!提供新的微信朋友圈心情说说大全,包括伤感说说、个性说说、经典句子、搞笑说说、爱情说说等励志句子及电影电视剧经典台词大全。

无锡市予坤净化设备有限公司为您提供净化工程、无尘车间、洁净室〈洁净级别为百级至三十万级〉,是一家专业从事净化工程施工安装企业,是从事空调净化技术和产品的开发、生产及工程安装的专业厂商,各类资质证书齐全,技术力量雄厚,工程装备精良,检测设备完善。

511340安卓网提供安卓游戏排行榜前十名,海量安卓游戏下载,最好玩的安卓游戏推荐等内容。找好玩的安卓游戏就上511340手机游戏网。

桐乡市洲泉欧兰格家居有限公司是一个融自主产品设计、风格创意、生产制造、销售服务于一体的明星家具品牌,家具加盟,家具厂家,每一件欧兰格的产品风格优雅而不失个性,创意不失实用,以追求手工精细得裁切雕刻。


2024年想要提升客流量,想要获取源源不断的客户,就一定要懂得做裂变,很多人不懂怎么做流量,怎么做裂变,给你分享一个系统的方法,1.导流量通过诱饵,渠道的方式导流,1,诱饵设计能够吸引客户并且能够带来客户的诱饵,诱饵一定要具备以下几点,①低成本但是这个成本也是相对来讲的,低成本肯定是成本越低越好,还有就是看投入产出比,投入产出越高,...。

多年来,微软都在运行一个名为TechNet的网站,IT专业人士可通过其下载有关微软产品的技术资料,进而帮助微软发现和解决问题,可是周三,安全公司FireEye爆料称,黑客正以一种巧妙的方式渗透入TechNet,并在其上运行他们的非法网络,或称僵尸网络,微软CEO纳德拉这些黑客没有直接针对TechNet的安全措施发动攻击,相反,他们在...。

在前不久的小米新品发布会上,雷军在发布小米8SE时称,手机屏幕之所以越做越大,一方面是基于用户需求,另一方面是手机里面越来越复杂,做大手机相对难度小,但这就产生了一个问题,喜欢小屏用户在手机市场上的选择越来越少,引领市场的苹果,在2016年春季发布会上发布了经典的小屏手机iPhoneSE,在当时颇受好评,伴随着一年一度的苹果WWDC进...。

雷锋网消息,据外媒报道,近日,器械巨头GE医疗宣布,董事会决定任命原英特格拉生命科学CEOPeterJ.Arduini成为新一届CEO,最终任命将从今年年底执行,目前还在交接阶段,并由一个特别委员会来指导和过渡过程,在此之前,上一任首席执行官KieranMurphy已提交辞职申请,卸任之后将继续担任公司顾问,KieranMurphy的...。

服装连锁加盟店,就是该企业组织,将该服务标章授权给加盟主,让加盟主可以用加盟总部的形象、品牌、声誉等,在商业的消费市场上,招揽消费者前往消费,而且加盟主在创业之前,加盟总部也会先将本身的经验,教授给加盟主并且协助创业与经营,双方都必须签订加盟合约,以达到事业之获利为共同的合作目标;而加盟总部则可因不同的加盟性质而向加盟主收取加盟金、保...。

全球治理的中国方案的总体目标构建人类命运共同体,人类命运共同体,aCommunitywithaSharedFutureforMankind,,旨在追求本国利益时兼顾他国合理关切,在谋求本国发展中促进各国共同发展,人类只有一个地球,各国共处一个世界,要倡导,人类命运共同体,意识,人类命运共同体这一全球价值观包含相互依存的国际权力观、共同...。

时政新闻眼丨“中非时间”开启习近平同多国元首宣布双边关系新定位,习近平,时政新闻眼,中非,习主席,中非关系
您是要问360阅读器的运行商店在哪下载吗,依据查问360官方显示,1、关上360阅读器,搜查360官方,2、进入360官方首页,找到官方下载页面,3、找到运行商店,点击安保下载即可,手机运行商店哪家的好,要说以后哪款手机运行市场软件最多,团体觉得以下几款运行商店都挺不错的,1、360手机助手360官方出品手机运行市场,中国最大的And...。

陆丰汽车的汽油发起机驳回三菱技术,柴油发起机驳回50铃技术,重要包含1.5升涡轮增压发起机和2.0升涡轮增压发起机,对于陆风,陆风汽车成立于2002年12月,是江铃控股汽车有限公司旗下的品牌,截止到2019年9月,市面上在售的陆风汽车包含陆风x2、陆风x5、陆风x7、陆风x八、陆风逍遥,以陆风x例如,它有1.5升涡轮增压发起机和2.0...。

玛莎拉蒂Ghibli是一款十分不错的车型,它在外观和内饰方面都有很大的优化,假设你正在寻觅一款奢侈轿车,那么这款车相对值得思考,首先,让咱们来看看这款车的外观,2019款的Ghibli驳回了与Levante和总载家族相似的设计,前脸看起来十分具备攻打性,同时,尾部的外型也十分粗劣,间断了现款尾灯的外型设计,而且驳回了双边共四出式排气规...。

木马专家2021是功能强大的木马病毒查杀工具。专门用来拦截系统病毒、木马信息,可以实时监控木马数据,自动拦截查杀。让电脑操作环境更加干净、流畅。这个软件功能还是比较给力的,欢迎用户来绿色资源网下载体验。木马专家官方介绍木马专家是一款木马查杀软件,软件

java学习方法有哪些? 1、第一步:安装JDK在开始学习的过程中,进行安装是零基础学生需要掌握的重要步骤,在进行软件开发的过程中,首先需要进行软件安装。JDK是进行安装的第一步,很多人可能对JDK的了解不是很多,可能会在第一步被JDK安装

小编发现现在的玩家找游戏,根据的不是游戏的类型,而是更具体到以里面的一种游戏名称为选择的基准,所以今天小编要介绍的是这就是江湖类似的游戏,喜欢这类游戏的玩家,可以跟着小编来看看,没听说过这个游戏的玩家,也不要着急,这款游戏是一款以江湖为背景的rpg手游,玩家在游戏内有充分的自由度,可以自由探索,还有剧情作为辅助,小编要介绍的游戏也是根...。
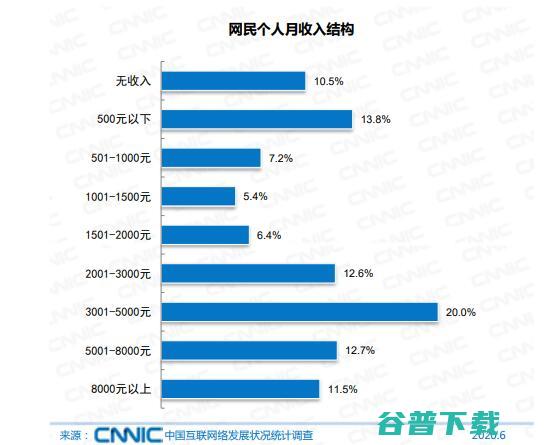
CNNIC发布,第46次中国互联网络发展状况统计报告,数据,截止2020年6月我国网民飙到9.4亿,月收入在5000元以上的网民群体占比不到1,4,约2成网民月收入在1000元及以下,看来靠网络创业赚大钱的还是少数哇,了解到,根据CNNIC发布的这次网民数据得知,截止到6月份,国内的网民已经飙升到大约9.4亿,互联网普及率达67.0%...。

雷锋网AI金融评论4月19日消息,光大银行日前宣布,将投入5亿元用于年度金融科技创新项目孵化,通过支持新产品、新模式、新市场的开拓创新,营造全行支持创新、鼓励创新的体制机制和文化氛围,助力实现打造一流财富管理银行的战略目标,此前在2019年度业绩发布会上,光大银行曾宣布,2020年科技投入占营业收入的比重将提高到3%以上、全行科技人员...。

发表在当贝投影仪2020,5,1411,35当贝F3,今年智能投影产品里发布的第一款主打的旗舰机,必须要来好好掰一掰了,先来介绍一下当贝F3,F3目前智能投影仪的顶配产品,拥有4,64GB的内存,Mstar6A938VP芯片,配置没有毛病可挑;硬件上,2050ANSI流明的亮度,8001,10000,1的对比度,支持全自动的梯形校正和...。
用什么软件制造鸽子图片这个要看你的技术怎样样了,要是有这方面的技术那就是pohotoshop了,这个软件能使你轻易的加工图片,不过有点复杂,要是偶然的做个图片还不想学习pohotoshop那么你就用光影魔术手了这个软件便捷而且经常使用便捷立马奏成果,不过我倡导你两者接合经常使用那样两个方面都能不充无余,手机上能用的ps软件有哪些,1、...。
