为AI颠覆GPU!计算机史上迎来第三个革命性架构IPU
被誉为英国半导体之父,也是Arm联合创始人的Hermann Hauser曾经这样说:“在计算机历史上只发生过三次革命,第一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。” 他所指的正是Graphcore率先提出的就是为AI计算而生的ipu(Intelligence Processing Unit)。

内存墙是阻碍AI芯片性能提升的关键,因此计算架构的创新变得更加重要,不过这其中大部分的架构创新都是在已有的架构基础上。 Graphcore联合创始人兼CEO Nigel Toon在ASPENCORE主办的2019 CEO峰会期间接受雷锋网采访时表示,Graphcore开创了全新的处理器类型IPU,IPU是专为机器智能设计的处理器,能够满足人们对高效易于使用的处理器的需求。

左:Graphcore销售副总裁/中国区总经理卢涛,右:Graphcore联合创始人兼CEO Nigel Toon
左右逢源的英国AI独角兽
Graphcore在风险资本的支持下于2016年在英国成立,成立三年时间,就获得了3.25亿美元的融资,去年估值就达到了17亿美元,其中的投资者既有像红杉资本这样的金融投资者,也有像戴尔、三星、微软等的战略投资者。
除了资本的认可,Graphcore还获得了多位AI领域的知名学术投资人为其背书,比如DeepMind 的联合创始人 Demis Hassabis、剑桥大学的 Zoubin Ghahramani 和 Uber 的首席科学家、加州大学伯克利的 Pieter Abbeel 以及 OpenAI 的 Greg Brockman、Scott Grey 和 Ilya Sutskever等。
被称为AI教父Geoff Hinton就曾说,“我认为我们需要转向不同类型的计算机。幸运的是,我这里有一个。”Hinton伸手进入他的钱包,拿出一个又大又亮的硅片,这个硅片就是Graphcore的IPU。

创立这家获得学界和资本都认可的两位创始人是Nigel Toon和Simon Knowles,Graohcore也是他们的第二次创业。 2002年,Toon和Knowles(现任Graphcore CTO)在英国Bristol共同创办了Icera,致力于打造3G modem芯片,2011年被英伟达以3.7亿美元的价格收购。
在Icera被收购之后不久,Nigel Toon和Simon Knowles就在思考再次进行创业,基于两位创始人的经验以及对未来的判断,在2016年创立了了Graphcore。如今,Graphcore在伦敦、剑桥、台湾、北京、Palo Alto、Oslo都设有办公室,员工人数将在今年底达到400人,IPU也已经于去年底推出。
那么,IPU为何能受到如此多的关注和期待?
Nigel认为,AI有三类芯片,第一类是简单的小型化加速器,用于手机、传感器等;第二类是ASIC,比如谷歌的TPU;第三类是可编程处理器,目前市场上只有GPU,Graphcore的IPU属于这个分类,但又有所不同,因为 IPU是一个非常灵活的处理器,从零开始,是专门针对AI设计的处理器架构,在未来很多新的AI应用中,IPU也会表现的更好。
之所以要推出IPU,是因为Nigel看到,如果只是针对基本的前馈卷积神经网络,GPU是一个非常好的解决方案,但随着网络变得越来越复杂,人们需要一个新的解决方案,ASIC和FPGA的采用就已经证明了GPU的弱点。
“我们接触过的所有创新者都说使用GPU正在阻碍他们创新。如果仔细看一下他们正在研究的模型类型,你会发现他们主要研究卷积神经网络,递归神经网络和其他类型的结构,例如强化学习,并不能很好地映射到GPU。这也正是我们将IPU推向市场的主要原因。”
Nigel指出,IPU是我们开创的一个全新的处理器类型,专为AI设计,IPU强大的并行处理能力实现了快速训练模型并进行实时操控。 其实现在有一些国外公司也在说他们的产品叫IPU,但我们首创的这个叫法,而且技术产品跟我们相比还差很多。
那IPU架构到底独特在哪里?Graphcore销售副总裁/中国区总经理卢涛对雷锋网表示 , Graphcore的IPU里面有1216个核,我们称之为Tile,每个Tile里都有计算单元和内存。 由于同时有上千个处理器工作,所以单个IPU的存储带宽能达到45TB,比性能最快的HBM提升了50倍以上,在相同算力下,功耗也降低了一半。

根据Graphcore的说法,IPU处理器是迄今为止最复杂的处理器芯片,基于16纳米的工艺集成了240亿个晶体管,每个芯片提供125 teraFLOPS运算能力。 借助IPU,一个完整的机器学习模型可以在处理器内部处理。而且IPU处理器具有数百兆字节的RAM,可在处理器上以1.6 GHz的速率全速运行。
但是, 提高带宽的同时,如何解决数据的通信以及提升数据的使用效率就是非常关键的问题,也是关键挑战。 卢涛表示, IPU内部里有一个叫all-to-all总线,这个互联总线,可以高速实现任意一个核到另外一个核的直接访问。涉及到跨多个芯片的时,通过IPU-Link就可以把多个IPU联结在一起,组成一个集群。当然,all-to-all总线中间的BSP(Bulk Synchronous Parallel)协议,不仅用于同一个芯片的不同核之间,而且跨芯片的核之间也可以通过该协议透过 IPU-Link 总线进行通信。
IPU-Link最多可以支持128个芯片的互联,如果要进行更大规模的训练,可以通过以太网或者Infiniband进行互联,另外针对超大规模AI 训练应用,Graphcore还开发了专门的IPU-POD。IPU-POD 是由 IPU-machine 组成的 POD,每个 IPU-machine 上集成的IPU-Gateway芯片里有一个叫做IPUoF的技术,能够把几千甚至几万颗的 IPU 处理器连在一起。
解决了数据通信的问题,还有数据的效率问题。IPU没有采用传统处理器架构中保证多个处理器数据一致性的Cache协议,而是通过BSP配合Poplar软件栈的方式来提升效率 。Nigel Toon表示,很多人都部署了BSP,但只是用在主机之间,也就是大规模的并行机制,我们在芯片上实现了BSP,同时配合Poplar的软件栈工具/编译器,它会把算法模型、数据处理之后,映射或者分配到处理器的不同位置,并定义好交换和同步的时间等,不仅更易于使用,而且具有足够的灵活性。
这样即使对于算法公司而言,虽然处理器有1000多个核,7000多个线程,但是不需要太担心通信的问题,能够让算法工程师非常方便地用。
Nigel Toon总结表示, IPU与其它的AI芯片相比,有三个比较核心的区别:
第一,处理器核的架构不同,IPU是MIMD的架构。
第二,IPU的模型在处理器内。
第三,大规模并行,IPU核之间的通信效率也非常高,这非常难,Graphcore进行了大量的创新。

相同的IPU硬件就可用于推理和训练
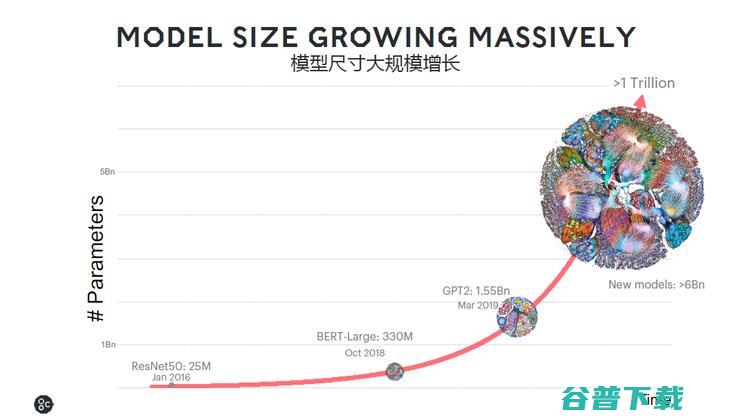
对于芯片公司而言,设计出独特的芯片并不是最难的,更难的是获得客户的认可和采用。 Nigel Toon表示,未来几年Graphcore都会专注在算力比较密集的场景,而不会做终端的应用。 IPU也更能够适应未来整个行业的变化非常快,模型的大小每3.5个月就会增长一倍。并且,模型参数增加一倍,但最后还是要拆成不同的尺寸,算力需求的增长将不止两倍,所以未来的算力需求将会呈现指数型的增长。
卢涛补充表示,现在AI做的主要是图片的目标识别,自然语言处理对算力的要求更高,未来视频的分析需要更高的算力,如何把AI应用到AR、VR都对算力提出了巨大的要求。
需要指出的是,使用相同的IPU就能进行AI训练和推理。在大家普遍的认知中,推理和训练对于算力有着巨大的需求,不 过Nigel Toon认为,训练和推理技术上本质上没有很大区别,先通过数据训练出模型,部署的时候实际上是通过推理是把模型拿出来。 在未来的应用里,部署的场景可能是推理,同时还要不停地训练和更新这个模型。

“从架构的角度,这对我们非常重要,因为随着机器学习演进,系统将能够从经验中学习。推理性能表现的关键包括低延迟、能使用小模型、小批次,以及可能会尝试导入稀疏性的训练模型;IPU可以有效地完成所有这些事情。”
据介绍, 在一个4U机箱中,16颗IPU共同合作协作进行训练,每颗IPU可以执行独立的推论任务,并由一个CPU上执行的虚拟机来控制,最终得到一个可用于训练的硬件。一旦模型被训练、布署,随着模型演进且想要从经验中学习时,就可以采用相同的硬件。
卢涛进一步指出,由于IPU架构的特性,模型部署的时候精度和训练的结果会保持一致,另外在 IPU 里面要做的计算跟要处理的处理都是在本地,以及 IPU 这种超大规模小型向量机的架构,使得IPU做稀疏化应用场景的时候,天生性能就会更好。 所以IPU既可以用于云服务器,在边缘端,IPU也非常擅长,自动驾驶就会是我们很重要的应用场景。
但还有一个关键问题, 拥有如此多核心和片内存储的IPU是否会成本高昂?Nigel Toon表示不一定,因为客户都会关注效能,如果 IPU的架构在实际应用场景实现几倍甚至几十倍的性能优势时,实际的总体拥有成本还是大幅降低。
有意思的是,在技术创新的同时,Graphcore也进行了商业模式的创新。 Nigel Toon表示,我们目前没有采用传统芯片销售的模式,我们更多的是通过合作,有两大类公司会是我们的合作伙伴,一类是服务器公司, 目前我们已经与戴尔易安信合作推出了IPU服务器,和中国的服务器厂商合作进展也很快,估计很快就会有搭载我们IPU的服务器上市。
另外一类是云服务提供商, 在新的时代,IT产品交付给最终的用户,云服务厂商非常重要。我们会和中国、美国的公司都进行合作,但具体的合作暂时还处于保密阶段。
最近,Graphcore宣布与微软的具体合作内容,并正式发布Microsoft Azure上Graphcore智能处理单元(IPU)的预览版,这是公有云领导供应商首次提供GrapchoreIPU。目前,Azure上的Graphcore IPU预览版现已开放供用户注册,专注于突破NLP界限并在机器智能方面取得新突破的开发者可获得优先访问权限。
对于中国市场,Nigel Toon表示中国是Graphcore非常重要的策略性市场,Graphcore的中国公司不仅会有销售和市场,还会注重工程技术方面的投入,会有很多定制化的开发工作,更好地与本地的社区、创新者一起用好IPU。
AI芯片要满足快速迭代的AI算法,算力的提升非常关键,但摩尔定律的放缓,让架构的创新变得更加重要,实际的情况是大部分创新都是基于已有的架构,Graphcore表示其IPU架构进行了更全面的创新,我们可看到其获得了资本和学术界的好评。当然,除了硬件架构的创新之外,软件工具链Poplar同样非常关键,这是IPU提升灵活性,降低算法开发者的应用门槛的核心,也是能比其它IPU性能更好的关键所在。
因此,AI的时代架构创新很重要,软硬件的协同更加重要。
原创文章,未经授权禁止转载。详情见 转载须知 。


ProcessOn是一款专业在线作图工具和知识分享社区,提供AI生成思维导图流程图。支持思维导图、流程图、组织结构图、网络拓扑图、鱼骨图、UML图等多种图形,同时可实现人与人之间的实时协作和共享,提升团队工作效率。

百度爱采购是百度旗下的B2B垂直搜索引擎,旨在帮助用户一站直达全网商品信息,触达海量优质商家。让买家快速便捷的找到优质货源,为商家提供海量匹配的询价信息,获得更多曝光,快速达成交易,降低成本提升盈利。百度爱采购,让采购批发变得更简单。

广州市克鲁兹电子科技有限公司主要是以研发、个性定制、设计、生产销售一体的音视频设备服务企业。

宁德时代新能源科技股份有限公司是全球领先的新能源创新科技公司,致力于为全球新能源应用提供一流解决方案和服务。

智能报修系统是专业的售后服务管理系统,针对家用电器和家用电器行业的售后服务管理,电脑和手机微信同步使用,实现微信报修、工单派工、定位签到、评价、到期预警、项目管理、备件管理等功能,关注“易报修系统”公众号免费试用,专注定制各种售后服务管理系统。

一个95后青年的个人博客,从事于成套电器行业,偶尔分享电器设备知识、电工技术文章的博客。

丁香通是丁香园旗下专业的生物医药科研线上采购平台,拥有试剂抗体、实验仪器、ELISA试剂盒、医疗设备、辅料原料等各类产品供求、价格/报价等信息近6000万条,4万多家品牌供应商入驻,致力为医药企业和生物医药相关行业人士提供优质的采购渠道和服务。

湖南麓明暖通专业做长沙中央空调,湖南中央空调,家用中央空调系统,家用中央新风系统,湖南电地暖,长沙暖气片等产品,是一家从事美的中央空调、美的家用空调等“美的”品牌产品的销售及相关服务的贸易型企业。

湖南志诚光辉石材有限公司提供:湖南石雕牌坊,湖南石雕栏杆,湖南石亭长廊,湖南浮雕壁画,石雕栏杆厂家电话:13575048633

624手游不但免费为玩家提供好玩的手机游戏下载,而且提供电脑手游等手游模拟器,筛选市面上热门的手游进行排行,定期还有手游活动,提供最全面的手机游戏礼包领取,打造温馨的手游平台,624手游一个专门提供优质手游的乐园!

欧艾电气(常州)有限公司是一家专业从事工控领域变频器、软起动器及仪器仪表等电气产品研发、生产及销售于一体的科技型企业,公司提供各种类型变频器产品的解决方案。

智者(ZHIZHE.COM)是发掘金融财经,产经资讯及科技创新相关板块,包含金融,财经,科技,创新,产经,银行,理财,人工智能,保险,投资,融资等价值观点,干货信息的汇聚平台。智者使得您在未来的创造中充满信心。


随着年龄的不断增长,女性的脸上便会出现各种色斑,皮肤也会越来越松弛,细纹也会越来越明显,近,就有不少人都在向小编咨询女人为什么衰老得快,想要青春美丽,办法有哪些,今天,小编就来为大家讲解一下吧!女人为什么衰老得快,伦敦英国学会学报指出,女性魅力源自雌激素,那么,雌激素是什么呢,没有雌激素,女人真的会变老变丑吗,雌激素,是一类女性荷尔蒙...。

人们在日常生活的过程中,由于饮食、作息、气候文化等方面的原因,可能会出现身体不舒服的情况,大家大多选择到附近的药店购买药品解决身体的问题,可以省去排队挂号的时间,同时还可以节省一定的时间和费用,因此推动了我国医药行业的发展,随着亚健康人员逐渐地增多,医药行业发展的越来越好,不少人想要加入其中,那么,医药连锁店加盟品牌店有哪些,震元医药...。
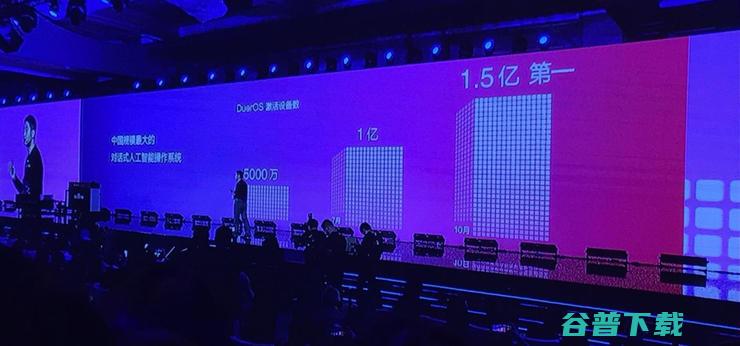
11月1日,在2018百度世界大会上,百度更新了其智能音箱,并推出小度语音车载支架产品,在主论坛上,百度智能生活事业群组,SLG,总经理景鲲首先就DuerOS的市场表现进行了总结,截至2018年10月,搭载百度DuerOS设备的激活量已超过1.5亿,月活跃设备量超过3500万,合作伙伴超过300家,搭载DuerOS的落地主控设备达到1...。

编辑,陈彩娴在今年的SIGGRAPH上,英伟达大显身手!近日,在非盈利国际化会员组织ACMSIGGRAPH举办的SIGGRAPH2021线上会议中,英伟达展示了NVIDIARTX技术能为3D开发者和行业爱好者带来的独家优势,当地时间8月10日,NVIDIA宣布推出Omniverse——它是全球首个为元宇宙建立的基础模拟平台,它可以让用...。

受到社会压力的波及,再来就是人们体内的惰性,快餐行业已经发展的炉火纯青了,而且还有饿了么,美团等行业的映衬,所以快餐已经成为了一个必不可少的行业,而且这个市场前景非常的好,加盟起来也非常的方便,所以进来的商家确实是不少,首先出名的一个就是肯德基,麦当劳,现在这些快餐的发展已经可以到24小时营业了,给深夜工作的人们一个方便,当然除了这些...。

发表在专业问答2023,5,3109,49展示机型信息,品牌型号,哈趣H2、哈曼卡顿AuraStudio3系统版本,当贝OS定制版、DOS系统哈趣H2连接音响可以通过有线或者蓝牙连接,有线连接可以通过HDMI线或音频线连接,下面为哈趣H2怎么连接音响的操作方法做具体说明,哈趣H2怎么连接音响方法一,蓝牙连接1.进行蓝牙配对按下蓝牙音响...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为地图广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在地图广告联盟网站首页底部或友情链接位...。

据央视资讯8月30日报道,中国海警局资讯发言人甘羽示意,8月28日,菲律宾1架H,145型直升机向合法滞留中国仙宾礁的菲海警9701号船空投物资,中方全程跟监、依规处理,菲方冒险行径,极易形成海空不测事情,近期,菲方屡次希图经过海警船、公务船、渔船等,对9701号船实施运补均遭失败,菲9701号船可以机动、自行撤退,关系疑问即能迎刃而...。

家用吸氧机多少钱是依据经常使用者须要那种机型来定价的,经过网上的报价咱们可以看见一升机的多少钱是在1400,1600元之间的,二升机的话要相对的贵一点多少钱是在1700,1900元之间的,三升机或许是更大的机器关键是针对的医疗经常使用的多少钱方面也是定价在3000元以上的,所以关于家用吸氧机来说不仅管多少钱的起因,更关键的是从经常使用...。

随着国度环保政策的推动,越来越多的人开局选用环保型的汽车,而比亚迪电动汽车因为其高性价比和杰出的性能,成为了泛滥生产者的首选,那么,比亚迪电动汽车究竟多少钱呢,上方咱们就为大家详细引见一下比亚迪电动汽车多少钱方面的内容,1.比亚迪e1作为比亚迪最廉价的电动汽车,e1定价大概为8万元,领有200km左右的续航里程,可以满足日常通勤的需求...。

NVIDIAGeForceRTX3090Ti驱动是一款针对该同型号显卡所推出的驱动安装应用。通过安装该驱动,能帮助设置显卡的各项参数

C语言或者c++不定长数组输入,哪位好心人教教我谢谢了... 1、长度不定,不好处理。你只能先定义一个“巨长”的数组了。2、字符数组的定义,引用和初始化:C语言中没有字符串类型,字符串是存放在字符型数组中的。字符数组综合举例。输出一个菱形。
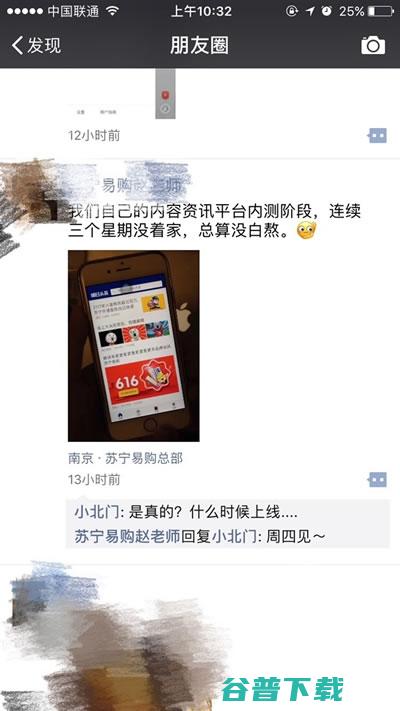
提到新闻资讯APP,很多人对今日头条并不陌生,2012年3月创建以来,4年间激活用户数超过6亿,日活跃用户数超过6600万,单用户日均使用时长超过76分钟,日均启动次数约9次,而近日,一款名为,明日头条,的APP也浮出水面,由苏宁易购研发,一个ID为,苏宁易购赵老师,的网友在微信朋友圈爆料称,,我们自己的内容资讯平台内测阶段,连续三个...。

三年深耕,雷锋网AI掘金志有幸重新定义了安防报道形态,并打造了中国最具影响力的,AI,安防,行业峰会,2018年3月,深圳,雷锋网AI掘金志举办中国首个以,动态人脸与车辆识别,点击查看内容详情,为主题的AI安防峰会,这是业内第一次将五大安防企业,海大宇天网,及商汤等AI独角兽的首席技术高管,聚于一堂的行业盛会,峰会之上,CCF前理事...。
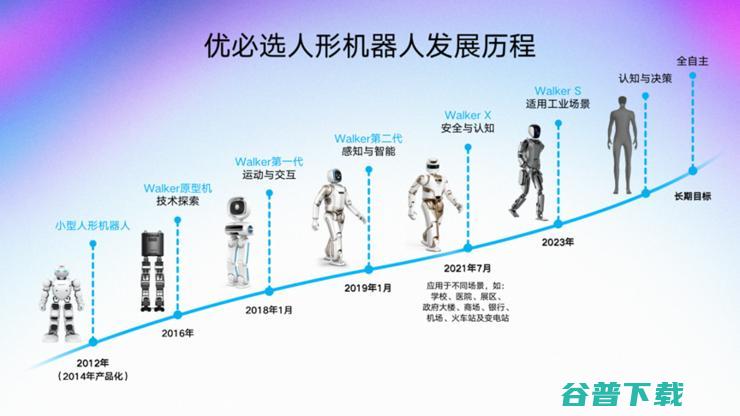
1967年,日本早稻田大学的加藤实验室正式启动WABOT项目,五年后,名为WABOT,1的机器人走出实验室,世界上第一个全尺寸人形智能机器人诞生,虽然WABOT,1行走一步需要45秒,步伐也只有10公分左右,但这项技术,在当时仍震惊了全世界,时至今日,人形机器人技术几经迭代,呈现出三个明显的发展阶段,缓慢静态行走、连续动态行走、高动态...。

5月11,14日,中国图象图形大会,CCIG2023,在苏州隆重召开,本次大会由中国科学技术协会指导,中国图象图形学学会主办,苏州科技大学承办,常熟理工学院协办,苏州高新区管委会、苏州市科学技术协会支持,来自图像图形领域学术界、产业界的同仁2000余人齐聚一堂,展开思想碰撞和深入交流,共同展望图像图形学领域前沿趋势,探索科技赋能产业升...。

三年前,5G迎来了商用元年,三年的时间里,全世界已经有175个运营商开始部署5G,中国更是交出了漂亮的5G成绩单,目前已建成了超过100万个基站,5G终端数超过4.2亿,在这期间,5G让超过600万网友,云登顶,珠穆朗玛峰,足不出户欣赏珠穆朗玛峰的壮美与险峻,也通过5G,云网技术见证了火神山、雷神山医院建设的中国速度,都说,4G改变生...。
