论文解读 基于强化学习的时间行为检测自适应模型 2018 AAAI (论文解读基于什么理论)
雷锋网 AI 科技评论按 :互联网上以视频形式呈现的内容在日益增多,对视频内容进行高效及时的审核也变得越来越迫切。因此,视频中的行为检测技术也是当下热点研究任务之一。本文主要介绍的就是一种比传统视频行为检测方法更加有效的视频行为检测模型。
在近期雷锋网 gair 大讲堂举办的线上公开上,来自北京大学深圳研究生院信息工程学院二年级博士生黄靖佳介绍了他们团队在 AAAI 2018 上投稿的一篇论文,该论文中提出了一种可以自适应调整检测窗口大小及位置的方法,能对视频进行高效的检测。视频回放地址:
黄靖佳,北京大学深圳研究生院信息工程学院二年级博士生。2016 年毕业于华中科技大学计算机学院信息安全专业,获学士学位。现研究方向为计算机视觉、行为检测、增强学习等。
以下是 AI 科技评论对嘉宾分享的内容回顾。
分享主题 :AAAI 2018 论文解读:基于强化学习的时间行为检测自适应模型

分享提纲:
分享内容:
大家好,我的分享首先是介绍一下行为检测的应用背景,接下来介绍我们团队提出的 SAP 模型,以及模型在实验数据集上的性能,最后是对本次分享的总结。
行为检测任务的介绍

但是这种方法在解决任务时存在两个难点。
首先是对于一个没有切割过的视频,比如在图中这个视频中,所需要检测的目标是一个三级跳运动,三级跳在不同的情况下,根据人的不同,所持续的时间也是不同的。
第二个难点是,目标时间出现的位置是在视频中的任意时间点。
所以说用「两阶段方法」进行目标行为预测,会产生非常多不同尺度,不同位置 proposal。最简单的方法是用不同尺度的滑动窗口,从前到后滑动,产生非常多的 proposal,然后再做分类。这种方法虽然行之有效,但时间复杂度和计算复杂度都相当高,使得在完成这项任务时往往需要花费大量的计算资源。
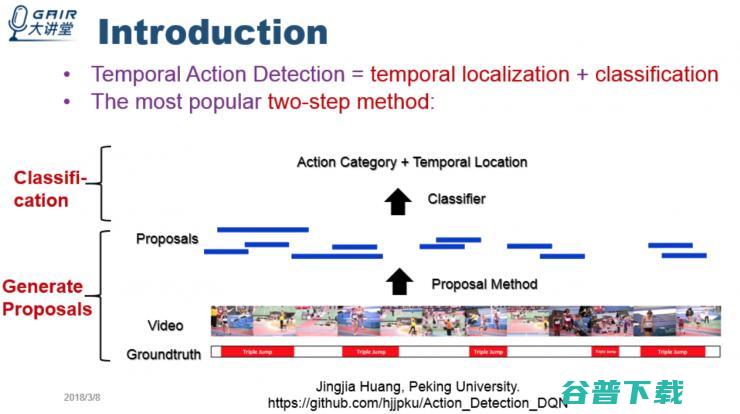
为了避免这种低效的检测方法,我们提出了一种可以自适应调整检测窗口大小及位置的方法,对视频进行高效的检测。
我们最开始的想法是能不能仅使用一个滑动窗口,只需要从头到尾滑动一遍就完成 proposal 产生过程呢?
这就必须要求窗口能不断地自适应地根据窗口所覆盖的内容,能够不断调节窗口的大小,最终的窗口大小能精确覆盖目标运动,从而得到检测的窗口区间。

我们使用增强学习作为背后的模型支撑来完成这样的循环过程,达到我们的目的。下面是 SAP 模型的框架图。

关于 TEMPoral Pooling Layer
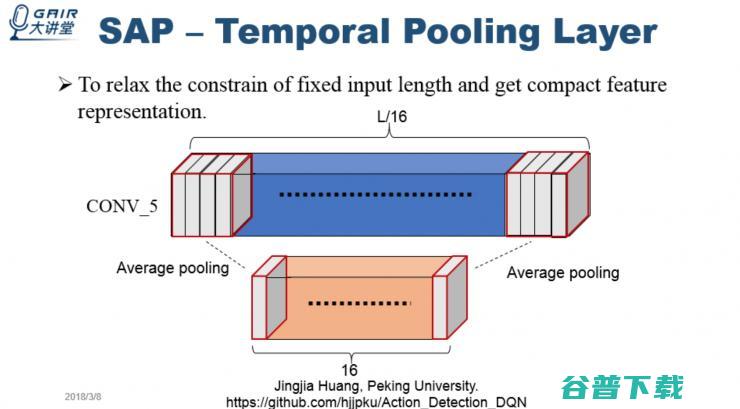
在原有的 C3D 模型中,要求输入的视频帧是固定的,一般是 16 帧或 8 帧。以 16 帧为例,当视频帧多于 16 帧,就需要对视频帧下采样,采样成 16 帧,送到视频中进行处理,这样在采样过程中会丢失非常多细节信息,造成特征表达不准确等问题。
而我们提出的 Temporal Pooling Layer 的输入帧可以是任意长度。
我们在增强学习中的奖励设置机制。在增强学习中,对于一个 agent,如果 agent 执行了一个动作后,我们认为是执行正确的,就给一个奖励;如果认为是错的,就给一个惩罚。

SAP 模型的训练过程,可到文末观看嘉宾的视频回放,或关注嘉宾的 GitHub 地址获取相关代码。

SAP 模型的测试

实验过程
我们的实验是在 THUMOS'14 数据集展开的,用它的 validation set 训练模型,在 test set 上进行实验评估。我们使用了是以下两个衡量标准。第一个是 recall 值和平均 proposal 数量函数第二个是 recall 和 IoU。


proposal 做分类后的评判标准是:Average Precison 和 mAP

检测性能的结果
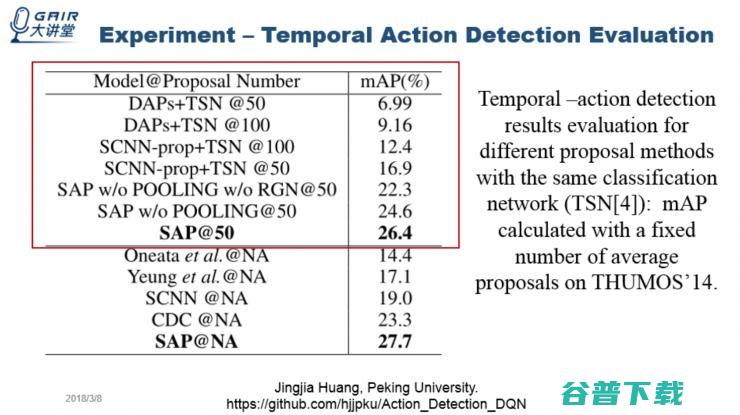
上图红色圈注的部分比较的是不同的模型,在取相同的 proposal 数量,用同样的分类器做分类,哪个模型的性能会更好。结果发现,在只有 50 个 proposal 的时候,我们的方法表现的最好。

总结
代码相关资料GitHub地址:
雷锋网GAIR大讲堂视频回放地址:
更多免费直播视频,请关注微信公众号: AI科技评论。



4399小游戏大全包含连连看,连连看小游戏大全,双人小游戏大全,H5在线小游戏,4399洛克王国,4399赛尔号,4399奥拉星,4399奥比岛,4399弹弹堂,4399单人小游戏,奥比岛小游戏,造梦西游online,造梦无双等最新小游戏。

大汉筛分机厂家生产振动筛分机,旋振筛分机,超声波筛分机,直线筛分机,气流筛分机,直排筛分机,滚筒筛分机等,外形分方形/圆形,材质有不锈钢/碳钢,型号有400mm-2000mm,厂家直销,价格低至3000元.

沈阳华威石油机械制造有限公司是集研发、生产、销售、服务于一体的石油设备及井下工具的专业生产企业。经过二十几年的努力和发展,取得了三十余项专利,其中发明专利3项,实用新型专利20余项。公司通过了ISO9001:2015质量管理体系认证、ISO14001:2015环境管理体系认证、ISO45001:2018职业健康安全管理体系认证及GB/T19022-2003/ISO10012-2003测量管理体系认证(AAA),我公司为高新技术企业。

冒泡分类,领先的分类信息网。您可以免费查找各种新鲜的二手物品交易、二手车买卖、房屋租售、招聘、交友及生活服务等分类信息。


超级网站目录是由人工编辑审核并免费收录各类优秀网站的中文网站目录,根据行业分类提供行业网站目录检索,旨在为网友和搜索引擎提供参考,是站长免费推广网站的最佳平台!

威廉伙伴是总部设在上海,营业范围包括广告代理、文化艺术交流策划、创意服务、公共活动组织策划、企业营销策划等。我们服务于上汽通用五菱、猎豹汽车、君马汽车等众多国内知名车企,从策略、创意、拍摄、制作、媒体投放到车展、年会、线下推广等各业务领域均与客户保持长期合作

心理老师联盟,心理老师之家,心理老师大本营,用软件与科技为心理老师分忧解难

趣游网专注于手游App及应用软件下载和攻略分享,覆盖各类热门应用,提供便捷的下载渠道。我们还汇聚了最实用的游戏攻略,助您轻松突破游戏各种难关,享受游戏的乐趣发现更多精彩!

常州永瀚电机有限公司


云视野科技有限公司


经营模拟类的单机游戏并没有过多的战斗元素,但仍然有很大的魅力,吸引了诸多玩家,因为游戏很容易给玩家带来成就感,也非常有创意,下面小编就给大家盘点一下目前最受欢迎的经营模拟类手游大全,对此有兴趣的玩家,可以下载尝试一下,1、,明日大亨,在游戏中,玩家将成为商业精英,各种各样的场景可以一一解锁,需要培训员工,建造一座座摩天大楼,将自己的管...。

大家好,我是你们的校长,我知道大家在家里都憋坏了,大家可能相对于封闭在家里,坐月子,,更希望能够早日上班,今天我带着大家换个思路来聊一个问题,面对新冠病毒的疫情,面对疫情危机,我们人类在天灾人祸方面有时候真的显得很无助,既然是危机,那就是危险和机遇并存,1、危险这几天,看到很多关于疫情的文章,这两天大家都在唱衰经济,说中小型企业,各种...。

获悉,12月4日,美团核心本地商业板块发布内部邮件,宣布新一轮组织架构调整,邮件内容显示,核心本地商业下原到家研发平台、到店研发平台、美团平台技术部整合升级为业务研发平台,任命孙致钊为业务研发平台负责人,向王莆中汇报,业务研发平台下,原到家研发平台、到店研发平台的各业务技术团队不变,各部门负责人向孙致钊汇报,原业务平台系统团队不...。

8月20日,印象笔记成立八周年之际,印象笔记董事长兼CEO唐毅在媒体沟通会上表示,印象笔记将深耕垂直领域和业务场景,拓展B端市场,并透露目前印象笔记正在进行A股市场IPO的新一轮融资,沟通会上,唐毅详细介绍了印象笔记当前的业务布局,管理个人信息的智能助手——,印象笔记,、针对企业级提高协作效率的团队工具——,印象团队,App、富集高价...。

根据第三方专业数字机构IDC出具的数据显示,2022年起,蓝牙耳机出货量连续下跌,在整体耳机市场疲软的行业大背景下,唯有,骨传导耳机,品类持续大热,创造行业中独自逆跌的,神话,骨传导耳机的大热,其本质是国内外户外运动以及健身市场规模的扩大,带来运动耳机市场的大热,在以往有限的市场选择中,相比较于入耳式耳机带来的闷塞,消费者们只能选择...。

发表在坚果投影仪2019,9,1710,47坚果J7好用吗,以前对LED灯泡的投影总感觉亮度不够,本来一直关注的都是L6H,但是家里用和单位用不一样,单位一台索尼,一台明基,那灯泡的热度和风扇的噪音我估计足能把看大片的好心情消磨殆尽,这回看到坚果J7都3000流明了,果断下手,也算是想试试看到底怎么样,坚果J7好用吗,坚果J7开箱机器...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为骆驼网站联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在骆驼网站联盟网站首页底部或友情链接位...。

据今天俄罗斯电视台,RT,网站7月1日报道,全球银行颁布按国民支出排名划分的2023年分类显示,俄罗斯从,中等偏上支出,升至,高支出,国度,乌克兰从,中等偏下支出,升至,中等偏上支出,国度,全球银行驳回的是可追溯至1989年的一种统计方法,也就是依照购置力平价,PPP,权衡的人均国民总支出,GNI,,并依据上一年数据,在每年7月1日左...。

俄罗斯或复原消费此前被制止的中短程导弹,增强远程打击才干和威慑力,据央视资讯报道,俄罗斯总统普京在6月28日在俄联邦安保会议常务委员会上示意,因为美国违犯,中导公约,等无关协定,俄罗斯应复原消费此前被制止的中短程导弹,这一动作是为了确保俄罗斯的片面安保,普京示意,美国已将中短程导弹运到欧洲用于军演,还以演习为由在菲律宾部署陆基中程导弹...。

CSDN电脑版是一款由北京创新乐知信息技术有限公司所推出的专业IT技术社区,致力于为中国的软件开发者和IT从业者提供全方位服务

mac忘记密码怎么找回 方法一:使用苹果随机光盘(macosxinstalldisc1),重启电脑,按住option键,选择光盘,进入后,先选择语言,在屏幕的上方会出现一个工具栏,在上面找到实用工具,在实用工具里面找到

码帮/辅助注册/雏菊任务/微信辅助系统/任务平台源码资源仅供学习研究美工使用,请勿用于商业和非法用途!源码说明本系统包括:做单端、下单端、总后台三端。结合微信辅助流程,严格定制的一套自动化任务平台。业务流程...

有趣的火柴棒游戏汇总有哪些,这类游戏大全正是为满足这一需求而生,它不仅提供了多样化的游戏选择,还让玩家有机会深入探索火柴人的独特世界,在这些游戏中,有些专注于展现火柴人自身的非凡能力,而有些则通过创意玩法让玩家感受到火柴棍的无限魅力,无论你是新手还是资深玩家,都能在这些游戏中找到属于自己的乐趣,1、,移动一根火柴使等式成立,游戏中的每...。

Adobe官方宣布,4月9日起,AdobeShockwave将正式终结,退出历史舞台,Windows版本的ShockwavePlayer也不再提供官方下载,Shockwave是一个基于浏览器的多媒体平台,主要用于交互应用、视频游戏等,最初诞生于1995年,2005年随着Macromedia公司被收购而进入Adobe大家庭,但近年来使用...。

开一个女装加盟店,其实其中的管理技巧是非常重要的,很多人都说,女装行业就是一个低难度的行业,入行更是非常容易的,事实上也是这样,进入女装行业的确也是一件不难的事情,但是,在如今这个竞争时代里面,想要做好你的女装加盟店生意,也并不是一件容易的事情,很多女装加盟店长们也都非常头疼,自己的女装加盟店应该要如何管理呢,那么现在不妨就来37°L...。

教育市场上指出,多阅读对于整个学习生活均可带来一定的帮助,由此很多的阅读教育项目,均是取得不错的发展,书果星球儿童阅读推广一站式的阅读服务,多年来致力于阅读指导和发展,实现了多方向经营的渠道,主要是面对五到十四岁的儿童所进行推广的专业阅读,作为大众创业者所信赖的项目之选,在此之前,去探索下书果星球儿童阅读怎么加盟,学生多吗,书果星球儿...。

8月7日,8月9日,2020年全球人工智能和机器人峰会,简称,CCF,GAIR2020,在深圳如期举办!CCF,GAIR由中国计算机学会,CCF,主办,香港中文大学,深圳,、雷锋网联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办,以,AI新基建产业新机遇,为大会主题,致力打造国内人工智能和机器人领域规模最大、规格最高、跨界最广...。
