苹果首份AI论文横空出世 提出SimGAN训练方法 (apple首)

当AI浪潮袭来,谷歌、Facebook、微软等几个山头恨不得把自己都浸没在潮水里,可劲打滚儿的时候,苹果这座孤岛却始终有一种不愿被沾湿的姿态。
12月初,在洒满阳光的西班牙NIPS大会上,苹果AI研究团队负责人Russ Salakhutdinov曾兴奋地宣布,苹果将允许其AI研究人员对外发布论文。那之后,众人都在翘首以待,巴巴等着这个这个世界上市值最高的公司(截至12月23日市值6172.34亿美元)的第一篇AI论文将以何种面目出现。

今天,这篇论文出来了。苹果伸出了手指,试探了一下海水。
这篇题为《通过对抗训练从模拟的和无监督的图像中学习》(Learning from Simulated and Unsupervised Images through AdveRSArial Training)的论文于12月22日提交给了arXiv.org,一经发布迅速点燃了媒体头条。
苹果这篇图像识别领域的论文,提出了一个所谓“模拟+无监督学习”(simulated + unsupervised learning),使用了如今最炙手可热的深度学习“对抗训练”。
而有着“GANs之父”之称的Ian Goodfellow在推特里直接评论道:“苹果第一份机器学习论文是关于GANs的。”
于是,GANs又借势火了一把。
生成对抗网络(GANs)的经典过程
所谓的GANs模型,就是让两个网络相互竞争,玩一个“猫鼠游戏”。
G尝试用自己的赝品来“蒙骗”D,而D也不断提高自己鉴别赝品的水平。这样G的造假能力和D的鉴别能力都会越来越高超。
在机器学习领域,需要海量的数据来训练模型,而海量数据本身的获取都成问题。AI界常有这么个说法:
南京大学周志华教授也曾经在演讲中提到机器学习应用的限制因素:
所以,GANs最具革命性的地方在于,它的生成器G自己产出数据,而人只需要最初输入一些随机向量。无怪乎,Yann LeCun曾评价说:
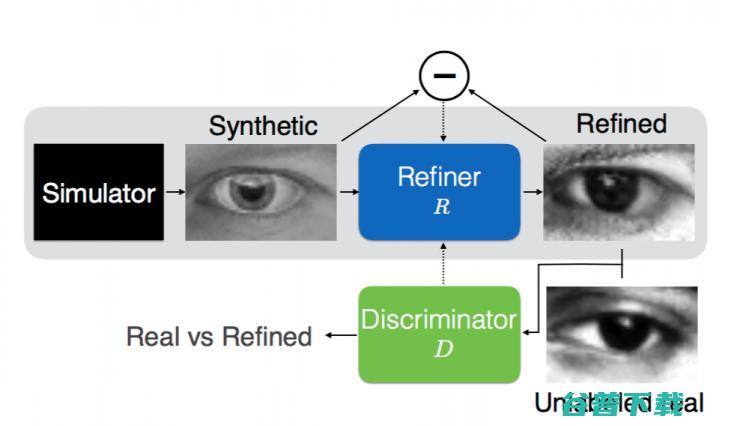
但是苹果这份论文里提到的模型,与GANs还是有些微不同的。他们想要解决的问题就是:提升合成图像的质量。他们对GANs稍加修改,提出了“SimGAN”训练方法,其中的“Sim”指的就是单词“模拟器”。论文摘要里提到:
苹果的SimGAN其实包括三部分:模拟器(Simulator)和精制器(Refiner),然后再加上一个判别器(Discriminator)。模拟器合成图像,再用精制器优化,最后喂给判别器训练。
有学术圈内人士对这篇论文的“含金量”表示怀疑,然而苹果这份论文“试水”的意义其实远大于论文本身的意义。Forbes评论道: 这篇AI论文,是苹果标志性的一步 。
对于AI业界来说,这表明苹果要迈开步子、扛着大旗来搅动海水了。
这篇论文的第一作者是Ashish Shrivastava,其个人主页上显示为马里兰大学计算机视觉博士。

其它共同作者还有5人,分别是Tomas Pfister, Oncel Tuzel, Wenda Wang(华裔), Russ Webb 和Josh Susskind。但是苹果的“秘密文化”并没有一下子就敞开大口,这6名研究人员,除了Tomas Pfister之外,雷锋网在Twitter上很难找到其它5人的踪迹,而Tomas Pfister这位剑桥、牛津双名校的高材生,至今发过的推文也只有5条而已。
PS:关注雷锋网(微信公众号:雷锋网)
百度硅谷 AI 实验室主任 Adam Coates:企业级 AI 的未来展望及人才竞争
AI+时代,产品经理如何做才能获得机会突破?
原创文章,未经授权禁止转载。详情见 转载须知 。




《劲舞团》端游下载,19周年全新游戏模式上线,最强福利开启,海量道具等你领!重返千禧年再聚首,我们的青春永不言悔!

4399逃跑吧少年官网为您提供逃跑吧少年怎么玩、逃跑吧少年攻略、营救队友技巧、逃跑吧少年视频、逃跑吧少年资讯爆料、逃跑吧少年电脑版下载、安卓版下载。

“徐涂艺术”品牌由“诗书画”三绝禅修艺术家徐涂老师首创,包括:徐体书法、写意国画、诗词楹联等落地原创常年展览定制、一对一精准人才教学、企事业文化艺术、古玩收藏鉴赏顾问等。

贵阳凯利建材有限公司专业从事混凝土生产、销售的部门。是贵州省较大的大型混凝土生产企业之一。企业坐落于山川秀丽、文学圣地修文县。随着西部大开发,贵州省各城区的建设发展,公司规模不断扩大,现已是注册资金1000万,投入资产3000万的大型企业,,其中设有生产部、实验部、市场部、质管部、质保部、对外贸易部、财务部、办公室等8个部室。 公司主要产品有混凝土、透水混凝土、彩色混凝土、彩色透水混凝土等水泥制品。公司产品通过ISO9001质量体系认证.并取得国家质量监督检验总局的“全国工业产品生产许可证”等各类生产与销售证书。 我厂主要生产的透水混凝土系列产品规格型号多达二十多种,公司采用先进的芯模振动制管机设备与技术,拥有年生产100万平方的生产能力,旗下的钢筋混凝土拥有不受地底温度影响,混凝土强度高、抗渗性好、安全流动性高、安装方便、绿色环保、抗外压能力强、生产效率高等优点。我厂生产的混凝土有以下特点: 1、色彩缤纷、色泽鲜明、透水度及表面耐磨性好、组群多样。 2、品种繁多、各式各样。 3、质量可靠:强度高、挤压不易损坏、面部平整、易于安装、对环境无污染、不褪色。 4、产量高:平均日产量达到3千平方以上。 “以质量求生存,以信誉谋发展”为理念、以市场需求为导向、以用户满意为宗旨、以科技进步为先导、以质量体系有效运行为保证,不断完美和巩固质量体系,提高企业竞争能力,发展企业规模经济。以专业的技术人员,先进的生产设备,成熟的生产工艺技术,严格的质量管理体系和完善的售后服务更好的服务于社会。由于公司产品质量可靠、信守合同、供货及时,受到广大用户一致好评。欢迎各界商家和客户前来指导、洽谈业务。 回顾多年的风雨历程,让客户满意一直是凯利永恒的主题,诚信不仅是凯利立身之本,更是企业可持续发展的保证。在未来的岁月中,凯利人将一如既往地在技术、服务和品质上全面发展,全心全意为客户提供更好的产品和更优的服务!

双体软件精英产业学院(原双体系卓越人才教育基地),是重庆移通学院按“软件技术实战+职场关键能力”两套模式进行软件技术人才培育的特色教学单位。

西风网,起名知识,起名

天才教育网(天才网)凝聚了全国上万个培训机构,百万条培训课程信息,千万条教育资讯,努力打造成为教育培训第一平台,为广大学员提供最优质的服务!

开店吉日,取名网,生辰八字查询,文化传统民俗,每日一卦、线上抽签、婚姻爱情占卜,帮助你更好地理解人生的选择与方向。

次方科技,esb,soa,mdm,api定制,次方科技,免费ESB,云ESB,服务编排

101家教是专业北京家教网,家教行业领导品牌★15年家教辅导,20万师资在线挑选★上门一对一家教,省时省力★师资包括重点中小学在职一线老师和名校优秀大学生★提供小学、初中、高中一对一上门家教辅导和代理加盟!

浙江杨氏实业有限公司成立于1994年,年产各类袜子7000多万双,种类达上千余种,多种袜子可供选择,满足您对舒适和时尚的需求。现拥有6个数字化生产车间,员工200余人,各类数字化智能一体袜机800余台及相应的配套设施。


游戏的类型多种多样,除了有战争题材的游戏,也会以不同的战争为背景,比如古代战争以及现代战争,同时还有很多的逃生游戏,那么2024大型逃生游戏下载哪个呢,小编给大家总结了几款满足需求的逃生游戏,除了丰富的玩法以及背景,还能带给玩家特别刺激的游戏体验,需要玩家开动脑筋,在这款大型的逃生游戏当中,主要就是多人解谜游戏,每一局有7位玩家,其中...。

大家好,我是小编,专注于短视频运营及直播带货,分享自己多年运营的实战经验,希望能给刚入门的、或正想入门的同学一些帮助,最近很多同学在来咨询我,开直播需要哪些设备?直播脚本怎么撰写?直播间怎么搭建?首先,做直播肯定少了直播的设备,作为新人很容易买错设备,甚至买了一堆没有用的东西,不少同学前期都买了很多用不了的设备,不过,如果你是想做带货...。

[摘要]诺基亚的前任员工在芬兰已经设立了400家创业公司,其中可能会出现下一个诺基亚,芬兰对于中国用户而言一度非常亲近,十几年来,出自于芬兰的诺基亚手机承载了人们的科技和数字生活,,科技以人为本,的口号已经深入身心,一度风靡的手机游戏Angrybirds也出自芬兰游戏公司Rovio之手,遗憾的是,去年,在诺基亚手机业务出售给微软之后,...。

字幕组双语原文,人工智能本科学位完整四年课程规划,斯坦福,英语原文,AComplete4,YearCoursePlanforanArtificialIntelligenceUndergraduateDegree翻译,雷锋字幕组,明明知道、jiazhenbin、娄门人家,离开学校已经有一段时间了,我现在有许多时间可以去反思下某些课程对我...。

营养早餐也是健康的关键,经过合理营养和平衡膳食的调节,从食物中摄入、消化、吸收、代谢和利用机体所需物质,即满足自身生长发育和维持生命活动,又全面加强人体营养水平,提高人体抵抗力、免疫力和应激能力,也是保护人体健康的一种手段,...。

校园暴力事件频发,引发社会广泛关注,青少年时期,本应是充满阳光和梦想的时期,然而,校园霸凌却如同阴云,遮蔽了这一片纯净的天空,未成年人保护法,本应成为保护弱小者的盾牌,却在这场事件中,成为加害者的庇护所,校园霸凌事件,往往以一种固定的模式展开,举报、传播、舆论发酵、惩罚和司法处理,然而,核心问题在于舆论的影响力,一旦事件被关注,就可能...。

我今天要讲的,是一个关于公平的故事,就像很多人回首往昔,都不知道为何会与某人结下友谊一样,我也有一个曾经觉得,这人跟我八竿子打不着,的朋友,高一文理分班的那阵子,林来到我们班,林是难得的美人,而我看见林的第一眼,便看见她眼里的不羁,那是一湾清浅的湖,又好似曾掀起过巨浪,从闲言碎语中得知,林在初中时就是年级上出名的,坏女孩,——我当时给...。

全球时报,全球网报道记者白云怡,在12日的外交部例行记者会上,有媒体提问称,菲律宾国防部长吉尔伯特·特奥多罗当天示意,中国正对菲律宾施加越来越大的压力,试图让菲律宾丢弃其在南海的主权权益,他还称菲律宾是所谓,中国侵略,的受益者,中方对此有何评论,对此,中国外交部发言人林剑回应示意,针对菲方无关人士的舆论,我要指出的是,每一次性中菲海...。

周一,多只美股出现行情异常,伯克希尔哈撒韦、蒙特利尔银行、巴里克黄金等股票出现暴涨,其中,股神巴菲特旗下投资公司伯克希尔哈撒韦突然从前一个收盘价的62万美元,股跌到了185.1美元,股,暴涨99.97%,随后,纽交所称,股票出现异常报价的要素是多少钱区间出现技术疑问,目前该技术疑问曾经获取处置,截至发稿,蒙特利尔银行、巴里克黄金复原买...。

外地期间7月1日,委内瑞拉总统马杜罗在电视节目上发表,委政府方案于本周内复原与美国政府之间的对话,马杜罗示意,过去两周内始终接到美方重启间接对话的提议,他自己曾经接受关系提议,并将于7月3日复原与美方的对话,他还示意,委美双方重启对话是紧急事项,总台记者宫祥诚,委内瑞拉总统,马杜罗简介委内瑞拉总统马杜罗是一位具有丰富政治经验和坚定左...。

如何进行Java开发项目的性能监控与调优在当今的软件开发领域中,性能监控与调优是确保项目能够高效运行和提供优质用户体验的重要环节。特别是对于Java开发项目而言,由于Java是一门强大且广泛使用的编程语言,其性能优化显得尤为重要。因此,本文将探讨如何进行Java开发项目的性能监控与调优。一、性能监控性能监控的目的是实时监测和记录项目运行过程中的各项性能指标,

八爪鱼采集器Mac版是Mac电脑上的一款全球百万用户信赖的数据采集器。八爪鱼采集器Mac版可以满足多种业务场景,适合产品、运营、销售、数据分析、政府机关、电商从业者、学术研究等多种身份职业;您可以免费下载。

近日,网易有钱宣布正式关门,12月23日起正式关闭在线充值服务下线APP,明年04月1网易有钱全面停止运营,关闭服务器,有账单数据的朋友赶紧导出了,根据松松编辑杰哥了解,网易有钱是网易2015年上线的一款自动记账产品件,当时主要对标随手记、挖财等互联网记账软件,凭借自动记账,信用卡管理,资产管理,基金管理等理财功能,拉了不少用户,算是...。

辅导班,是以提高成绩,不一定学习成绩,为目的一个课外辅导机构,通常也称作,课外辅导班,学习辅导班,军考辅班,辅导班辅导的课程科目种类很多,包括,小学、初中、高中的语文、数学、英语、物理、化学、生物、历史、地理、政治、美术、体育、音乐等,还有一些语言类的辅导,以及社会上需要培训辅导的科目,辅导班大致分为三类,小班和大班以及一对一辅导,...。

夏威夷当地时间7月26日,CVPR2017最后一天,李飞飞教授等学者在ImageNetworkshop上缅怀过去8年计算机视觉,CV,发展的ImageNet时代,同时宣布挑战赛最终归于Kaggle,同一天上午,WebVision也公布了第一期获奖名单,WebVision竞赛由苏黎世联邦理工、GoogleReasearch、卡耐基梅隆大...。
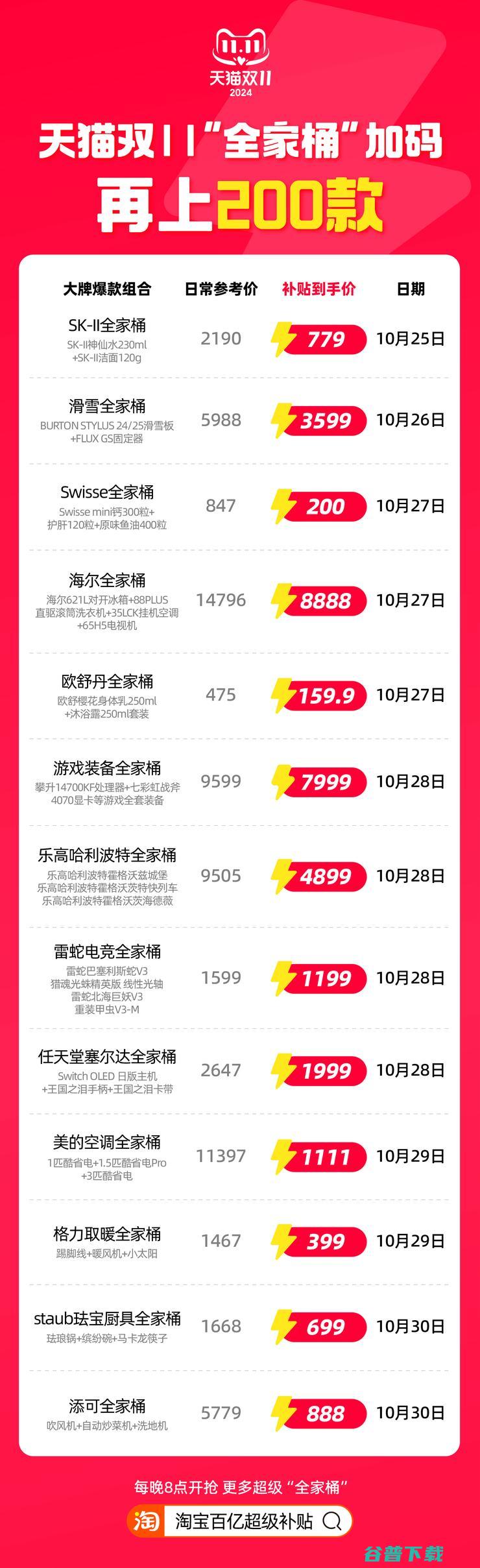
大牌,全家桶,再加码!乐高哈利波特,全家桶,原价9505元,补贴价4899元,SK,II,全家桶,原价2190元,补贴价779元,爱马仕香水,全家桶,原价1516元,补贴价仅399元……10月25日,天猫双11再加码,淘宝百亿补贴增推超200款大牌全家桶,除了以上大牌,增推的,全家桶,当中,还包含消费者呼声很高的美的空调三件套,原价1...。

发表在专业问答2023,1,1516,38展示机型信息,品牌型号,坚果O1S、iPhone14、华为mate40系统版本,LunaOS、iOS16.1、鸿蒙OS2.0软件版本,当贝投屏1.0.2坚果O1S投屏需要和手机连接同一无线网才可以完成,总共可以分为三步,下面为坚果O1S怎么投屏的详细步骤做具体说明,坚果O1S怎么投屏一、苹果手...。
