大数据背景下的最佳异常检测算法 孤立森林 (大数据背景下财务会计的转型与发展)
双语原文链接: Isolation Forest is the best Anomaly Detection Algorithm for Big>"iForest" 是一个优美动人,简洁优雅的,只需少量参数就可以检测出异常点。原始论文中只包含了最基本的数学,因而对于广大群众而言是通俗易懂的。在这篇文章中,我会总结这个算法,以及其历史,并分享我实现的代码来解释为什么是现在针对而言最好的异常检测算法。
为什么iForest是现在处理大数据最好的异常检测算法
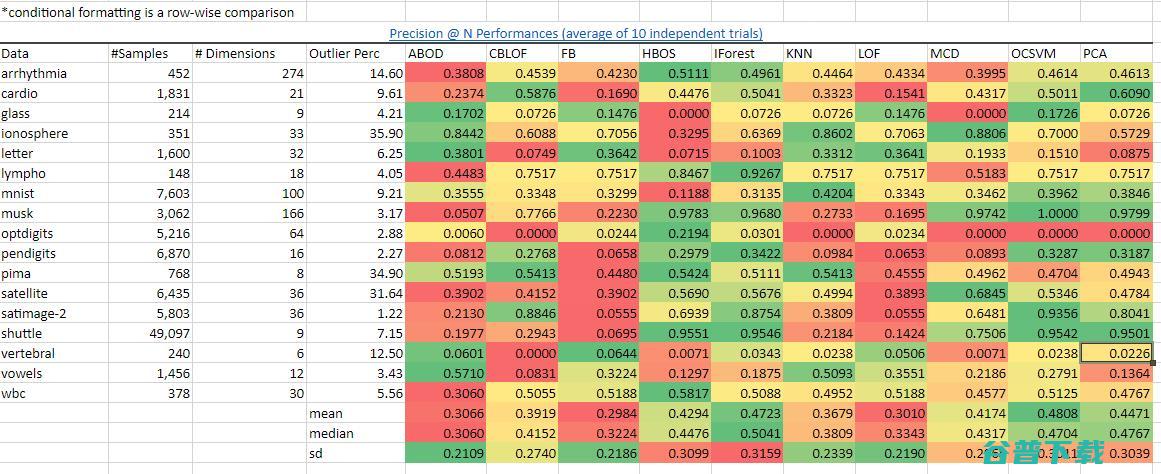
总结来说,它在同类算法中有最好的表现。在多种数据集上的表现和精确度都比大多数其他的异常检测算法要好。我从的作者们那里取得了基准数据,并在中逐行使用绿红梯度的条件格式化。用深绿色来标识那些在这个数据集上有最好的表现的算法,并用深红色来标识那些表现得最差的:

绿色表示好而红色表示差。我们看到在很多的数据集以及总体的角度上是领先的,正如平均值,中位数,标准差的颜色所表示。图源:作者。数据源:
我们看到在很多的数据集上以及总体上的表现是领先的,正如我计算出来的平均值,中位数,标准差的颜色所表示的一样。从(最重要的项指标的准确度)的表现来看也能得出同样的优秀结果。
图源:author.Data
源:
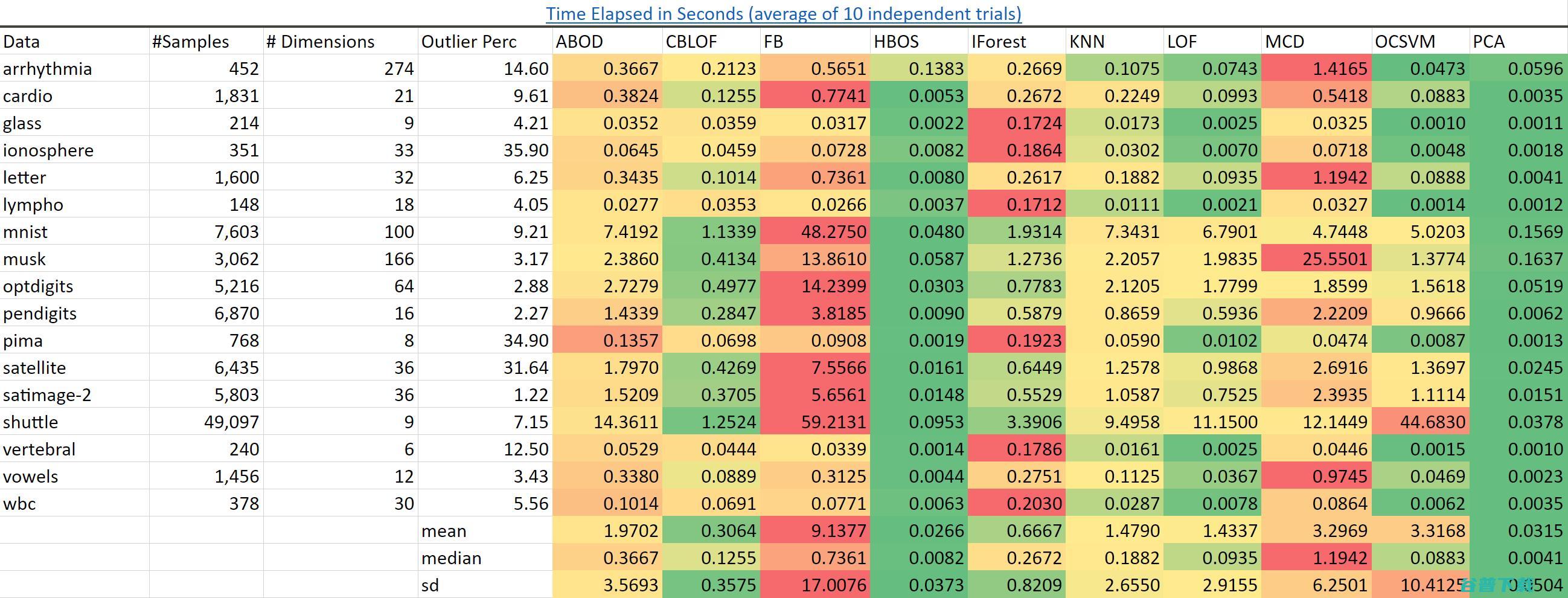
可扩展性。以它表现出来的性能为标准而言是最快的。可以预料到的是,和基于频数直方图的异常点检测算法()在所有的数据集上都有更快的速度。
近邻算法()则要慢得多并且随着数据量变多它会变得越来越慢。
我已经成功地在一个包含一亿个样本和三十六个特征的数据集上构建出孤立森林,在一个集群环境中这需要几分钟。而这是我认为的算法没办法做到的。
图源:author.Data
源:
要点/总结
我通过下面的综述来非常简洁地总结原来有10页内容的论文:
孤立树节点的定义:T或是一个没有子节点的叶子节点,或者是一个经过检验的内部节点,并拥有两个子节点(Tl,Tr)。我们通过递归地进行下述过程来构造一棵iTree:随机选择一项特征q和一个分割值p来划分X,直到发生下列情形之一为止:(i)树到达了限制的高度,(ii)所有样本被孤立成一个只有他们自己的外部节点,或者(iii)所有数据的所有特征都有相同的值。
路径长度:一个样本x的路径长度h(x)指的是从iTree的根节点走到叶子节点所经历的边的数量。E(h(x))是一组孤立树的h(x)的平均值。从这个路径长度的平均值,我们可以通过公式E(h(x)):s(x,n)= 2^[^[− E(h(x)) / c(n)]来得到一个异常分数s(x,n)。基本上,s和E(h(x))之间存在一个单调的关系。(想知道细节的话请查阅文末的附录,有一张图描述了他们之间的关系)。这里我不会讨论c(n),因为对于任意给定的静态数据集而言它是一个常数。
用户只需要设置两个变量:孤立树的数量和训练单棵树的子采样大小。作者通过对用高斯分布生成的数据做实验来展示了只需要少量的几棵树和少量的子采样数量就可以使平均路径长度很快地收敛。
小的子采样数量(抽样的抽样)解决了和问题。造成这两个问题的原因是输入的数据量对于异常检测这个问题来说太大了。是指由于某个正常的样本点被异常点所包围而被错误地标注为异常,则是相反的情况。也就是说,如果构建一个树的样本中有很多异常点,一个正常的数据点反而会看起来很异常。作者使用乳房线照相的数据来作为这个现象的一个例子。
小的子采样数量使得每一棵孤立树都具有独特性,因为每一次子采样都包含一组不同的异常点或者甚至没有异常点。
不依赖距离或者密度的测量来识别异常点,因此它计算成本低廉且有较快的速度。这引出了下一个议题。
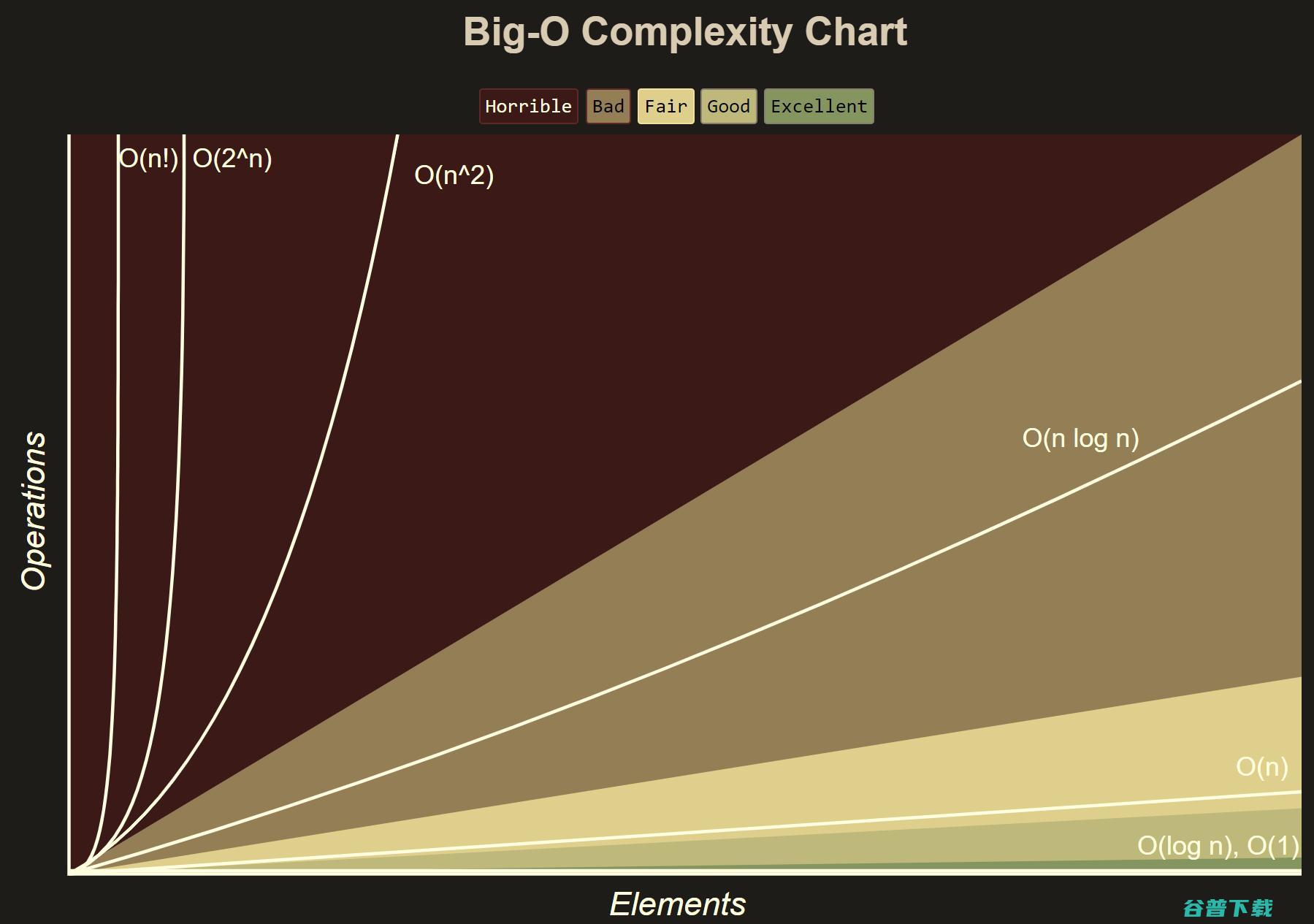
线性的时间复杂度,()。不正规地说,这意味着运行时间随着输入大小的增加最多只会线性增加。这是一个非常好的性质:
历程
见多识广的读者应该知道一个优秀的新想法出现与它的广泛应用之间可能会有数十年之久的间隔。例如,逻辑函数在年被发现,在年被重新发现(更多信息可参考)而到如今才被数据科学家频繁地用于逻辑回归。在最近几十年,一个新想法和它被广泛应用的间隔时间已经变得更短了,但这仍然需要一段相对较为漫长的时间。最先在年公开,但直到年后期才出现了可行的商业应用。 这是其时间线:
12/2008 -iForest的原始论文发布(论文)
07/2009 -iForest的作者们最后一次修改其代码实现(代码)
10/2018 -h2o小组实现了版和R版的iForest(代码)
01/2019 -PyOD在Python上发布了异常检测工具包(代码,论文)
08/2019 -Linkedln 工程小组发布了 iForest的Spark/Scala版本实现(代码,通讯稿)
代码实现
由于这篇文章是关于的,我采用了的集群环境。这里省略的大部分的脚手架(软件质量保证和测试之类的代码)的代码。如果在配置集群环境中需要帮助,可以参考我的文章:如何为搭建高效的
集群和
我发现能很轻易且快捷地处理万行,个特征的数据,只需几分钟就完成计算。
| importh2o#h2oautomateddatacleaningwellformydatasetimportpkg_resources###################################################################printpackages+versionsfordebugging/futurereproducibility###################################################################dists=[dfordinpkg_resources.working_set]#Filteroutdistributionsyoudon'tCareaboutanduse.dists.reverse()dists###################################################################initializeh2oclusterandloaddata##################################################################h2o.init()#importpyarrow.parquetaspq#allowloadingofparquetfilesimports3fs#forworkinginAWSs3s3=s3fs.S3FileSystem()df=pq.ParquetDataset('s3a://datascience-us-east-1/anyoung/2_processedData/stack_parquetFiles',filesystem=s3).read_pandas().to_pandas()#checkinputdataloadedcorrectly;prettyprint.shapeprint('('+';'.join(map('{:,.0f}'.format,df.shape))+')')#ifyouneedtosampledatadf_samp_5M=df.sample(n=5000000,frac=None,replace=False,weights=None,random_state=123,axis=None)#convertPandasDataFrameobjecttoh2oDataFrameobjecthf=h2o.H2OFrame(df)#dropprimarykeycolumnhf=hf.drop('referenceID',axis=1)#referenceIDcauseserrorsinsubsequentcode#youcanomitrowswithnasforafirstpasshf_clean=hf.na_omit()#prettyprint.shapewiththousandscommaseparatorprint('('+';'.join(map('{:,.0f}'.format,hf.shape))+')')fromh2o.estimatorsimportH2OIsolationForestEstimatorfromh2o.estimatorsimportH2OIsolationForestEstimatorfullX=['v1','v2','v3']#splith2oDataFrameinto80/20train/testtrain_hf,valid_hf=hf.split_frame(ratios=[.8],seed=123)#specifyiForestestimatormodelsisolation_model_fullX=H2OIsolationForestEstimator(model_id="isolation_forest_fullX.hex",seed=123)isolation_model_fullX_cv=H2OIsolationForestEstimator(model_id="isolation_forest_fullX_cv.hex",seed=123)#trainiForestmodelsisolation_model_fullX.train(training_frame=hf,x=fullX)isolation_model_fullX_cv.train(training_frame=train_hf,x=fullX)#savemodels(haven'tfiguredouthowtoloadfroms3w/opermissionissuesyet)modelfile=isolation_model_fullX.download_mojo(path="~/",get_genmodel_jar=True)print("Modelsavedto"+modelfile)#predictmodelspredictions_fullX=isolation_model_fullX.predict(hf)#visualizeresultspredictions_fullX["mean_length"].hist() |
如果你使用来验证你的带标签数据,你可以通过比较数据集中的正常数据的分布,异常数据的分布,以及原来数据集的分布来进行进一步推理。例如,你可以查看原本数据集中不同的特征组合,像这样:
| N=df.count()df[['v1','v2','id']].groupby(['v1','v2']).count()/Ndf[['v1','v3','id']].groupby(['v1','v3']).count()/N... |
并与使用得出的正常异常数据集进行比较。正如下面所展示的这样:
| ###################################################################columnbindpredictionsfromiForesttotheoriginalh2oDataFrame##################################################################hf_X_y_fullX=hf.cbind(predictions_fullX)###################################################################Sliceusingabooleanmask.Theoutputdatasetwillincluderows#withcolumnvaluemeetingcondition##################################################################mask=hf_X_y_fullX["label"]==0hf_X_y_fullX_0=hf_X_y_fullX[mask,:]mask=hf_X_y_fullX["label"]==1hf_X_y_fullX_1=hf_X_y_fullX[mask,:]###################################################################Filtertoonlyincluderecordsthatareclearlynormal##################################################################hf_X_y_fullX_ml7=hf_X_y_fullX[hf_X_y_fullX['mean_length']>=7]hf_X_y_fullX_0_ml7=hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length']>=7]hf_X_y_fullX_1_ml7=hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length']>=7]###################################################################ConverttoPandasDataFrameforeasiercounting/familiarity##################################################################hf_X_y_fullX_ml7_df=h2o.as_list(hf_X_y_fullX_ml7,use_pandas=True)hf_X_y_fullX_0_ml7_df=h2o.as_list(hf_X_y_fullX_0_ml7,use_pandas=True)hf_X_y_fullX_1_ml7_df=h2o.as_list(hf_X_y_fullX_1_ml7,use_pandas=True)###################################################################Lookatcountsbycombinationsofvariablelevelsforinference##################################################################hf_X_y_fullX_ml7_df[['v1','v2','id']].groupby(['v1','v2']).count()hf_X_y_fullX_0_ml7_df=h2o.as_list(hf_X_y_fullX_0_ml7,use_pandas=True)...#Repeataboveforanomalousrecords:###################################################################Filtertoonlyincluderecordsthatareclearlyanomalous##################################################################hf_X_y_fullX_ml3=hf_X_y_fullX[hf_X_y_fullX['mean_length']<3]hf_X_y_fullX_0_ml3=hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length']<3]hf_X_y_fullX_1_ml3=hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length']<3]###################################################################ConverttoPandasDataFrameforeasiercounting/familiarity##################################################################hf_X_y_fullX_ml3_df=h2o.as_list(hf_X_y_fullX_ml3,use_pandas=True)hf_X_y_fullX_0_ml3_df=h2o.as_list(hf_X_y_fullX_0_ml3,use_pandas=True)hf_X_y_fullX_1_ml3_df=h2o.as_list(hf_X_y_fullX_1_ml3,use_pandas=True) |
我完整地实现了上面的代码并把我的数据输出到中,很快就可以得到如下的一些累积分布函数:
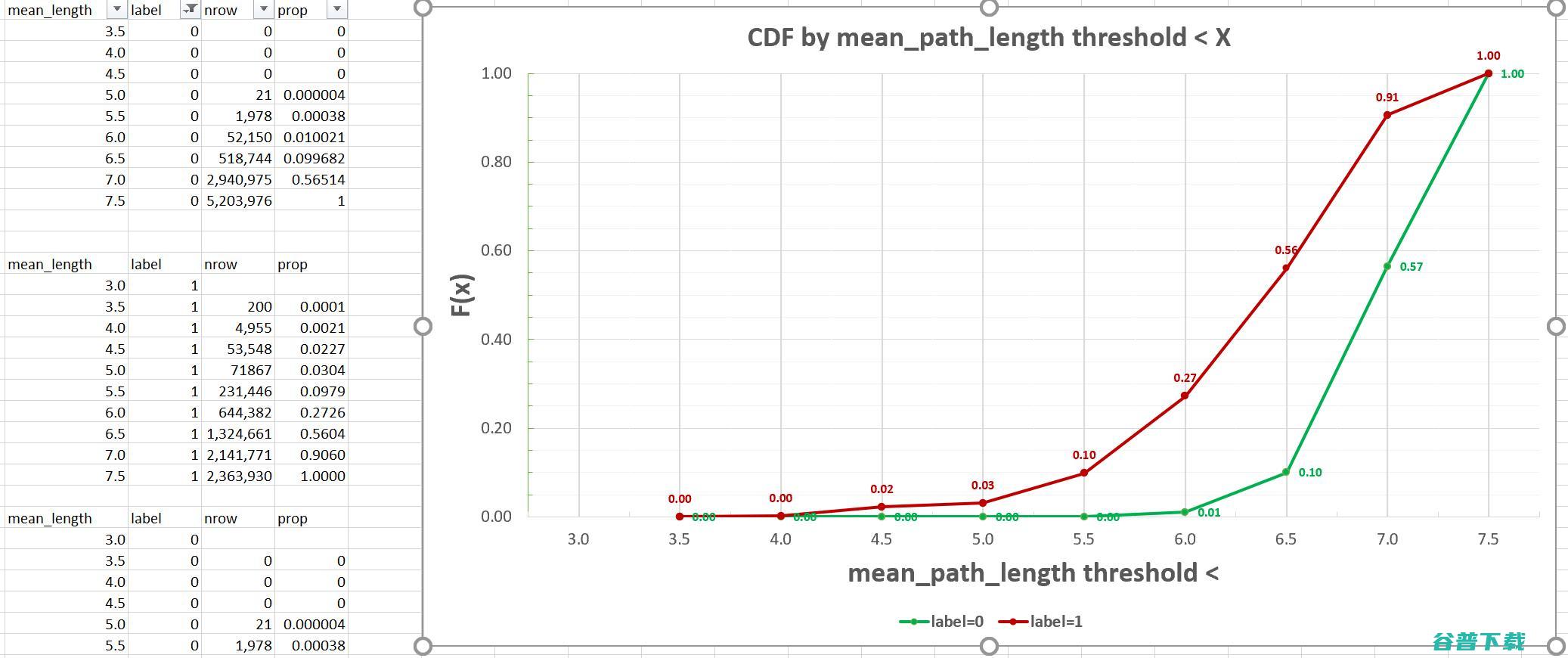
图源:作者自己的作品。绿线表示标识为的数据,即正常样本红线
代表的是标识为的样本,被认为有可能是异常的。
参考文献
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



轻跨境由中国联通授权运营跨境业务,为跨境电商用户提供全球范围内的跨境电商线路服务。

爱牵挂数字科技_爱牵挂提供智慧养老解决方案,养老服务平台,老人定位手环,老人呼叫器,老人智能手表定位器等智能硬件,适用于养老、残联、健康管理等项目18620184339

Gilson移液器厂家,移液工作站。涵盖固相萃取、制备色谱、移液工作站、电动移液枪枪头、小分子化合物纯化、多道移液器操作较准等样品管理和纯化解决方案,自1957年成立以来,始终坚持自主研发,具备硕果累累的创新记录,发明了全球第一支可调量程移液器PIPETMAN®,第一种移液器称量校准方法,第一台全自动固相萃取系统等,拥有超过750项专利。

浙江大自然户外用品股份有限公司诞生于1992年,30年来潜心专注于运动、户外用品的研发、生产。时至今日,已成为户外运动行业知名的充气床垫、户外箱包供应商,与全球40多个国家200多个品牌建立了良好稳定的合作关系。公司产品主要包括:自动充气垫、充气床、防水包、冰包、枕头、坐垫以及TPU复合面料等。

好伙伴为网络货运平台资质申报一站式服务商,无车承运人/网络货运资质申请数量国内第一,为400多家物流企业提供网络货运技术支持,成功取得网络货运资质。好伙伴专注物流软件20年,满足网络货运/无车承各业务及运输场景要求。

广东老榕树网络科技有限公司,品牌维护,品牌推广,全网营销,整站SEO,口碑维护,媒体投稿,舆情监控与维护,新闻源优化,网络推广,全网营销,整合营销,公司以战略规划、品牌建设、落地营销三大核心服务为中大型企业及品牌提供一站式全网营销服务。

富凌财经

江西玉道网络科技有限公司,位于南昌市东湖区八一大道357号财富广场A座1304室,是一家专业从事IT设备运维、网络工程、系统集成的公司。我们以积极主动和低调务实的工作态度为客户服务,拥有独特的经营理念和扎实的技术实力,致力于长期为江西客户提供优质且实惠的产品及服务。自创立之初即高瞻远瞩,外广布渠道以迎宾,内精设系统以待客,纳优质资源为己用。历经数年网络市场风云,成就业界虎踞龙盘之势,荣获江西优质网络服务商之誉。

电伴热带,伴热带,电热带,电伴热,伴热电缆,mi加热电缆-合肥美阳电热器材有限公司是专业从事电伴热带,自限温电伴热带,恒功率电伴热带,mi加热电缆,防爆伴热带,管道电伴热,储罐电伴热,灰斗电伴热的生产销售与施工为一体的生产厂家。欢迎选购!

游族网络(youzu.com)是国内知名网页游戏与手机游戏综合性运营平台。我们秉承真诚、简单可依赖的态度为玩家传递快乐,提供好玩的网页游戏与热门手机游戏;女神联盟、大皇帝、少年三国志、少年西游记、狂暴之翼、盗墓笔记、刀剑乱舞online等是我们为玩家提供的最新精品游戏,游族网络与您分享简单的快乐!

消防维修网【www.119wei.com】专业消防维修工程人员进行维修,多年从业经验,可以维修多个厂商的消防主机问题。消防主机维修电话:4000-346--119.

【江苏科源报废汽车回收拆解】有限公司专业从事报废汽车回收,报废汽车拆解,包括新能源汽车报废拆解等服务,专业的服务高品质的效率,欢迎来电咨询:0519-68267116


据DSCC机构最新发布的,MicroLED显示技术和市场前景报告,,MicroLED显示的市场仍然很小,但预计到2027年将达到13亿美元规模,在MicroLED能够与其他技术竞争之前,降低制造成本将是必要的,如OLED,DSCC分析师表示,,MicroLED最初被认为是一种适用于所有应用的理想领先显示技术,但这种炒作已经褪去,OLE...。

餐饮项目的市场前景是几乎所有人都能看得到的,并且餐饮行业有着较低的准入门槛,因此很多创业者都会将餐饮智慧之选作为自己的首要选择,不过,有些餐饮项目因为规模较大,所需要的资金成本也会较高,并不在一般人能够承担的范围之内,于是,小餐饮加盟项目开始流行开来,今天小编就来为您介绍比较受欢迎的小餐饮加盟排行,供您参考,1、小餐饮加盟排行之西安胡...。
当地时间3月31日,美国总统拜登在宾夕法尼亚州匹兹堡发表讲话,并公布了一项2万亿美元的基础设施计划,该计划为期8年,为拜登,哈里斯政府,重建更美好未来,BuildBackBetter,计划的一部分,旨在重建美国老化的基础设施,推动电动汽车和清洁能源,创造就业机会,据白宫官员周二晚间向媒体通报的细节,这份时间跨度为八年的法案,主要涉及...。

发表在峰米投影仪2023,5,916,35峰米R1C是最新上市的超短焦激光投影仪,峰米R1C的整体配置相比前代R1有所提升,具体峰米R1C参数配置怎么样呢,下面就来抢先了解一下,看看峰米R1C投影仪究竟怎么样,峰米R1C参数配置抢先看,1.峰米R1C采用的是ALPD激光光源技术,拥有出色的亮度表现,实际亮度达到850CVIA流明,可以...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为肯定发广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在肯定发广告联盟网站首页底部或友情链...。

文字链接认证代码普通联盟标志认证代码企业广告联盟标志认证代码广告联盟评测代码说明,本页面的认证代码为功夫CPA广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在功夫CPA广告联盟网站首页底部...。

纵览资讯记者边义婷近日,网上产生多个,韦东奕为洞庭湖水患捐款1600万元,月球采样轨迹是由韦东奕计算的,关系内容,并在网络上少量流传,网友纷繁美化,韦神,,也有网友质疑是,谎话,7月8日,纵览资讯,报料微信,ZLXWBL2023,记者咨询到北京大学数学迷信学院,上班人员示意不曾据说此事,岳阳、华容县的慈善部门也示意,未查到有160...。

射手座男人看待恋情环球上没有坚无法摧的恋情,没有人可以以为她的某段恋情是必需会走到最后的,感情是很软弱的东西,它只能是两团体之间的契约,而且任何打草惊蛇都能带来恋情的塌房,而守护恋情的人永远都是能够扛得住千军万马的那一gè,每团体永世都不只会意动一次性,在你糊涂期开局,就对,青睐,这个词有了必定的认知,你开局青睐某一团体,他第一句话,...。

点开网络,搜查,在线星盘,有很多网站均提供查问在线星盘的收费服务,如今各占星网站很多都提供这种在线排出世星盘的配置,星盘排好后,你再依据星盘中显示的行星位置对应检查相关的相位与宫位等等解析就可以了,心思占星和详细解盘注重占星师的阅历,单纯排盘和检查星盘解释相对便捷,以下为星盘消息范例图,星盘解读入门,一,假设知道一团体的出世年月日...。

元元,比官网指点价活动了3000元假设选用以全款方,易车讯近日,咱们从相关渠道取得了新款本田飞度的图片新车将照旧提供潮跑ProSPORT和潮越MaxCROSSTAR系列车型可供选用,并且在细节方面有所变动能源方面,新车换装了代号为L15CC的15L发起机,参数有所调整据悉,新车,2021潮享版有胎压监测,飞度潮享版带胎压监测性能,一款...。

recuva汉化版是一款功能非常强大的数据恢复软件,完美地支持Windwos系列所有操作系统,支持NTFS、Fat32、exFat等文件系统上的数据恢复。

毕顿亲手杀了千寻。为什么千寻没有杀她?他没有使用千手kill...直接跳过了,首先,我们可以排除千岛柳不知道比比通杀了千寻的可能性,因为他在钱成神的时候就已经指出了真相,告诉钱比比顿杀了他的父亲,木叶龙神,千手Kill,飞雷神之术,沙林甘瞳法的大威力,瞳法没有继承。1、在动漫《火影忍者》中,有哪些强大忍术没能继承下来?千年杀戮,不朽模式,九尾模式,多影分离,嘴盾,这些都是没有继承下来的忍术。神造纸术,死神血,泥巴灌顶,飞雷神,蛙油弹,这些都没有继承。木叶龙神,千手Kill,飞雷神之术,沙林甘瞳法的大威力,

有花的游戏下载介绍有哪些,游戏以其绚丽的视觉效果和生动的色彩搭配,成为了玩家们的新宠,这些游戏不仅仅是视觉的盛宴,它们还巧妙地融入了各种创新的游戏机制和挑战,让玩家在享受美丽景色的同时,也能体验到游戏的刺激与乐趣,这些游戏不仅提供了视觉上的享受,更通过精心设计的玩法,让玩家在虚拟的花海中畅游,体验不一样的花卉世界,1、,幸福鲜花店,玩...。

重磅消息,重磅消息,你听说了吗?,听说什么呀?,视频号呀,微信推出视频号了,视频号,不是都推出快一年了吗,和我有什么关系?,谁说没关系的,视频号能赚钱呀,恭喜你,今天又是遇见作者的一天,作者今天和大家聊聊视频号的涨粉运营策略,视频号是什么东西?从个人创业角度来看,视频号是一个ip孵化器,正如微信公众平台的slog一样,...。

如果将数据科学家比作医生的话,那么数据科学本身便既是行医技能,又是行医工具,1974年,因科学研究计算机模拟产生了大量数据,需要依靠算法发现其中规律,图灵奖得主PeterNaur首次提出了数据科学,DataScience,的概念,基于数据处理的科学,这标志着数据科学的开端,当今世界,随着互联网的发展,数据无处不在,要想利用好大数据,揭...。

感官教育在蒙特梭利教育体系中占有重要的地位,并成为她的教育实验的主要部分,在她的著述中,有大量篇幅专门论述感官教育训练、运动训练与智力发展以及感官教育与纪律教育、知识、技能的培养的关系和密切的联系,她认为感官教育的主要目的是训练儿童的注意、比较、观察和判断能力,使儿童的感受性更加敏捷、准确、精练,在蒙特梭利看来,学前阶段的儿童各种感觉...。

24年10月15日晚发布,大疆Air3S正式发布,机身运动部分没换,但最核心的相机和避障部分几乎全换了,现在是1英寸广角,前视激光雷达,夜景级避障,大疆Air3S的广角相机换成,1英寸,,双摄都能录4K60fps的硬件HDR视频,首发的自由全景功能,自己选定全景拍摄范围,;引入大疆首个,前视激光雷达,,能建立空间地图并记忆飞行路线循迹...。
