万亿次 180 每秒 谷歌新一代 三大变化值得关注 TPU (万亿次每秒的计算机称为)
在人工智能领域,训练一个先进的机器学习模型需要投入大量的计算资源。随着机器学习算法越来越多的应用在各个领域并表现出优越的性能,对于机器学习算法专业硬件的需求,也变得越来越强烈。
2016 年,谷歌首次公布了专为加速深层神经网络运算能力而研发的芯片——TPU,在计算性能和能耗指标上,TPU 的表现都远远优于传统 CPU、gpu 组合。(我们在上个月也曾发布过一篇文章,解析 TPU 耀眼成绩背后的原因)
在 5 月 19 日凌晨举行的谷歌 I/O 2017 大会上,谷歌正式发布了第二代 TPU。新的芯片相比初代产品,在 性能、应用、服务 方面再一次实现突破。
一、性能方面
新一代 TPU 能够同时应用于高性能计算和浮点计算。 并且最高可以达到每秒 180 万亿次的浮点运算性能。相比而言,上周英伟达刚刚推出的 GPU Tesla2 V100,每秒只能达到 120 万亿次浮点运算。
相比第一代在功能上实现从无到有的突破,第二代的起点相对更高,开发团队也能更加集中资源来提升改进 TPU 的性能。相信通过硬件、软件的优化,后续第三代、第四代在性能取得持续突破的可能性非常大。

二、应用方面
第一代 TPU 没有特别提到组合应用、集群应用的功能,而且自身没有存储空间。第二代在发布会上直接就展示了一个 包含 64 颗二代 TPU 芯片的 TPU pod 运算阵列。这个运算阵列, 最多可以为单个 ML 训练任务提供每秒 11.5 千万亿次的浮点计算能力,大大加速机器学习模型的训练。

也有专业媒体提到,新的 TPU 在左右两侧各有四个对外接口,在左侧额外增加了两个接口。这些接口未来可能允许 TPU 芯片直接连接存储器,或者是直连高速网络,从而实现更加复杂的运算。理论上,开发者也能在此基础上设计更多的功能,添加更多的扩展。
三、服务方面
从 Cloud TPU 的命名上面,也可以直观地了解到,新一代的 TPU 将加入谷歌云计算平台,并对外提供云服务。这也就意味着 TPU 不再只是谷歌内部的独享服务,而将成为任何人都能轻松分享、应用的神器。
这里就看出谷歌比较贼的地方了,第一代刚出来的时候,藏着掖着的,还特别低调地说只打算自己内部使用。二代研发出来,直接就上云了:硬件不对外销售,服务可以啊。
如果是直接的硬件销售,很多中小型的公司(比如我们公司:智慧思特)可能会更加偏向于选用 GPU:应用范围更广,可以根据需要安排处理不同的任务。大型的公司(比如阿里、FAcebook),ML 任务量非常大,才会考虑采购 TPU,甚至出于经费、效率的考虑,自主组建团队进行研发(比如这次谷歌自己做 TPU,Facebook 也有过自主研发数据中心硬件设备的报道);
对外销售服务的话,首先是激活了中小企业的这块需求市场,用户只需根据使用时间进行付费,节省了成本。另外,大型企业自身的资源利用率也有了很大的提升,摊薄了成本。比如阿里,为了应对双十一准备的海量服务器,在闲暇时间可以对外提供云计算服务。最后,避免了跟硬件厂商(比如英伟达)直接的利益冲突。
四、小结
综合来说,TPU,尤其是 Cloud TPU 让大型互联网公司印证了自主研发硬件的可行性。
性能上,针对自主业务进行成倍优化,节约硬件采购、数据中心建设、时间消耗等成本;应用上,可以灵活地与现有设施、设备进行组合、扩展;服务上,通过云实现资源的对外销售,赚取收益。
对应的,根据企业自身业务的不同,未来可能出现的定制化硬件设备也会不一样。比如针对在线交易数据处理的 APU?针对在线社交互动的 FPU?
至于如何评价 Cloud TPU,大概可以算是标志着人工智能专业硬件时代的到来吧。
版权申明:本文由 智慧思特大数据 编辑整理,雷锋网获得授权转载。
版权文章,未经授权禁止转载。详情见 转载须知 。



腾讯视频致力于打造中国领先的在线视频媒体平台,以丰富的内容、极致的观看体验、便捷的登录方式、多平台无缝应用体验以及快捷分享的产品特性,主要满足用户在线观看视频的需求。

4399消消看小游戏大全收录了国内外消消看类小游戏、宝石消消看小游戏、美女消消看小游戏、在线消消看小游戏。好玩就拉朋友们一起来玩吧!

2024深圳电子信息博览会将于2024年4月7-9日在深圳举行|光博会|集成电路展|信息通信|家用电器展|智能穿戴展|数码电子展|电子元件展|智能家电展会|聚焦未来电子信息发展,展示5G+,人工智能,移动互联网,物联网,云计算,大数据等前沿技术与家电消费电子产业进行深度融合的最新成果。致力于中国半导体芯片产品及电子生产企业、相关产业服务供应商等打造全面、集中的一站式采购交易合作平台。

陕西老三届实业有限责任公司老三届世纪星老三级首座盛邦物业陕西克力地产有限责任公司西安千秋置业有限责任公司

南京沪联新型建材有限公司

聚神铺导航是一个聚合全网免费实用的网址大全,专注宝藏工具,在线影视,动漫大全,免费音乐下载,免费小说网,绿色软件等资源网站分享.非常全面的网址导航!

成都晟昆辐射防护屏蔽工程一站式服务

神楚科技(湖北)有限公司,核心团队在商业连锁零售行业有20余年的从业经验,能提供智慧商业整体解决方案及区块链应用,自主研发神楚云平台提供商业购物中心、文旅综合体、百货商场、超市、便利店、果蔬、果饮、零食、专卖、农贸市场、无人自助店等零售连锁业核心管理软件和手机移动端的相关应用。也是海信收银POS硬件和ERP系统的核心代理,还提供收银机、自助收银机、自助售货机、智能盒饭机、条码电子秤、收银电子秤、扫描平台、客流视频监控、电子价签、防盗报警等零售设备及技术服务。

东莞市中卡嘉电子科技有限公司

腾云信息科技是一家专业的互联网基础服务提供商,整合网络营销实战策划,提供阿里云企业邮箱,东莞企业邮箱,东莞网站建设,东莞短视频运营,东莞抖音推广,东莞网站设计,网页设计制作,网站推广,东莞网站优化,东莞网站优化,东莞网络营销,专业网络营销等服务,热线:13751310643

河南省大雄鹰服饰有限公司成立于2003年,坐落于河南省沈丘县机械产业园内,总建筑面积4万平方米,是集设计、生产、销售为一体的民营企业,曾多次参与中国校服团体标准的制订

方林装饰是一家集装饰装修、设计、施工、主材、家具家电售卖于一体的全产业链实力派家装公司。拥有1000名设计师,10000名自有工人,凭借精湛徽派专利工艺,七星服务体系口碑相传,已累计服务全国业主超15万家!预约热线:400-063-1918


XDA论坛已经给出了具体的WP8.1越狱破解教程,以下教程方法由远景论坛整理发布,我们发现,安装在MicroSD卡中的微软官方应用可以获得比普通程序更多的访问和编辑权限,尤其是,用于开发人员的预览,应用,点此下载,那么这就提供了一种可能,如果我们将注册表编辑器等xap替换掉这些高权限应用,可想而知会带来多大的访问权限呢?先下载以下两个...。

7月9日,罗曼罗兰2023秋冬新品发布会在罗曼罗兰总部隆重举行,全国加盟商朋友齐聚一堂,共襄盛会,罗曼罗兰集团董事长徐德荣先生致词追光而遇沐光而行,借,光遇,展绘罗曼罗兰二十年灿烂历程,罗曼罗兰集团董事长徐德荣先生说道,承载时光印记,二十年如一日,秉承,生态、舒适、时尚,理念,专注家纺,专注品质,创造思维,整合全球出色资源,跨界探索与...。

奶茶取材自然新鲜,且不添加任何色素与添加剂,故奶茶是健康品质的饮品,深受年轻群体的青睐,市场中,奶茶的店面品牌迭出,其中,阿水大杯茶凭借着其出色、健康的品质成为奶茶项目中较为知名的品牌,阿水大杯茶在产品制作过程中,是有着严苛的品质标准要求,并且坚持古法制作工艺,充分还原奶茶的经典风味,所以阿水大杯茶是很受欢迎的,那么现在加盟阿水大杯茶...。
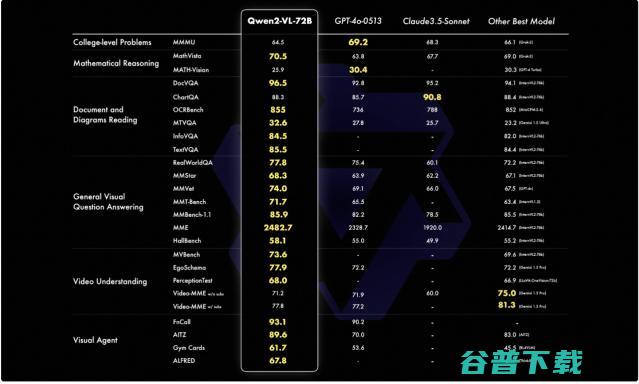
8月30日,阿里通义千问发布第二代视觉语言模型Qwen2,VL,旗舰模型Qwen2,VL,72B的API已上线阿里云百炼平台,Qwen2,VL在多个权威测评中刷新了多模态模型的最佳成绩,在部分指标上甚至超越了GPT,4o和Claude3.5,Sonnet等闭源模型,2023年8月,通义千问开源第一代视觉语言理解模型Qwen,VL,成为...。

发表在专业问答2020,11,920,03展示机型信息,品牌型号,明基w1120、当贝盒子B1、iPhone11系统版本,null、当贝OS2.0、ios14明基W1120不具备智能操作系统,所以无法投屏,需要使用hdmi线连接一个智能电视盒子,当手机与电视盒连接同一局域网后,手机打开无线投屏功能,搜索连接对应的电视盒子即可投屏,明基...。

发表在专业问答2021,5,1313,37展示机型信息,品牌型号,当贝X3系统版本,当贝OS2.0软件版本,当贝市场4.2.7可以,智能投影仪可以看电视节目,只需要在智能投影仪上安装当贝市场,然后通过当贝市场搜索下载装机必备,在装机必备中找到闪电超清直播进行下载安装使用即可,智能投影仪可以看电视节目吗可以的,智能投影仪是可以看电视节目...。

发表在综合交流大区2024,11,2711,002025年4K投影仪有必要买吗,答案是有必要的,4K投影技术如今已经相当成熟,价格方面也越来越实惠,三四千的预算即可入手,那么2025值得推荐的4K投影仪有哪些呢,下面就分享给大家,看看2025有哪些4K投影仪值得入手,2025值得推荐的4K投影仪,第一款,当贝F7Pro第二款,极米RS...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

转换mp3格局的软件有迅捷音频转换器迅捷音频转换器,提及MP3格局转换,当然少不了这款迅捷音频转换器,它具有市面上多种干流音频格局之间的相互转换,在转换的环节中,还允许自定义设置关系参数,咱们可以依据自己的需求,对输入文件的品质和声道等启动选用,这款软件的转换速度较快,音频文件的输入成果好,并且允许批量转换,能够在较大水平上提高咱们的...。

第一名,天蝎座急功近利,深藏不露,城府极深,有气魄,有野心,英勇,意志力超强,隐忍、执着,洞察力极强,迸发力强,有12星座举世无双的第六感,是成大事者的首选,实数12星座之冠,第二名,摩羯座享乐耐劳,大器晚成,有野心,忍气吞声,坚决不移,意志顽强,大智若愚,是成大事者另一选用,综合实力略仅次于天蝎座的优等星座!第三名,水瓶座思想怪异,...。

腾讯电脑管家最新版本电脑版是腾讯公司推出的一款电脑安全管理软件,它可以实时保护电脑的安全,查杀病毒木马软件,可以清理各种垃圾,可以修复电脑漏洞和腾出更多的内存,欢迎有需要的朋友到downcc下载使用!官网介绍腾讯电脑管家正式版官方对外发布,应用腾讯自研

U盘量产工具万能版是一款非常专业的通用优盘量产软件。有很多时候U盘都会出现一些,那么想要重新使用的话,就需要重新格式化

珠宝是人们喜爱佩戴的产品,可以提升个人的气质,所以人们对珠宝有较大的需求量,市场上也涌现出更多的珠宝品牌,其中就有金至福珠宝,金至福珠宝是一家连锁品牌店,也是行业翘楚品牌,所以在市场上发展很好,也取得不错的成绩,那么,加盟金至福珠宝优势多不多,经营容易吗,加盟金至福珠宝优势多不多1.品牌优势,金至福珠宝拥有多年的品牌积淀和市场口碑,为...。

发表在其它家用投影仪品牌2021,8,711,21汇趣生产的投影仪型号较少,汇趣f18投影仪就是其中之一,官方给出的屏摄图看起来效果非常的不错,那么汇趣f18投影仪真实画面怎么样呢,入手后悔吗,本文带大家一探究竟,一、汇趣f18投影仪参数汇趣f18投影仪采用的是LED光源,官方宣传支持4k分辨率,但并没有给出显示芯片的尺寸;内置安卓智...。

代码说明,本页面的认证代码为555广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在555广告联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升5...。

宝马5系国产车型的长度、宽度和高度区分为5087mm、1868mm、1500mm和3108mm,宝马5系国产车型为延长轴距车型,出口车型为规范轴距车型,出口车型的长度、宽度和高度区分为4954mm、1868mm和1489mm,轴距为2975m,宝马5系国产车型共经常使用两种发起机,一种是低功率版2.0升涡轮增压发起机,另一种是高功率版...。

1、梦见一座破旧的庙宇的吉凶指数基础安宁,成功运佳,财利声誉俱得并大开展之势,肥壮、短命、幸福之兆,唯若人格或地格若凶数,恐因好大,喜功,行事亦易招败,若无凶数,则可免忧虑,大吉昌,吉凶指数,94,仅供参考,2、梦见一座破旧的庙宇的宜忌,宜,宜清算马桶,宜穿娇艳袜子,宜喝碳酸饮料,忌,忌穿格子衬衫,忌拍照,忌亲吻,3、梦见一座破旧...。
