ACL 2020 亮点摘要 (acl2024)

字幕组双语原文: ACL 2020 亮点摘要
英语原文: Highlights of ACL 2020
翻译:雷锋字幕组( 唐里 、 张超726 、 情报理论与实践 、)
今年国际计算语言学协会(ACL)变为线上举办了,很遗憾我没多少机会去和其他学者交流,和同事们叙叙旧,但是遗憾之余值得庆幸的是我也相比平时听了更多讲座。因此我决定将我做的笔记分享出来并讨论一些行业总体趋势。本文不会对 ACL 进行详尽的介绍,内容的选择也是完全基于本人的兴趣。同时我也非常推荐读者看一看最佳论文。
近年来整体趋势
在根据我自身参与的讲座来讨论研究趋势之前(当然参与讲座数量有限,会存在误差),让我们来看一看ACL网页上的一些整体数据吧。今年收到交稿量最多的方向分别是通过机器学习处理自然语言,对话和交互系统,机器翻译,信息提取和自然语言处理的应用及生成。
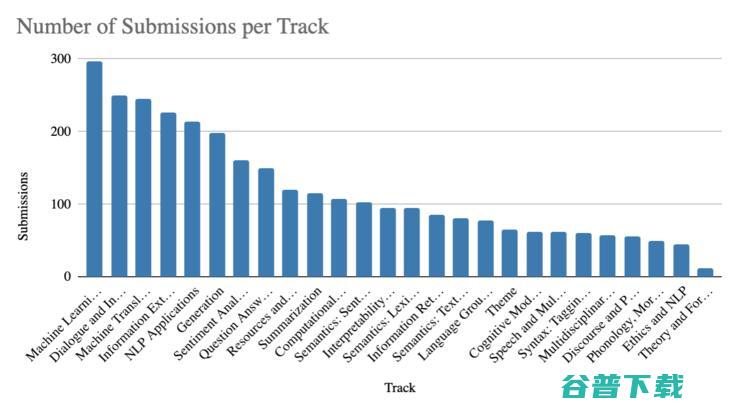
上图是每个研究方向提交稿件的数量
这些数据相比往年怎么样呢?下图显示了从2010年后每个方向论文数量的变化。图源 Wanxiang Che
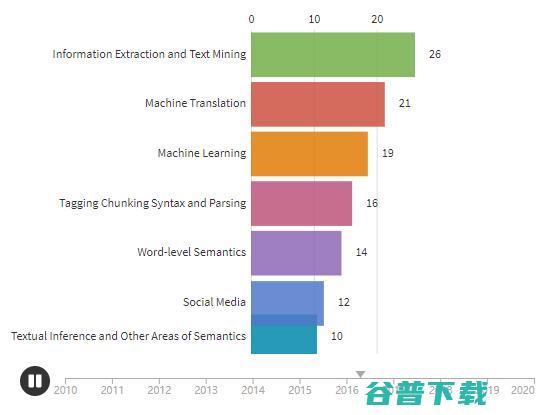
总的来说,论文有从基础任务到高级任务发展的趋势,例如从通过单词级,句子级语义和语篇的句法,过渡到对话。机器学习方向研究也正稳步增加,越来越多的文章提出具有普遍性目标的模型,而这些模型都基于多个任务来衡量。
ACL 2020 趋势
“我调整了基于某任务的BERT模型,然后在某评价标准下表现更好了”这类论文更少了
在自然语言处理研究有个反复出现的模式,1. 介绍一个新模型;2. 通过改进模型,或者将其应用于多任务实现一些容易的目标然后发表;3. 发表文章分析其不足之处或缺陷;4. 发表新的数据集。尽管某些步骤可能同时进行,我得说我们现在就处于2和3之间。小标题的结论是基于我选择的论文得出的,而我很大程度上过滤掉了这类文章。所以或许换一种说法,那就是今年ACL 2020 还是有挺多文章不是这一类型的。
不再依赖大型已标注数据集
在过去两年中我们可以发现研究向这些步骤靠近,先基于无标记文本的自监督方法进行预训练然后在更小的具体任务数据上微调。在今年会议上,很多论文聚焦于更少监督的训练模型。这有一些替代方案,及其示例论文:
无监督方法: Yadav等人 提出了一个基于检索的问答方法,这种方法可以迭代地将询问提炼到1KB来检索回答问题的一些线索。在常识类多选任务上通过计算每个选项的合理性得分(利用Masked LM), Tamborrino等人 取得了令人欣喜的成果。
数据增强(Data augmentation): Fabbri等人 提出了一种方法可以自动生成上下文,问题和回答三合一的形式来训练问答模型。他们首先检索和原始数据相似的上下文,生成回答:是或否,并且以问句形式向上下文提问(what, when, who之类开头的问句)然后基于这三件套训练模型。 Jacob Andreas 提出将不常见的短语替换为在相似语境下更常用的短语从而改进神经网络中的组合泛化能力。 Asai和Hajishirzi 用人工例子增加问答训练数据,这些例子都是从原始训练数据中按逻辑衍生出来用以加强系统性和传递一致性。
元学习(Meta learning): Yu等人 利用元学习去迁移知识用以从高源语言(high-resource language)到低源语言(low-resource language)的上义关系检测。
主动学习(Active learning): Li等人 搭建了一个高效的标注框架,通过主动学习选取最有价值的样本进行批注进行共指关系解析。
语言模型并不是你所需要的全部ーー检索又回来了
我们已经知道,语言模型的知识是缺乏和不准确的。在这次会议上,来自 Kassner and Schütze 和 Allyson Ettinger 的论文表明某些语言模型对否定不敏感,并且容易被错误的探针或相关但不正确的答案混淆。目前采用了多种解决方案:
检索:在Repl4NLP研讨会上的两次受邀演讲中,有两次提到了检索增强的LMs。 Kristina Toutanova谈到了谷歌的 智能领域 ,以及如何用实体知识来增强LMs(例如, 这里 和 这里 )。 Mike Lewis谈到了改进事实知识预测的最近 邻LM模型 ,以及Facebook的将生成器与检索组件相结合的 RAG模型 。
使用外部知识库:这已经普遍使用好几年了。 Guan等人 利用常识知识库中的知识来增强用于常识任务的GPT-2模型。 Wu等人 使用这样的知识库生成对话。
用新的能力增强 LMs: Zhou 等人 训练了一个 LM,通过使用带有模式和 SRL 的训练实例来获取时间知识(例如事件的频率和事件的持续时间) ,这些训练实例是通过使用带有模式和 SRL 的信息抽取来获得的。 Geva 和 Gupta 通过对使用模板和需要对数字进行推理的文本数据生成的数值数据进行微调,将数值技能注入 BERT 中。
可解释 NLP
检查注意力权重今年看起来已经不流行了,取而代之的关注重点是生成文本依据,尤其是那些能够反映判别模型决策的依据。 Kumar 和 Talukdar 提出了一种为自然语言推断(NLI)预测忠实解释的方法,其方法是为每个标签预测候选解释,然后使用它们来预测标签。等人 开发了一种忠实的解释模型,其依赖于事后归因(post-hoc)的解释方法(这并不一定忠实)和启发式方法来生成训练数据。为了评估解释模型, Hase 和 Bansa 提出通过测量用户的能力,在有或没有给定解释的前提下来预测模型的行为。
反思NLP的当前成就,局限性以及对未来的思考
ACL今年有一个主题类别,主题是“通观现状与展望未来”。
我们求解的是数据集,而不是任务。在过去的几年中,这种说法反复出现,但是如今,我们的主要范式是训练庞大的模型,并在与我们的训练集非常相似的众包测试集上对其进行评估。荣誉主题奖论文作者塔尔·林岑()认为,我们在大量数据上训练模型,这些数据可能无法从人们可用的数据量中学到任何东西,而且这些模型在人类可能认为不相关的数据中找到统计模式。 他建议,今后,我们应该标准化中等规模的预训练语料库,使用专家创建的评估集,并奖励成功的一次性学习。
凯西·麦基翁(Kathy McKeown)的精彩主题演讲也谈到了这一点,并补充说排行榜并不总是对推动这一领域有所帮助。 基准通常会占据分布的顶端,而我们需要关注分布的尾部。 此外,很难使用通用模型(例如LM)来分析特定任务的进步。 在她的终身成就奖访谈中,邦妮·韦伯强调需要查看数据并分析模型错误。 即使是一些琐碎的事情,比如同时查看精确度和回忆,而不是只查看F1的总分,也可以帮助理解model s的弱点和长处。
当前模型和数据存在固有的局限性。 邦妮还说,神经网络能够解决不需要深入理解的任务,但是更具挑战性的目标是识别隐含的含义和世界知识。 除上述论文外,几篇论文还揭示了当前模型的局限性:例如, Yanaka等人 。 和 Goodwin等 指出神经NLU模型缺乏系统性,几乎不能概括学习到的语义现象。 艾米莉·班德(Emily Bender)和亚历山大·科勒(Alexander Koller) 的最佳主题论文认为,仅从形式上学习意义是不可能的。 Bisk等人在预印本中也提出了类似的要求。 提倡使用多种方式学习意义。
我们需要远离分类任务。 近年来,我们已经看到了许多证据,证明分类和多项选择任务很容易进行,并且模型可以通过学习浅层的数据特定模式来达到较高的准确性。 另一方面,生成任务很难评估,人类评估目前是唯一的信息量度,但是却很昂贵。 作为分类的替代方法,Chen等。 将NLI任务从三向分类转换为较软的概率任务,旨在回答以下问题:“在假设前提下,假设成立的可能性有多大?”。 Pavlick和Kwiatkowski进一步表明,即使是人类也不同意某些句子对的并列标签,并且在某些情况下,不同的解释可以证明不同的标签合理(并且平均注释可能会导致错误)。
我们需要学习处理歧义和不确定性。 Ellie Pavlick在Repl4NLP上的演讲讨论了在明确定义语义研究目标方面的挑战。 将语言理论天真地转换为NLI样式的任务注定会失败,因为语言是在更广泛的上下文中定位和扎根的。 盖·艾默生(Guy Emerson)定义了分布语义的期望属性,其中之一是捕获不确定性。 冯等。 设计的对话框响应任务和模型,其中包括“以上皆非”响应。 最后,Trott等 指出,尽管语义任务关注的是识别两种话语具有相同的含义,但识别措辞上的差异如何影响含义也很重要。
有关道德伦理的讨论(很复杂)
ACL 在道德伦理方面的进步是非常显著的。前几年,NLP 中道德伦理还少有人研究,但如今却已然是 ACL 的一大类别,而且我们所有人在提交其它类别的论文时也都会考虑伦理道德。事实上,我们这个社区现在开始转向批评那些探讨重要的公平性问题而同时又未能解决其它道德伦理考虑的论文。
我强烈推荐观看 Rachael Tatman 在 WiNLP 研讨会上洞见深入的主题演讲「What I Won’t Build(我不会构建的东西)」。Rachael 说明了她个人不会参与构建的那几类系统,包括监控系统、欺骗与其交互的用户的系统、社会类别监测系统。她提供了一个问题列表,研究者可用来决定是否应该构建某个系统:
Leins et al. 提出了许多有趣但仍待解答的道德伦理问题,比如符合道德伦理的 NLP 研究是怎样的,这应该由谁、通过什么方式决定?模型的预测结果应该由谁负责?ACL 应该尝试将自己定位为道德卫士吗?这篇论文讨论的问题之一是模型的双重使用问题:一个模型既可以用于好的目的,也可以用于坏的目的。事实上,会议期间,针对 Li et al. 的最佳展示论文发生了一场 Twitter 争论(很不幸该争论由一个匿名账号主导)。该论文提出了一个出色的多媒体知识提取系统。
其它值得关注的论文
本文作者还列举其它一些不属于以上类别的论文。
Cocos and Callison-Burch 创建了一个大规模的标注了含义的句子资源,其中的含义是通过同等含义的词进行标注的,比如 bug-microphone 中 bug 是个多义词,这里使用 microphone 进行标注,就固定了其小型麦克风 / 窃听器的含义,而非虫子的含义。
Wolfson et al. 将问题理解引入为一个单独的任务,其按照人类的方式通过将复杂问题分解为更简单的问题来进行解答。
Gonen et al. 提出了一种用于测量词义变化的非常直观和可解释的方法,其具体做法为检查词分布的最近邻。
Anastasopoulos and Neubig 表明尽管使用英语作为中心语言来进行跨语言嵌入学习是最佳实践,但却往往是次优的;该论文提议了一些用于选择更优中心语言的一般原则。
最后,Zhang et al. 众包了 Winograd 模式挑战赛的解释,并分析了解决该任务所需的知识类型以及现有模型在每种类别上的成功程度。
总结和思考
这些论文和主题演讲给我带来一种感觉,尽管过去几年取得了巨大的进步,但我们还没有走上正确的方向,也没有一条非常可行的前进道路。 我认为主题类别的变化具有正面意义,这能鼓励研究者不执着于容易取得的小进步,而是着眼大局。
我喜欢能够在自己的时间里(以喜欢的速度)观看这么多演讲,但这样也确实错过了与其他学者的互动,我不认为与不同时区的参与者呆在一个虚拟聊天室里是一个很好的替代方案。我真的希望疫情之后,会议将再次线下举行,但希望同时也允许人们以更低的注册费用远程参会。
希望明年能看到你们排着队买难喝的咖啡!(译者:笑)
雷锋字幕组是一个由AI爱好者组成的翻译团队,汇聚五五多位志愿者的力量,分享最新的海外AI资讯,交流关于人工智能技术领域的行业转变与技术创新的见解。
团队成员有大数据专家,算法工程师,图像处理工程师,产品经理,产品运营,IT咨询人,在校师生;志愿者们来自IBM,AVL,Adobe,阿里,百度等知名企业,北大,清华,港大,中科院,南卡罗莱纳大学,早稻田大学等海内外高校研究所。
如果,你也是位热爱分享的AI爱好者。欢迎与雷锋字幕组一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。



LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

园区点评网是全国范围内领先的专业园区招商服务网站,为各类产业园区提供园区招商、招商引资、园区资产管理服务,为大中小企业提供专业的企业选址服务,为各级政府单位构建各区域产业地图。

成都安宇广告主营:成都招牌制作、成都店招制作、LED光彩亮化工程、3M布灯箱制作安装、软膜卡布灯箱、动感灯箱、各类发光字、精品字、钛金字、霓虹灯字、灯箱制作、标识标牌,雕刻加工亚克力水晶字、PVC字、泡沫字、UV平板喷印、及各类亚克力制品等。

中山市溢锦纺织有限公司专业从事于生产绳带,鞋带织带,生产厂家.产品价格优惠,质量有保证,深受消费者的欢迎,电话18933344899欢迎来电咨询!

《天果仙剑》以经典原版《仙剑传奇》《仙剑情缘》为基础,延伸各种特色《仙剑版本传奇》怀旧,复古,公平,公正

珠海飞创智能科技有限公司,简称“珠海飞创”,座落于有“百岛之市”“浪漫之城”美称的广东省珠海市。是一家致力于伟迪捷标识设备代理、软件开发、系统集成、自动化设备研发、激光焊接

东莞诚材培训学校为你提供东莞叉车培训,铲车培训,叉车证复审,挖掘机培训,电工培训考证,焊工培训,氩弧焊工培训,二氧化碳保护焊工培训,co2气体保护焊培训,挖土机培训等东莞培训学校发布课程信息。13713201360陈老师

威客中国网即时间财富网,现已更名为威客牛,威客牛是威客行业中领先的威客网;服务品类涵盖平面设计、装修设计、网站建设、软件开发等多种企业服务领域。威客牛网致力于为广大中小企业解决各种外包需求问题,打造全方位的设计、开发服务兼职平台。

孔明聊项目

南华物流集团|物流园开发|物流园区运营|物流链产业投资|冷库租赁|仓储租赁|物流服务

蓝黛科技集团股份有限公司前身重庆市蓝黛实业有限公司,成立于1996年5月8日,2015年6月12日公司股票在深圳证券交易所上市交易,证券代码:002765,证券简称:蓝黛科技。公司主要产品为汽车手动变速器总成、自动变速器总成、新能源减速器、纺织机械传动总成和汽车变速器齿轮、轴、同步器等零部件、汽车发动机齿轮及轴等零部件。

瑞泽能源是一家专注节能环保产业的高新技术企业,从事水泵节能、水泵节能技术、空压机节能、水泵节能改造、以及高效节能风机等节能服务。

中国古风类型的游戏是现在手游中的一股清流,小编今天来给大家带来的是中国古风田园类经营游戏推荐2022,在这些游戏中大家可以重新回到中国的古代世界中,体验到恬静舒适的田园风光,并且运用自己的头脑进行经营,成为富豪,1、,江南百景图,来到了经历大战之后的明朝江南地区,玩家需要做的就是利用自己的聪明才智在废墟上重新营造城市,我们需要招募各种...。

有意思的火柴棒游戏汇总有哪些,这些游戏,以其独特的益智魅力,吸引着无数寻求挑战的灵魂,玩家们在屏幕上轻轻移动这些虚拟的火柴棍,就像是在进行一场思维的舞蹈,每一次移动都可能揭开一个新的谜题,这些由火柴棍构建的游戏世界,不仅仅是简单的娱乐,它们是智慧的竞技场,是创意的展示台,在这里,每一次成功的解谜都是对玩家智慧的肯定,每一次新的发现都是...。

共享充电项目是当下热门的创业项目,在国内几乎所有的城市地区都有着大量的共享充电服务项目火热经营发展,以不同的充电服务面向顾客,受到了很多消费者的喜爱,街电作为业内实力充电服务项目,资质齐全而且在业内有着多年的发展历程,在诸多充电项目上获得了认可,并且在市场的发展遍及规模较大,获得了很多创业人士的选择,那么,街电的收费高吗,街电作为真源...。

米线是一个非常大众化的消费,很多男女老幼都爱吃,米线不仅美味,营养也非常的丰富,随着人们对于饮食的探索,米线的种类也越来越多,米线被越来越多的消费者喜爱,很多的加盟者对米线行业也非常的感兴趣,那么加盟者该选择哪个品牌加盟呢,哪个品牌的米线比较的畅销,张一碗米线品牌米线店加盟,四季畅销营收多又快,俘获了众多美食爱好者的味蕾,张一碗米线主...。

截至5月13日下午16点,四川省地震灾害与抗震救灾工作通报了最新的伤亡情况,这场512大地震造成了极其惨重的人员伤亡,据官方统计,死亡人数已超过人,此外,还有人受伤,9404人被困等待救援,房屋损毁严重,据统计,受损房屋数量达到了346万间,这场灾难的破坏力可见一斑,让人心痛,整个灾区的救援和重建工作正在紧张有序地进行中,广西巴马地震...。

医保中心的权力大,医保中心是医疗保险的办事机构,负责具体的经办工作,包括个人和单位的医保管理,他们受医疗保险处的领导,同时也受人力资源和社会保障局的管理,医保中心在医保事务的处理过程中拥有较大的权力,包括审核和支付医疗费用、管理医保基金、制定医保政策等,医保局是医保基金的管理者和监督者,负责监督医保中心的运行和管理,以及对医保政策的制...。

自从俄乌抵触迸发以来,乌克兰方面不时在保持向西方盟友需要声援F,16战役机,在乌军看来,这款老式的战役机在俄乌战场上仍能施展较大作用,至少可以协助对消一局部俄空军取得的地面长处,美国、丹麦等盟友出于种种思考,在阅历了漫长的拉锯战后逐渐交付了大批战役机,这批宝贵的F,16战役机成为目前乌军最珍爱的武器,▲画面中的红色修建让俄军事博主确定...。

外地期间12日,以色列新任国防部长卡茨示意,在指标成功之前,以色列不会在黎巴嫩开战,也不会给黎真主党喘息的时机,卡茨称,以色列将确保解除真主党的武装才干,让以色列北部居民安保前往家园,总台记者张卓雅,点击进入专题,中东形势继续更新...。

这关于处于开展阶段的自主品牌来说尤为关键B90的外观很好的传承了家族设计,外观流利大气,是自主品牌车型中无法多得的成熟之作奔流B90的外观承袭了B70圆润丰满的设计,同时经过各种线条的搭配,勾画出更具层次感的前脸,不是奔流b90没有气压减震器,只要油气混合减震器,或电控空气弹簧,油气混合减震的原理和油压减震差不多就是在减震器底部设有气...。

菲亚特领雅,Linea,是一款由菲亚特外型核心设计的三厢车,它不只形状慷慨优雅、操控性出众、极具适用性、而且具备较高的性价比,它适宜各种场所的经常使用,可谓家庭关键用车的最好选用,泛滥的长处使得它在世界颁布时一夜之间成为了注目标焦点,领雅是菲亚特出口的车么,安保性能怎样样领雅最贴心的就是电动腰部撑持的性能,只管腰部撑持的性能在不少同级...。

长生劫的卦象系统目前只有十三个卦象,每个卦象所代表的效果也都不同,这里绿色资源网小编为大家带来长生劫吉凶全卦象解析,让你了解什么是凶什么是吉!喜欢的朋友不要错过哟! 长生劫算卦攻略大全 算卦系统目前刷出来是13卦。 6凶卦 駭涛凶水卦:浪费

《联众江湖》,一款跨越时空的传奇游戏,是一款有着精彩剧情和丰富玩法的角色扮演游戏,拥有海量玩家,深受众多玩家喜爱。一、游戏背景《联众江湖》以中国古代的江湖文化为背景,讲述

在目前国内儿童乐园还是主要以门票来维持儿童乐园的绝大支出,这一方面导致了儿童乐园在经营模式上的缺陷,另一方面也极大限制了国内儿童乐园的发展,虽然这种模式一时半刻难以改变,但还是有一些促销创收的手段帮助儿童乐园获得更多的经营,具体如下,1、群发短信、公众号营销,短群发信,或用本地知名的生活类资讯公众号,向手机客户发送每月的主题活动及近的...。

dkngo大神级投影控发表于2024,03,11全息投影技术是一种通过光学原理实现的三维影像投影技术,它利用激光的某些特殊属性来创建一个完整的三维物体,这个物体似乎悬浮在空气中,可以被观察和操作,下面是一种简单的自制全息投影方法,材料,1.一台激光器2.一个平面玻璃板3.一些透明的硬质塑料4.一些黑色不透明板步骤,1.找到一个薄而平整...。
代码说明,本页面的认证代码为5173广告联盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在5173广告联盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提...。

这几天,黎巴嫩寻呼机爆炸事情仍在继续发酵,这一被称为,现代特洛伊木马,的恶性事情引发了大家对包含手机、智能汽车在内的智能终端安保疑问的恐慌,依据目前各方披露的信息,是以色列的情报部门筹划了这一系列的爆炸事情,那么,以色列情报机构究竟是如何操作的,在以色列情报部门的关系历史资料中,找到了答案,点击进入专题,黎巴嫩寻呼机爆炸事情...。

冥王星最近落入12星座黄道十二宫的状况如下,记住就可以了,1779,1523年,落入第12宫双鱼座;1823,1851年,落入第一宫白羊座;1851,1883年,落入第二宫金牛座;1883,1913年,落入第三宫双子座;1913,1938年,落入第四宫巨蟹座;1938,1957年,落入第五宫狮子座;1957,1971年,落入第六宫处女...。
